はじめに
最近、機械学習(ML)の新たな形態として MLOps が注目されています。モデルをリリースした後も継続的なフィードバックを行い、必要に応じて学習しなおしモデルを更新するという方法です。
その実現のためには Azure や AWS などのクラウドサービスを駆使してデータ取得から学習、そしてモデルの継続的な評価までを自動化してやる必要があります。今までクラウド環境で ML の開発をやっていた人も、いきなり自動化すると言われてもどこからどう手を付ければ分からないと思います。
そこで、 Azure の公式ドキュメント内で定義されている MLOps 成熟度モデルを基に、どのようにして従来の ML 環境を MLOps 化していけばいいか、また成熟度モデルには記載されていない MLOps 化に使えるサービスを調べてみました。
MLOps とは
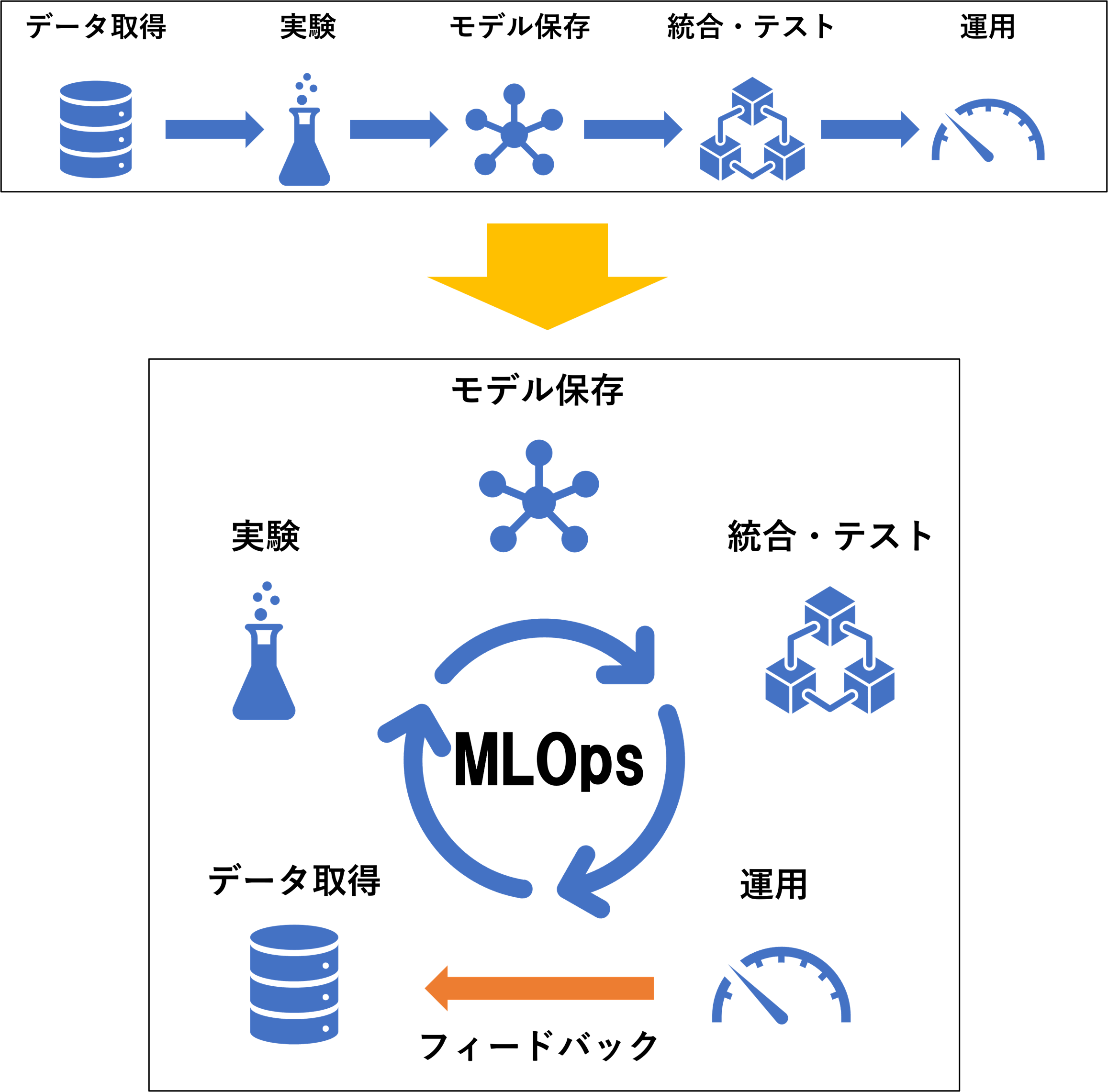
MLOps は、DevOps の考え方を機械学習に取り入れた開発手法です。 DevOpsは、開発と運用のチームが連携することによって、リリース後のフィードバックをいかに素早く反映し、またリリース…を繰り返す開発モデルです。
従来の機械学習を用いたシステム開発は、与えられたデータに対して実験を繰り返し、最適なモデルを作成したら終わり、ということがほとんどでした。しかし、近年ではリアルタイムで追加されていくデータを扱うシステムも増え、データセットの急激な変化(データドリフト)に対してモデルが陳腐化していく問題もあります。
デプロイ後もモデルの性能やデータの変化を継続的に監視し、フィードバックを基に継続的にモデルを改善していくというのが MLOps のやり方です。
MLOps への移行と成熟度モデル
Microsoft は MLOps 化を段階的に実現するための指標として、「MLOps 成熟度モデル」をAzureのドキュメント内で定義しています。
