今回はAutoMLのチュートリアルをやってみたいと思います。
この記事ではAzureMLStudio上での操作で実行をしていきます。
ワークスペースやクラスターの作成、実行方法等は最初の記事を参考にしてください。
データの追加
それではまずはAutoMLのジョブを作成していきます。
左上の新規機械学習ジョブを開きます。
次にデータの選択、登録です。
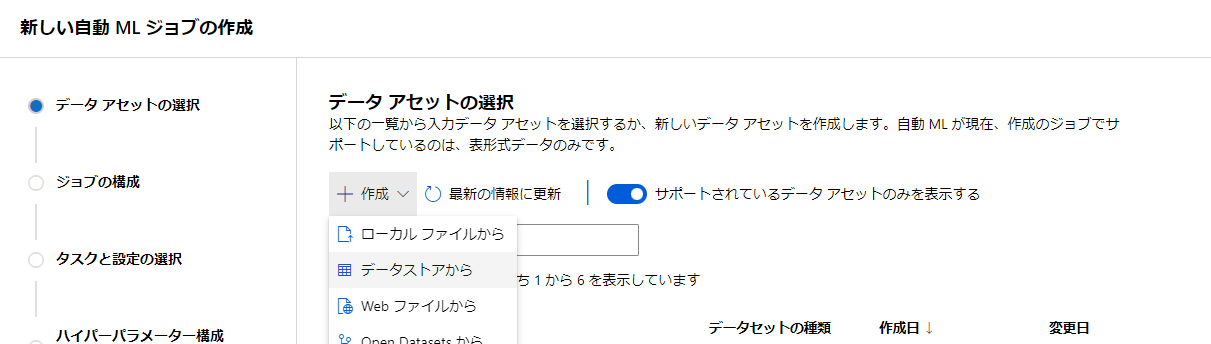
今回はtitanicのデータを用意してみたいと思います。
以前の記事でデータストアに登録しているのでそちらを持ってきたいと思います。
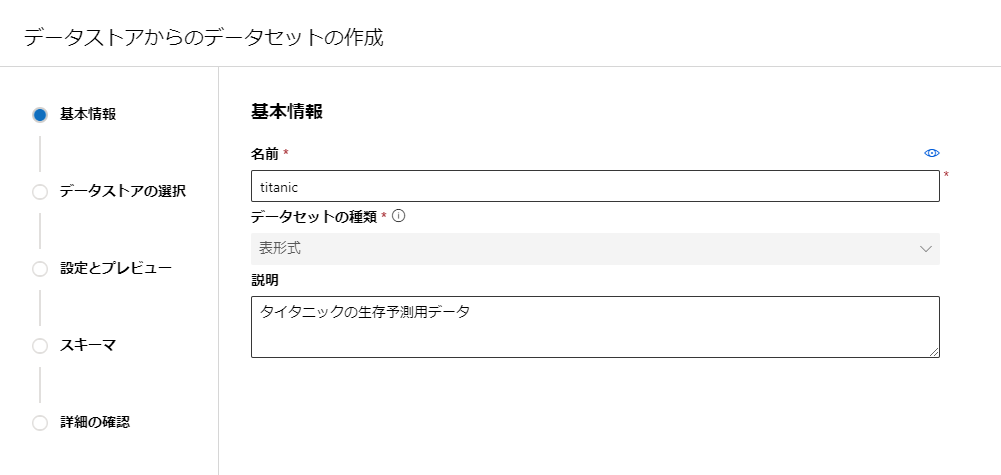
