はじめに
今回は、2019年5月2日に Elena Boiarskaia 氏、 Navin Albert 氏、そして Denny Lee 氏によって投稿された「Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks」 の翻訳をまとめたものを紹介します。
本記事のリンクは下記参照で。
■リンク
Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks
Databricks 上で決定木と MLflow を用いた大規模な金融詐欺の検出
人工知能(AI) を使った大規模な不正パターンの検出はとても難しく、その理由は3つあります。
■3つの理由
- ふるいにかける履歴データの多さ
- 機械学習の発達とディープラーニングの技術の複雑さ
- 実際に起きた不正行為(動作)の例が少ない
更に、金融業界においてはセキュリティに対する懸念と AI を用いた不正行為の判別方法に対する説明が重要で、これが不正パターン検出に向けた作業をより難しくしてます。
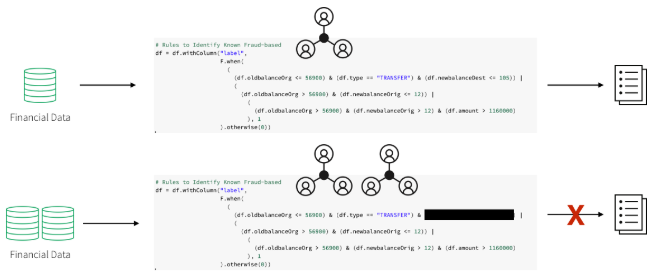
ドメインのエキスパートチームは、検出パターン構築のために詐欺師の一般的な行動をベースとしたルールを用意することとしました。ワークフローには、金融詐欺の分野におけるエキスパートがまとめた特定の動作の要件が含まれています。
データサイエンティストは利用可能なデータのサブサンプルを取得し、これらの要件や既存の詐欺の例を用いて、ディープラーニングや機械学習のアルゴリズムのセットを選択します。
検出パターンを本番で利用するにあたり、データエンジニアは主に SQL を用いてモデルを閾値を持つルールセットへと変換します。結果、金融機関は一般データ保護規則(GDPR)に準拠した、不正取引の特定につながる明確な証拠を提示することができますが、ハードコード化されたルールセットを用いた不正検知システムにも問題点はありました。
■問題点
- 不正パターンの変化に対するアップデートにとても時間がかかる
- 現在の市場で起きている不正行為の変化に即座に対応できない
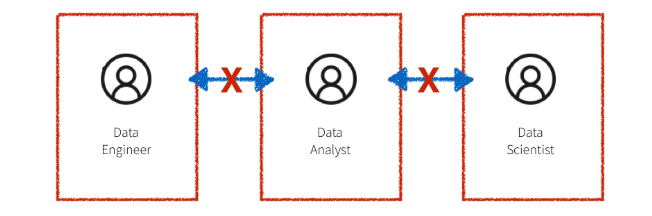
それに加えて、上述したワークフローのシステムはサイロ化されていることが多く、図のようにドメインエキスパート、データサイエンティスト、データエンジニアがすべて区画化されています。
