はじめに
データ分析プラットフォームである Databricks は、処理速度やコストの面において高く評価されており、欧米でのスタンダードサービスとなっています。
テーマ選定の背景としては
- 日本語の情報が少なかったり
- 技術難易度が高いレクチャーが多い
初心者にとってはまだまだハードルが高いのが現状です。
本連載がそのハードルを下げるものになれば幸いです。
本記事チュートリアルについて
- 公式ドキュメントでは、既存の異常検知ロジックをコードで記載
- その結果を正解ラベルに用いて、機械学習モデルを構築
本記事で利用するデータには通常/異常の判定情報が付与されています
(詳細は連載#2で触れます)。
そこでリモデルまでの流れの見通しをよくするために、本連載ではこれを正解ラベルとしています。
データ探索の一部に Azure Anomaly Detector
(時系列データから異常を見つけるマネージドAIサービス) を利用してみたり、
作成したモデル2種それぞれの使い方を考えてみたりと、アレンジを加えています。
個人的に Databricks の好きなところ
- 知識の共有がしやすい
- ユーザビリティを強く意識して作られている GUI
- 他のサービス (データベースとかBIツール) との連携性がいい
- モデルの利用や継続的な改善に至るまでの導線がスムーズ
これが結果的に下記に繋がると思います。
- 分析チームの生産性を上げやすくなる
- 学習コストが低い
チュートリアルの開始
モバイル決済のログデータから、各決済が正常取引か不正取引かを判定していきます。
ワークスペースの作成
以下の URL から Azure ポータルへログイン
https://azure.microsoft.com/ja-jp/
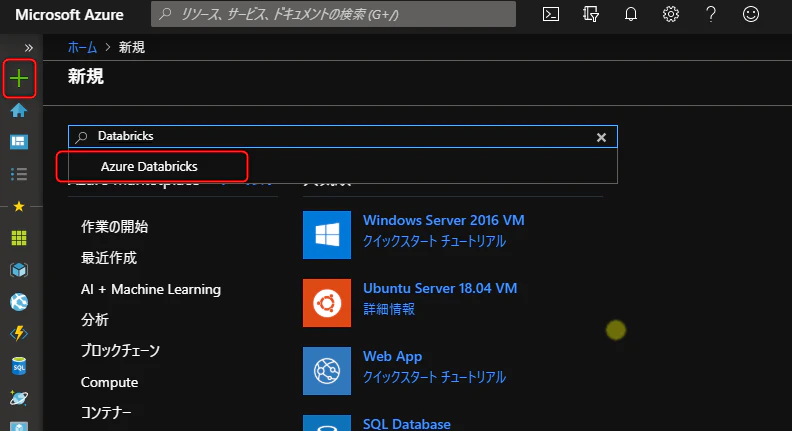
左上の+をクリックし、検索窓に Databricks と入力し、候補に出てきた Azure Databricks をクリック
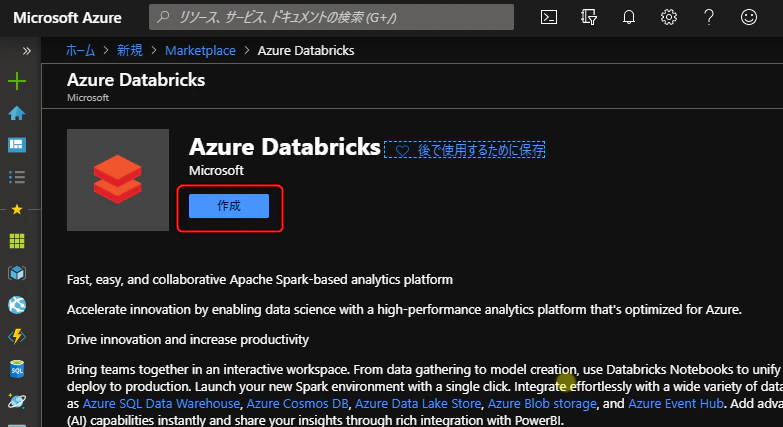
作成をクリック
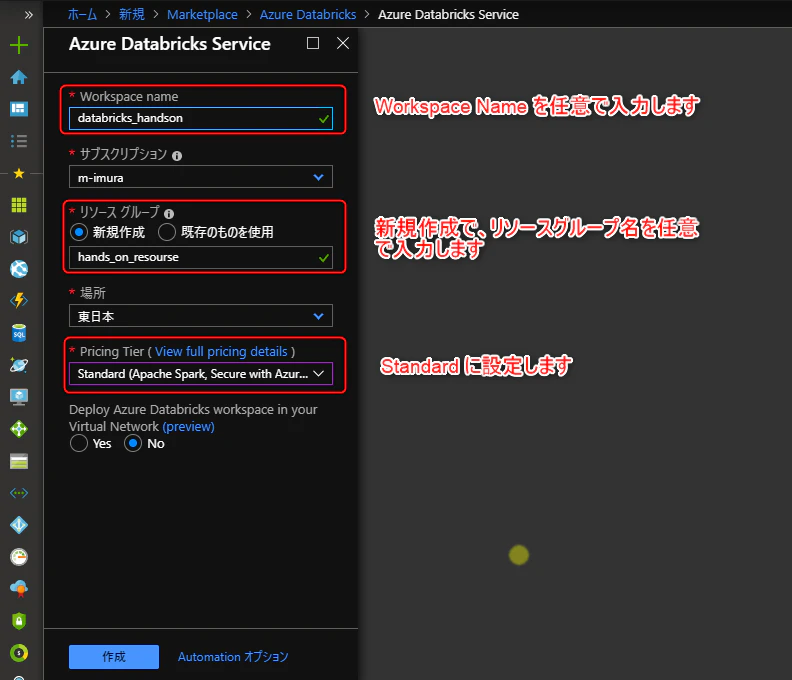
以下のようにワークスペースを設定、作成をクリック
(ワークスペースの展開に2-3分を要します)
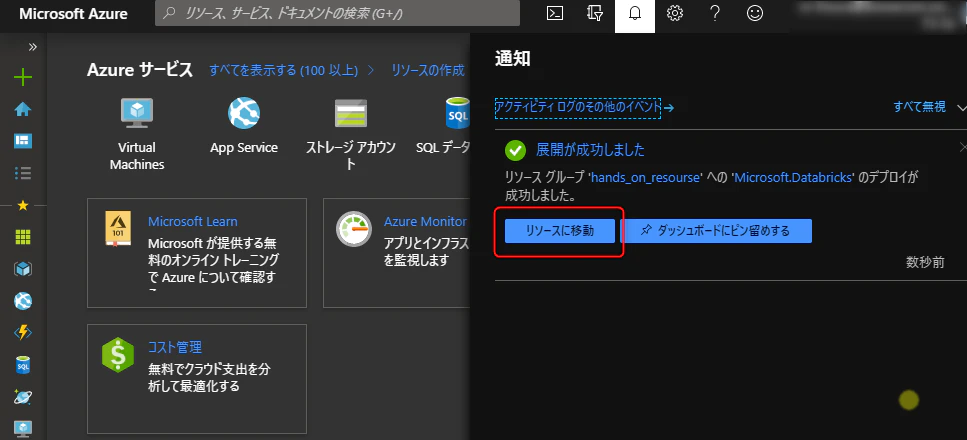
しばらくするとワークスペース展開完了の通知が届くので、リソースに移動をクリック
