はじめに
これまでのAzure Databricks の操作紹介第4弾目の記事です。
【Azure Databricks: 3-2. DBFSにAzure Data Lake Storage Gen2をマウント】の続きになります。
これまでの記事は以下のから参照できます。
Azure Databricks: 1. リソースの作成
Azure Databricks: 2. Databricksの基本事項
Azure Databricks: 3-1. DBFSにBlob Storageをマウント
Azure Databricks: 3-2. DBFSにAzure Data Lake Storage Gen2をマウント
この記事の概要
この記事では、サンプルデータからAzure Databricks を利用した Spark の操作について紹介しています。
PySpark ・ SQL を使いながらデータ分析を行い最後はCSV形式で出力します。
こんな方に読んでもらいたい
- Databricks に関して興味のある方
- PySpark ・ Spark SQL を勉強している方
- データ分析に興味のある方
サンプルデータセット
今回はkaggleのデータセット「Brazilian E-Commerce Public Dataset by Olist」をサンプルデータとして使います。
このデータはOlist StoreというブラジルのECサイトで行われた2016年から2018年までの約10万件の注文に関するデータが含まれています。
データ量としてはビッグデータというほどに多くありませんが、注文の商品明細やレビューなどが複数のCSVに分かれて保存され、それぞれがIDで紐づけられているため、PySparkやSpark SQLの練習に適しています。
CSVの読み込み
注文ごとの商品の明細情報「olist_order_items_dataset.csv」を使ってデータの読み込みとPySparkの操作を行っていきます。
DataFrameに読み込み
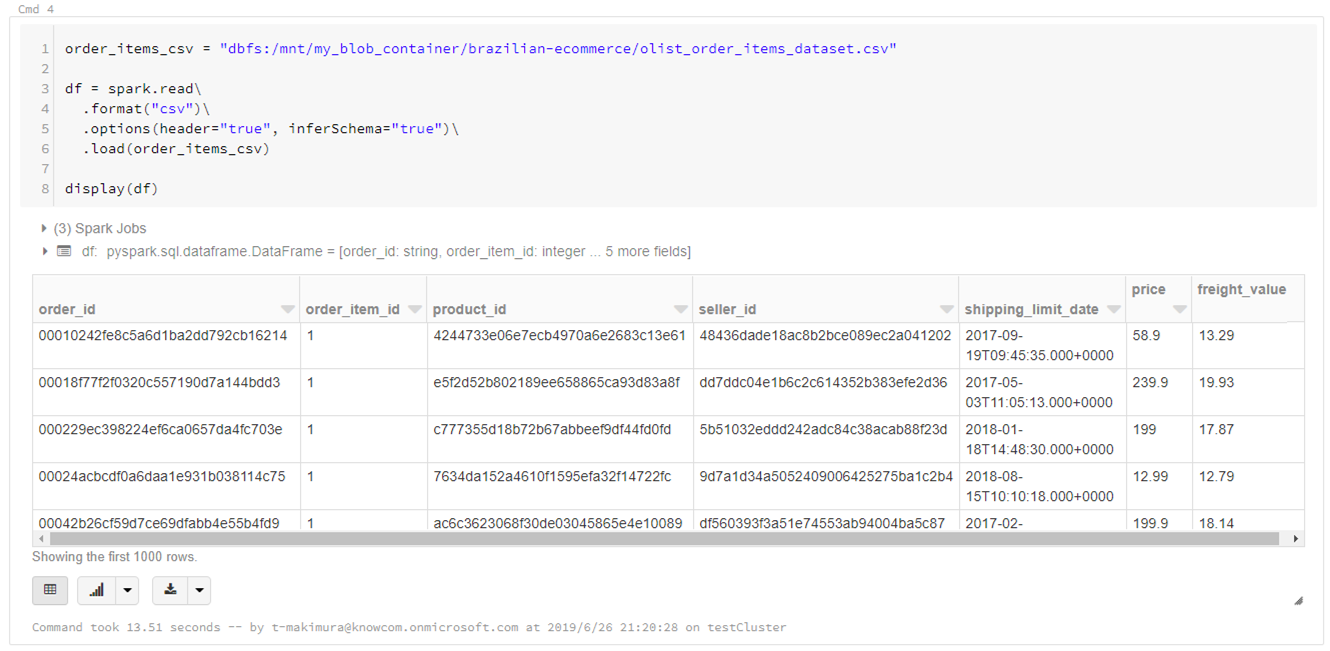
下記スクリプトでCSVをSpark DataFrameとして読み込みます。