同ガイド内では、成熟度の利用目的の例として以下が挙げられています。
- 新しい契約の作業範囲を見積もる。
- 現実的な成功基準を確立する。
- 契約終了時に引き渡す成果物を特定する。
また、MLOps が成熟していくことのメリットについては以下が挙げられます。
- データサイエンティスト・データエンジニア・ソフトウェアエンジニアの各チームが緊密に連携できるようになる
- インシデントやエラーが開発・運用プロセスの品質向上につながる可能性が高くなる
各レベルの概要
Microsoft の定義では、MLOps の成熟度はパイプラインの自動化の度合いによってレベル分けされています。
すべての作業が手動で行われる状態から、最終的にリリース→フィードバックの反映までを自動化することが目標となります。
レベル0: MLOps なし
ポイント:すべての工程が手動
データ収集・学習・モデル実装・リリース……これらの工程はすべて手動で行われ、チーム間でのデータは手渡しとなります。各チームはバラバラに開発を行っておりサイロ化してしまっています。
まずはパイプラインを整備して、テストやリリースなどのソフト開発/運用側の自動化を目指すのが目標です。
レベル1: DevOps はあるが MLOps はなし
ポイント:ソフトウェア側のテストの自動化を行う
モデルの統合テストが行われ、テストとリリースの自動化がされるようになります。また、データ収集も自動化される場合があります。
この時点では ML 側のやり方はレベル0と変わりありません。チームもサイロ化したままです。ここから ML 部分の自動化を進める必要があります。
レベル2: 学習の自動化
ポイント:レベル1に加えて、学習が自動化・追跡され、再現可能な環境を作る
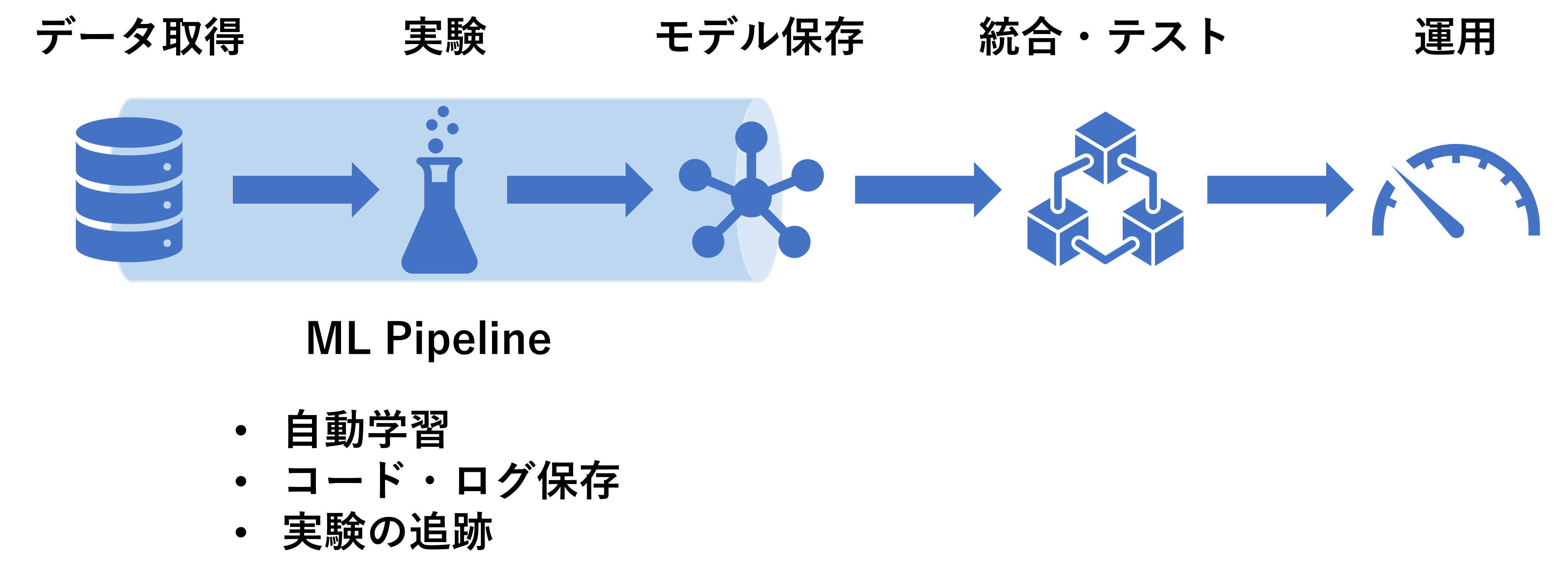