データエンジニアは、大量のデータを管理し、ドメインエキスパートやデータサイエンティストの作業を本番レベルのコードに変換する役割を担っています。
共有のプラットフォームが無いため、ドメインのエキスパートとデータサイエンティストは、解析の為に1台のマシンに収まるサンプリングされたデータに頼るしかありません。これによってコミュニケーションが困難になるだけでなく、最終的には連携にも支障をきたします。
この記事では、以下の内容について紹介していきます。
- Databricks のプラットフォーム上の機械学習のユースケースに、様々なルールに基づいた検知のユースケースを変換する方法
- 大規模なデータセットからモジュール機能を構築するフレームワークを活用し、機械学習による不正検知データパイプラインを作成とリアルタイムでデータを可視化する方法
- 決定木と Apache Spark MLlib を用いた不正の検出方法と、モデルの精度向上のために MLflow を用いた反復処理と改良方法
機械学習を用いた解決
金融業界において、機械学習モデルは特定した不正ケースを正当化する方法が無い「ブラックボックス」な解決策を提供するものと考えられてきたため、機械学習モデルに対して消極的です。
GDPR の要件と金融規制により、データサイエンスの力を活用することは一見不可能に見えますが、大規模な不正行為の検出に機械学習を適用したことで、上述した多くの問題を解決できることを様々な成功事例が証明しています。
実際に確認された詐欺行為の事例が少ないため、金融詐欺の検出の為に、教師あり機械学習モデルをトレーニングするのは非常に困難です。しかし、特定の不正行為を識別する既存のルールセットの存在は、合成ラベルのセットと特徴量の初期セットの作成の手助けになります。
ドメイン分野のエキスパートによって開発された検出パターンの出力は、適切な承認プロセスを経て本番利用に使われる可能性があります。期待される不正行為フラグを生成するため、機械学習モデルをトレーニングするためのスタート地点として利用されることで、下記の3つの不安要素を解決できます。
■3つの不安要素
- トレーニングラベルの欠如
- 使用するモデルの選定
- モデルに適切なベンチマークを有しているかどうか
ルールに基づく不正行為フラグを認識するよう機械学習モデルをトレーニングすると、混同行列を介して期待される出力との直接比較ができます。結果がルールベースの検出パターンと厳密に一致している場合、このアプローチは機械学習ベースの不正防止に懐疑的な方々の信頼を得るのに役立ちます。