読み込むCSVはカラム名を示す行が先頭にあるため、読み込みオプションとして「header=”true”」、またカラムのデータ型を自動推定するため「inferSchema=”true”」として読み込んでいます。
(※CSV読み込みオプションの詳細はDatabricksドキュメントも参照してください)
|
1 2 3 4 5 6 7 8 9 10 |
order_items_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/olist_order_items_dataset.csv" df = spark.read\ .format("csv")\ .options(header="true", inferSchema="true")\ .load(order_items_csv) display(df) |
スキーマを指定して読み込み
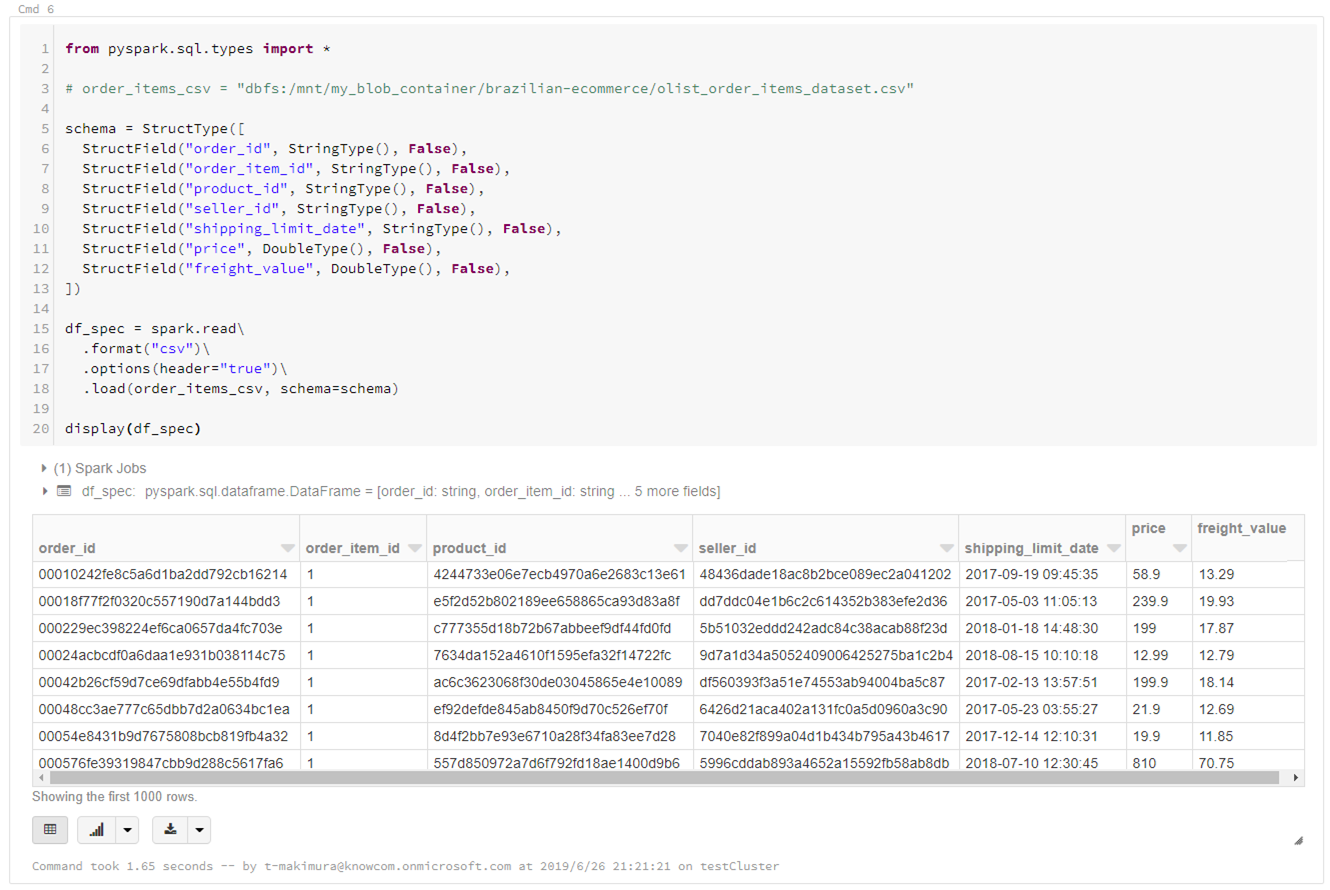
スキーマを指定して読み込みを行う場合は下記のようにします。
※指定できる型はSparkドキュメントも参照
カラムのデータ型指定にinferSchemaを使用した場合、型推定のため1回余計に読み込むことになり、読み込みのパフォーマンスが低下します。
データのスキーマがわかっている場合は、スキーマを指定して読み込むことを推奨します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from pyspark.sql.types import * # order_items_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/olist_order_items_dataset.csv" # スキーマ指定 schema = StructType([ StructField("order_id", StringType(), False), StructField("order_item_id", StringType(), False), StructField("product_id", StringType(), False), StructField("seller_id", StringType(), False), StructField("shipping_limit_date", StringType(), False), StructField("price", DoubleType(), False), StructField("freight_value", DoubleType(), False), ]) df_spec = spark.read\ .format("csv")\ .options(header="true")\ .load(order_items_csv, schema=schema) display(df_spec) |
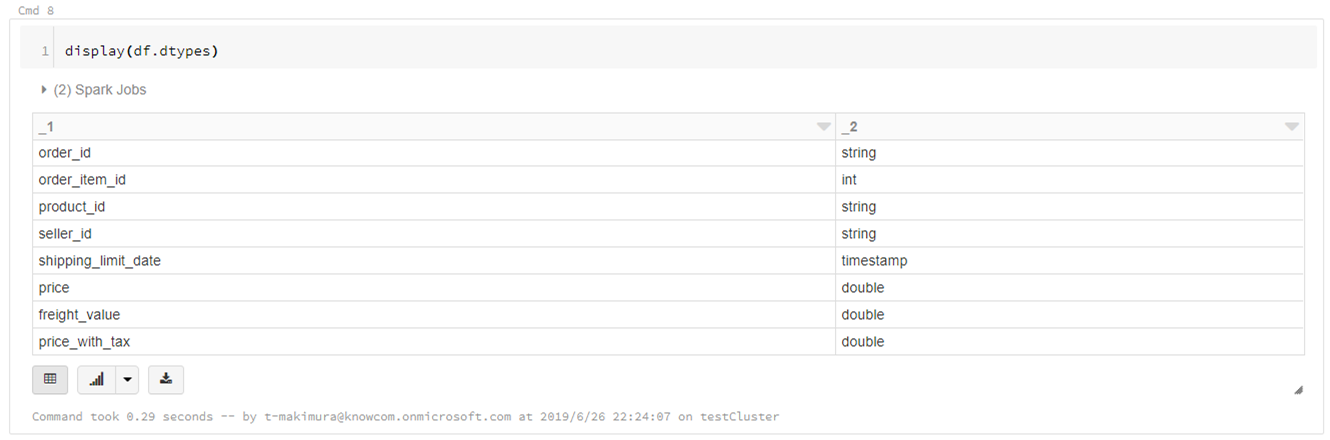
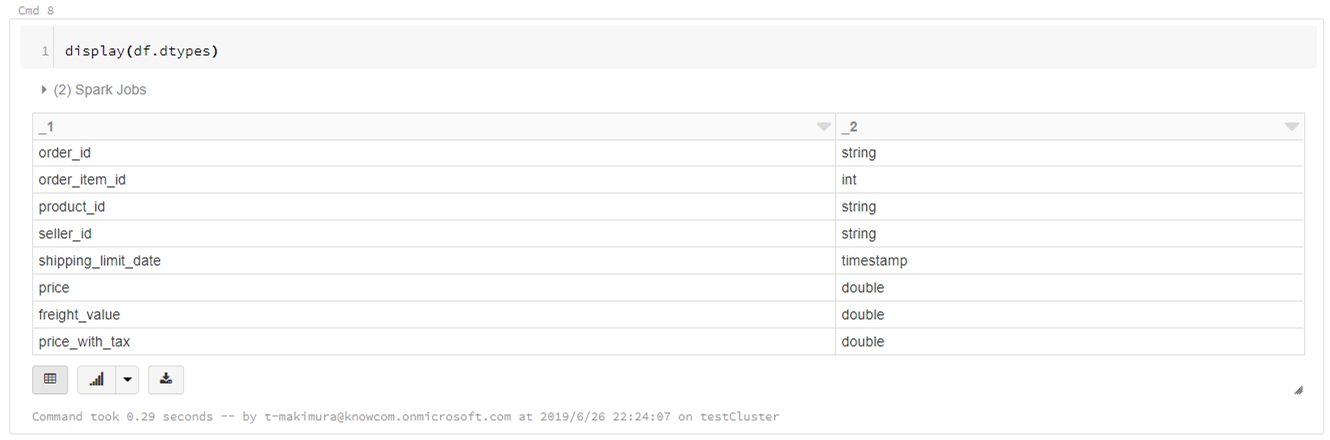
データ型の確認
|
1 2 |
display(df.dtypes) |
PySparkでのDataFrameの基本操作
読み込んだCSVでPySparkの基本操作を実行します。
指定行数抽出して表示
|
1 2 |
display(df.head(5)) |
全レコード数のカウント
|
1 2 |
df.count() |

計算列の追加
|
1 2 3 4 |
# 送料込合計列追加 df = df.withColumn("total_price", df["price"] + df["freight_value"]) display(df) |
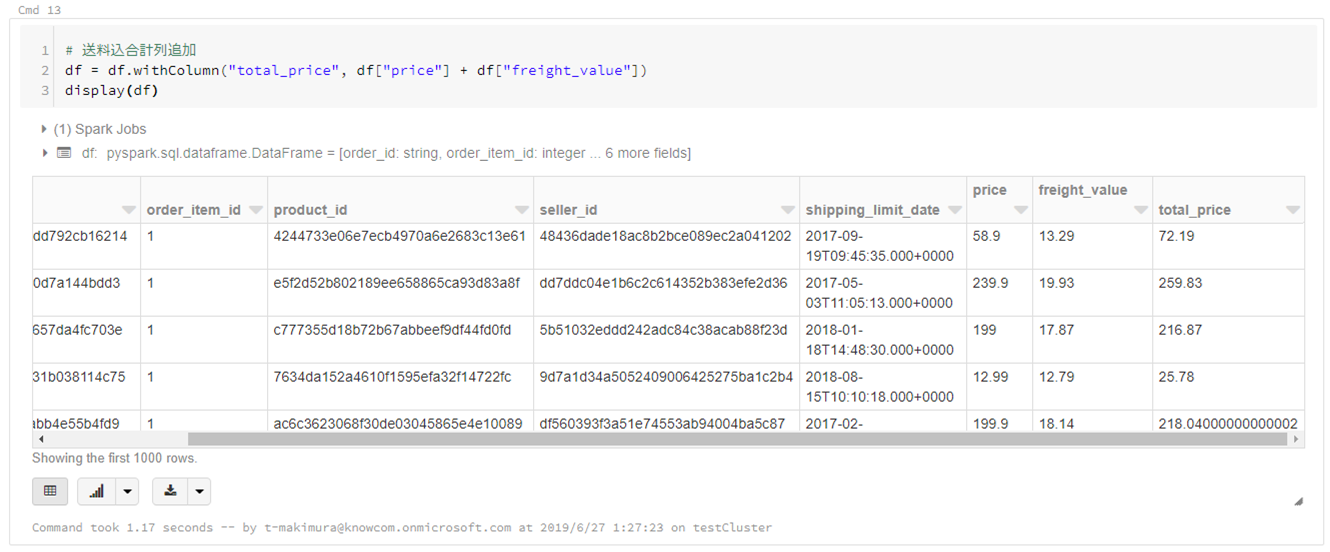
カラムを指定して抽出
|
1 2 3 4 5 |
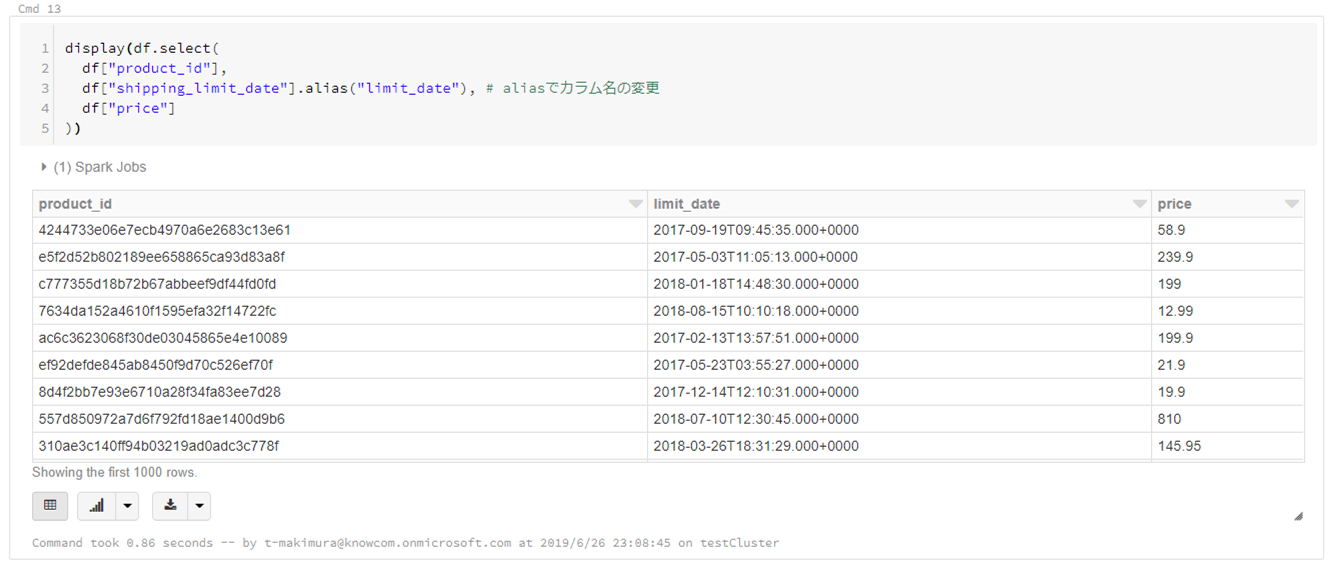
display(df.select( df["product_id"], df["shipping_limit_date"].alias("limit_date"), # aliasでカラム名の変更が可能 df["price"] |