機械学習に自動化を導入します。データの準備・実験・モデルの選定というプロセスをパイプライン化して一括で処理できるようにします。また、コードやモデルのバージョンを管理し、実験の再現性を担保することで自動化を勧めます。
この時点で、データサイエンティストとデータエンジニアが連携し、実験内容をうまくコードに反映できるようになります。
レベル3: モデルデプロイの自動化
ポイント:レベル2に加えて、アプリケーションと学習モデルの統合を自動化する
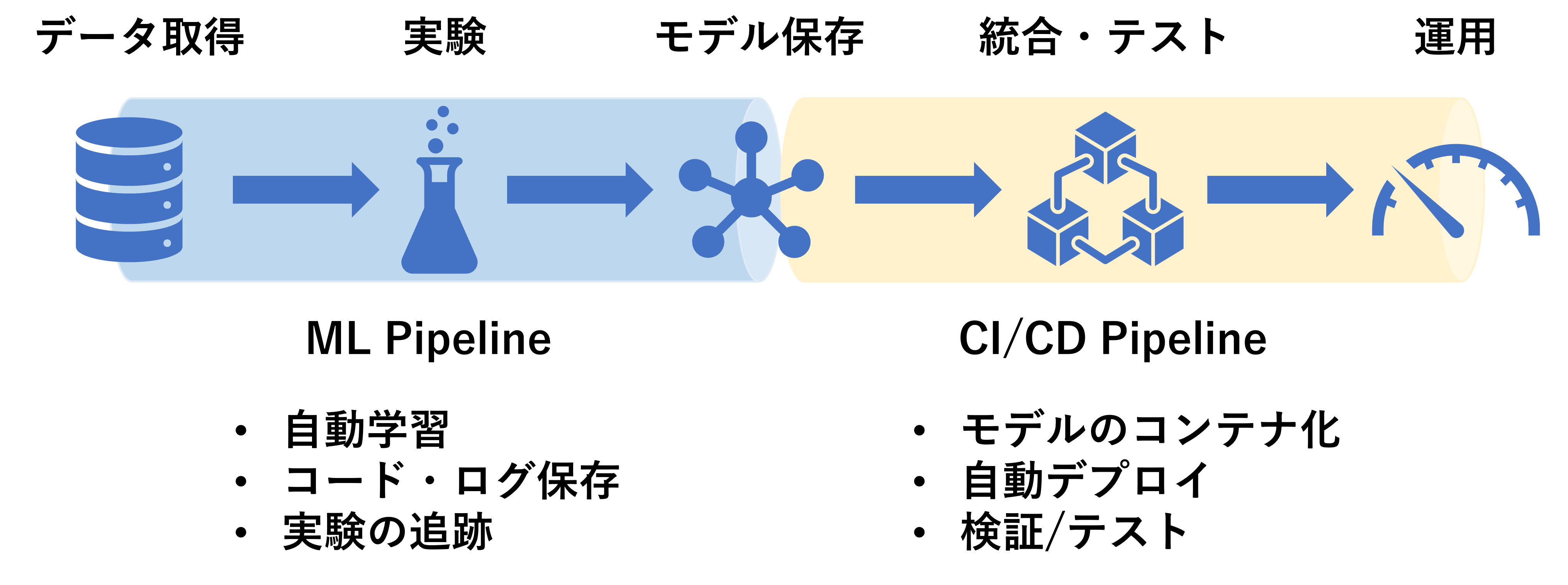
自動学習したモデルを、アプリケーションにするところまでを自動化します。モデルが更新されたら CI/CD パイプラインによってアプリ開発側に渡され、自動で統合とテストが行われるようになります。
これによって、モデルの実装がデータサイエンティスト頼りにならずに、ブラックボックス化を予防することができます。データエンジニアとソフトウェアエンジニアが連携できるようになりました。
レベル4: MLOps 運用の完全自動化
ポイント:レベル3に加えて、デプロイしたモデルを監視し、再学習を自動化する
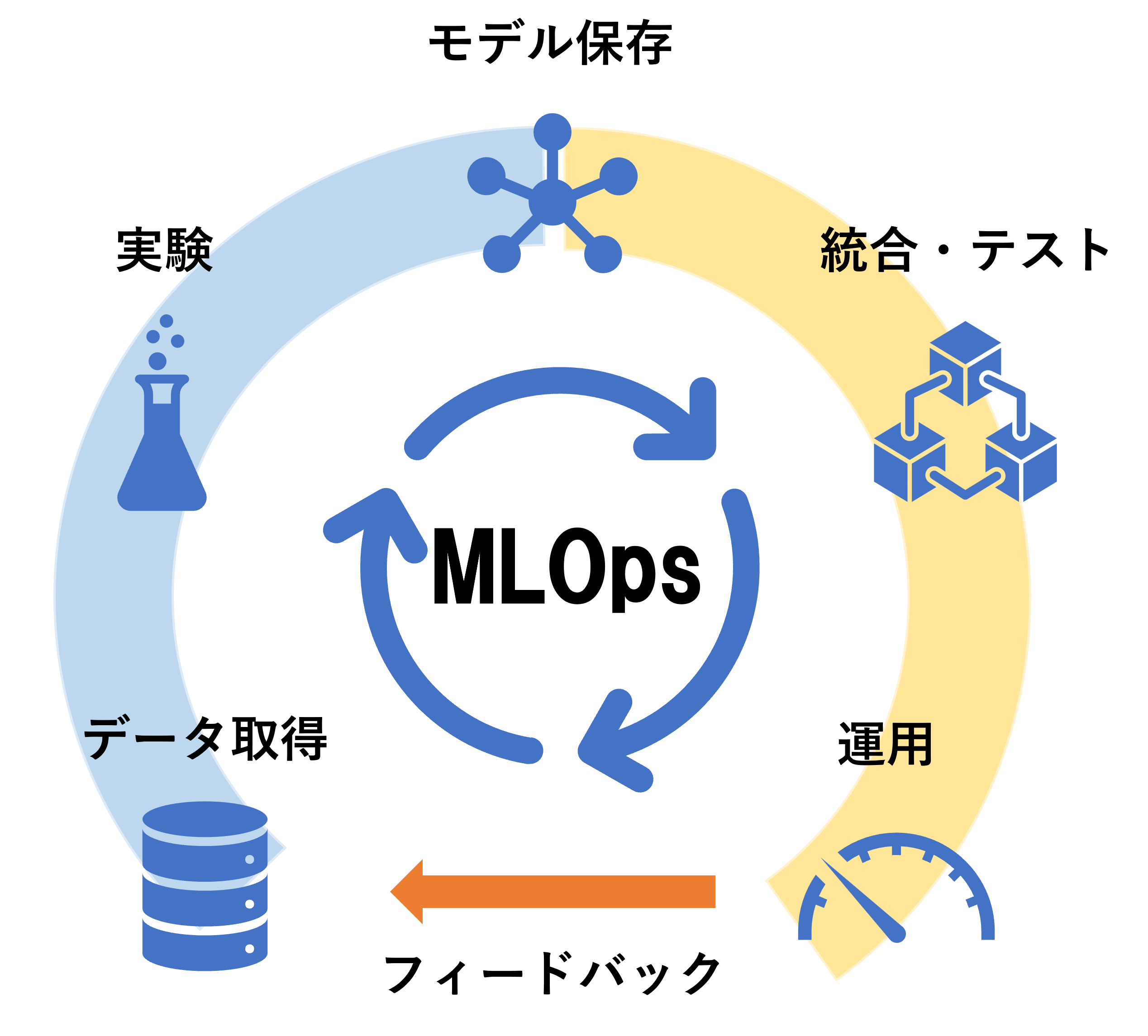
MLOps の核となる再学習のプロセスを実装します。そのためには、どのタイミングで再学習するかという条件を考えた上で、メトリクスから学習をトリガーするシステムが必要です。
モニタリングする対象としては、アプリのパフォーマンスや、データセットの変化が挙げられます。データサイエンティストがソフトウェアエンジニアと連携してモデル改善に必要なデータを特定します。これによってフィードバックをモデル改善に還元するサイクルが完成しました。
MLOps 運用に使えるサービス
成熟度モデルのガイド上では、MLOps を運用する上で必要な具体的なサービスやアーキテクチャについては言及されていません。