このモデルの出力は解釈がとても簡単で、元の検出パターンと比較した場合に予想される偽陰性、および偽陰性のベースラインの議論として役立つと思われます。
さらに、機械学習モデルの解釈が難しいという懸念については、初期の機械学習モデルとして決定木モデルが利用されれば、より緩和されると思われます。
■決定木モデルを利用するメリット
- モデルは一連のルールに沿ってトレーニングされているため、決定木は他のどの機械学習モデルよりも優れている可能性があるから
- モデルの最大限の透明性
モデルの透明性は、アルゴリズムに組み込まれた機能を理解することによって最終的に達成されます。解釈可能な機能があると、解釈可能で防御可能なモデル結果が得られます。
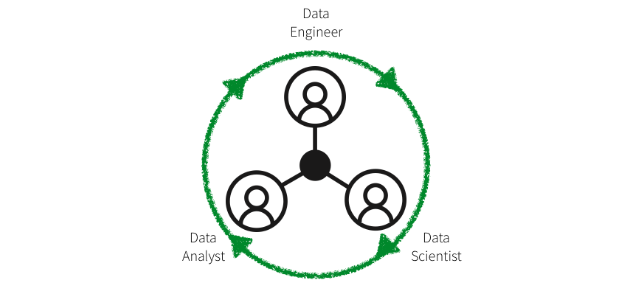
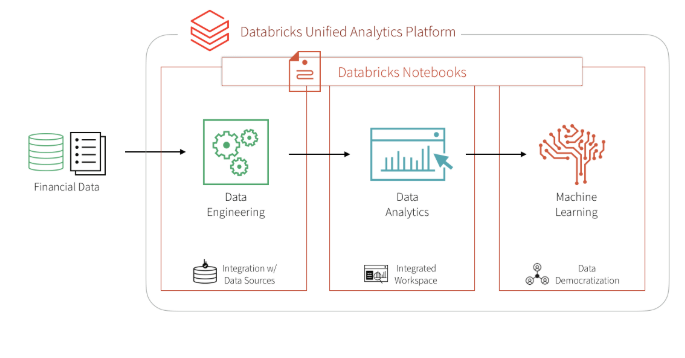
機械学習でアプローチすることの最大の利点は、最初のモデリング作業以降はモジュール化されたラベルや特徴量、あるいはモデルタイプセットのアップデートを短い時間でシームレスに生産可能という点です。ドメインエキスパート、データサイエンティスト、データエンジニアが同じデータセットを大規模に処理し、ノートブック環境で直接やりとりができる Databricks 統合分析プラットフォームによって、さらに促進されます。それでは、始めていきましょう。
データの取得と探索
この例では、合成データセットを使用します。
自分でデータセットを読み込む場合は、Kaggle からローカルにデータセットをダウンロードし、Azure 、または AWS にデータをインポートしてください。
以下の表は、PaySim のデータセット情報です。 PaySim のデータは、アフリカ諸国で実施されたモバイルマネーサービスの1ヶ月間の財務ログから抽出した実際の取引のサンプルをもとに、モバイルマネーの取引をシミュレーションしています。

データの探索
Databricks File System(DBFS)にデータをアップロードしたので、Spark SQL で素早く簡単に DataFrame を作成できます。

DataFrame を作成したので、スキーマと最初の1000行を見て、データを確認しましょう。

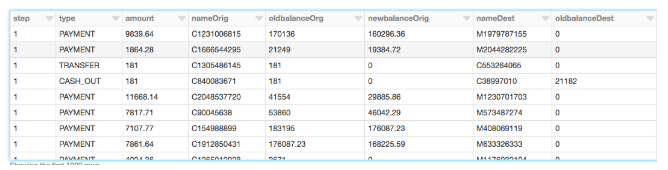
トランザクションの種類
データを可視化して、取引の種類と全体の取引量に対する貢献度を見てみましょう。
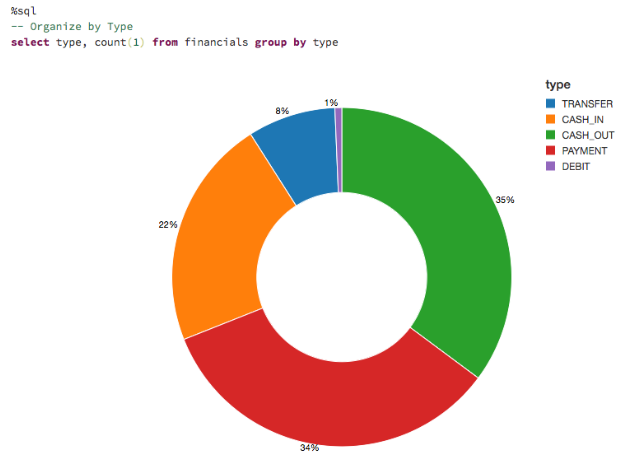