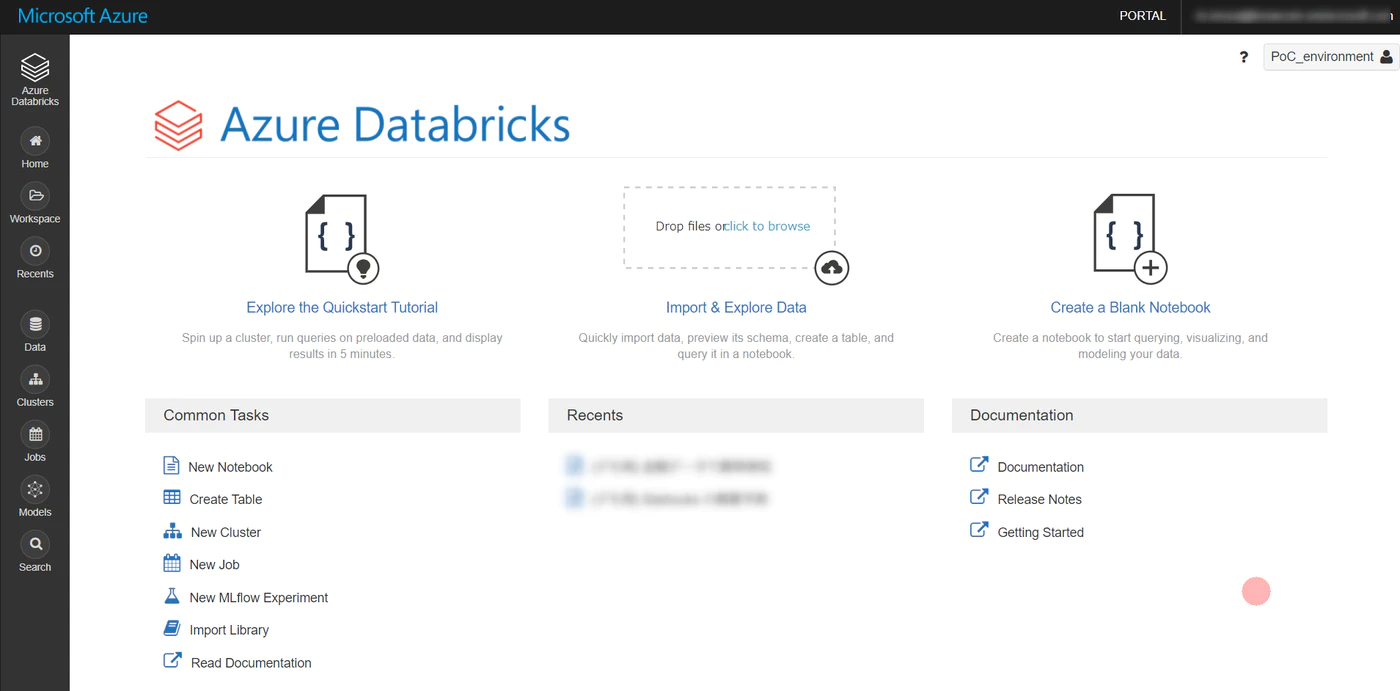
こちらの画面に遷移すればワークスペースの作成完了
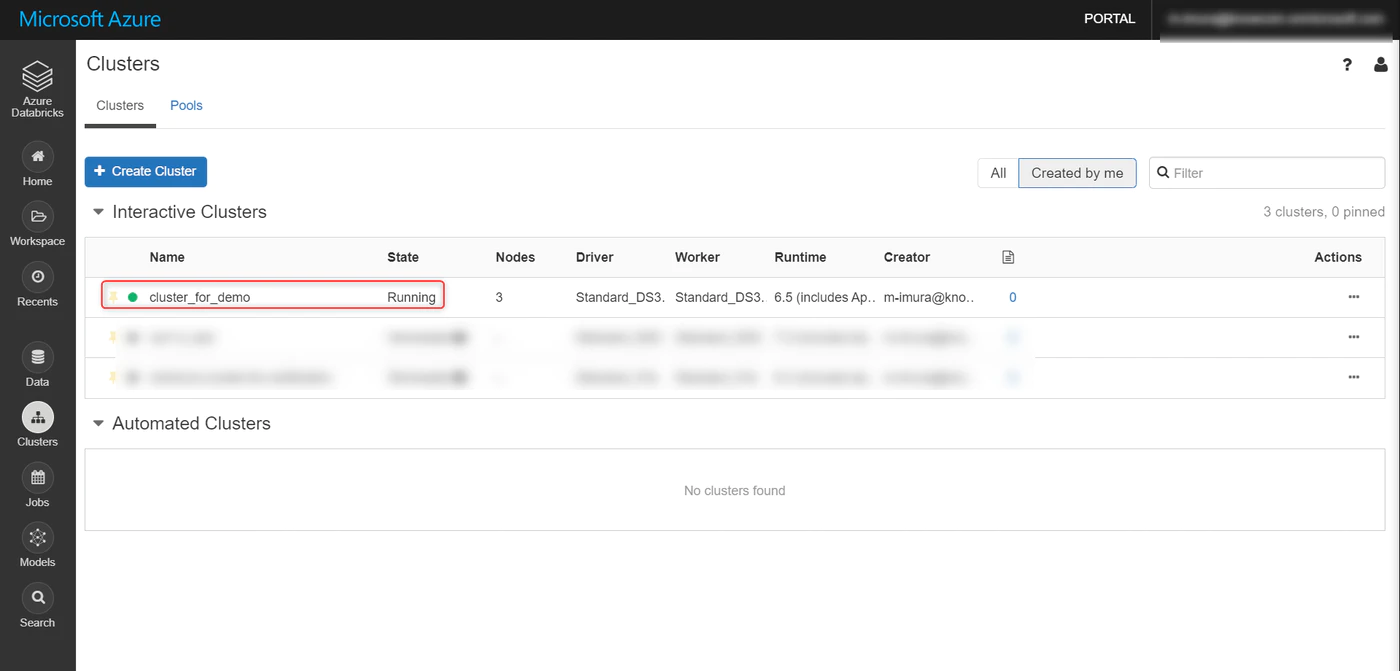
クラスタの作成
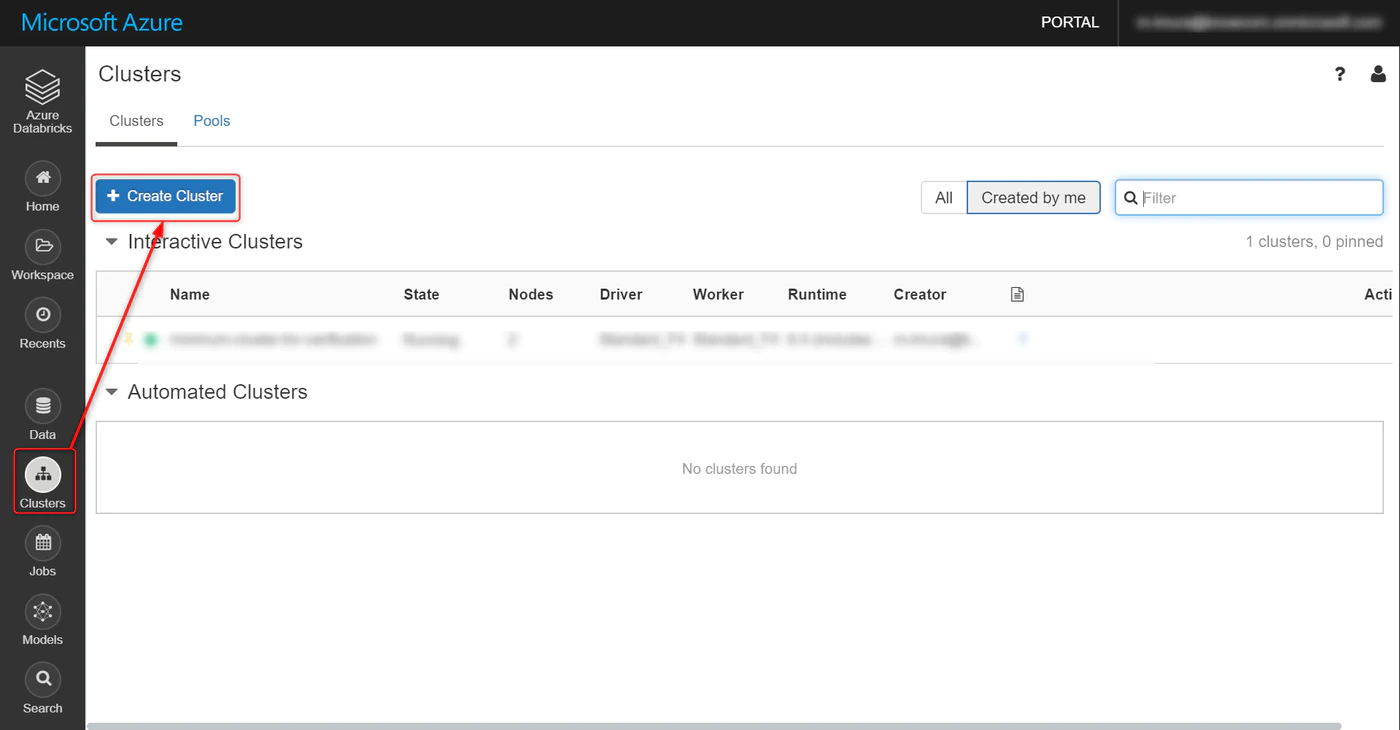
Cluster タブを選択し、Create Cluster をクリック
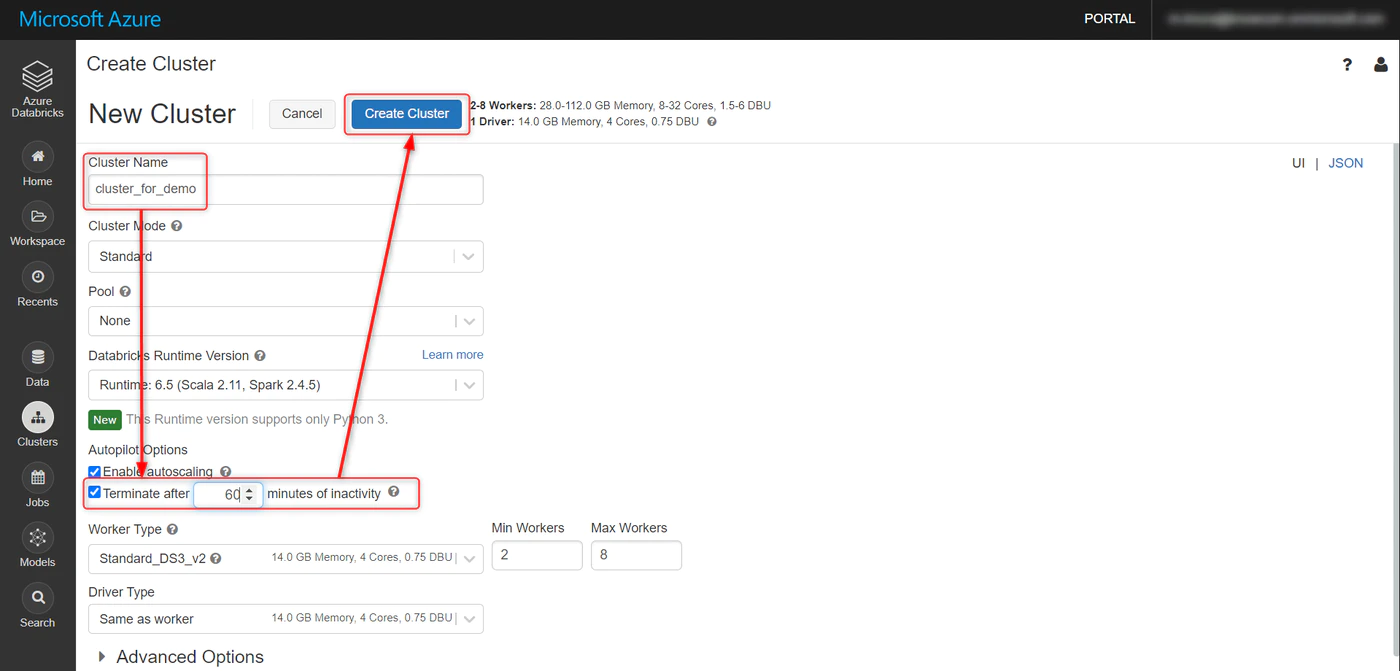
任意でクラスタ名を設定し、Creater Cluster をクリック
有償版であれば詳細を設定できます。
今回はオートターミネーションを 60分 に設定。
しばらく待つと Status が Running に。これで完了。
データのアップロード
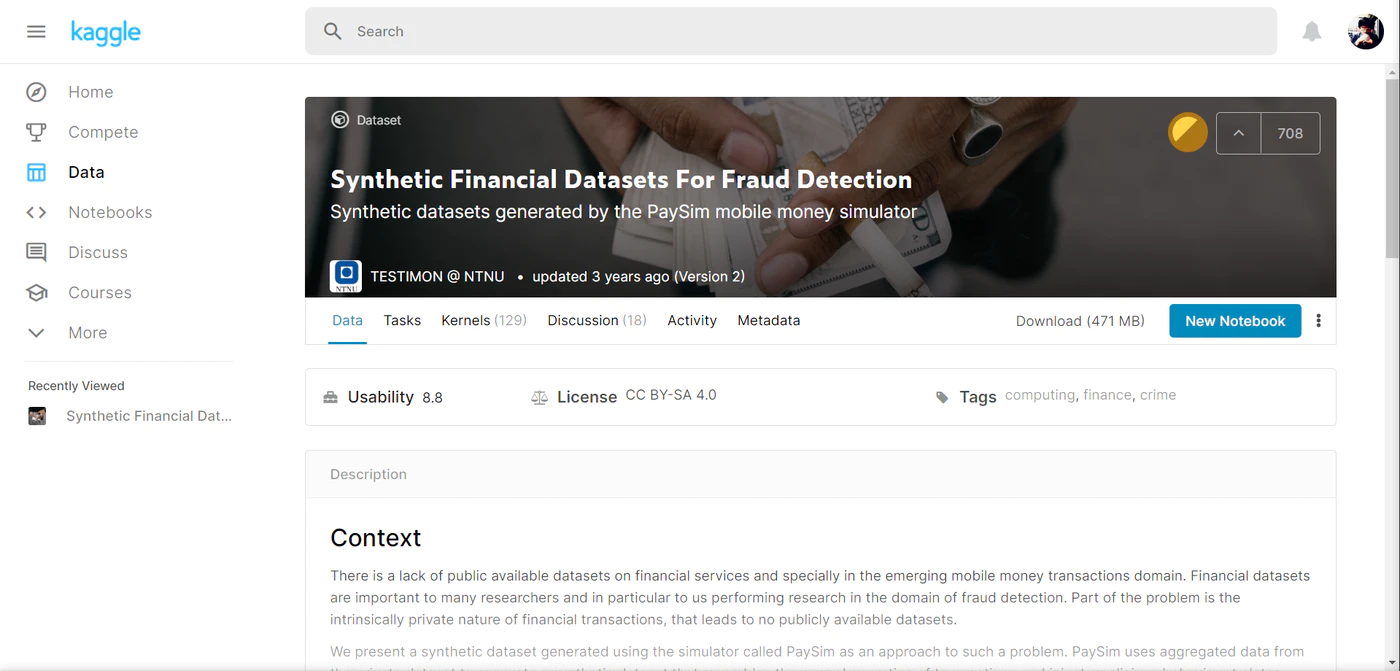
以下サイトからデータをダウンロードします。
※ Kaggle のユーザーアカウントが必要
Kaggle – Synthetic Financial Datasets For Fraud Detection
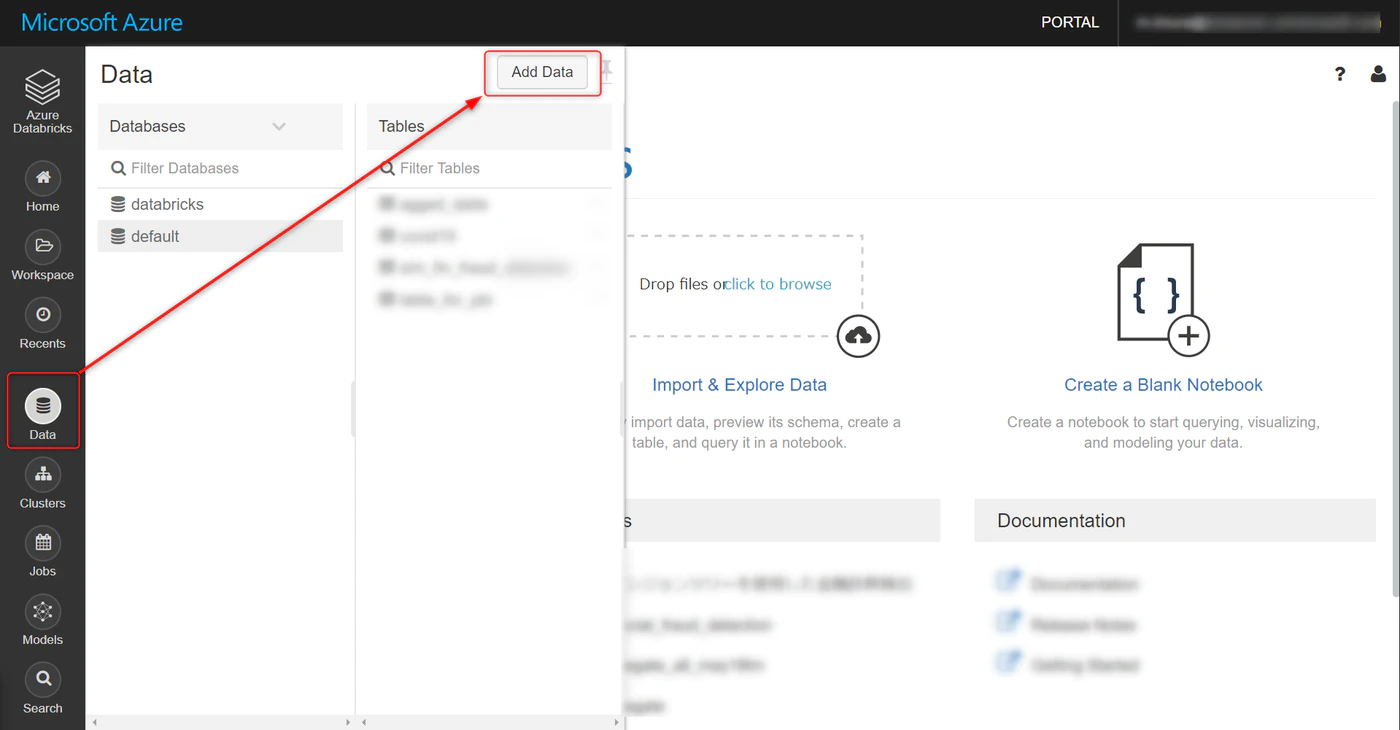
