構成
全部で3部構成にする予定です。
Part.1
検索インデックスの作成 (今回)
Port.2
デモアプリの作成(次回)
Port.3
Power BI 1 レポートの作成(次々回)
はじめに
News ZERO さんがTwitterで新型コロナ「陽性」の経験談を募集されており、使われたハッシュタグはトレンド入りしました。
そこで今回は、「#感染したから伝えたい」を含むツイートを約500件取得し、Azure Cognitive Search で人物・感情・キーフレーズなどを抽出 → デモアプリを作成→Power BI テンプレートでワードクラウドの表示をさせてみました。
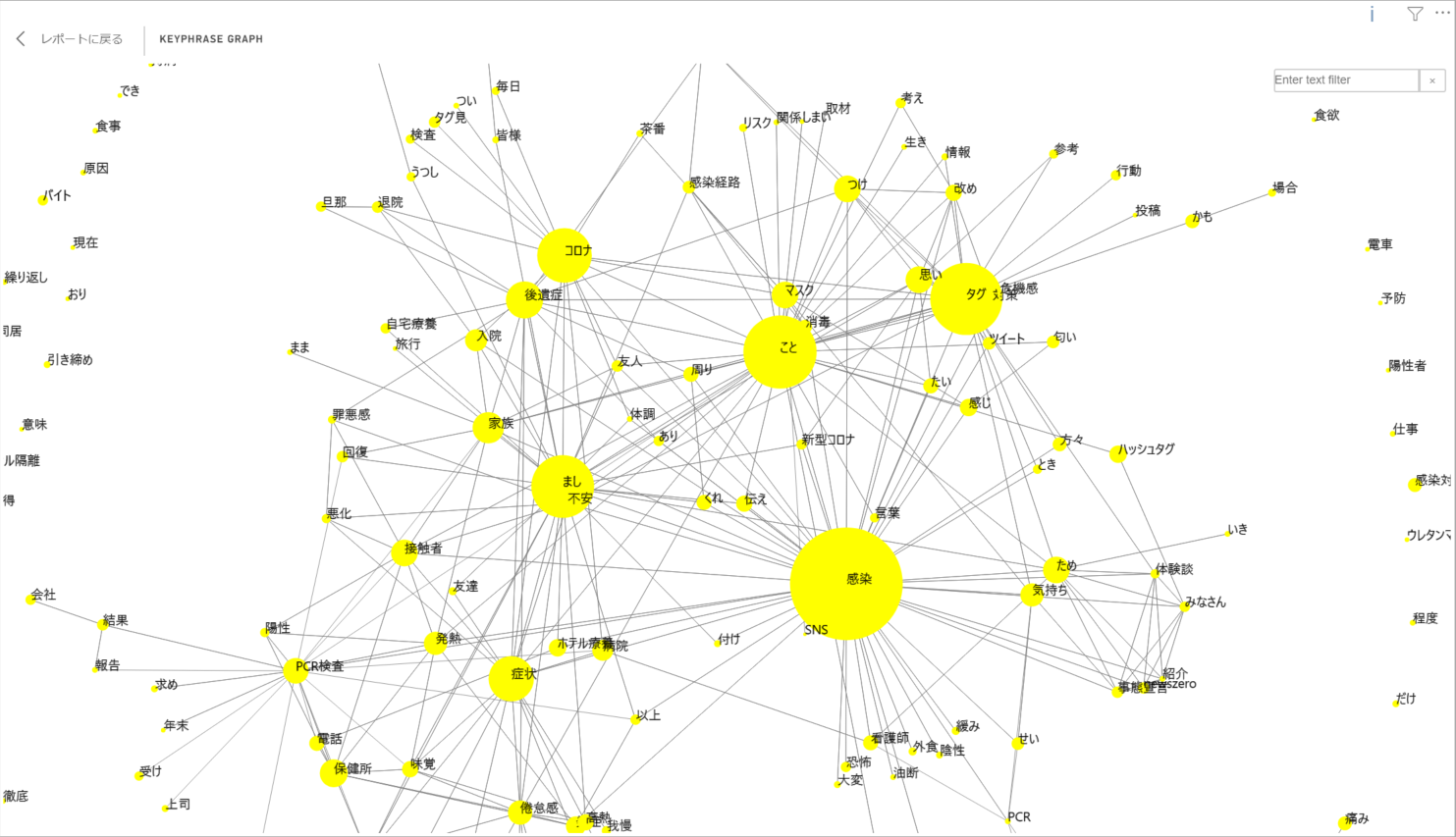
↓ こんな感じのワードクラウドが簡単に得られます。

Azure Cognitive Search とは
Azure Cognitive Search (旧称 Azure Search)は、Web、モバイル、エンタープライズの各アプリケーション内のプライベートな異種コンテンツに対する豊富な検索機能を提供する、クラウド検索サービスです。
公式ドキュメント:https://docs.microsoft.com/ja-jp/azure/search/search-what-is-azure-search