金額を把握するために、取引の種類や送金額への貢献度に応じたデータの可視化をします。
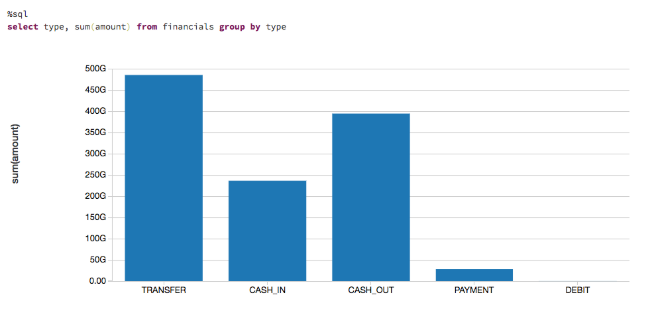
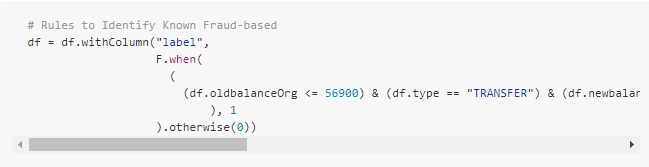
ルールベースのモデル
モデルのトレーニングに、既知の詐欺事件の大規模なデータセットから始めることは滅多に無いです。ほとんどの実用的なアプリケーションでは、不正検知パターンはドメインの専門家によって確立された一連のルールによって識別されます。ここでは、これらのルールに基づいて「label」と呼ばれるカラムを作成します。
ルールによってフラグ化されたデータの視覚化
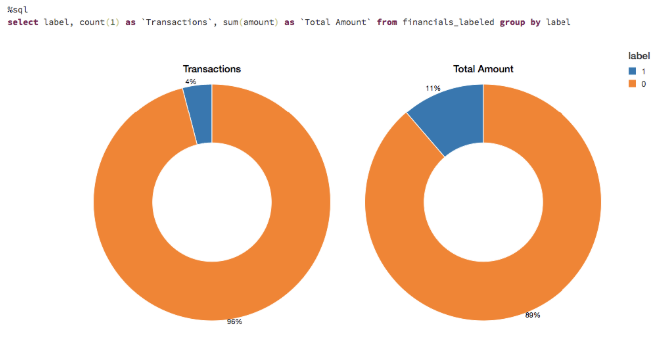
これらのルールは、非常に多くの不正ケースにフラグをよく立てます。フラグがついた取引数を可視化します。約4%のケースと、ドル総額の11%が不正行為としてフラグが付いてるのが分かります。
適切な機械学習モデルの選択
多くの場合、ブラックボックス化されたアプローチを使用してた不正検出は使用されません。
- ドメインの専門家は取引が不正であると識別された理由を理解できなくてはいけない
- 行動を起こす場合は、証拠を法廷に提出する必要がある
以上の理由から、決定木は簡単に解釈できるモデルであり、このユースケースの出発点として最適です。詳細については、意思決定ツリーに関するこのブログ 「The Wise Old Tree」 を参照ください。
トレーニングセットの作成
MLモデルを構築して検証するために、「.randomSplit」を用いて 80/20 の分割を行います。ランダムに選択されたデータの80%がトレーニング用に、残りの20%が結果の検証用に確保されます。

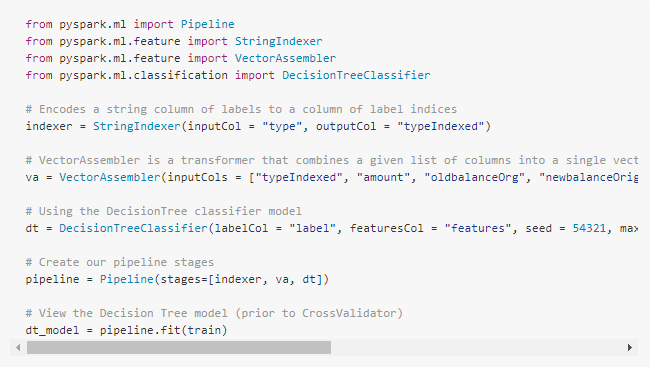
機械学習モデルのパイプラインの作成
モデルのデータを準備するために「.StringIndexer」を使用してカテゴリ変数を数値に変換します。次に、モデルに使用したい機能を全部組み立てます。決定木モデルに加えて、これらの特徴準備ステップを含むパイプラインを作成し、異なるデータセットでこれらのステップを繰り返すことができるようにします。
最初にパイプラインをトレーニングデータに適合させ、その後にそれを使用してテストデータを変換するので注意してください。
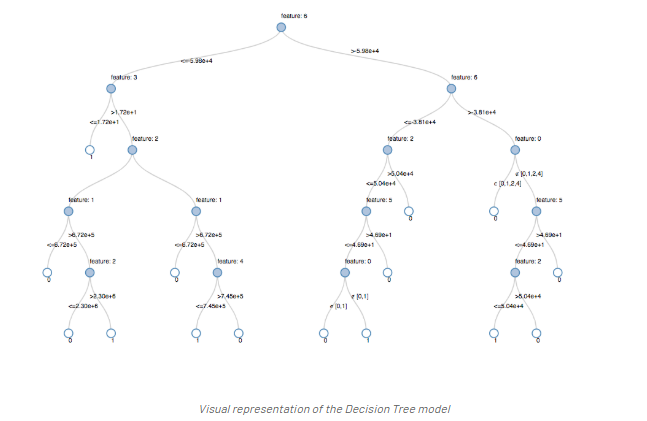