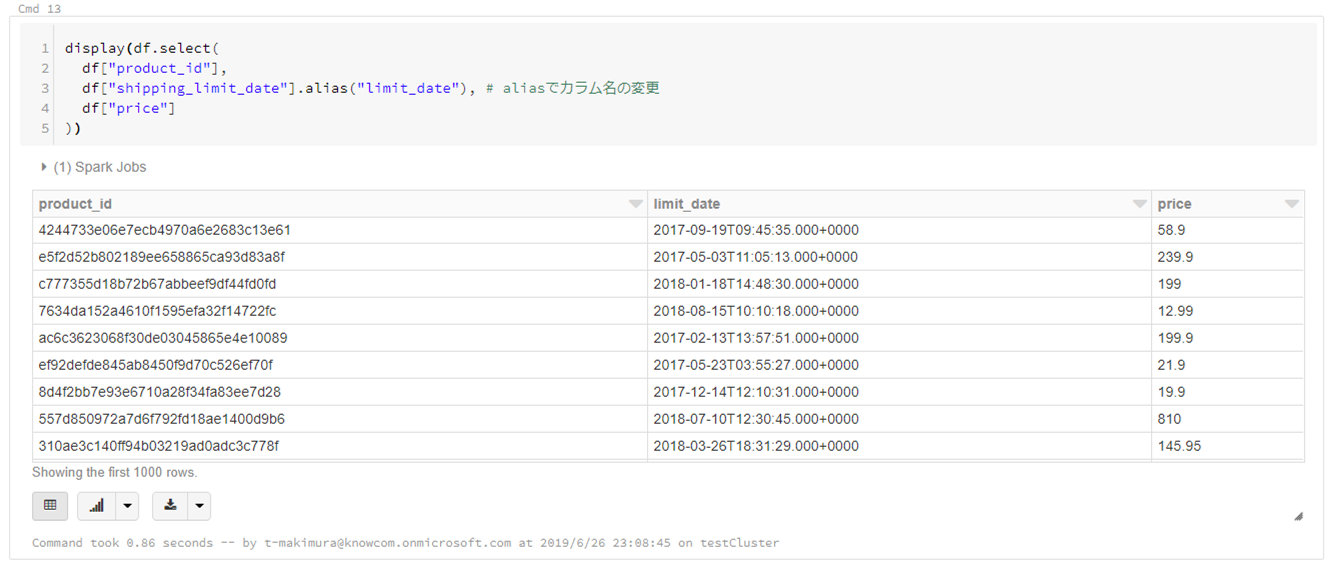
条件でレコード抽出
|
1 2 3 4 5 |
# 2018/01/01 ~ 2018/01/31のデータを抽出 from datetime import datetime df_jan = df.filter((df["shipping_limit_date"] >= datetime(2018, 1, 1)) & (df["shipping_limit_date"] < datetime(2018, 2, 1))) display(df_jan) |
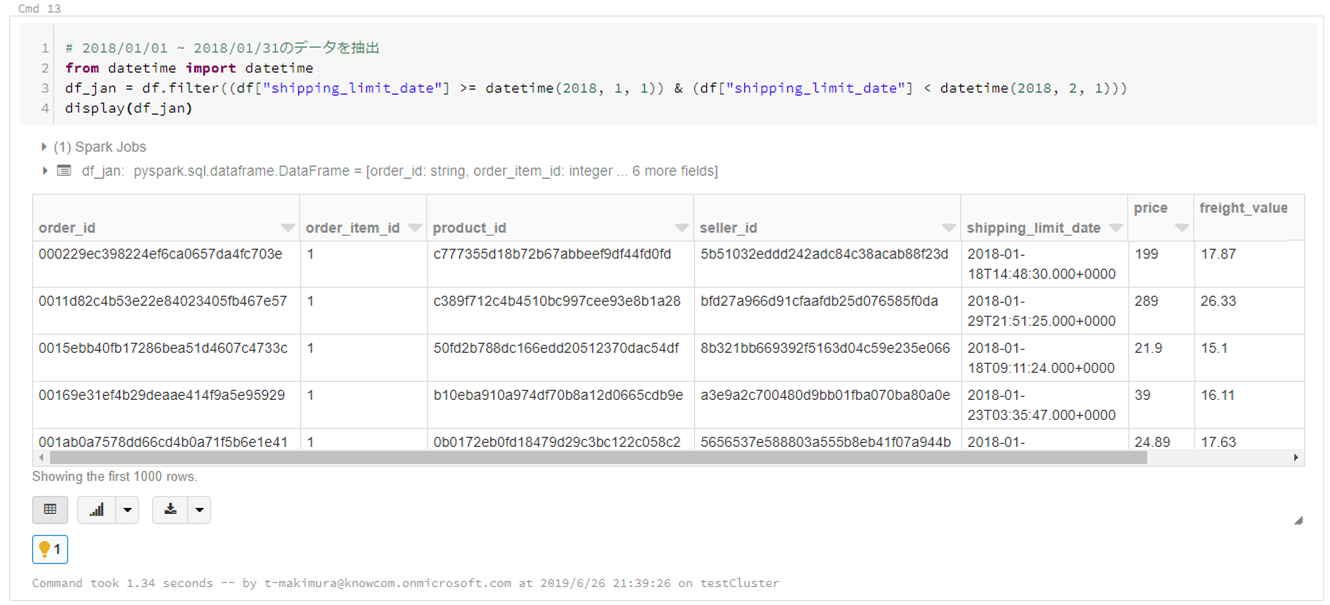
レコードのカウント
|
1 2 3 4 |
# product_idごとの売り上げの個数 df_count = df_jan.groupBy("product_id").count() display(df_count) |
レコードの集計
|
1 2 3 4 |
# product_idごとの売り上げの合計 df_sum = df_jan.groupBy("product_id").agg({"price": "sum"}) display(df_sum) |
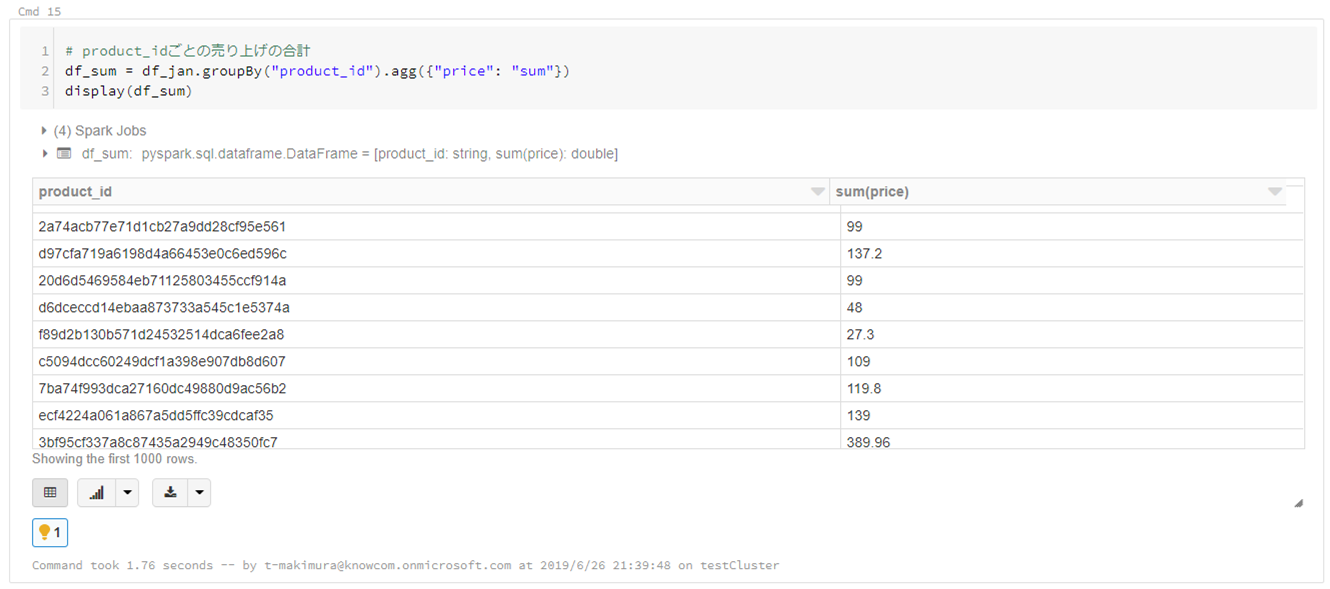
Spark SQLを使用した操作
DataFrameをTemp Tableに登録することでSpark SQLを使用した集計が可能になります。
Temp Tableの登録
|
1 2 |
df.createOrReplaceTempView("order_items") |

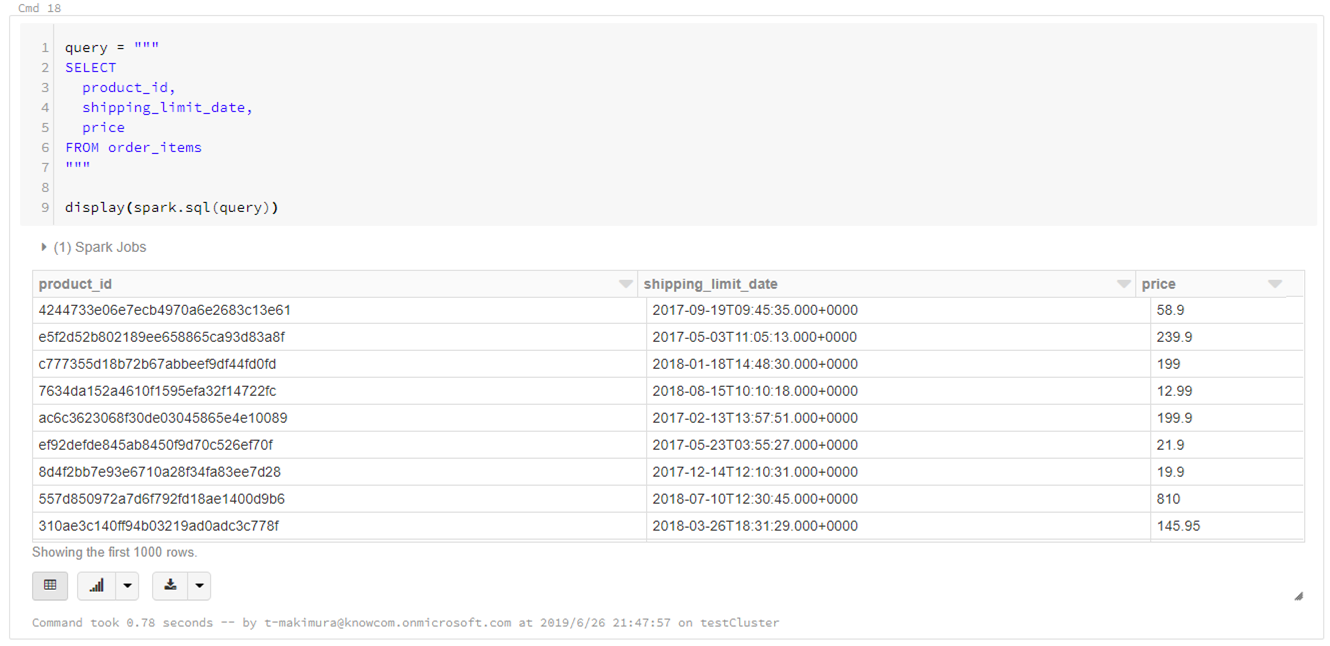
Spark SQLによるカラム抽出
|
1 2 3 4 5 6 7 8 9 10 |
query = """ SELECT product_id, shipping_limit_date, price FROM order_items """ display(spark.sql(query)) |
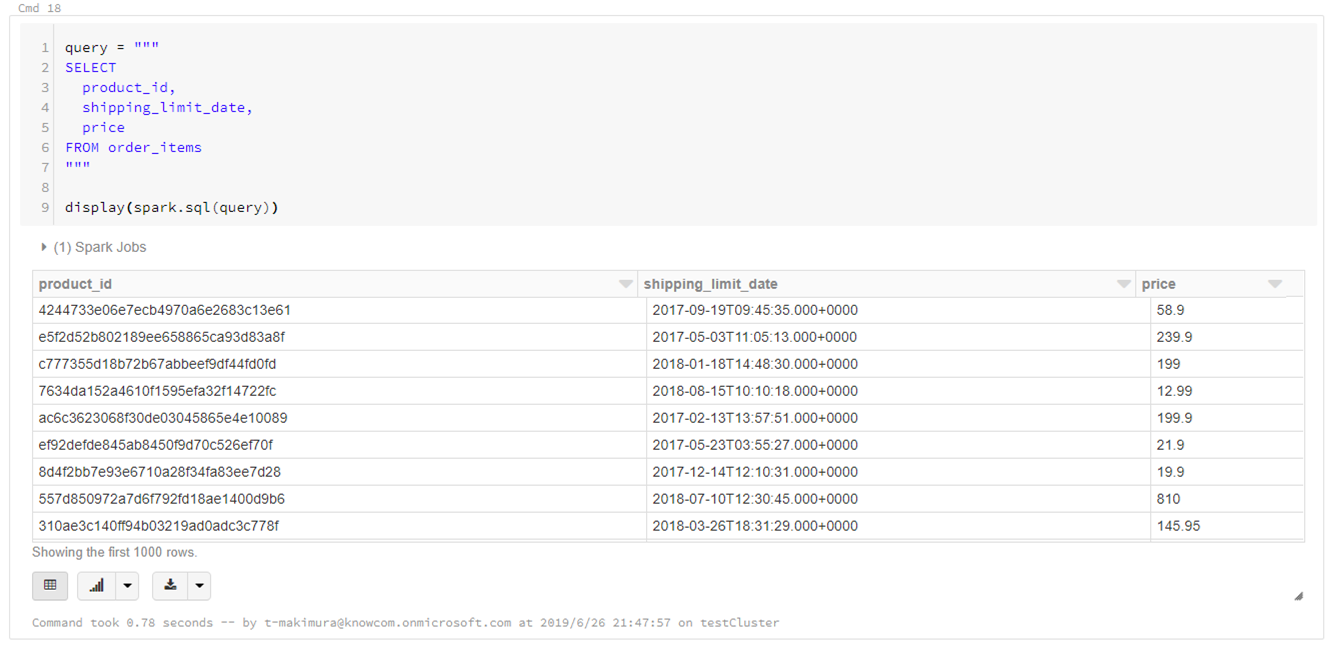