今回はテキストデータのみ使いますが、Cognitive Searchでは画像、映像、音声などの非構造化データも検索可能です。
また、Cognitive ServicesやPower BIとの連携も容易です。
手順
ざっくりと以下の5つの手順でやっていきます。
- Twitter API を使用してデータを用意する
- BLOB ストレージにツイートデータアップロード
- Cognitive Search で検索インデックスの作成
- デモアプリの作成(Part2. デモアプリの作成 で説明します。)
- Power BI テンプレートでワードクラウド表示(Part3. Power BI レポートの作成 で説明します。)
1. Twitter API を使用してデータを用意する
1-1. Twitter APIの利用申請→APIトークン取得
Developerサイトにて英語で申請→うまくいけば1日で使えるようになります。
申請内容が不十分だと、メールが来て改めてAPIの使用用途を聞かれます。
APIの申請方法、APIキーの取得方法については、以下リンクが参考になるかと思います。
参考リンク:https://www.itti.jp/web-direction/how-to-apply-for-twitter-api/
1-2. Pythonで 「#感染したから伝えたい」 を含むツイートを収集
以下の記事を参考にし、1月13日~1月21日までの 「#感染したから伝えたい」 のハッシュタグを含むツイートを約500件集め、CSVファイルに出力しました。
参考リンク:https://qiita.com/nomotom/items/de1bc00ef350edc21624
2. BLOB ストレージにCSVファイルをアップロード