データセットの名前を決めて
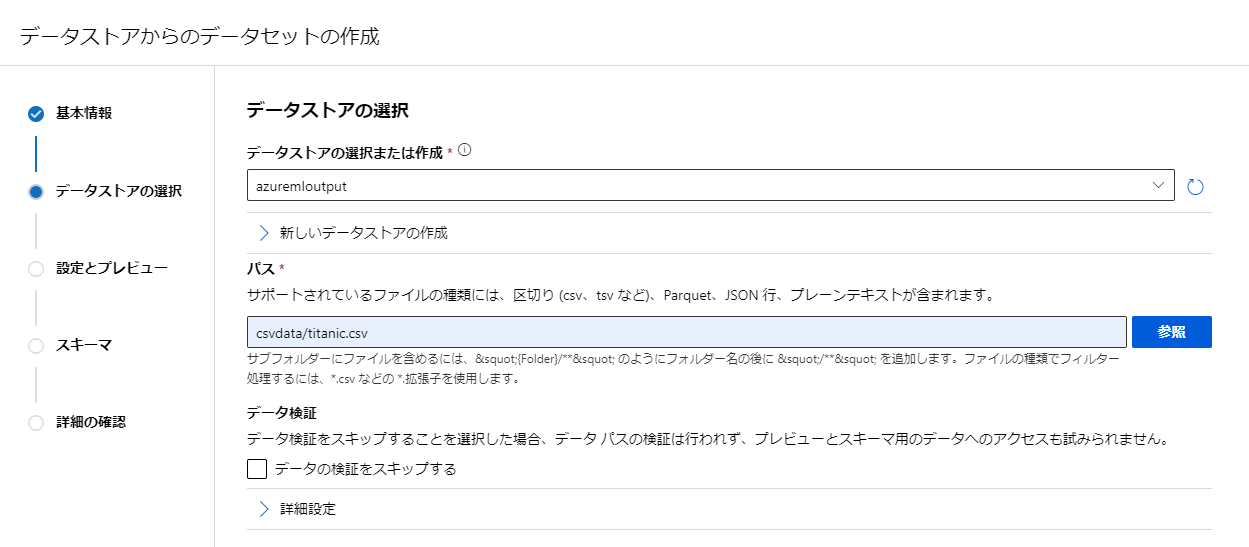
データを選択して
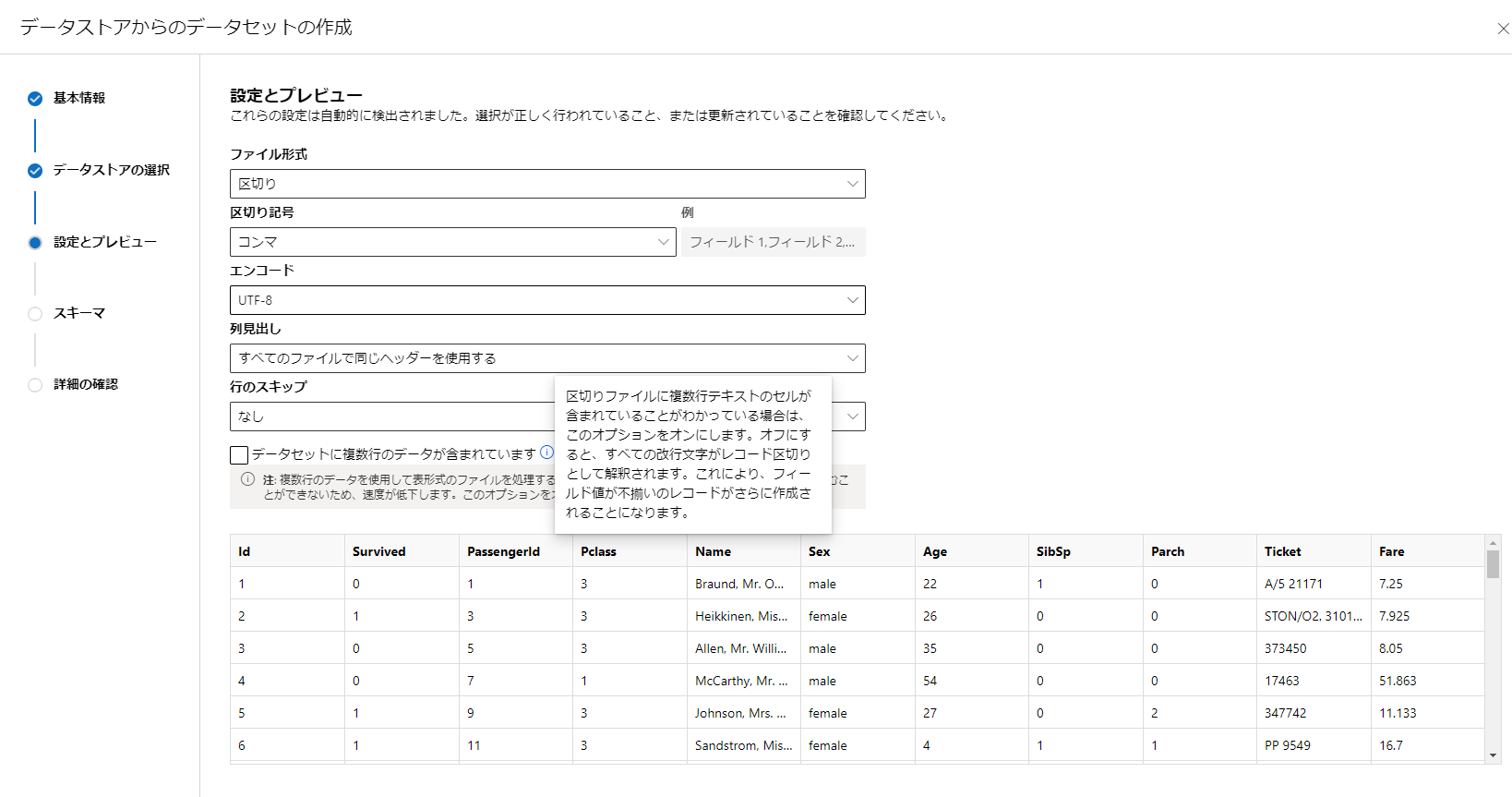
データの設定をします。
この時データ内に複数行(改行してるデータ)があるかを指定します。
存在する場合は別途処理をするようなので速度が低下するようです。
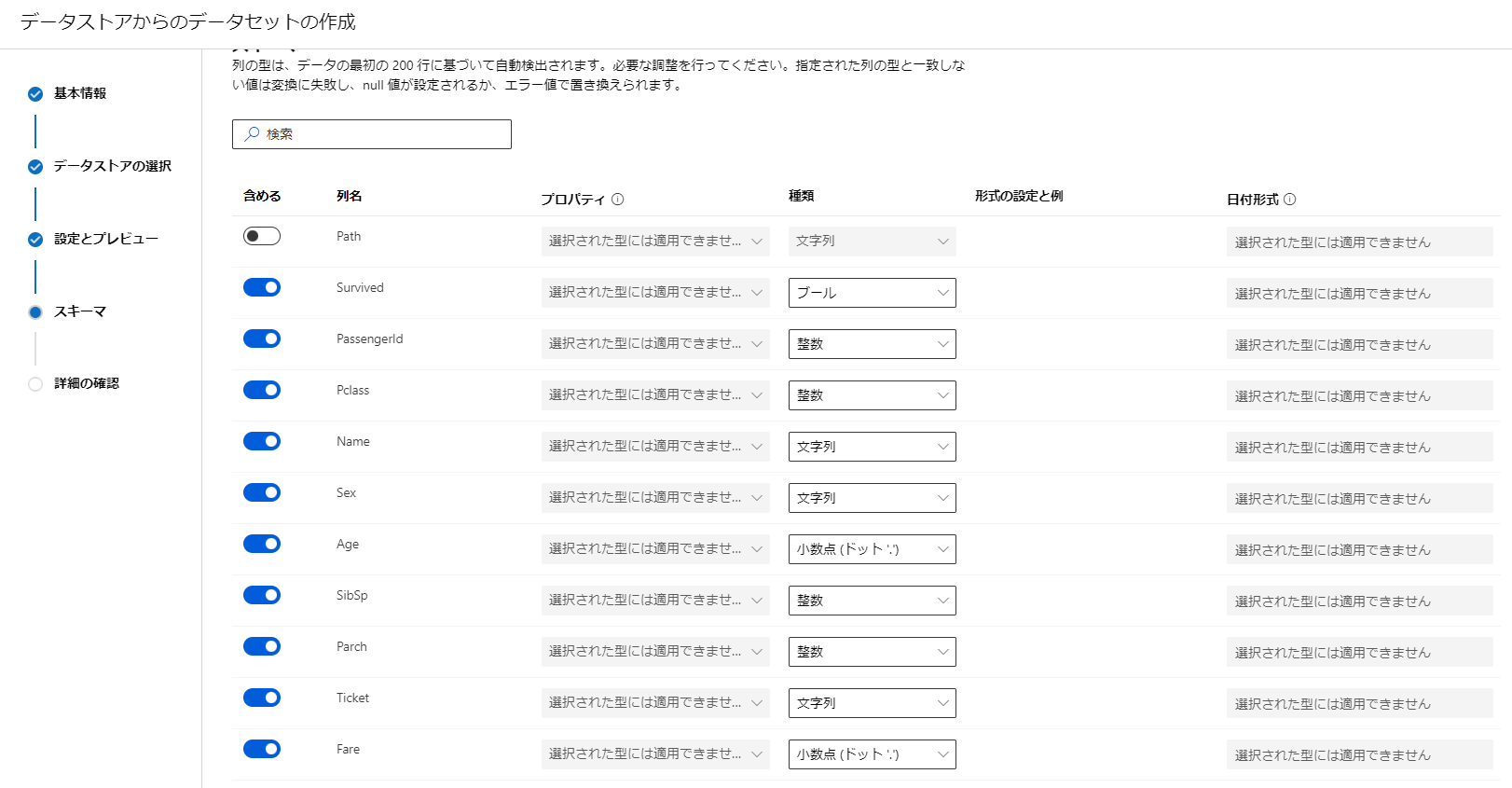
その後学習に利用するデータの設定をします。
学習に含めるか、データの型の指定を行えるようです。
また日付型の場合は形式の設定ができるみたいですね。