Data タブを選択し、Add Data をクリック
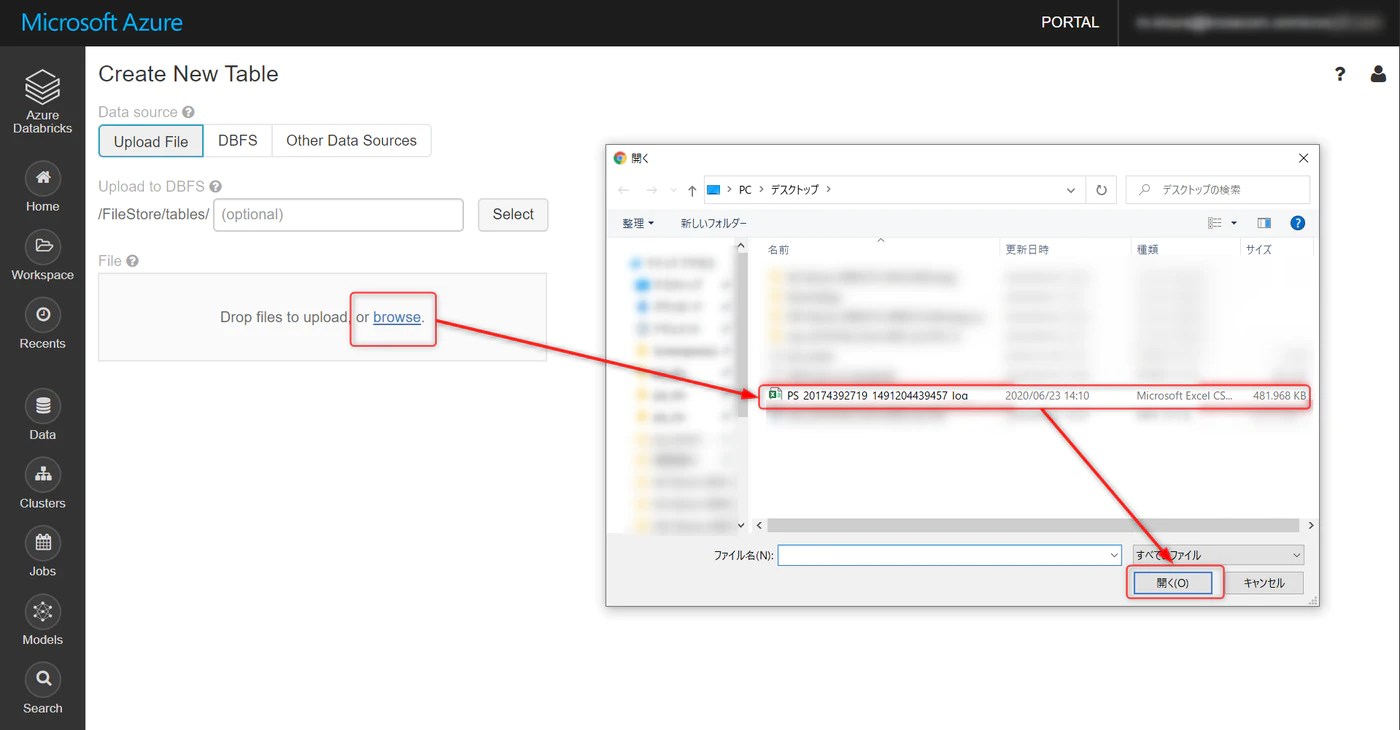
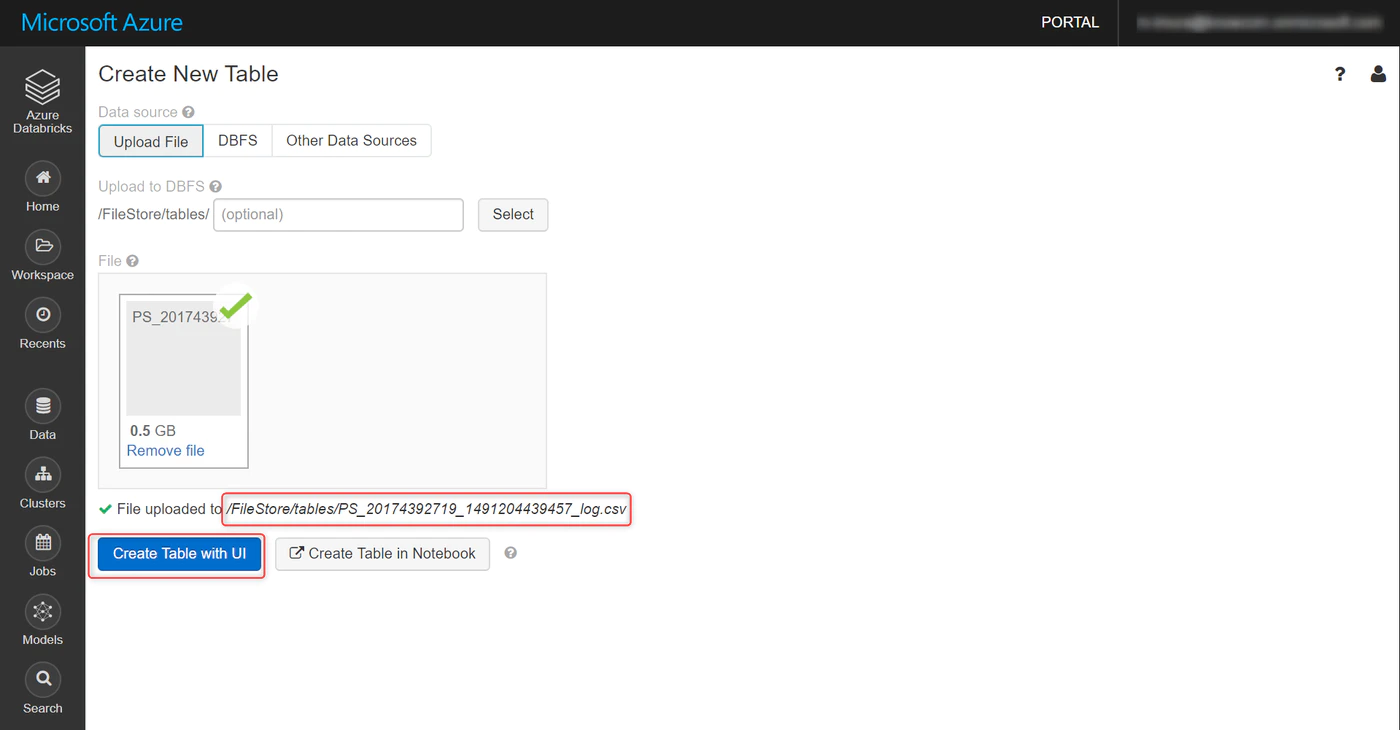
Upload File → browse と進み、ダウンロードしたファイルを選択
アップロードが完了するとこちらの画面に。
デフォルトでは File Store にデータが格納されます。
Create Table with UI をクリック
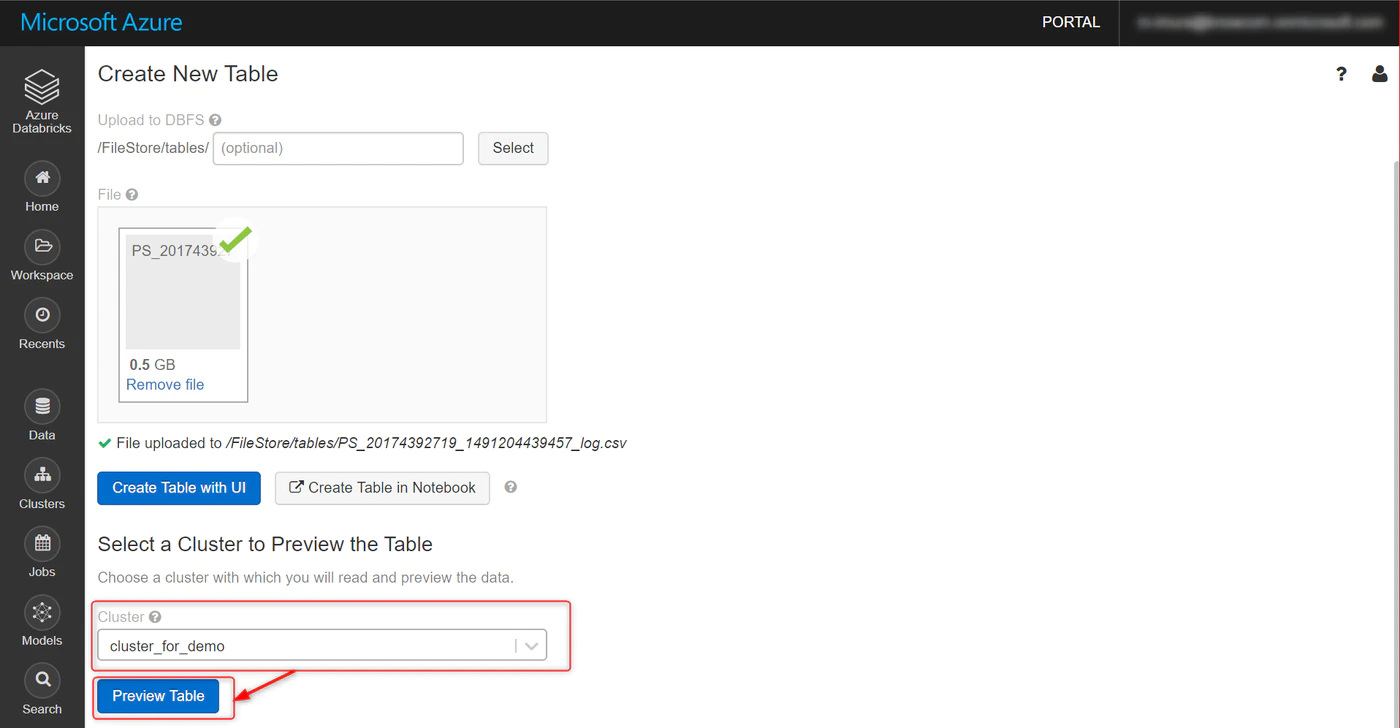
先ほど作成したクラスターを選択し、Preview Table をクリック
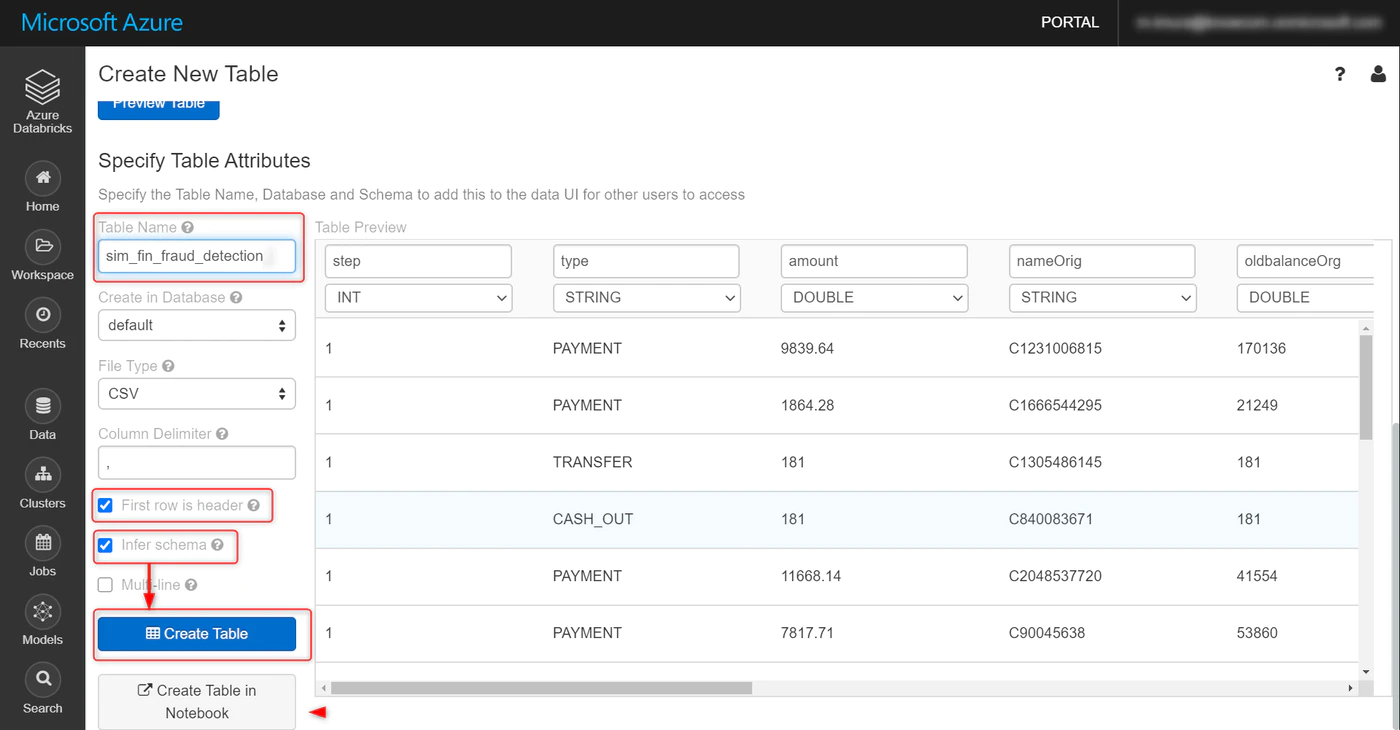
デフォルトではアップロードしたファイル名が、そのままテーブル名になっています。
これを sim_fin_fraud_detectionに変更します。
オプションは、First row is header (最初の行をカラム名として読み取り)と
Infer Schema (各カラムのデータ型自動類推)にチェックを入れ、
Create Table をクリック。