モデルの可視化
パイプラインの最後のステージである決定木モデルの「display()」を呼び出すことで、各ノードで選択された決定を持つ初期フィットモデルを表示できます。これは、アルゴリズムが結果の予測にどのように到達したかを理解するのに役立ちます。

モデルのチューニング
最適なツリーモデルが得られることを確認するために、いくつかのパラメーターのバリエーションを使用してモデルを相互に検証します。データが96%の陰性と4%の陽性のケースで構成されている場合、不均衡な分布の説明に、Precision-Recall(PR)評価指標を使用します。
モデルのパフォーマンス
モデルを評価するには、トレーニングセットとテストセットの精度再現率(PR)とROC曲線下の面積(AUC)メトリックを比較します。PR と AUC は共に非常に高いようです。
。
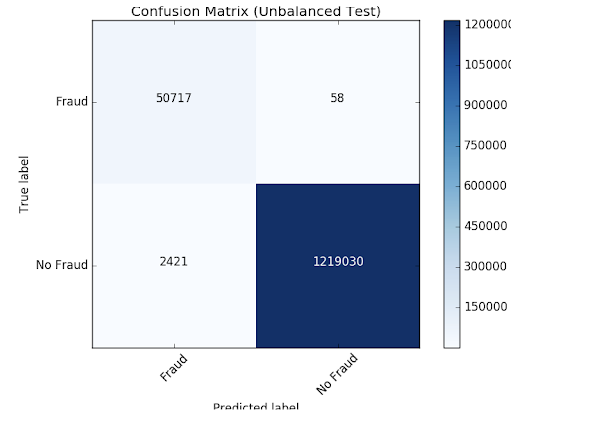
モデルがどのように結果を誤分類したかを見るために、matplotlib とpandas で混同行列を可視化します。
クラスの調整
可視化した結果、以下の事がわかりました。
- モデルが識別した元のルールよりも2421個も多くケースを識別している
- アルゴリズムによって検出されなかったが、もともと識別された58個のケースがある
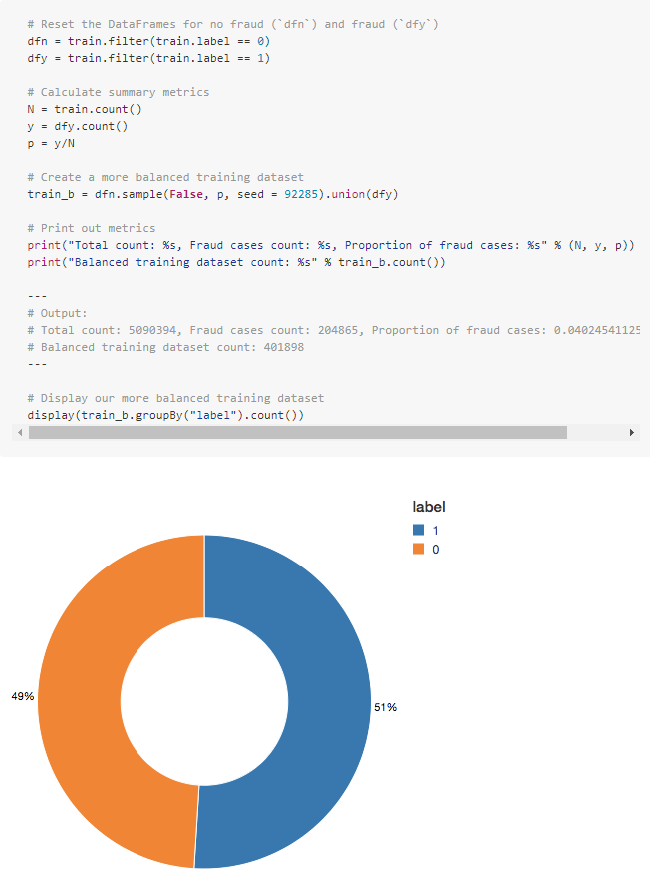
アンダーサンプリングを使用してクラスのバランスを取り、予測をより改善してみます。全不正ケースを保持し、不正ではないケースをダウンサンプリングしてその数と一致させ、バランスのとれたデータセットを取得します。
新しいデータセットを視覚化すると、イエスとノーのケースがほぼ 50/50 であることがわかります。
パイプラインのアップデート
次に、ML pipeline を更新して新しいクロスバリデータを作成します。ML pipeline を使用しているため、新しいデータセットで更新するだけで、同じパイプラインステップをすばやく繰り返すことができます。

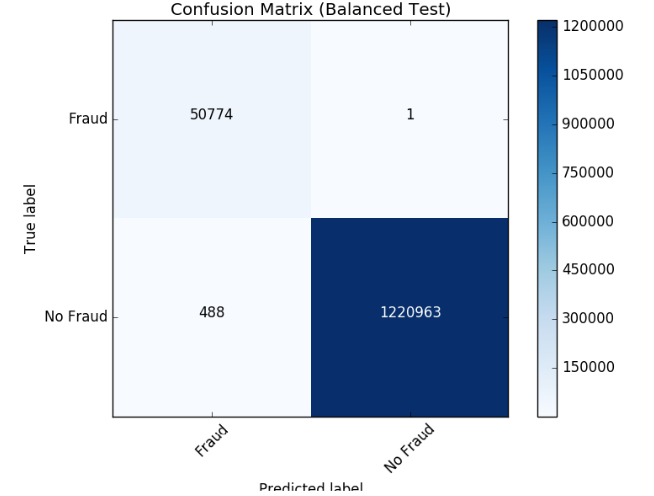
結果の確認
新しい混同行列の結果を見ると、モデルは1つの不正なケースのみを誤認しました。クラスのバランスを取ることで、モデルが改善されたようです。
モデルのフィードバックと MLflow の利用
