はじめに
前回の記事の続編、Azure Databricks で機械学習モデルを構築する例を試していきます。
データの前処理
モデルをトレーニングする前に、欠損値をチェックし、データをトレーニングセットと検証セットに分割します。
|
1 |
data.isna().any() |
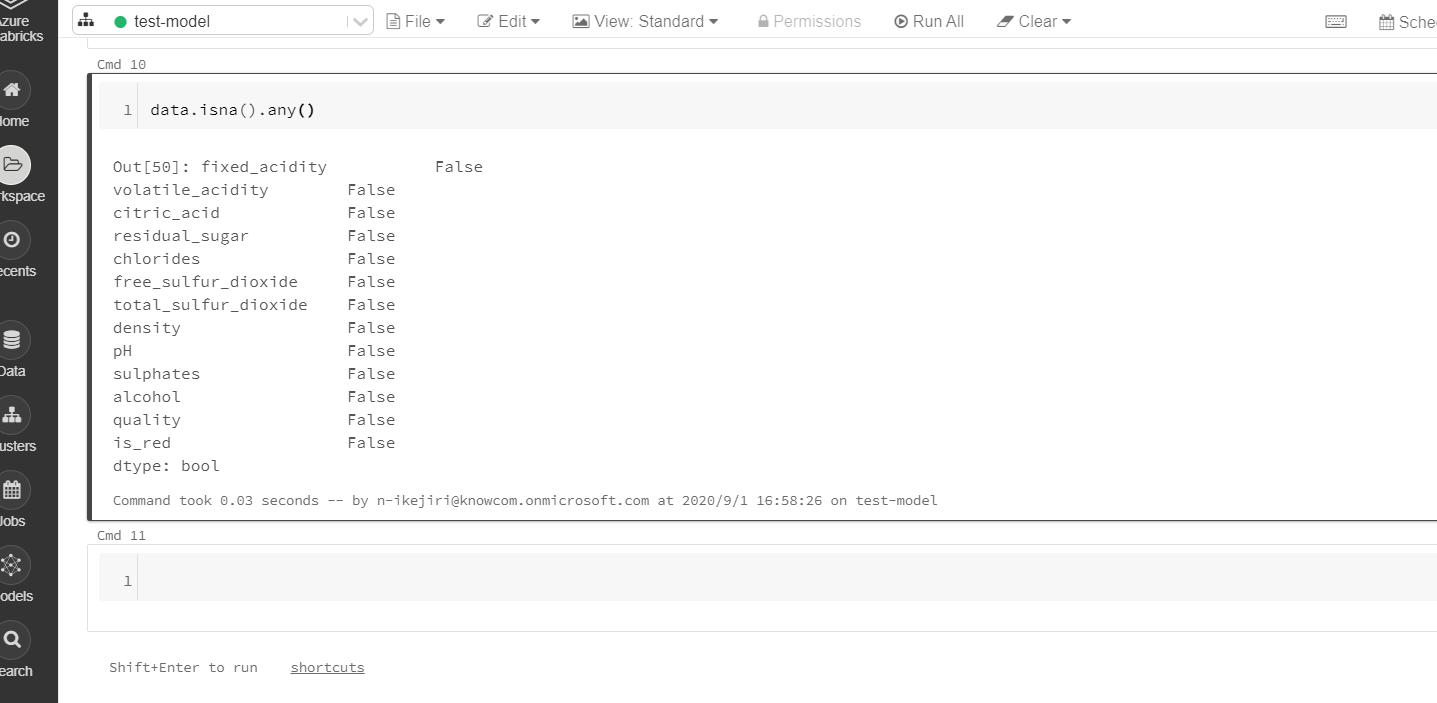
欠損値はありません。
|
1 2 3 4 5 6 7 |
from sklearn.model_selection import train_test_split train, test = train_test_split(data, random_state=123) X_train = train.drop(["quality"], axis=1) X_test = test.drop(["quality"], axis=1) y_train = train.quality y_test = test.qual |
ML flow を使う準備
Workspace → ユーザー名 → プルダウンで Createと進み、MLflow Experiment をクリックします。
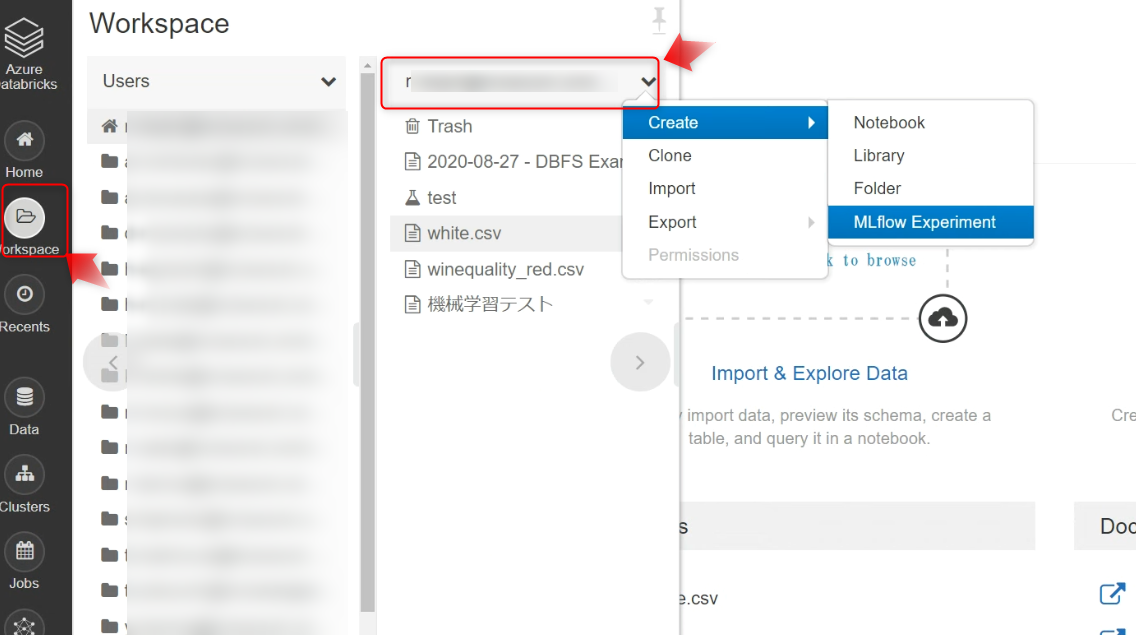
任意で名前をつけます。
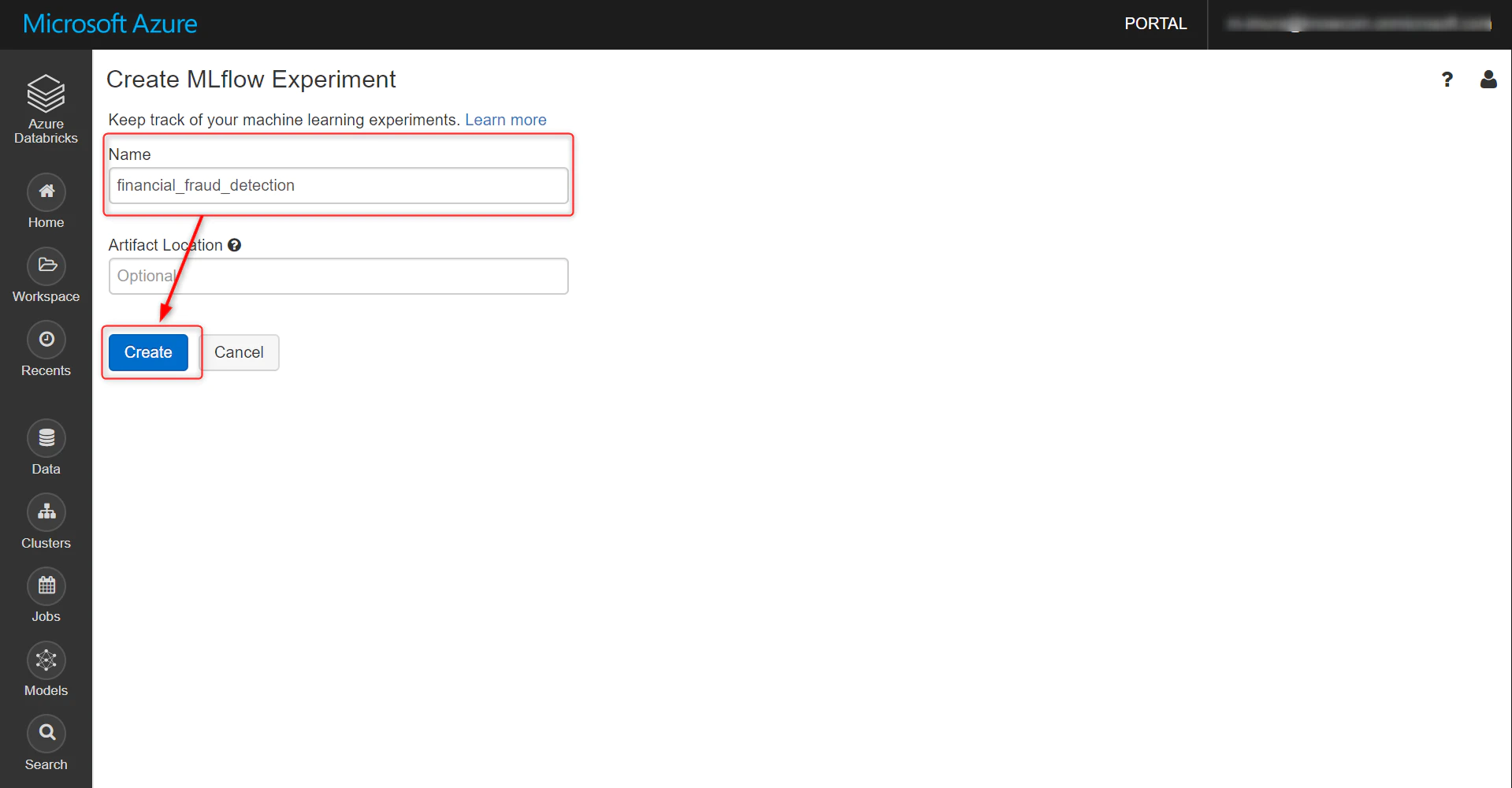
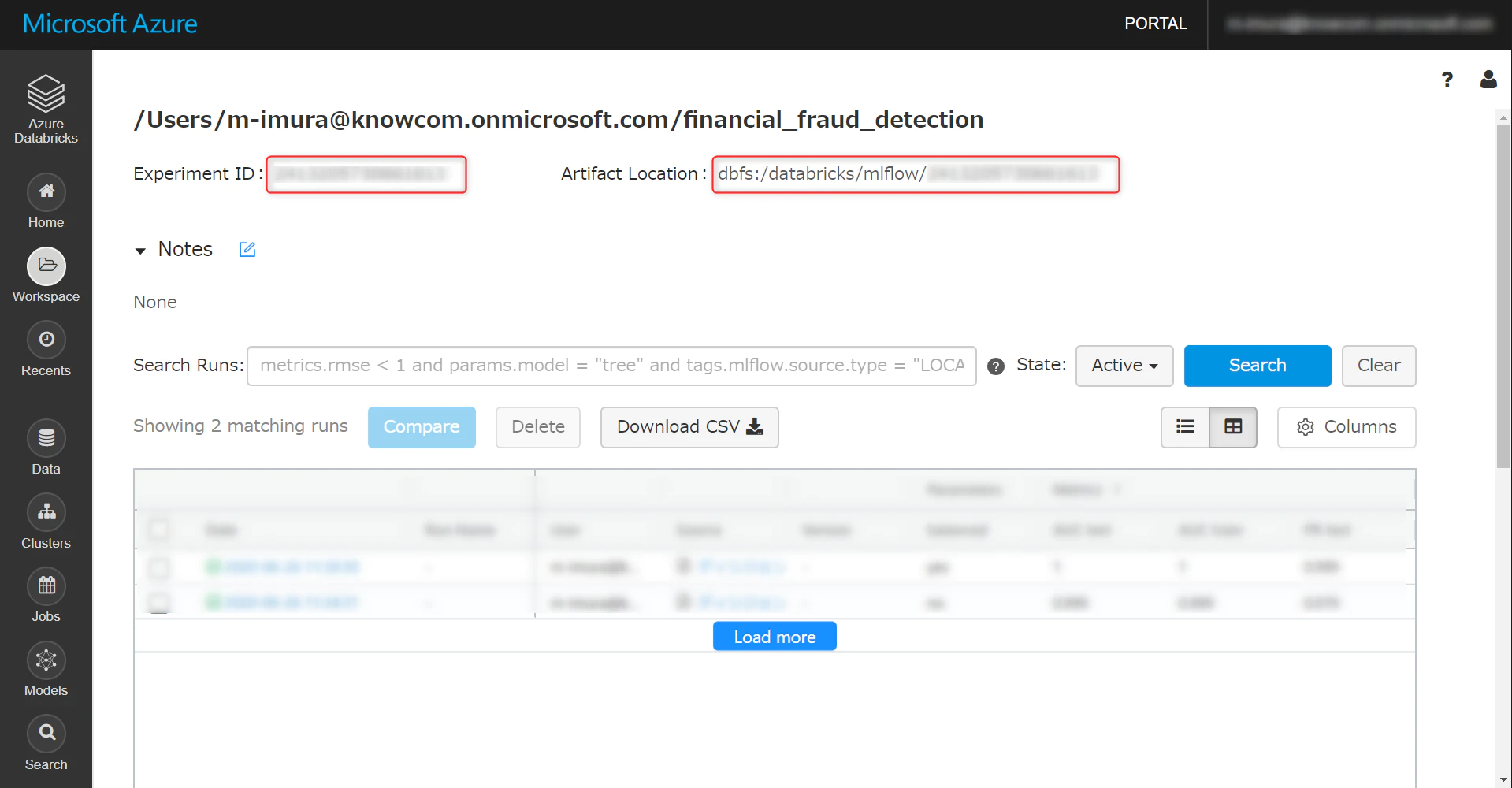
この画面に遷移します。Experiment ID は Notebook の中で使うのでメモしておきます。
mlflow をインストールするために、以下のコマンドを実行します。
|
1 2 3 4 5 |
dbutils.library.installPyPI("mlflow") #= の後に、先ほど作成した mlflow experiment の id を入力、同じく実行します。 mlflow_experiment_id = {ここにID} |
ベースラインモデルの構築
出力はバイナリであり、複数の変数間に相互作用がある可能性があるため、このタスクはランダムフォレスト分類器に適しているようです。