%sqlマジックコマンドを使用する場合
|
1 2 3 4 5 6 7 |
%sql SELECT product_id, shipping_limit_date, price FROM order_items |
DataFrameの結合
データセットに含まれる他のCSVファイルと組み合わせて商品カテゴリごとの売り上げを集計してみます。
各商品の詳細情報「olist_products_dataset.csv」をDataFrameに読み込みます。
|
1 2 3 4 5 6 7 8 9 |
products_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/olist_products_dataset.csv" df_prod = spark.read\ .format("csv")\ .options(header="true", inferSchema="true")\ .load(products_csv) display(df_prod) |
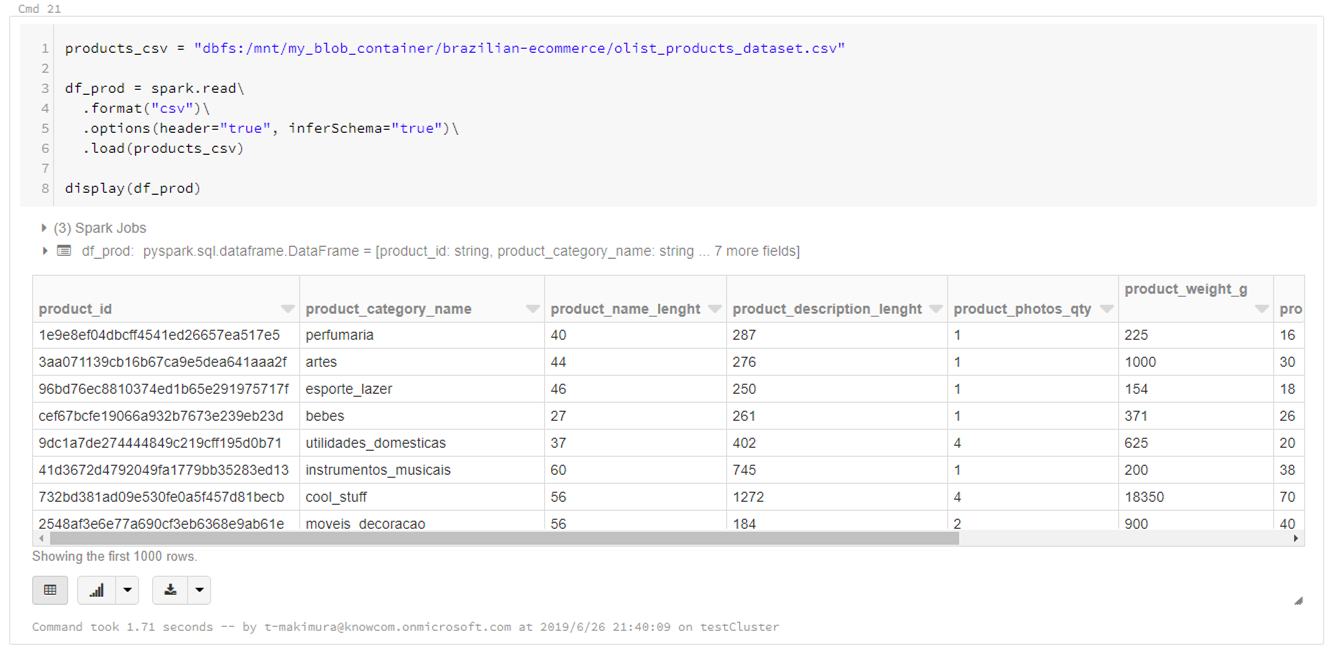
|
1 2 3 4 5 6 7 |
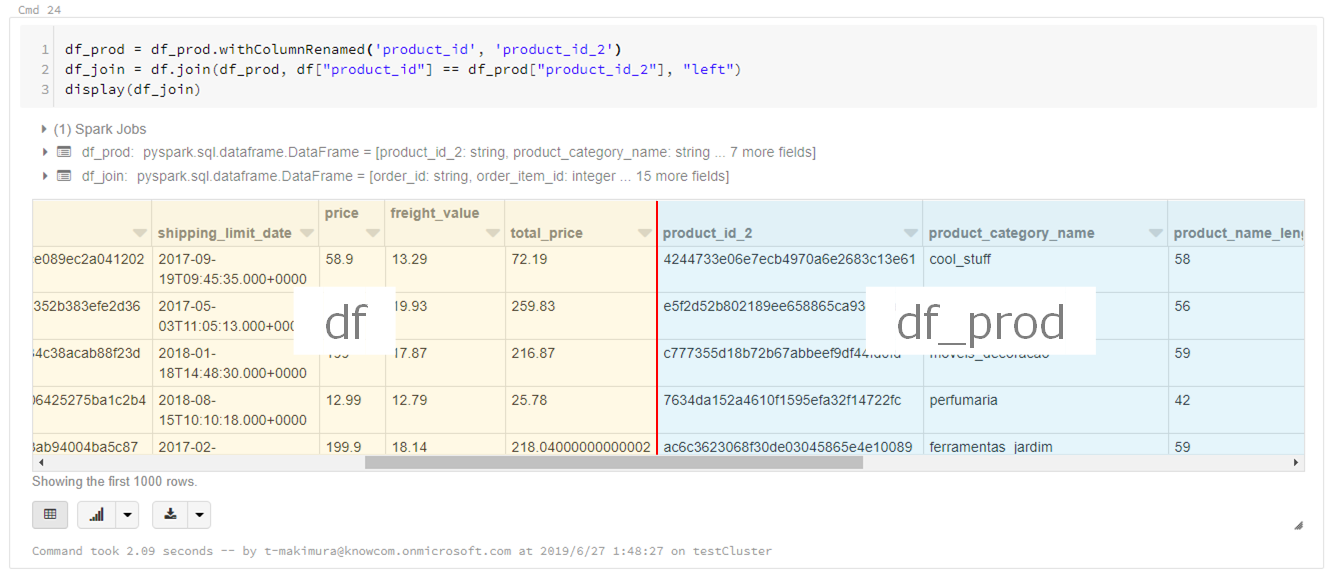
# カラム名の変更 df_prod = df_prod.withColumnRenamed("product_id", "product_id_2") # DataFrame結合 df_join = df.join(df_prod, df["product_id"] == df_prod["product_id_2"]) display(df_join) |
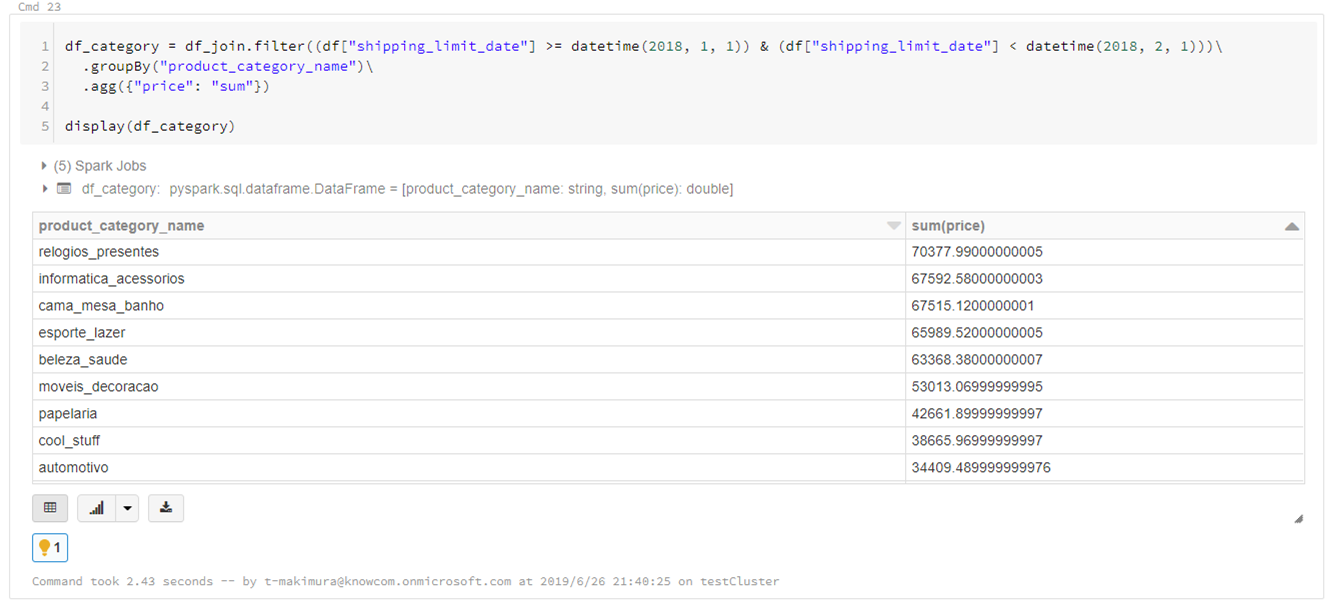
2018年1月の商品カテゴリごとの売り上げ金額を集計します。
「sum(price)」をソートすると「relogios_presentes」の売り上げが最も高いことがわかりますが、ポルトガル語なので何の商品カテゴリかわかりません。
|
1 2 3 4 5 6 |