Azure Blob Storageでストレージアカウントを作成→コンテナー作成→CSVファイルのアップロードをします。
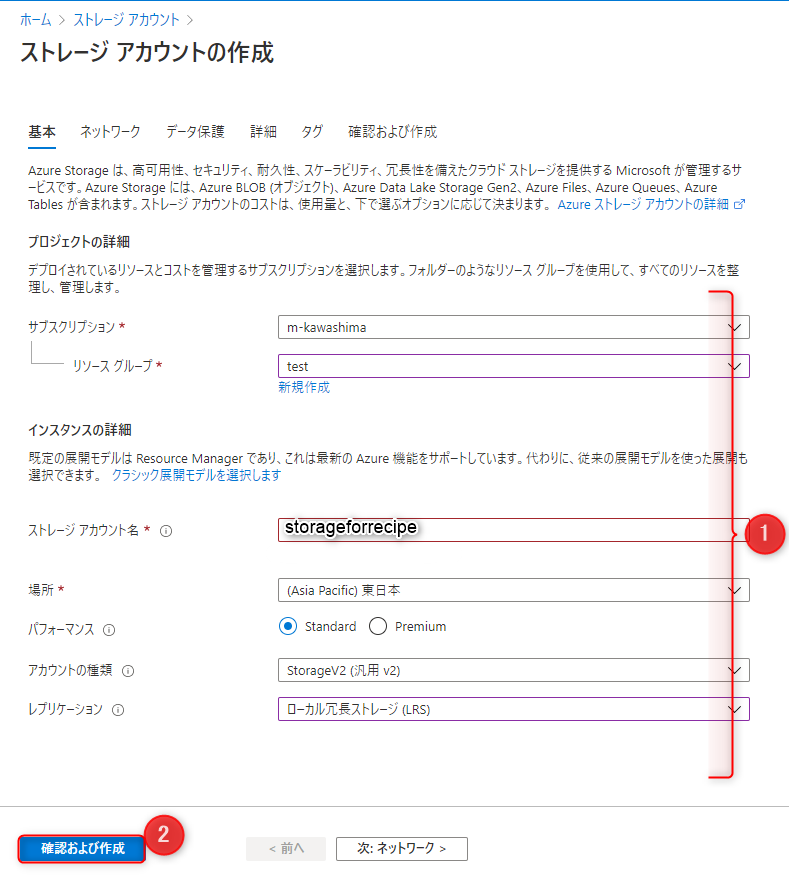
まずストレージアカウントを作成します。

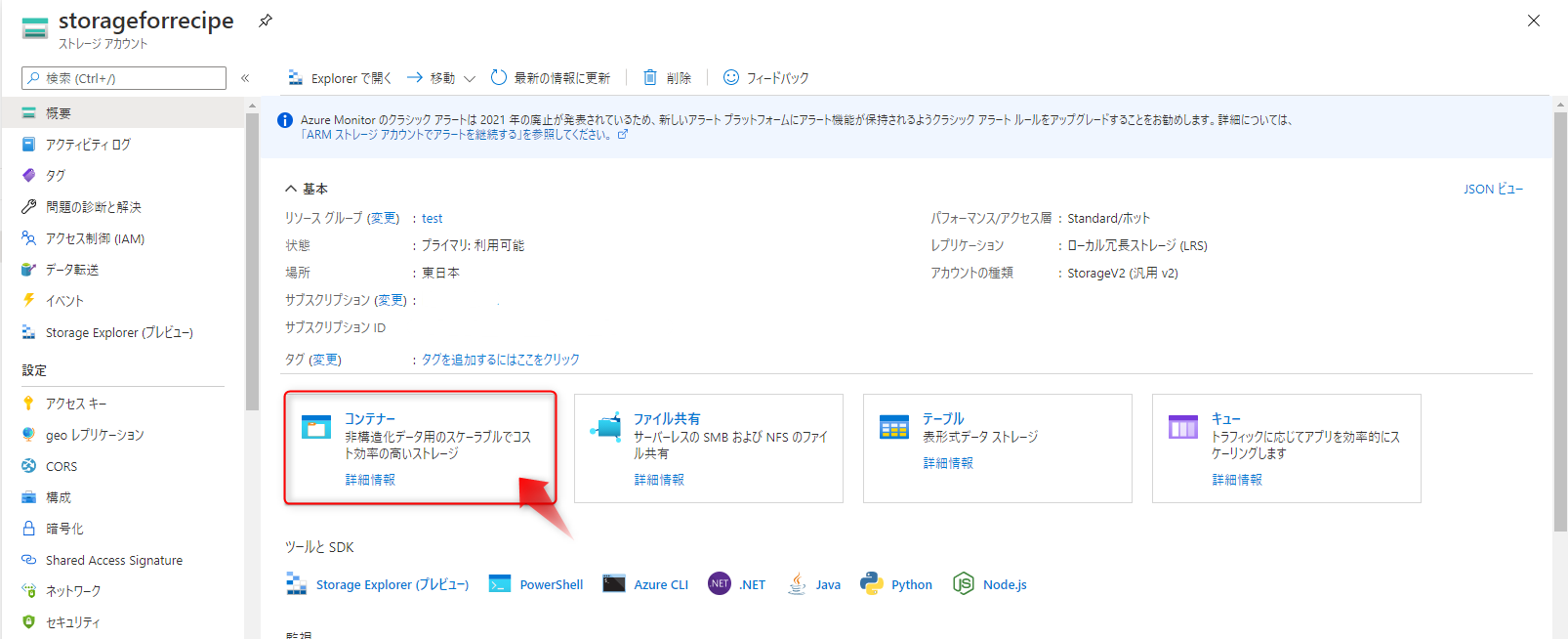
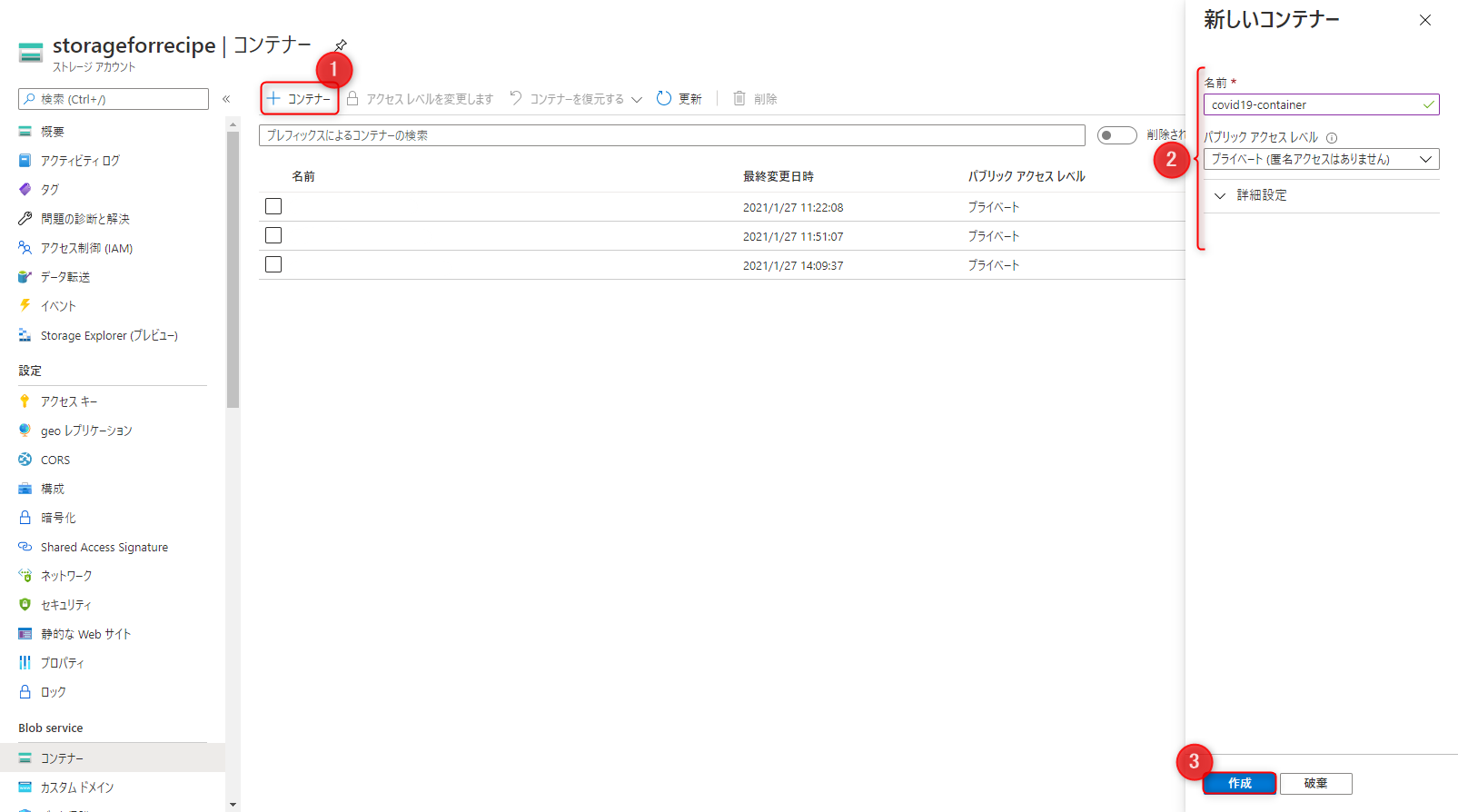
次にコンテナーを作成します。
最後に先程用意したCSVファイルをコンテナーにアップロードします。
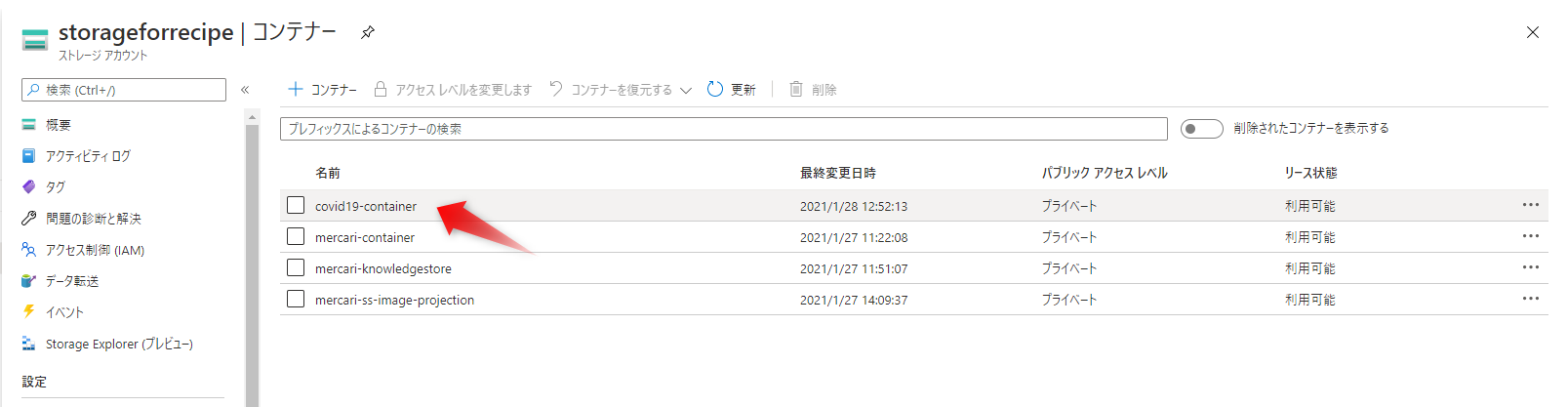