データの型は初期値としておおむね正しいものが設定されているようなのであまり気にしなくてもよさそうです。
今回はSurvivedの項目を整数からブールに変更してみました。
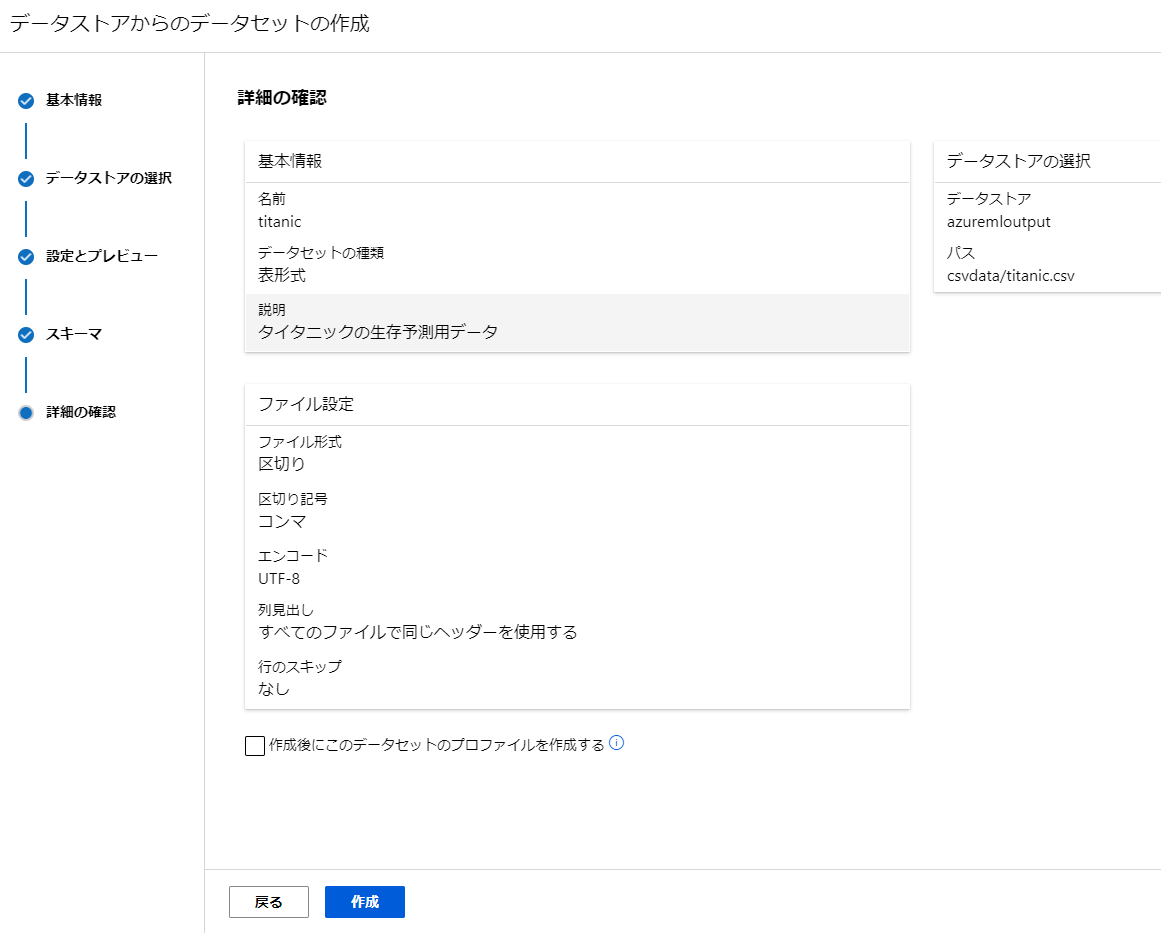
最後に確認して登録します。
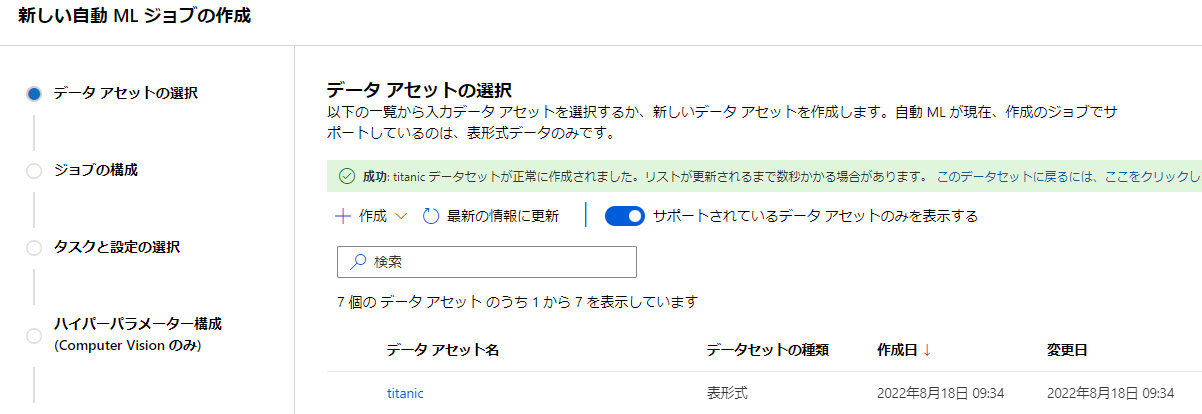
ちゃんと追加できました。
ジョブの構成
続いてジョブを設定していきます。

実験の名前と予測対象のカラム名を指定し、学習に用いるコンピューティング先を指定します。
タスクと設定の選択
ここではどのアルゴリズムで学習させるかを選択できるようです。
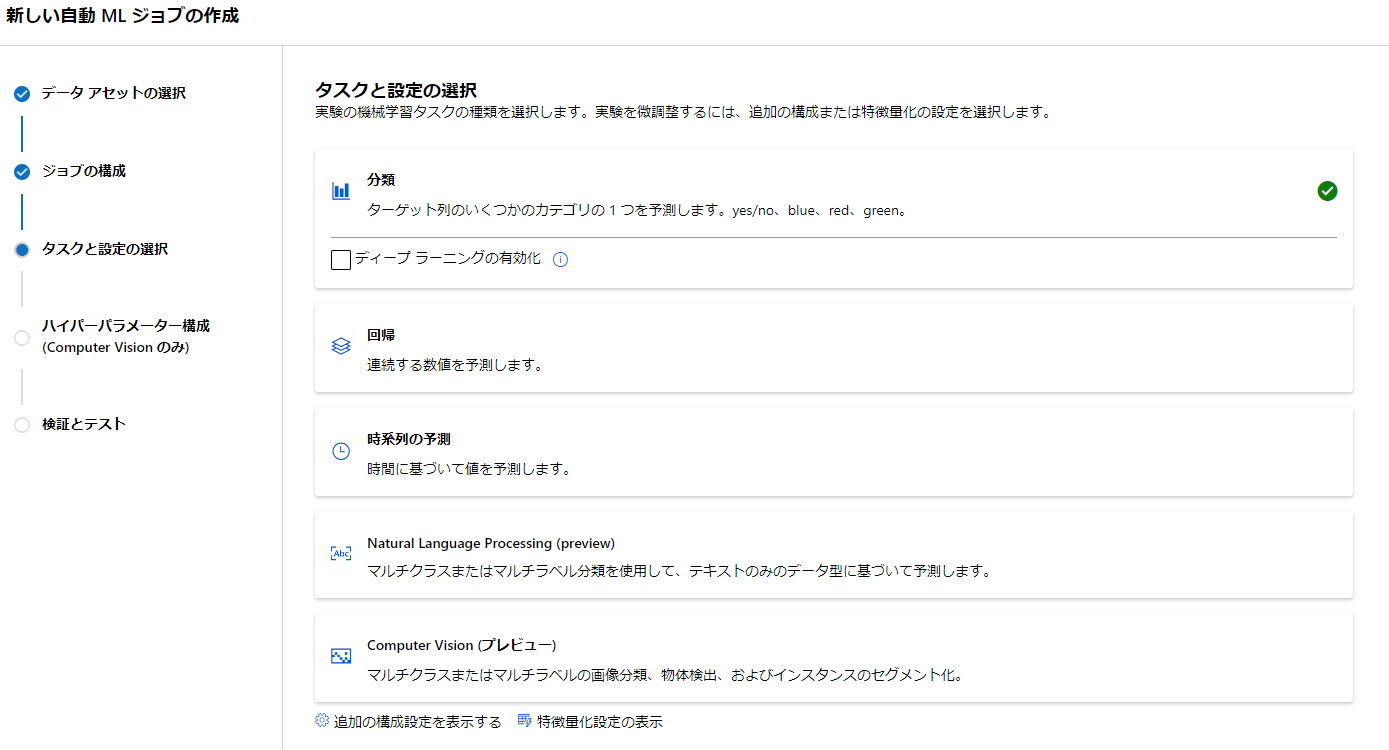