df_category = df_join.filter((df["shipping_limit_date"] >= datetime(2018, 1, 1)) & (df["shipping_limit_date"] < datetime(2018, 2, 1)))\ .groupBy("product_category_name")\ .agg({"price": "sum"}) display(df_category) |
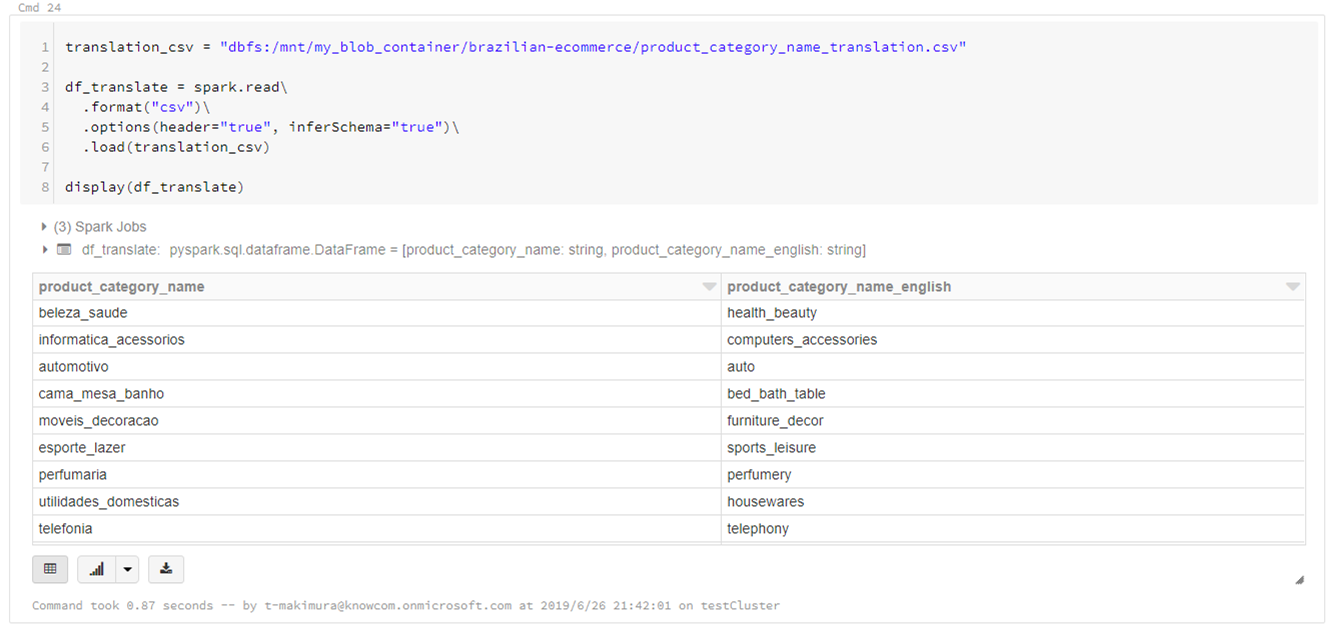
データセットにカテゴリを英語翻訳したCSVファイルがあるため、これも読み込みます。
|
1 2 3 4 5 6 7 8 9 |
translation_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/product_category_name_translation.csv" df_translate = spark.read\ .format("csv")\ .options(header="true", inferSchema="true")\ .load(translation_csv) display(df_translate) |
結合して翻訳します。
|
1 2 3 4 5 |
df_category = df_category.join(df_translate, df_category["product_category_name"] == df_translate["product_category_name"])\ .select(df_translate["product_category_name_english"], df_category["sum(price)"]) display(df_category) |
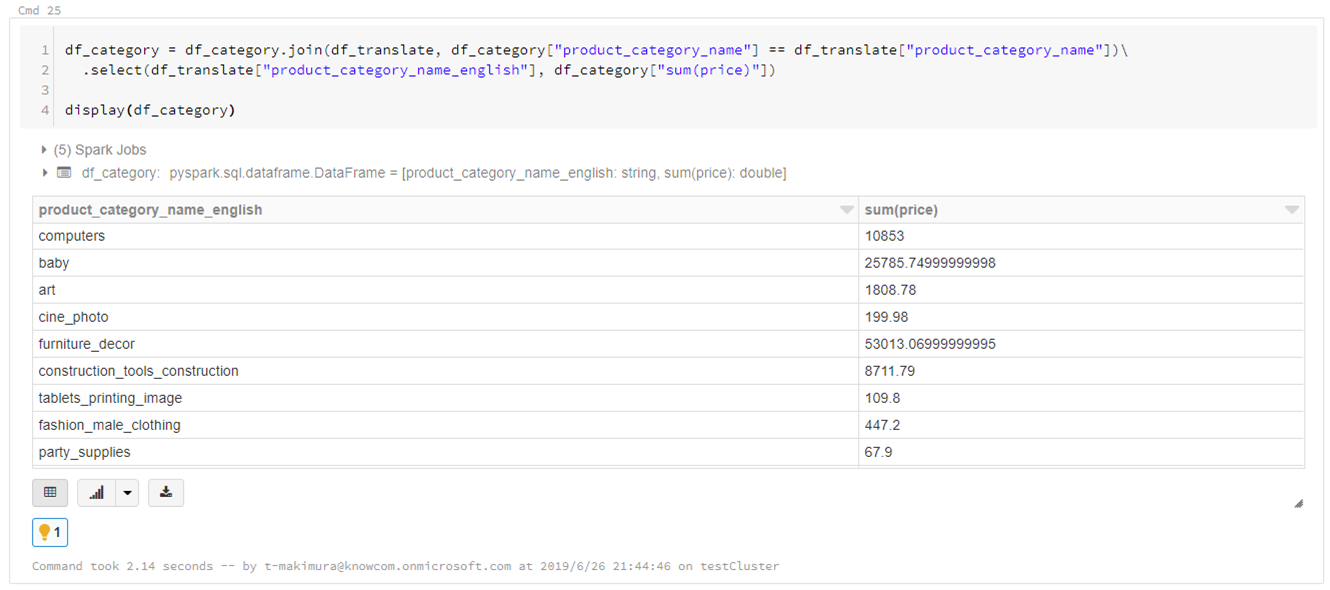
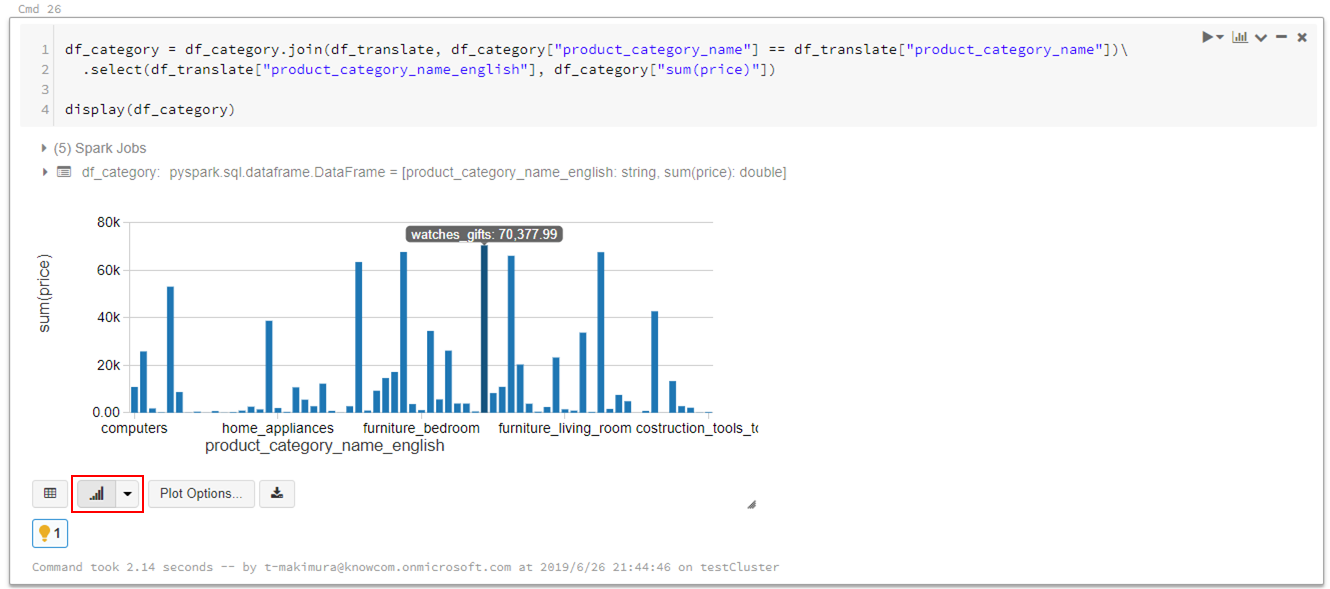
Databricksではデータの可視化も簡単にできます。
売り上げが最も高いのは「watches_gifts」であることがわかりました。