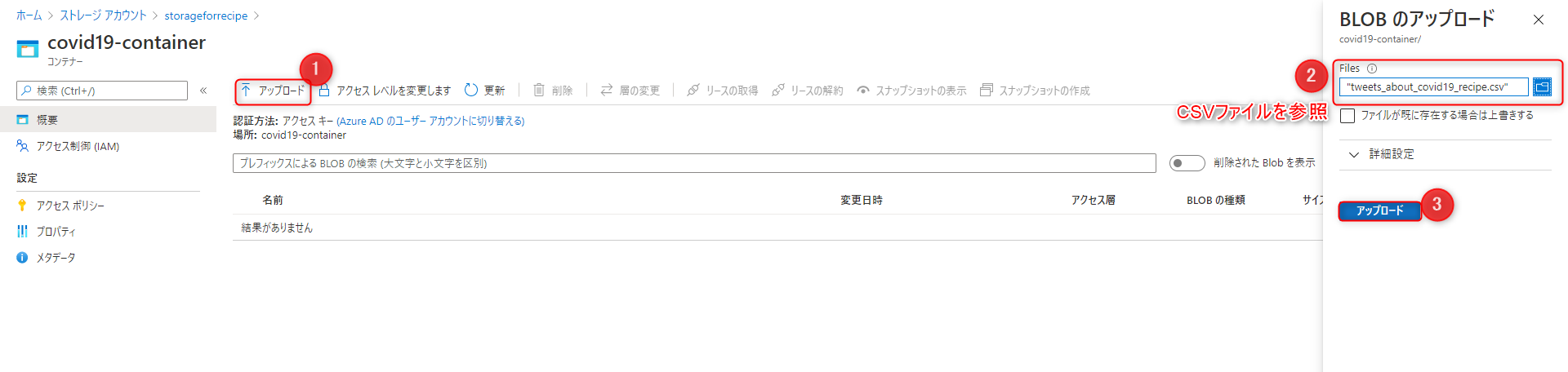
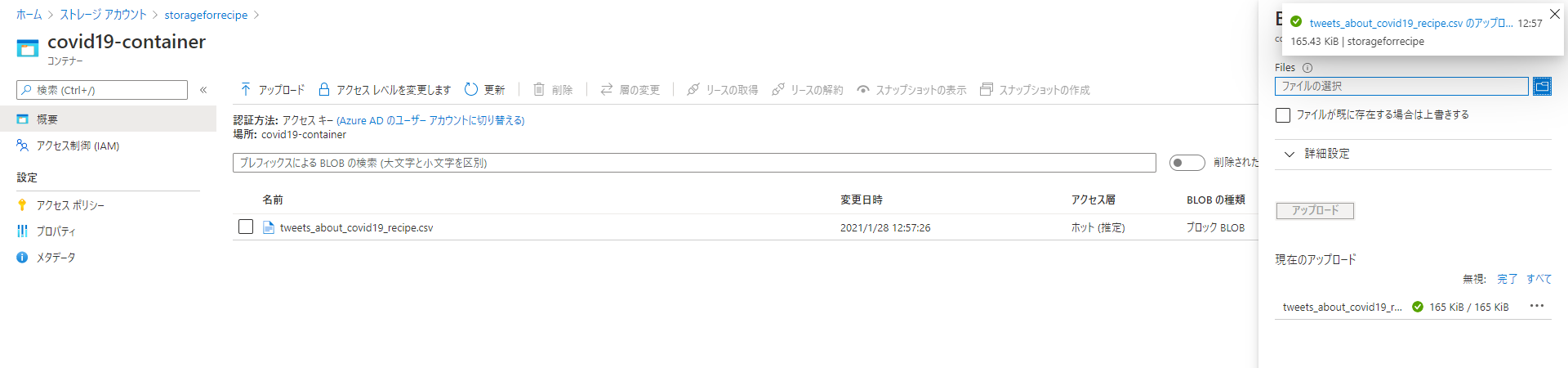
これでデータの準備ができました。
3. Cognitive Search で検索インデックスの作成
3-1. Cognitive Search リソースの作成
Azure Portalにログインし、Search Serviceを開きます。
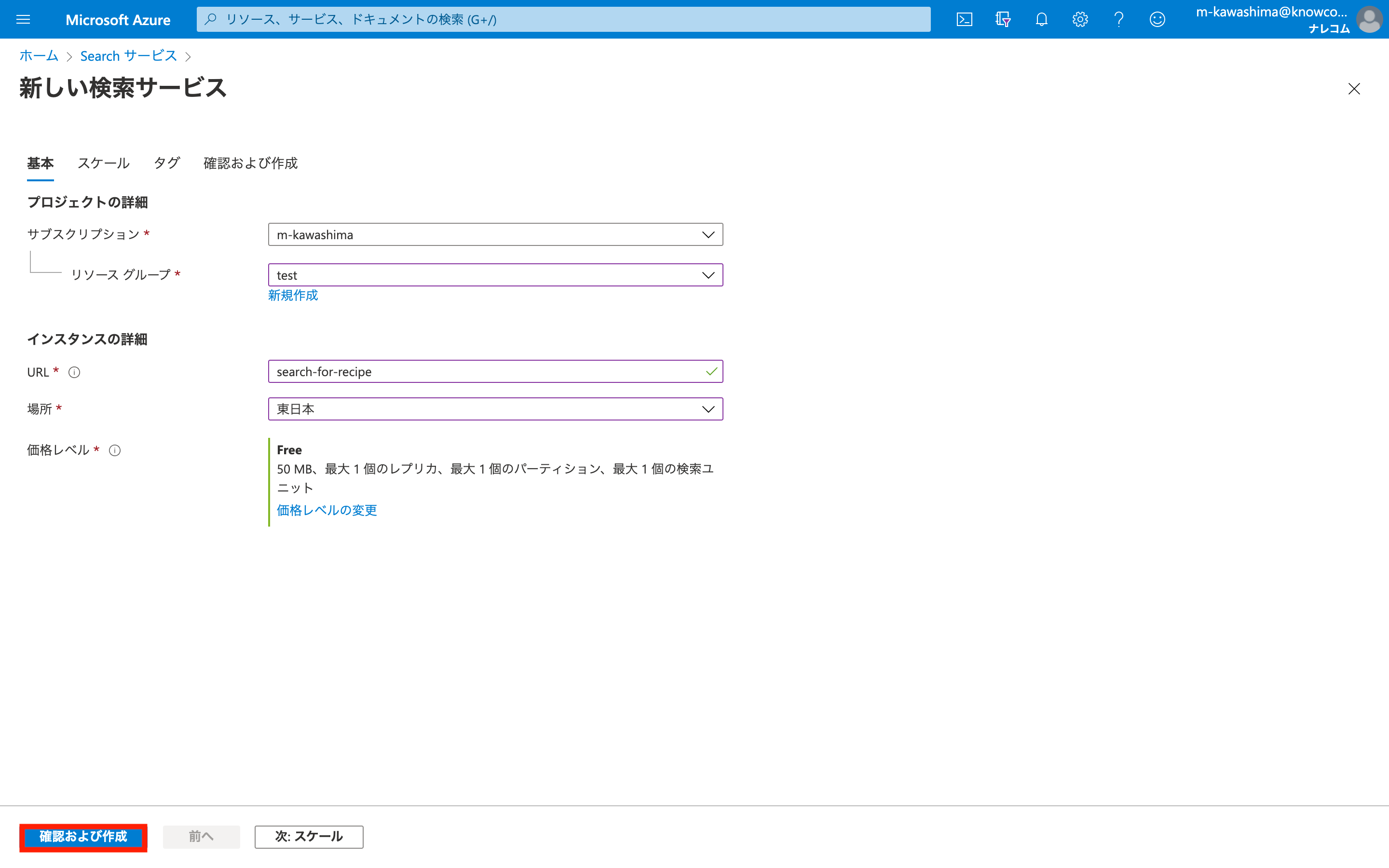
「Search サービスの作成」をクリックします。