予測対象から自動で最適なものを選んでくれてるようです。
異なるものが選択されていればここで修正できますね。
今回はこのまま分析で行います。
ディープラーニングの有無も選べます。
今回はなしで行きましょう。
検証とテストの種類を選択
ここでは検証方法とテストデータの設定ができます。
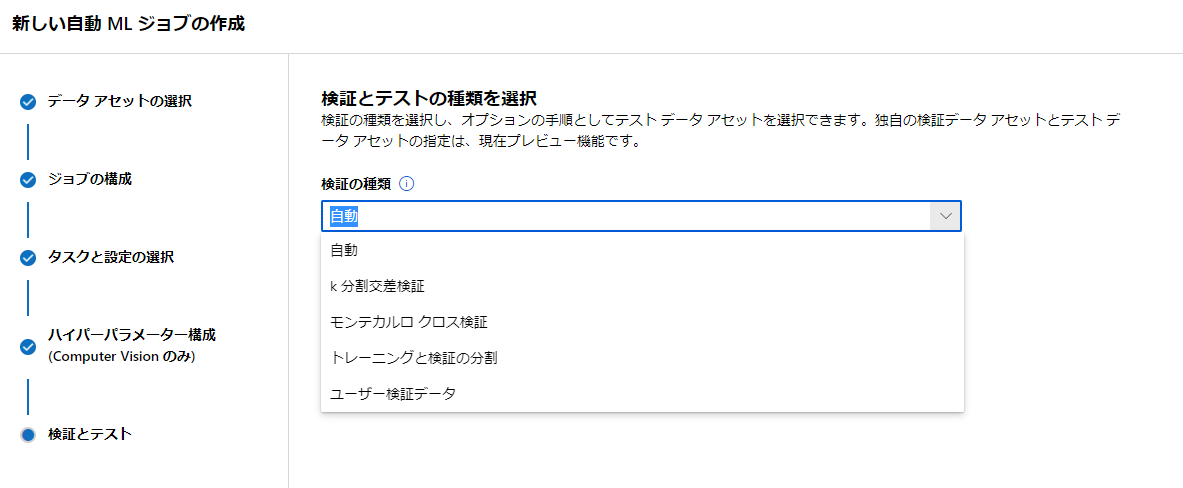
検証にはいくつか種類があるようですが自動という項目があるので今回はこれで行きたいと思います。
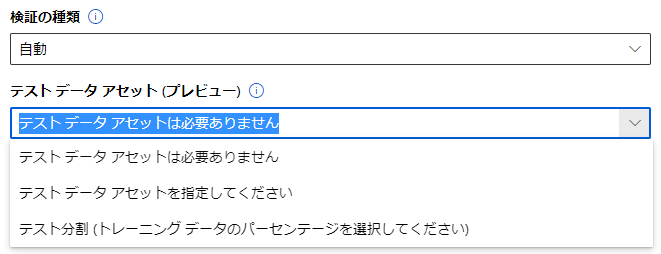
テストデータについては、自分で指定するか分割するかを選べるようです。
今回はテストデータ30%で分割してもらいましょう。