生産用のモデルが選択されたら、フィードバックを継続的に収集して、モデルが引き続き対象の動作を識別していることを確認します。ルールベースのラベルから始めているので、人間のフィードバックに基づいて検証された真のラベルを将来のモデルに提供したいと考えています。
この段階は、機械学習プロセスの信頼と信頼を維持するために重要です。アナリストはすべてのケースをレビューすることはできないため、モデルの出力を検証するために、慎重に選択されたケースをアナリストに提示していることを確認します。例えば、モデルの確実性が低い予測は、アナリストが検討するのに適した候補です。このようなフィードバックが加わることで、モデルは変化する景色に合わせて改善・進化を続けていきます。
MLflow は、異なるモデルのバージョンを学習する際に、このサイクルを通じて助けてくれます。様々なモデル構成とパラメータの結果を比較しながら実験を追跡できます。例えば、MLflow UI を使用して、バランスの取れたデータセットと不均衡なデータセットで学習したモデルの PR と AUC を比較することができます。
データサイエンティストは、MLflow を使用して様々なモデルのメトリクスや追加の可視化や成果物を追跡することで、どのモデルを本番環境に導入すべきかの判断に役立てることができます。データエンジニアは、選択したモデルとトレーニングに使用したライブラリのバージョンを.jarファイルとして簡単に取得して、本番の新しいデータに展開することができます。
このように、モデルの結果をレビューするドメインエキスパート、モデルを更新するデータサイエンティスト、本番でモデルを展開するデータエンジニアの連携は、この反復プロセスを通じて強化されていきます。
結論
Databricksプラットフォームを使用する主な利点
- データサイエンティスト、エンジニア、ビジネスユーザーがプロセス全体でシームレスに連携できること
- データの準備、モデルの構築、結果の共有、モデルの本番環境への導入を同じプラットフォームで実行できる
- チーム全体に信頼が構築され、効果的で動的な不正検出プログラムに繋がる
わずか数分で無料の試用版にサインアップしてこの Notebook を試して頂き、独自のモデルを作成してみてください。
おわりに
Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks の翻訳まとめは以上です。
本記事にはより詳しく記載がされているのでそちらも参照ください。
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