MS の社員が具体的な Azure サービスの実例を示した記事を執筆しており、そちらなどを参考にしながら各レベルに引き上げるために活用できるサービスの例を挙げます。
レベル1→2
- Azure Machine Learning Pipeline
- Azure Machine Learning の機能の一つで、データ処理や学習といった機械学習の各工程をワークフローとして繋いで実行したり、過程を可視化することができます。エンジニアは各工程の内部処理に気を配れば良く、MLの自動化に貢献します。
- GitHub Actions
- GitHub への Push などをトリガーとして、Azure など他サービスへのアクションを自動で行えるサービスです。GitHub と Azure を連携する場合に、テストの自動化などが可能になります。
- Databricks Workflows
- こちらは Azure Databricks で利用できる機能で、ワークフローを作成・可視化する機能を持ちます。こちらは Databricks 固有のノートブックの自動実行機能などが含まれています。
- MLflow
- 機械学習のコード、モデル、結果などいろいろ記録できるツールです。再現可能な実験を行う上では必須となります。Azure ML やDatabricks に組み込むことができます。
レベル2→3
- Azure Pipelines
- Azure MLの Pipeline と名前が似ていますが別物です。こちらはサービスを跨いだパイプライン化を行うツールです。モデルからサービスへのデプロイを自動化できます。
- Azure Container Registry
- 完成したモデルをコンテナとして保存し、バージョン管理として利用するほか自動でデプロイすることができます。
- Webhook
- MLflow でのモデル更新をトリガーにして自動テストやデプロイを実行できるようになります。
レベル3→4