CSVの書き出し
DataFrameを書き出す場合は下記コマンドを使用します。
|
1 2 3 4 5 6 7 |
# DataFrameCSV書き出し output_path = "/mnt/my_blob_container/brazilian-ecommerce/order_items_with_detail.csv" df.join.write\ .format("csv")\ .options(header="true")\ .save(output_path) |

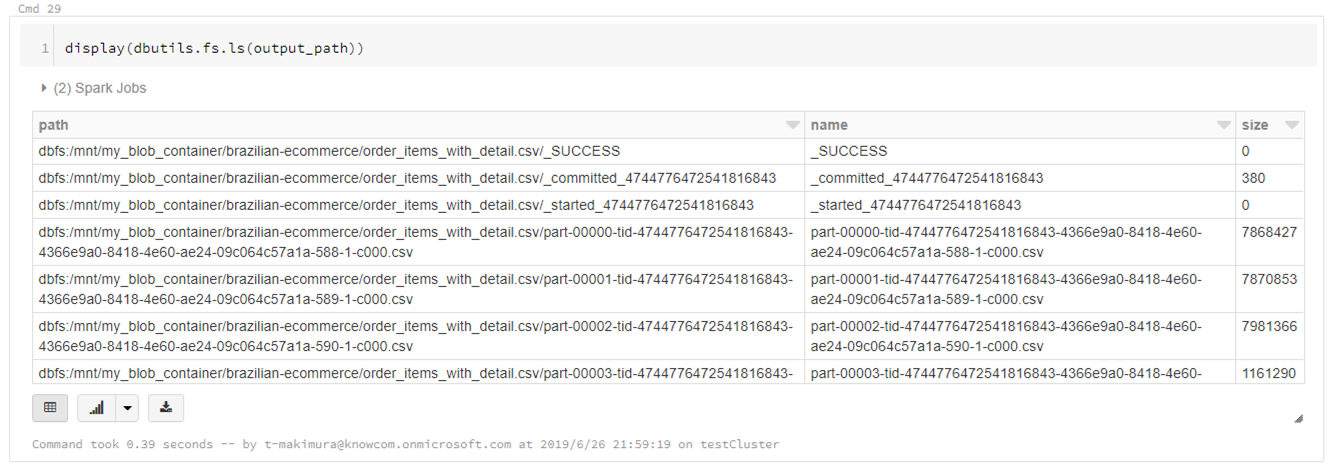
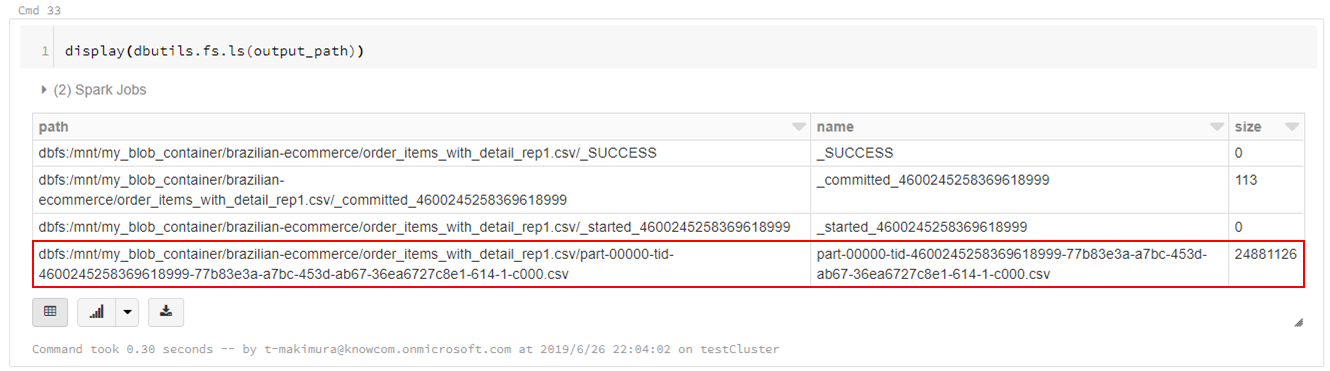
CSVは指定したパスに直接書き出されるのではなく、指定パスのディレクトリが作成され、直下に分割されたCSVファイルとして出力されます。
|
1 2 |
display(dbutils.fs.ls(output_path)) |
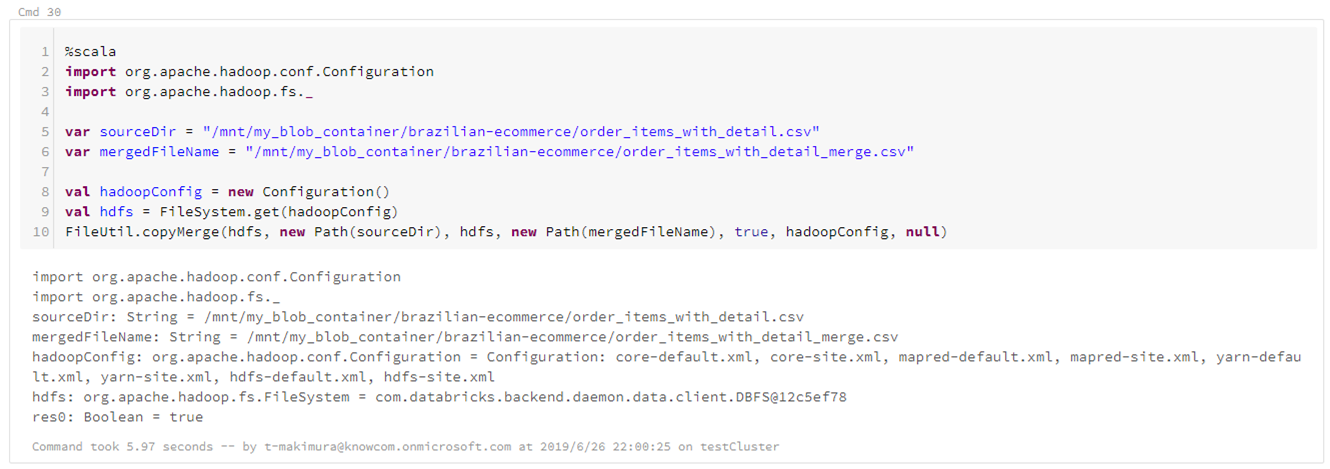
ファイルを1つのCSVとして出力する場合は、HadoopのFileUtil.copyMergeを使用し、上記で出力したファイルをマージして1ファイルにまとめます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
%scala import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs._ var sourceDir = "/mnt/blob_container/output.csv" var mergedFileName = "/mnt/blob_container/output_merge.csv" val hadoopConfig = new Configuration() val hdfs = FileSystem.get(hadoopConfig) FileUtil.copyMerge(hdfs, new Path(sourceDir), hdfs, new Path(mergedFileName), true, hadoopConfig, null) |