mlflow experiment 設定
機械学習のライフサイクル管理にとても便利な mlflow ですが、
今回はモデルの比較という用途に絞って最低限の設定を行います。
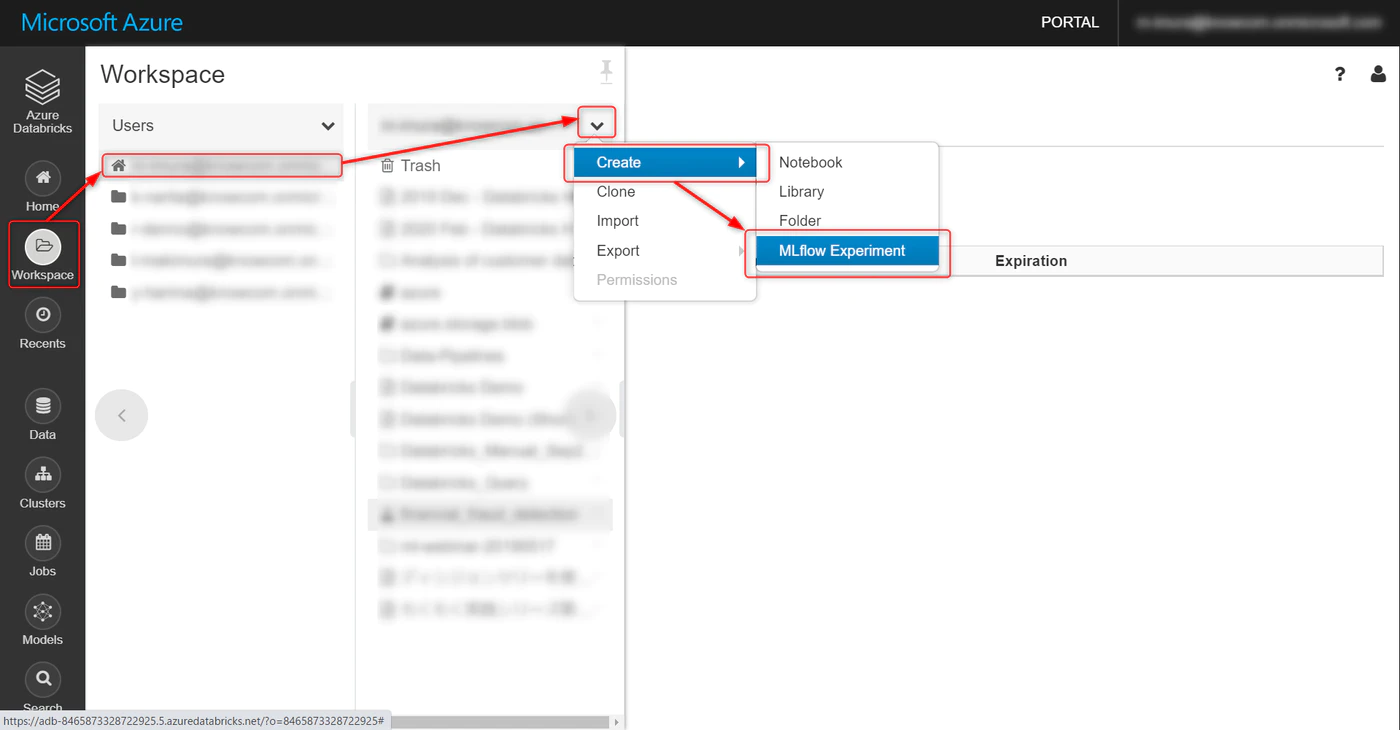
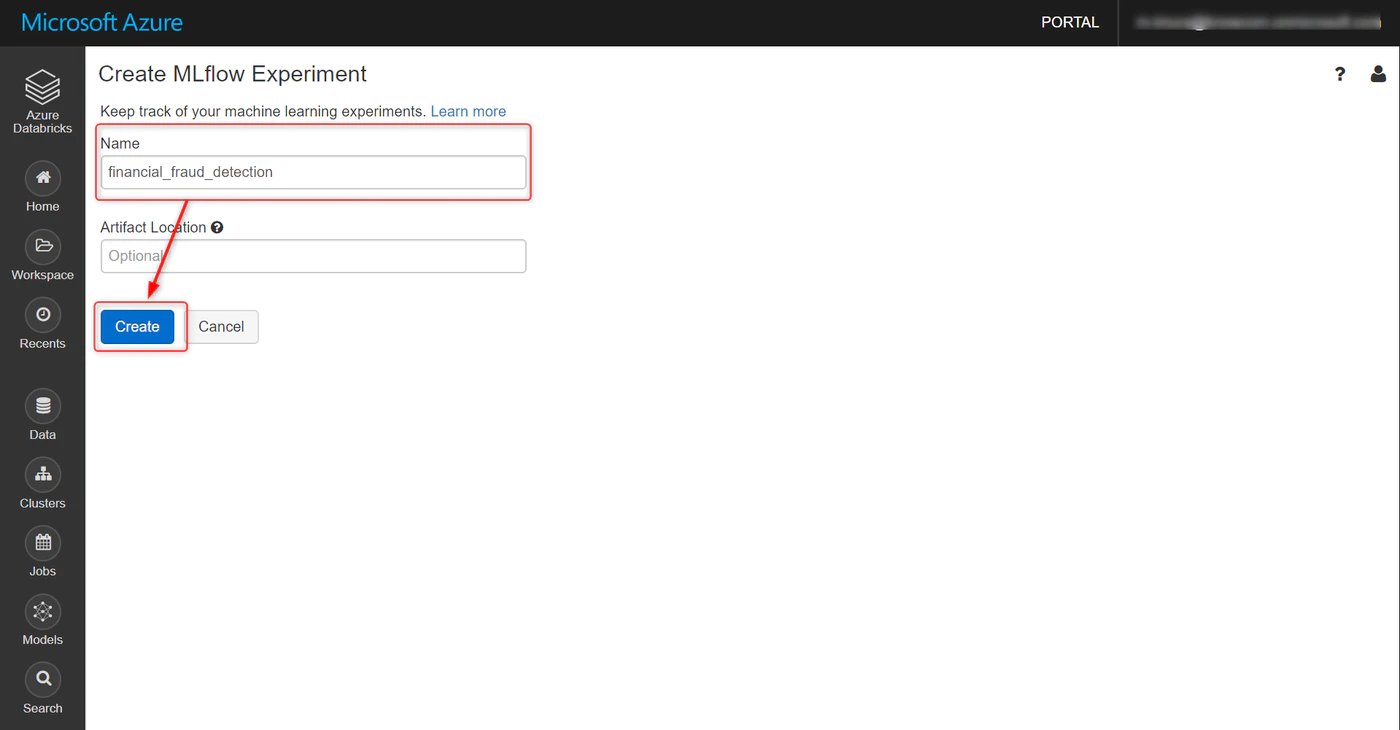
Workspace → ユーザー名 → プルダウンで Createと進み、MLflow Experiment をクリック
名称を任意で指定、Create をクリックします。
Artifact Loacation は特別に指定しなくてOK
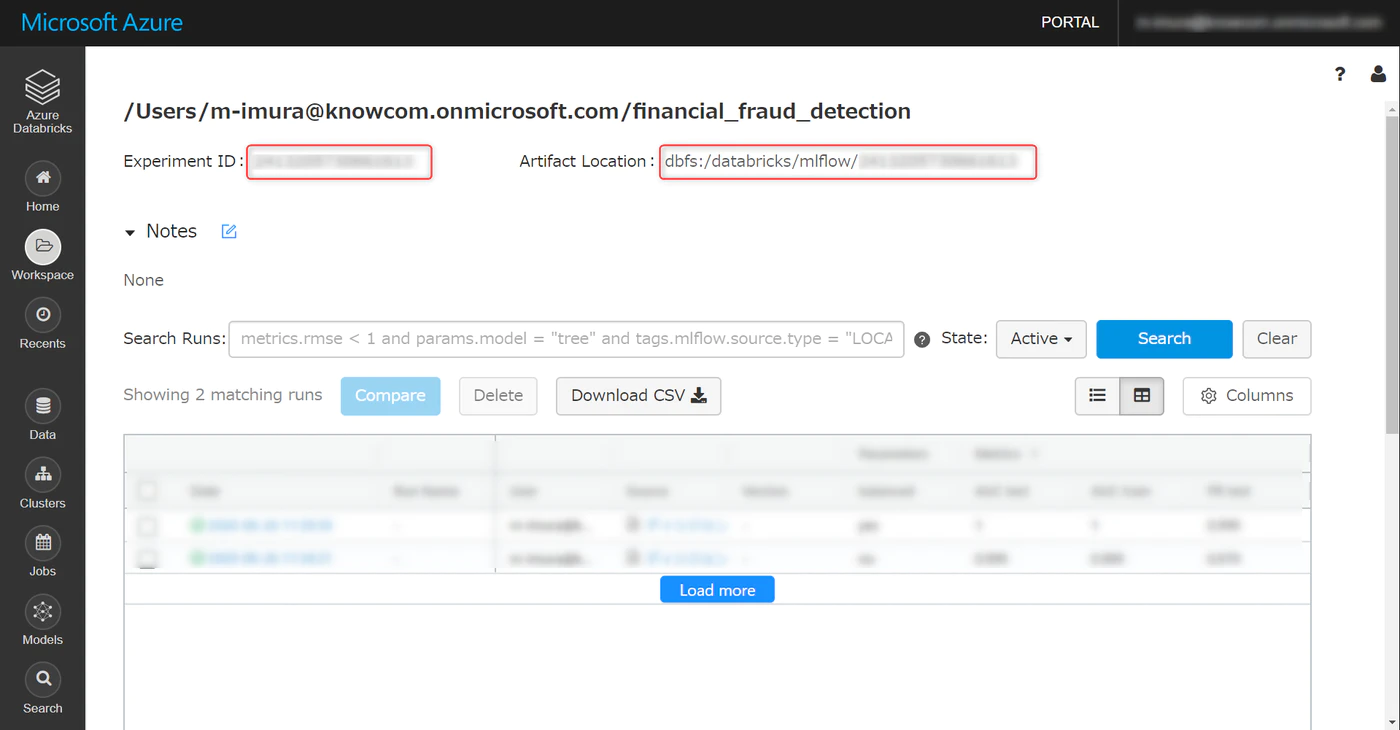
以下の画面に遷移します。
Experiment ID は Notebook の中で使うのでメモしておきます。
Collaborative Notebook 作成
実際にコードを記載して分析ロジックをくみ上げたり、その中にメモを残したりする Collaborative Notebook を作成します。
使い勝手は Jupyter Notebook にかなり近いです。
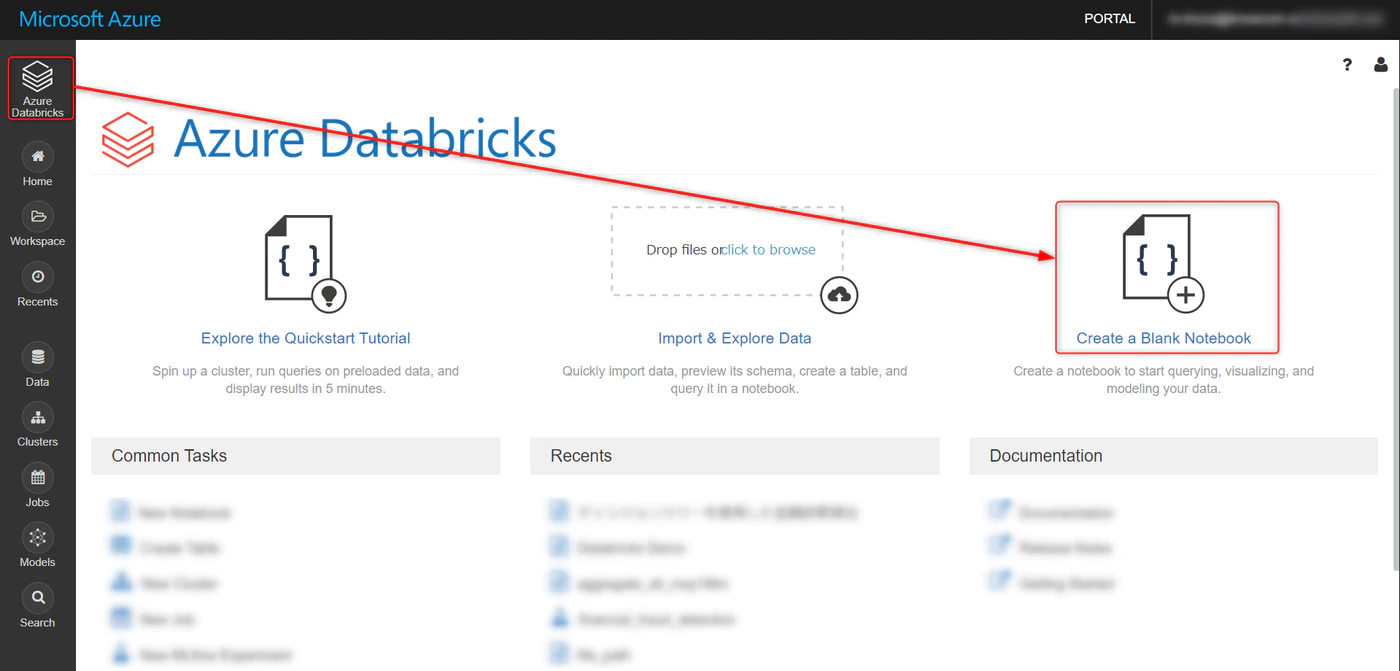