その後実行します。
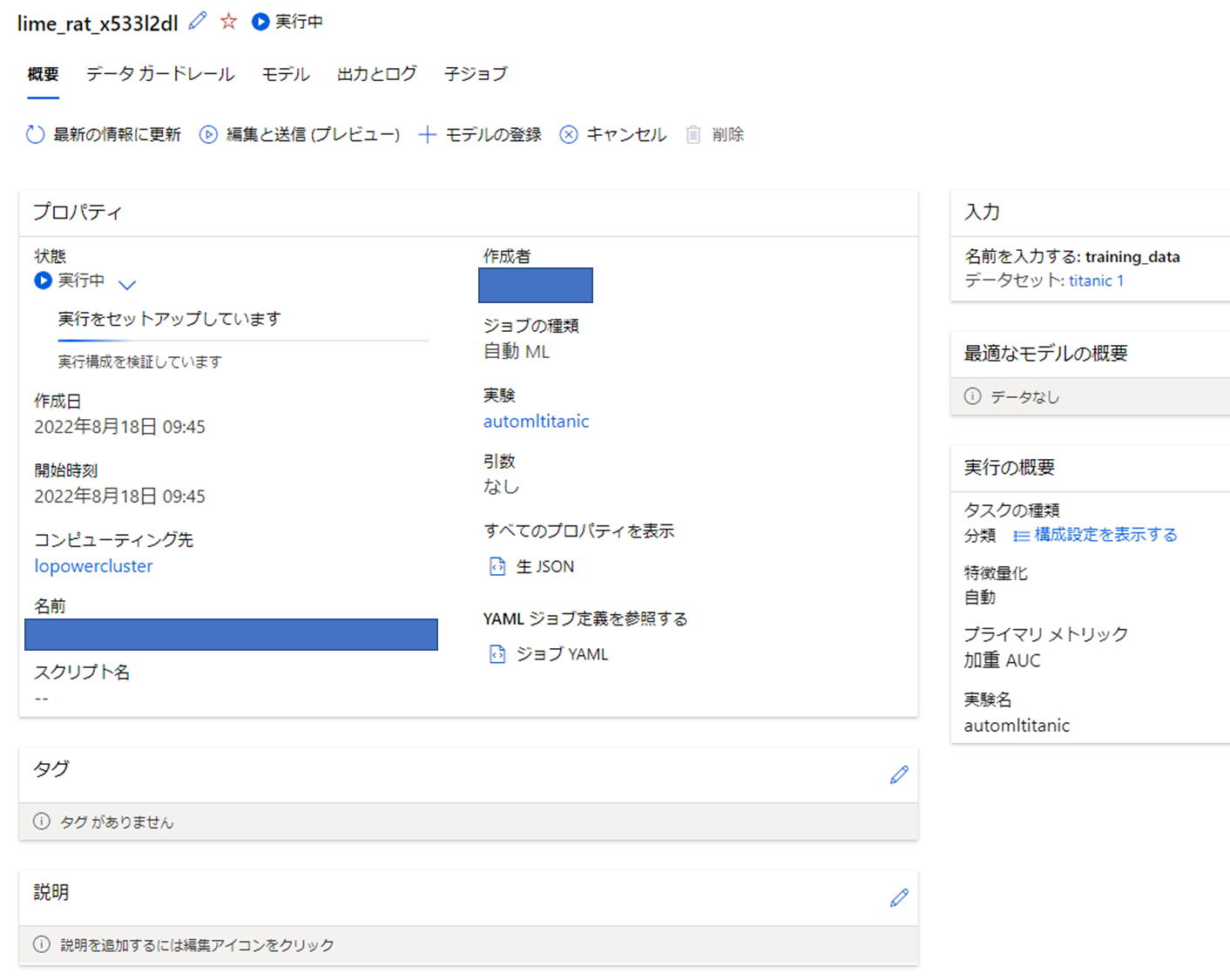
実行できました。
完了まで待ってみましょう。
結果の確認
実行終了までに55 分 48.33 秒かかりました。
全部で58個のモデルが作られているようです。
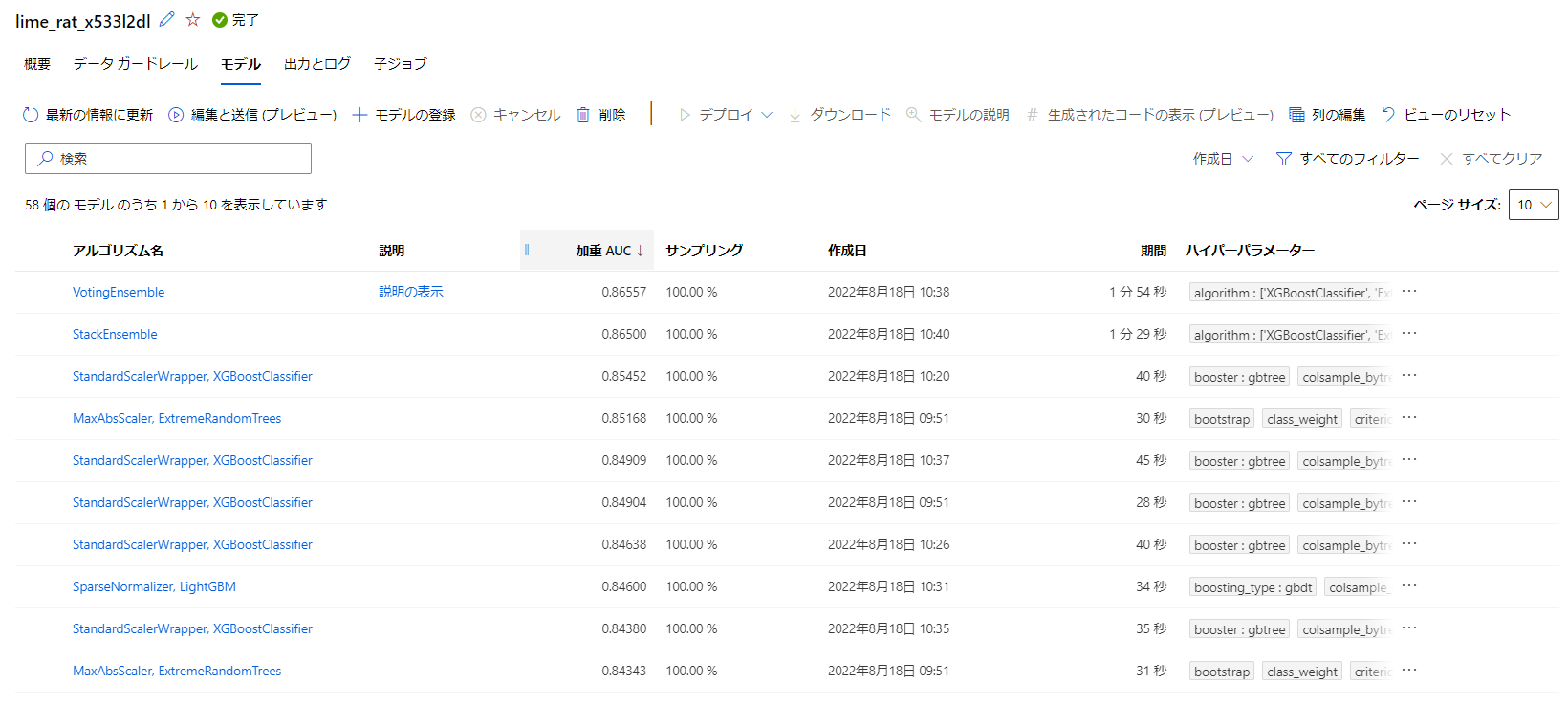
一番良かった結果には説明がついてるようです。
こちらを確認してみましょう。
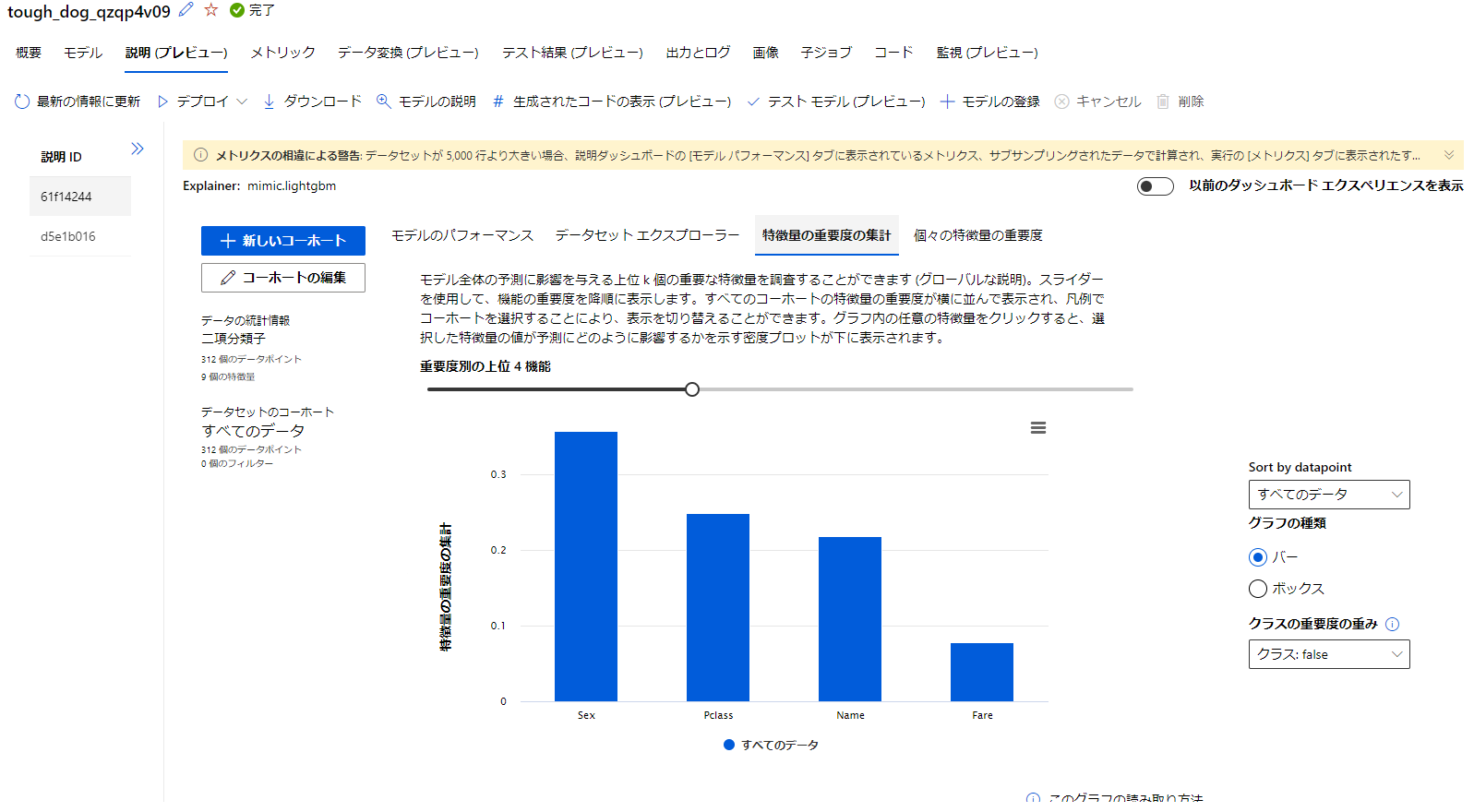
説明プレビュー
説明タブではデータについてが可視化されているようです。
重要度やデータの分布が確認できるようです。