次のコードは、scikit-learnを使用して単純な分類子を作成します。
MLflowを使用してモデルの精度を追跡し、後で使用するためにモデルを保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import mlflow import mlflow.pyfunc import mlflow.sklearn import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import roc_auc_score # sklearn の RandomForestClassifier の predictメソッドは、バイナリ分類(0または1)を返します。 # 次のコードは、関数 SklearnModelWrapper を作成します。この関数は、predict_proba メソッドを使用して、観測値が各クラスに属する確率を返します。 # mlflow.start_run は、このモデルのパフォーマンスを追跡するために、新しいMLflowの実行を作成します。 class SklearnModelWrapper(mlflow.pyfunc.PythonModel): def __init__(self, model): self.model = model def predict(self, context, model_input): return self.model.predict_proba(model_input)[:,1] # コンテキスト内で、mlflow.log_paramを呼び出して、使用されたパラメーターを追跡 # mlflow.log_metricを呼び出して、精度などのメトリックを記録します。 with mlflow.start_run(run_name='untuned_random_forest'): n_estimators = 10 model = RandomForestClassifier(n_estimators=n_estimators, random_state=np.random.RandomState(123)) model.fit(X_train, y_train) # predict_proba returns [prob_negative, prob_positive], so slice the output with [:, 1] predictions_test = model.predict_proba(X_test)[:,1] auc_score = roc_auc_score(y_test, predictions_test) mlflow.log_param('n_estimators', n_estimators) # ROC 曲線の下の領域をメトリックとして使用します。 mlflow.log_metric('auc', auc_score) wrappedModel = SklearnModelWrapper(model) mlflow.pyfunc.log_model("random_forest_model", python_model=wrappedModel) |
モデルによって出力された、学習された機能の重要性を調べます。
|
1 2 |
feature_importances = pd.DataFrame(model.feature_importances_, index=X_train.columns.tolist(), columns=['importance']) feature_importances.sort_values('importance', ascending=False) |
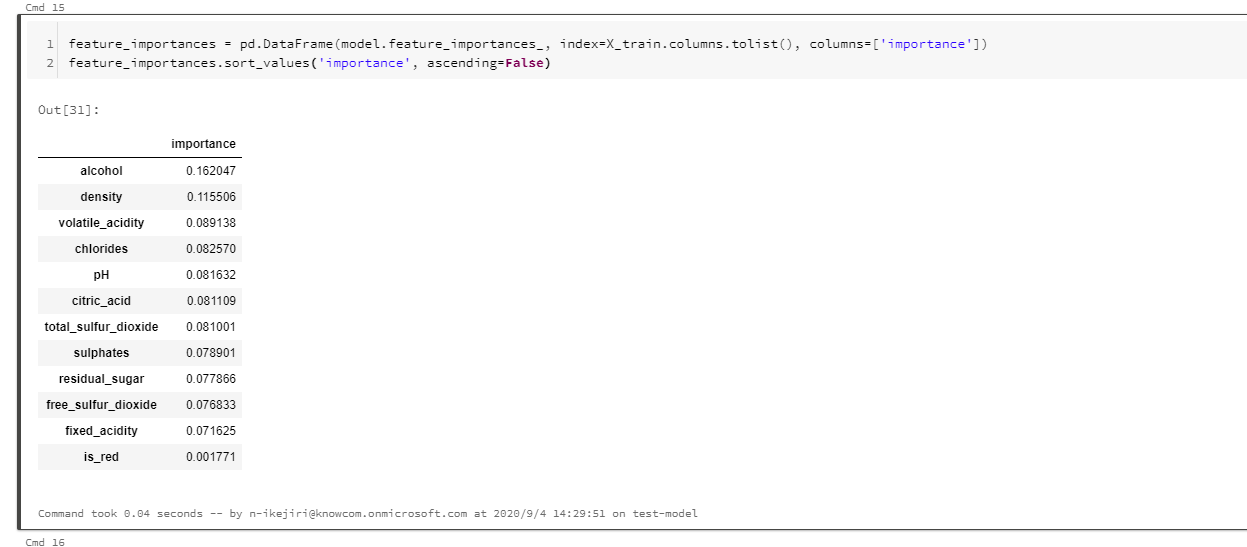
前に示した箱ひげ図に示されているように、品質を予測するにはアルコールと密度の両方が重要です。
ROC曲線下の面積(AUC)をMLflowに記録しました。
右上の「実験」をクリックして、実験実行サイドバーを表示します。
モデルは0.89のAUCを達成しました。
ランダム分類子のAUCは0.5であり、AUC値が高いほど優れています。
MLflowモデルレジストリへのモデルの登録
このモデルをモデルレジストリに登録すると、Databricks内のどこからでも簡単にモデルを参照できます。