- Azure Monitor
- デプロイしたモデル/サービスの、メトリックやログを監視できるツールです。フィードバックを得るためには重要になるでしょう。
- dataset monitors
- Azure ML の機能で、データセットの変化を監視できます。データドリフトが起こった際に、自動で再学習を行う機能もあります。
まとめ
MSとしては、まずは現在のシステムがどのレベルに相当するのかを見極めて、次にどこを自動化する必要があるかを認識しつつ段階的にシステムを成長させていくような開発をすることが重要だと語られています。
今回 MLOps について調べた際、よく分からなかったのがLevel1の立ち位置であり、成熟度モデルでは自動的ビルド/テストと定義されているのに対して、実例の記事ではデータパイプラインと ML 環境の整備を指しており、整合していない印象を受けました。これについては筆者のDevOps自体への理解がまだ足りていない面もありそうですが。
また、機械学習のプロセスを追跡して自動化する、というステップに関しては想像がついた(今まで Colab での開発をやっていた為)のですが、その後のアプリへの統合やコンテナ化については経験が無かったため理解しづらかったので、今後はその辺りも併せて勉強していきたいです。
余談
ちなみに同様のテキストは Amazon や Google も公開していますが、その基準やゴールは三者三様です。
詳しくはこちらの記事を読んでいただきたいのですが、それぞれの違いをまとめると
- Google は自動化に着目し、 ML と CI/CD の2段階に大別している
- Azure は自動化をより細かく段階分けし、チームワークに言及
- Amazon は組織内での標準化に着目し、スケーリングを見据えている
Googleのガイドにはより汎用的にDevOps/MLOpsの解説が書かれているようなので、こちらをより読み込んでおこうと思います。