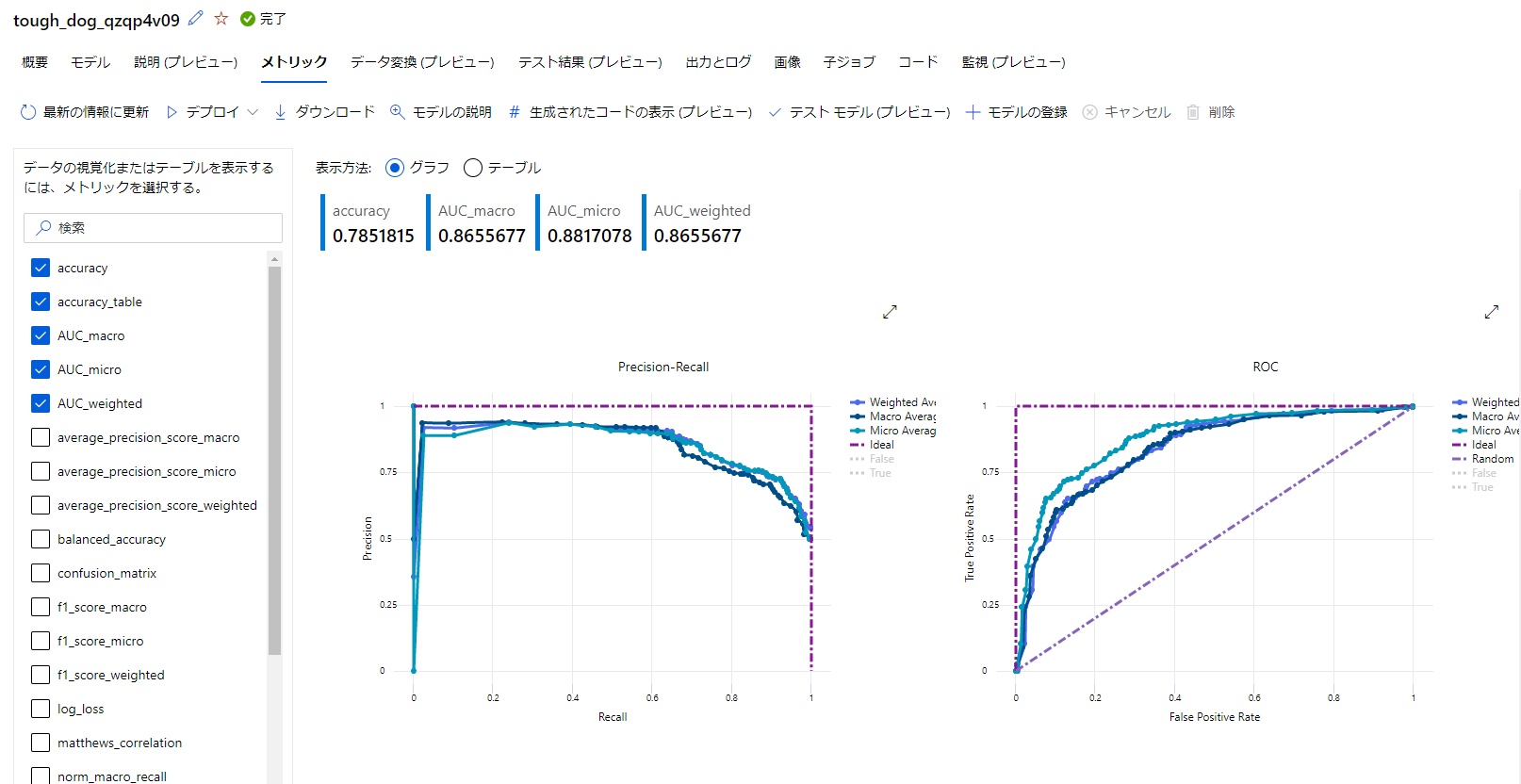
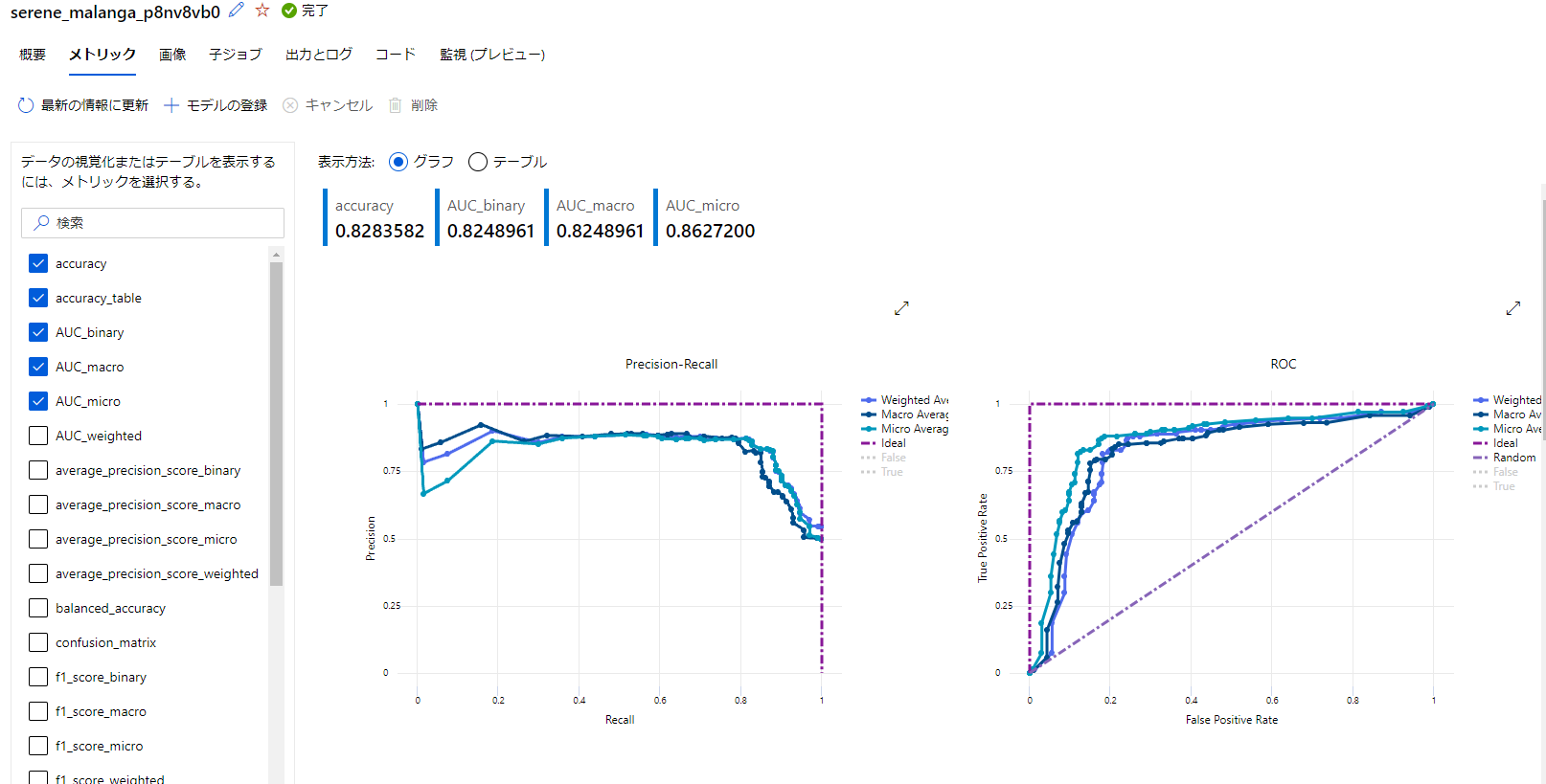
メトリック
メトリックでは精度指標が可視化されて確認できるようです。
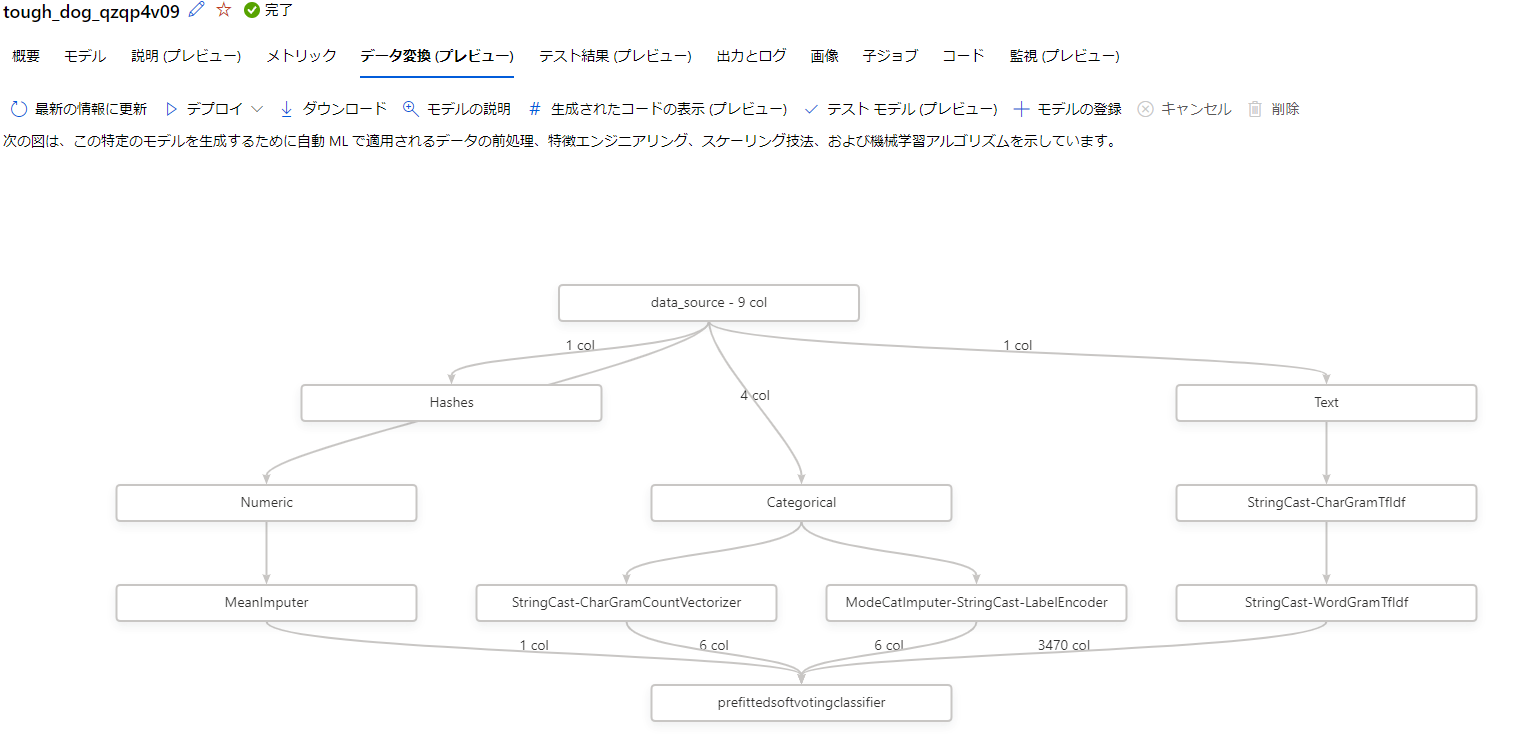
データ変換
データ変換タブではどのようにデータが処理されているかを可視化してくれています。
テスト結果
テスト結果タブではテストデータを用いた結果を可視化してくれています。
表示内容はメトリックと同じようですね。
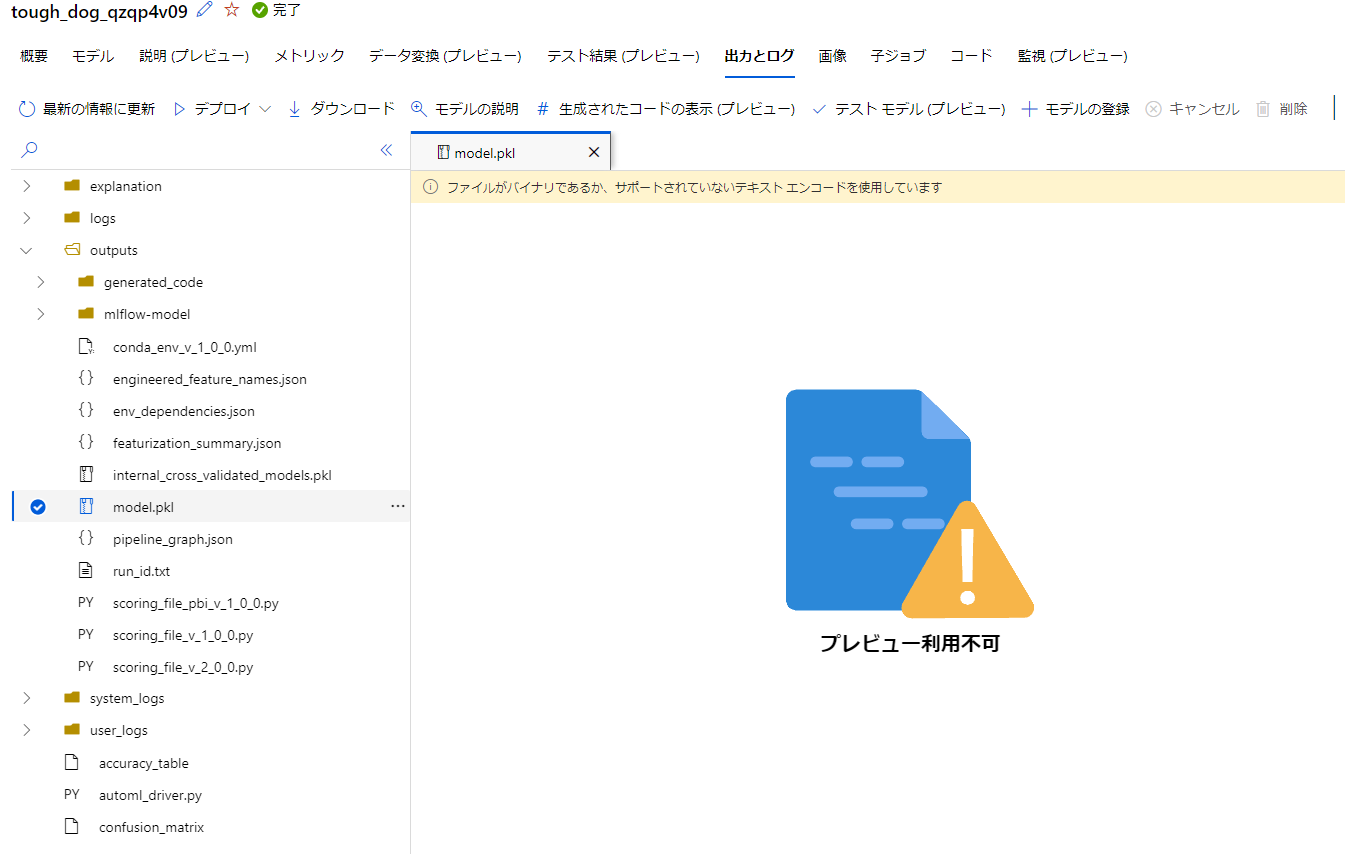
成果物