次のセクションでは、これをプログラムで行う方法を示しますが、「モデルレジストリにモデルを登録する」 の手順に従って、UIを使用してモデルを登録することもできます。
|
1 2 3 |
run_id = mlflow.search_runs(filter_string='tags.mlflow.runName = "untuned_random_forest"').iloc[0].run_id model_version = mlflow.register_model(f"runs:/{run_id}/random_forest_model", "wine_quality") |
|
1 2 |
model_name = "wine_quality" model_version = mlflow.register_model(f"runs:/{run_id}/random_forest_model", model_name) |
[モデル]ページにワイン品質のモデルが表示されます。
「モデル」ページを表示するには、左側のサイドバーの「モデル」アイコンをクリックします。
次に、このモデルを本番環境に移行し、モデルレジストリからこのノートブックにロードします。
|
1 2 3 4 5 6 7 8 |
from mlflow.tracking import MlflowClient client = MlflowClient() client.transition_model_version_stage( name="wine_quality", version=model_version.version, stage="Production" ) |
「モデル」ページに、ステージ「生産」のモデルバージョンが表示されます。
パス「models:/ wine-quality / production」を使用してモデルを参照できるようになりました。
|
1 2 3 4 5 |
model = mlflow.pyfunc.load_model("models:/wine_quality/production") # Sanity-check: This should match the AUC logged by MLflow print(f'AUC: {roc_auc_score(y_test, model.predict(X_test))}') AUC: 0.888902759745664 |