トップ画面から、Create a Blank Notebook をクリック
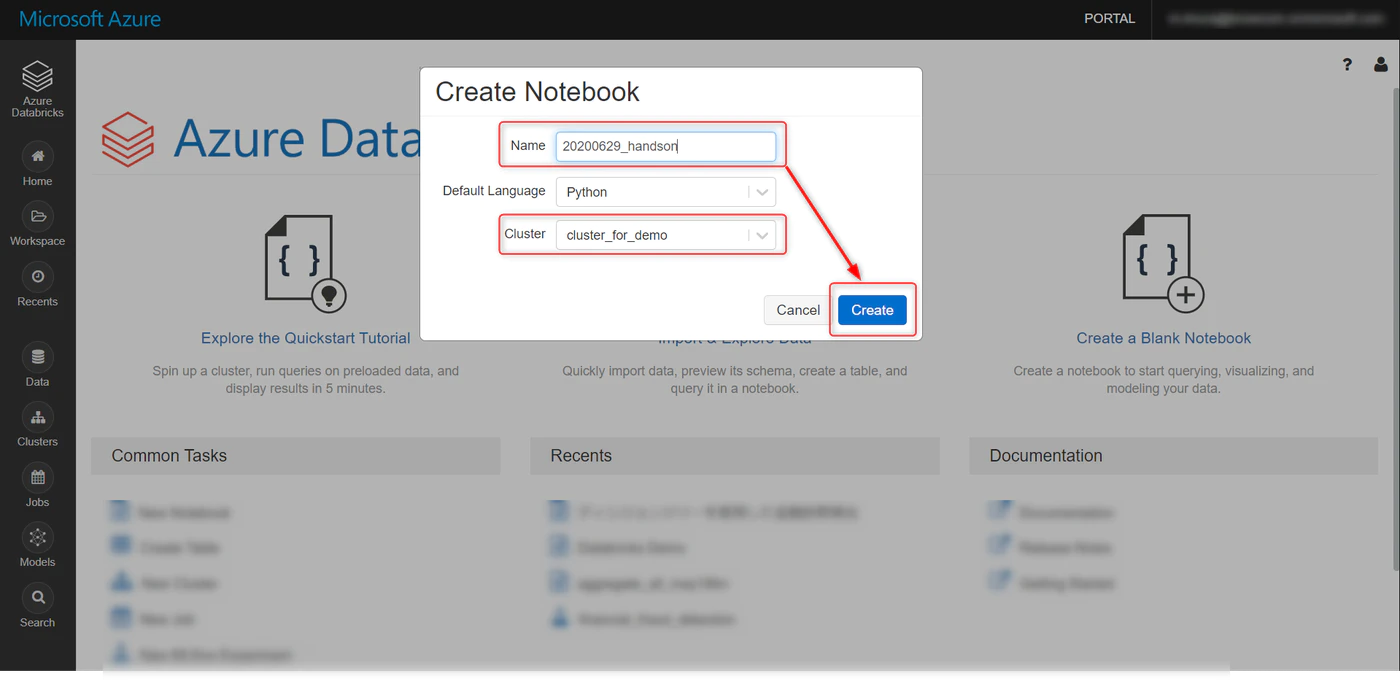
任意で名称を変更、作成したクラスタを選択して、Create をクリック
以下の画面になればOKです。
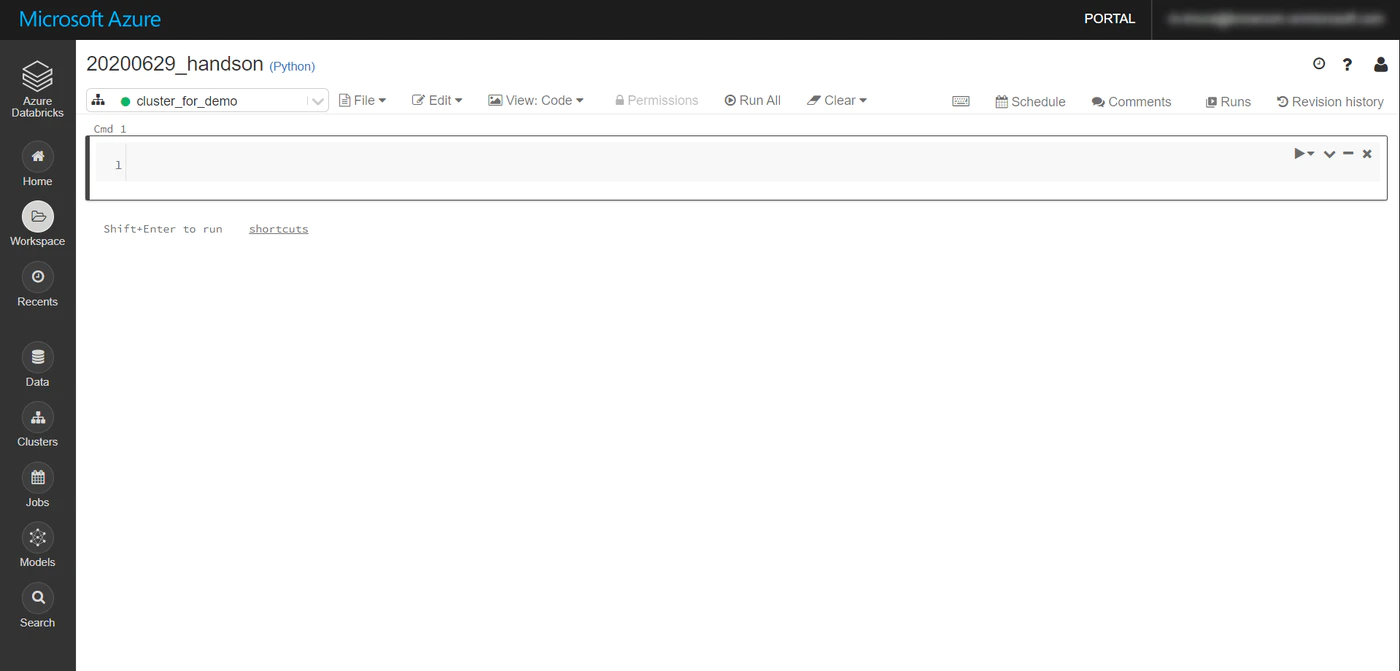
Collaborative Notebook 使用方法
灰色のエリア(セル)にコードを書き、shift + enter を押すことで、セルが実行されます。
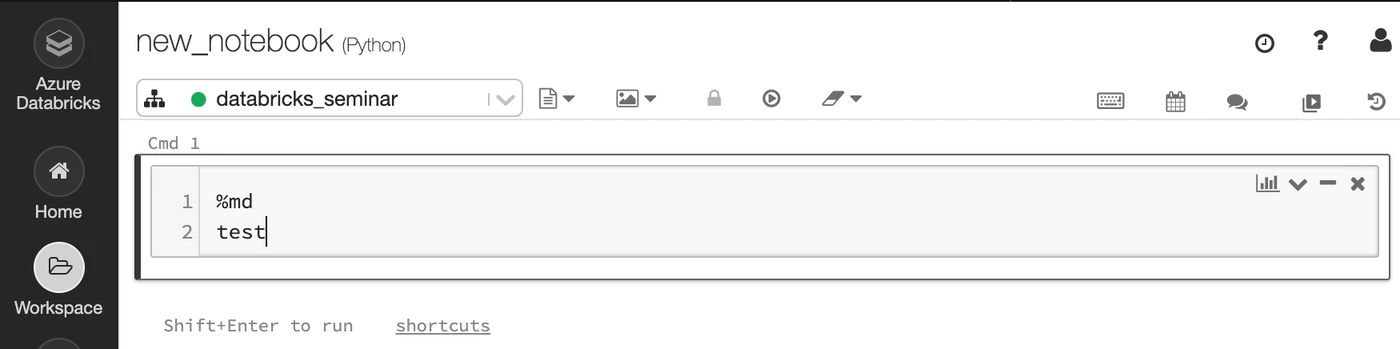
%md の後に文章を入力、セルを実行することで、markdown 形式で Notebook 上にメモを残すことができます。
セル中央部の下もしくは上にマウスカーソルを当て、+ をクリックすると新しいセルを追加できます。
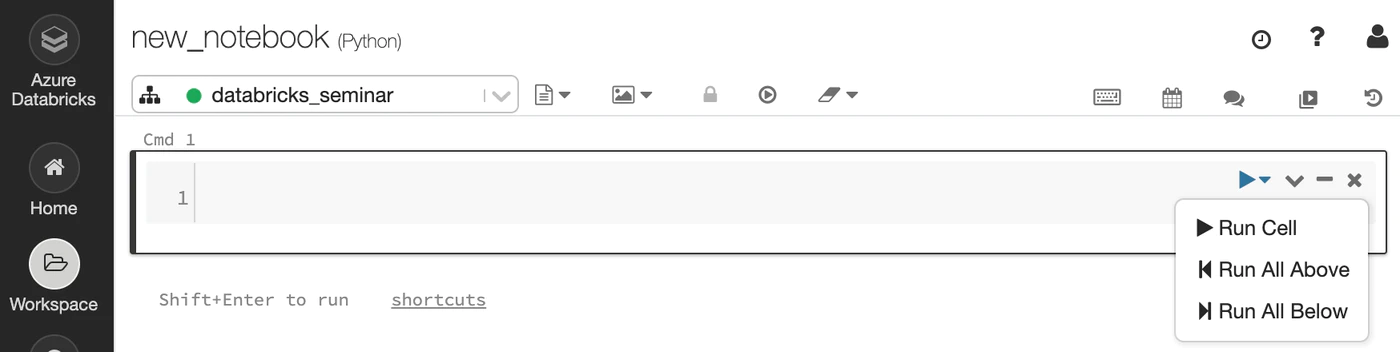
セル左上のプルダウンより、対象のセルから上、もしくはセルより下のセルを実行できます。
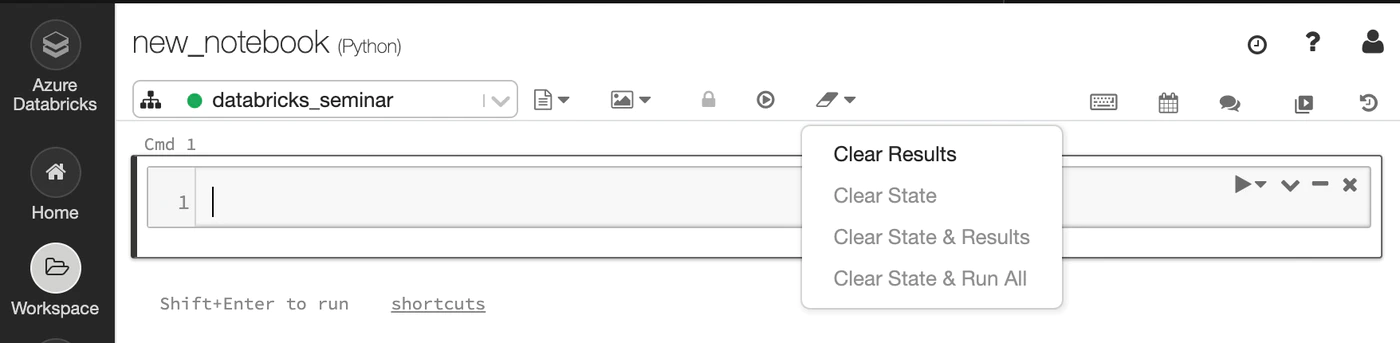