出力とログを確認してみたところ、model.pklというモデルファイルがありました。
このモデルが使えると思ったなら、これを利用して運用することができるのかなと思います。
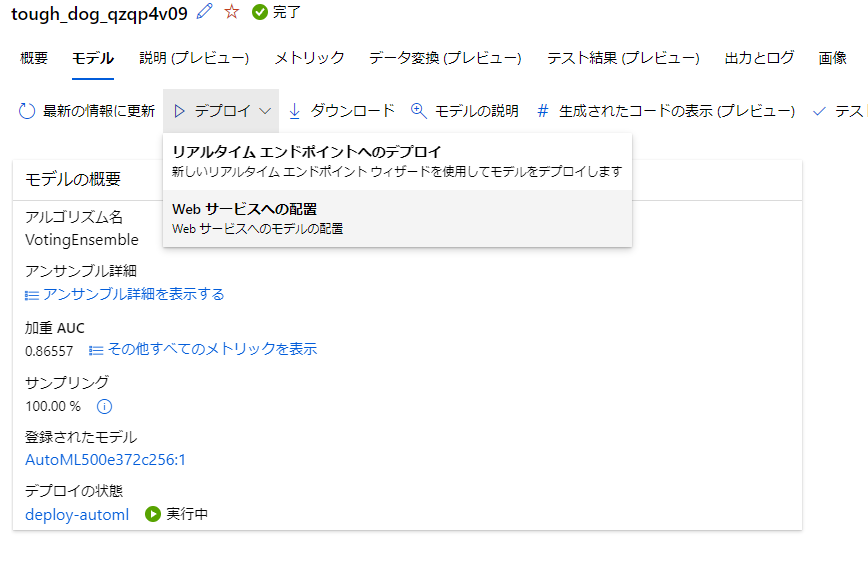
デプロイ
作成したモデルをデプロイします。
リアルタイムエンドポイントとwebサービスへの配置がありますが、今回はwebサービスへの配置を行ってみたいと思います。
モデルのページからデプロイを選択します。
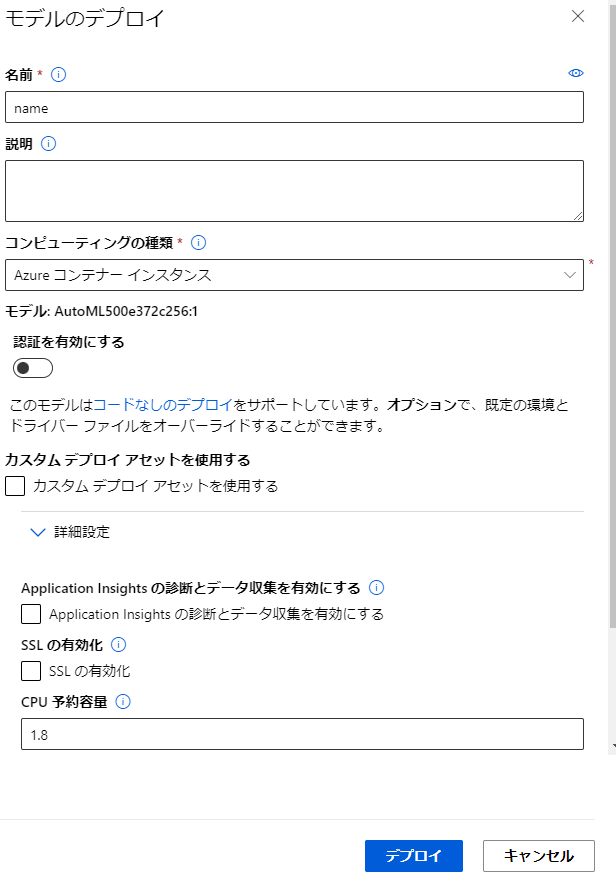
名前等の設定を行うとデプロイができます。
デプロイしたモデルのテストを行ってみます。
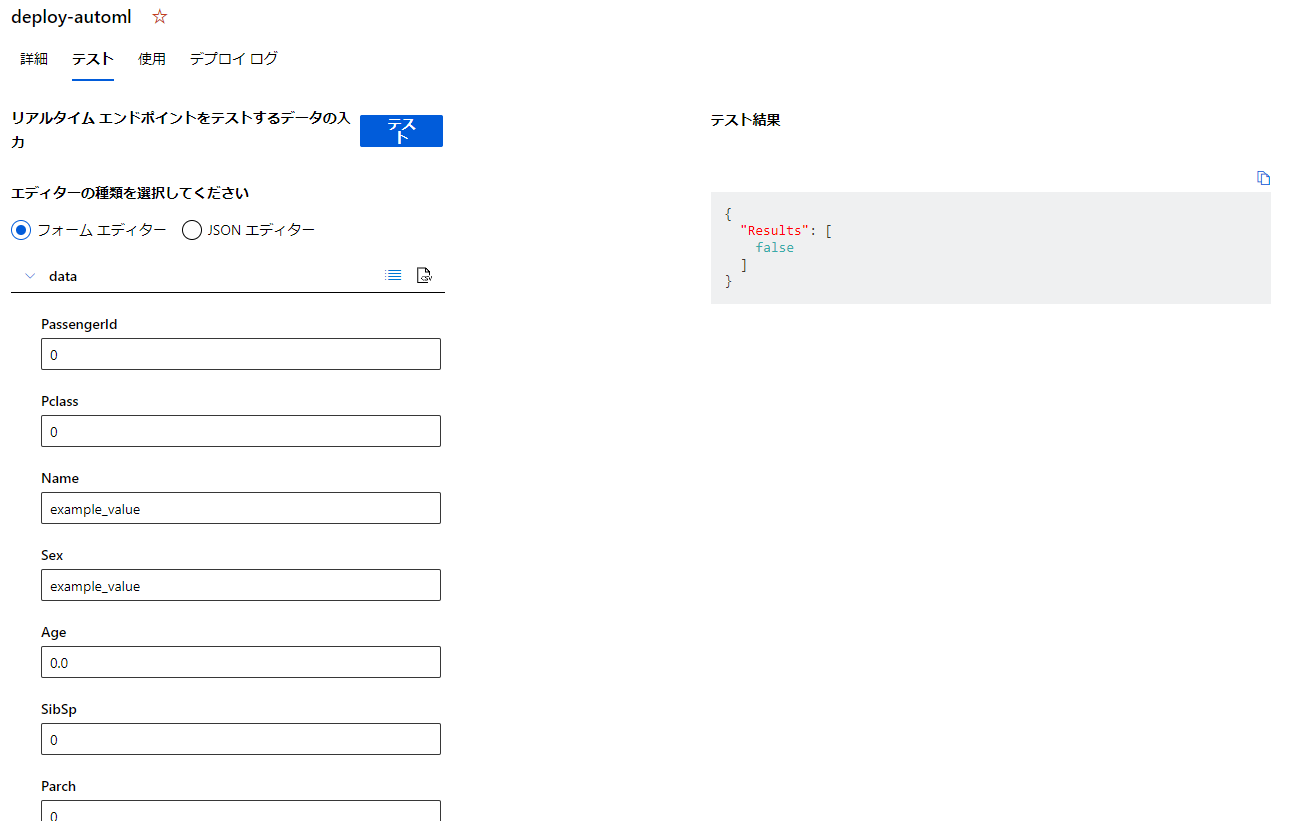