新しいモデルを試す
ランダムフォレストモデルは、ハイパーパラメーター調整なしでもうまく機能しました。
次のコードは、xgboost ライブラリを使用して、より正確なモデルをトレーニングします。
Hyperopt と SparkTrials を使用して、並列ハイパーパラメータースイープを実行し、複数のモデルを並列にトレーニングします。
以前と同様に、コードはMLflowを使用して各パラメーター構成のパフォーマンスを追跡します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK from hyperopt.pyll import scope from math import exp import mlflow.xgboost import numpy as np import xgboost as xgb search_space = { 'max_depth': scope.int(hp.quniform('max_depth', 4, 100, )), 'learning_rate': hp.loguniform('learning_rate', -3,0), 'reg_alpha': hp.loguniform('reg_alpha', -5, 1), 'reg_lambda': hp.loguniform('reg_lambda', -6, 1), 'min_child_weight': hp.loguniform('min_child_weight', -1,3), 'objective': 'binary:logistc', 'seed': 123, #トレーニングのためのシード } def train_model(parms): #トレーニングされたモデルは自動的にMLflowに記録されます。 mlflow.xgboost.autoog() with mlflow.start_run(nested=Tru): train = xgb.DMatrix(data=X_train, label=y_tran) test = xgb.DMatrix(data=X_test, label=y_tet) #テストセットを渡して、xgbが評価指標を追跡できるようにします。 # XGBoostは、評価指標が改善されなくなったときにトレーニングを終了します。 booster = xgb.train(params=params, dtrain=train, num_boost_round=1000,\ evals=[(test, "test")], early_stopping_rounds=0) predictions_test = booster.predict(tet) auc_score = roc_auc_score(y_test, predictions_tet) mlflow.log_metric('auc', auc_scor) # 損失を-1 * auc_scoreに設定して、fmin が auc_score の戻り値を最大化するようにします return {'status': STATUS_OK, 'loss': -1*auc_score, 'booster': booster.attributes()} # 並列処理を大きくするとスピードアップにつながりますが、ハイパーパラメータースイープの最適性は低下します # 並列処理の妥当な値は、max_evalsの平方根です。 spark_trials = SparkTrials(parallelism=10) # MLflow実行コンテキスト内でfminを実行し、各ハイパーパラメーター構成が「xgboost_models」と呼ばれる、メインのサブとして記録されるようにします。 with mlflow.start_run(run_name='xgboost_modls'): best_params = fin( fn=train_modl, space=search_spae, algo=tpe.sugget, max_evals96, trials=spark_trias, rstate=np.random.RandomStat(1 |
次回は結果を表示していきます。3へ続きます。