セル上部の消しゴムアイコンから clear result を選択することで、実行結果をクリアできます。
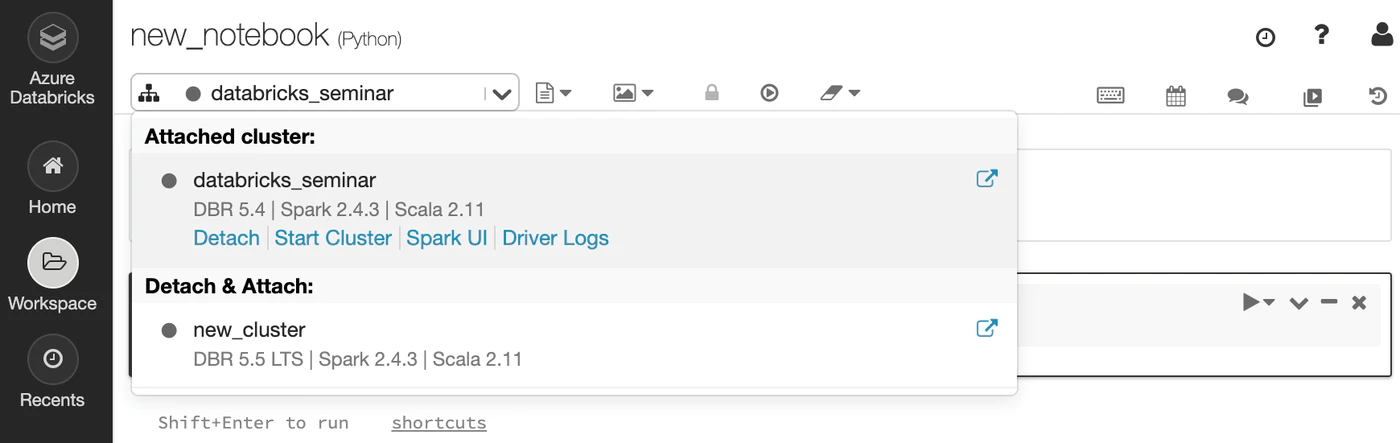
クラスタが停止した場合は、クラスタアイコンから、Start Cluster をクリックします。
mlflow 初期設定
クラスタに mlflow をインストールするために、 Notebook 上に以下のコマンドを実行します。
|
1 2 |
dbutils.library.installPyPI("mlflow") |
= の後に、先ほど作成した mlflow experiment の id を入力、同じく実行します。
|
1 2 3 4 5 6 7 8 |
mlflow_experiment_id = {your_experiment_id} import mlflow import mlflow.spark import os print("MLflow Version: %s" % mlflow.__version__) |
結果
MLflow Version: 1.9.1
以上の2つのセルを実行しておくことで、この Notebook 上で行うモデリング処理が mlflow に記録されるようになります。