|
1 2 3 4 |
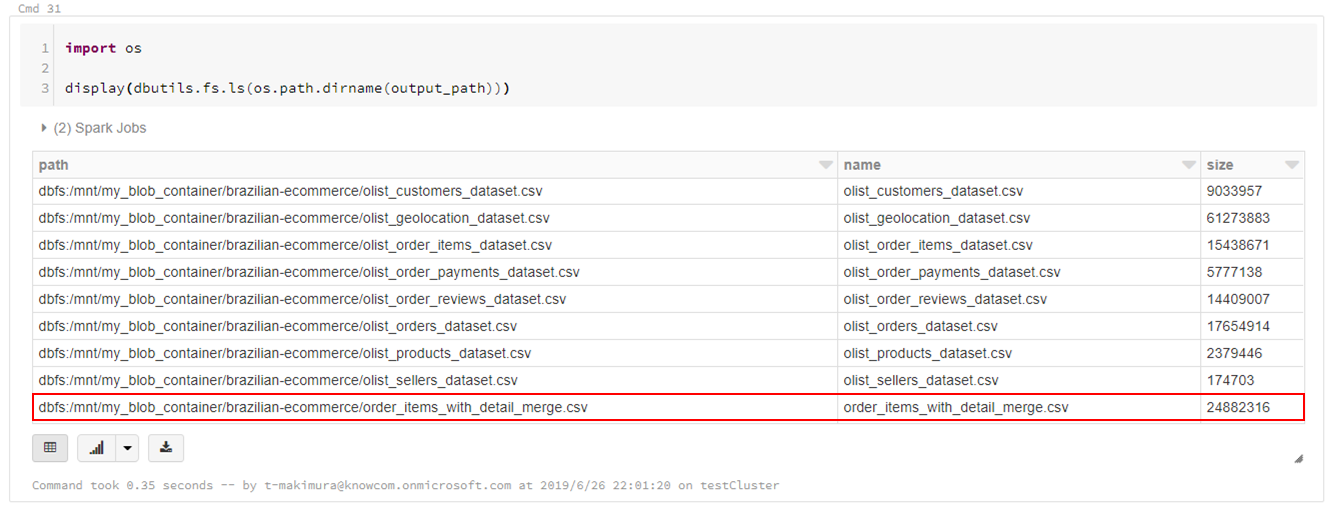
import os display(dbutils.fs.ls(os.path.dirname(output_path))) |
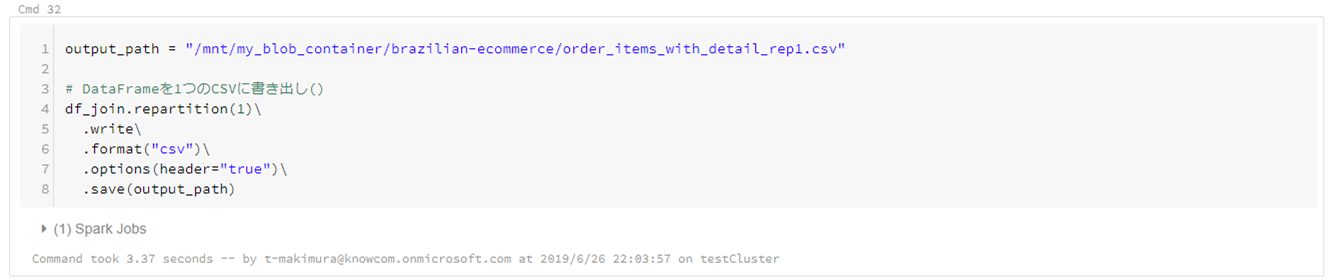
Clusterのメモリ量に余裕がある場合は、下記スクリプトで1ファイルにデータを書き出すことができます。
この場合でも「output.csv/part-00000-xxxxxxxxx.csv」のような名称でファイルが出力されるため、出力後必要に応じてファイルの移動を行います。
|
1 2 3 4 5 6 7 8 |
output_path = "/mnt/my_blob_container/brazilian-ecommerce/order_items_with_detail_rep1.csv" # DataFrameを1つのCSVに書き出し() df.repartition(1).write\ .format("csv")\ .options(header="true")\ .save(output_path) |
|
1 2 |
display(dbutils.fs.ls(output_path)) |
最後に
Azure Databricks 上で Spark を操作していきました。
データを元に特定の課題解決に向けて Azure Databricks を活用する1つの方法として知っていただけたと思います。
今後も様々なデータを Azure Databricks 上で分析していきたいです。
Azure Databricksの導入ならナレコムにおまかせください。
弊社は、Databricksのソリューションパートナーとしてお客さまのデジタルトランスフォーメーションの推進に貢献致します。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
Databricks ソリューションパートナーに関してはこちら