実行結果がjsonで帰ってきてますね。今回はfalseになったようです。
まとめ
今回はAutoMLをStudio上で実行してみました。
58個もモデルを作ってるためか時間はかかってしまいましたね。
このモデルの作成数についてですが、ジョブの作成時にタスクと設定の項目に追加の構成設定をする項目がありました。
中身を見てみると、終了の目標閾値や実行したいモデルの種類を選択できるようです。
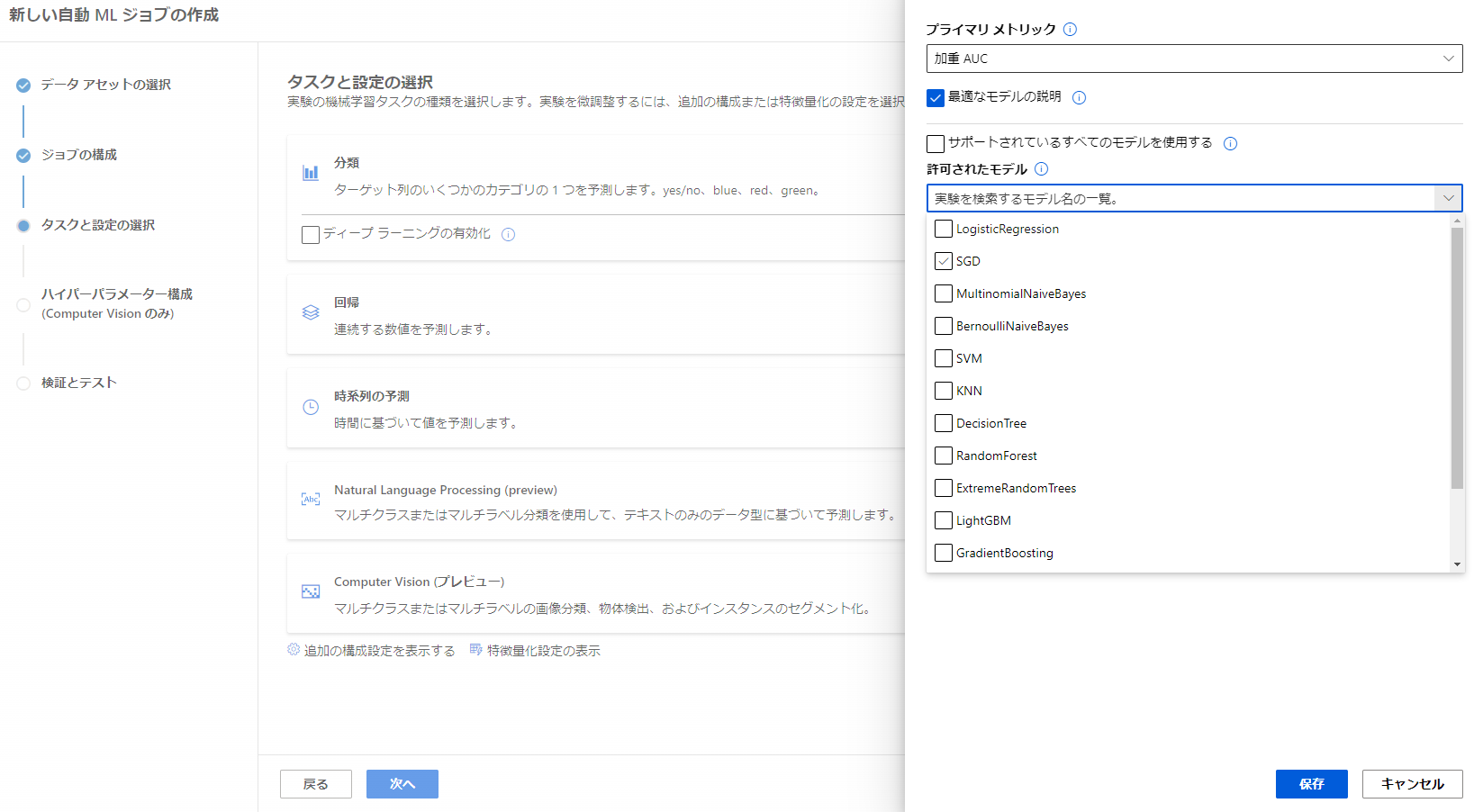
こちらを設定することで短時間で任意のモデルを確認することができるようになりますね。
次回はこれらをpythonから実行してみたいと思います。