備考:Notebook のインポート
Databricks の公式事例ページや Github には、そのまま活用できる Collaborative Notebook がアップロードされています。
以下の方法でインポート可能です。
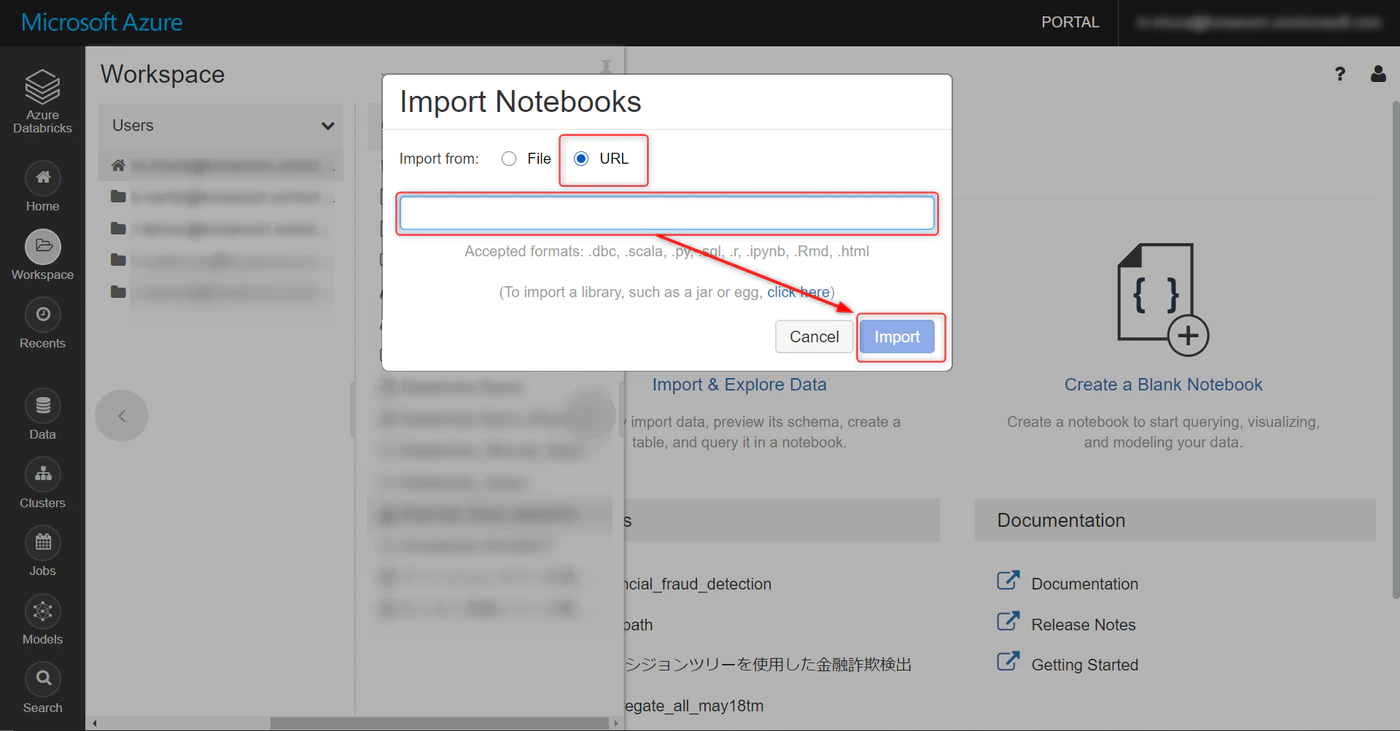
Workspace から User を選択し、以下のプルダウンから Import をクリックします。
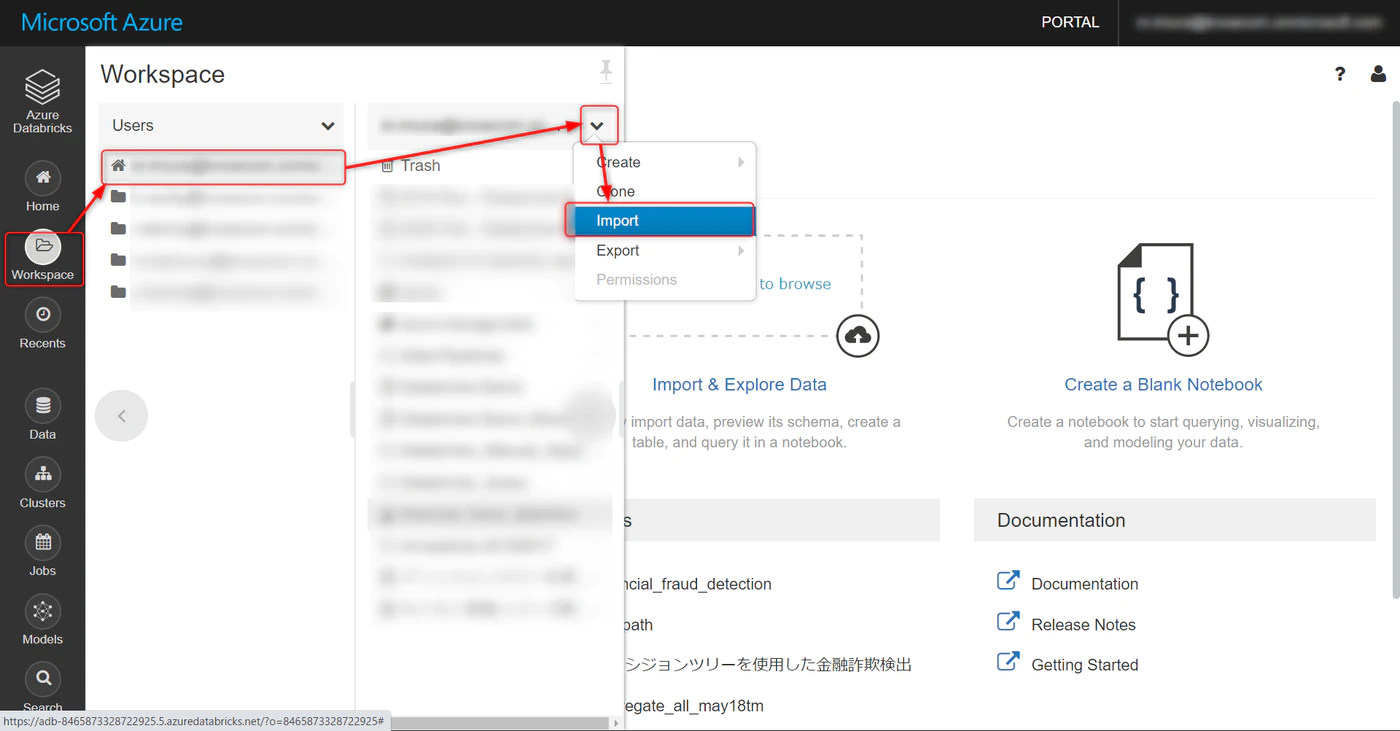
URL を選択し、インポートしたい Notebook の URL を張り付け、Import をクリックします
おわりに
今まで専門分野ではなく、データ分析を学ぶ必要があったり
機械学習を社内で取り入れていく必要があるが、一から学習するには時間がかかる、、、という時の救世主になるのではないかと思います!
次回はインポートしたデータの中身を見ていきます。お楽しみに!
関連記事リンク
本連載は、Databricks 社が展開している以下のコンテンツをベースにしています。
Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks
※翻訳まとめ