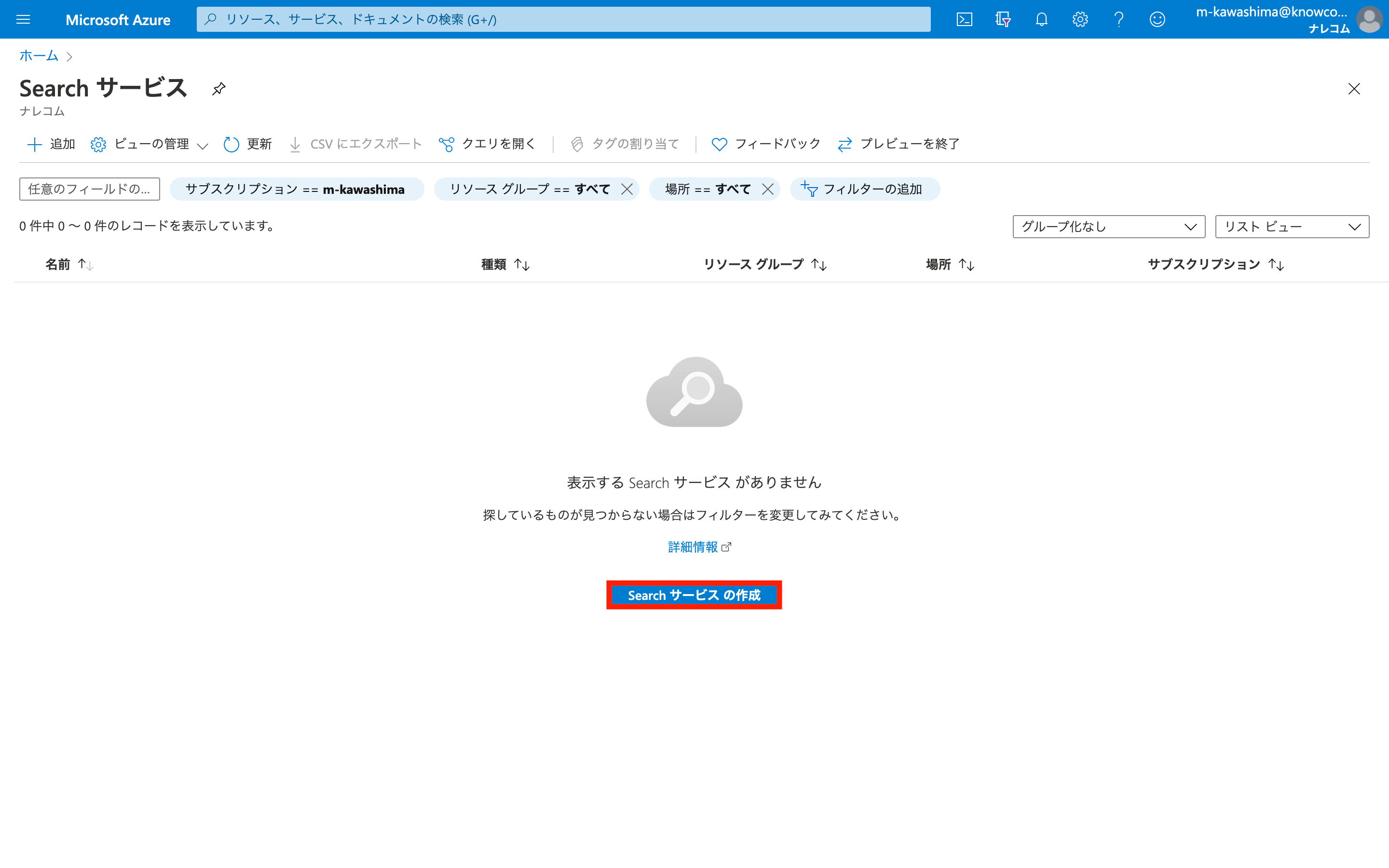
サブスクリプション~価格レベルまでを設定し、「確認および作成」でリソースを作成します。
価格レベルについての詳細:https://azure.microsoft.com/ja-jp/pricing/details/search/
これらを設定後、「確認および作成」で作成。
3-2. インデックス作成
作成したリソースに移動し、「データのインポート」をクリックします。
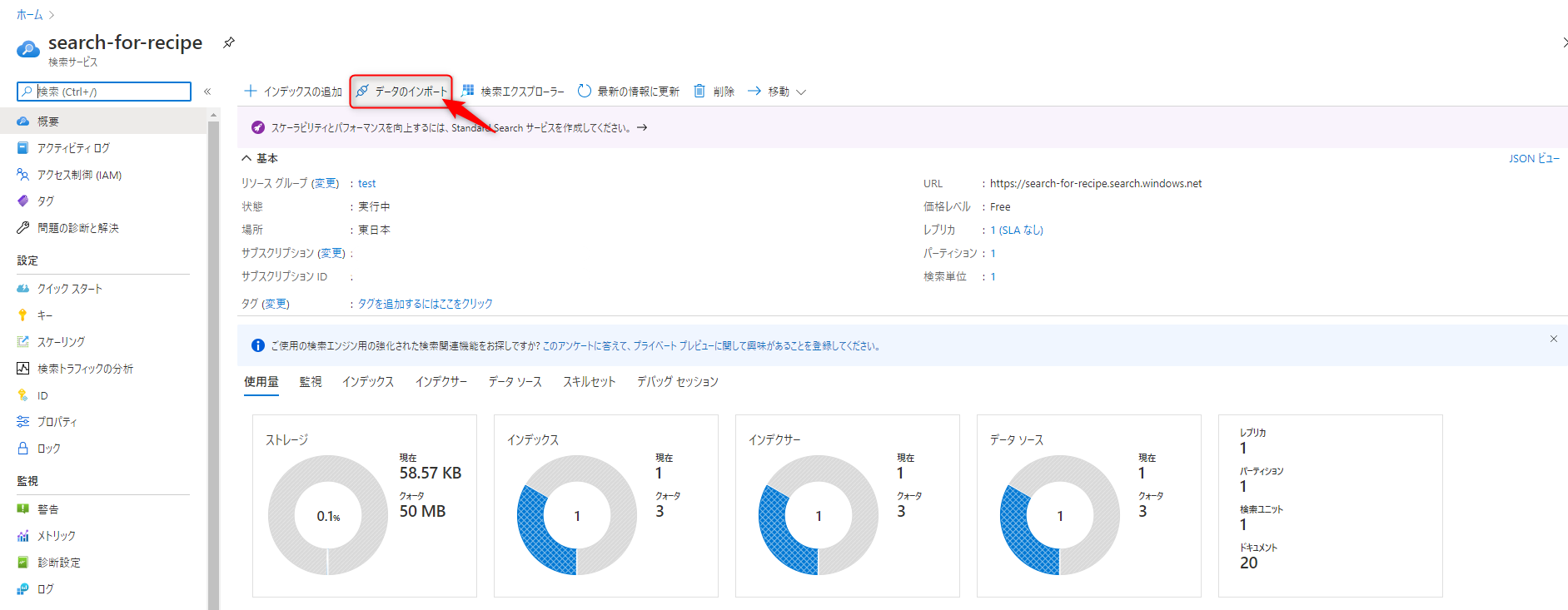
3-2-1. データに接続
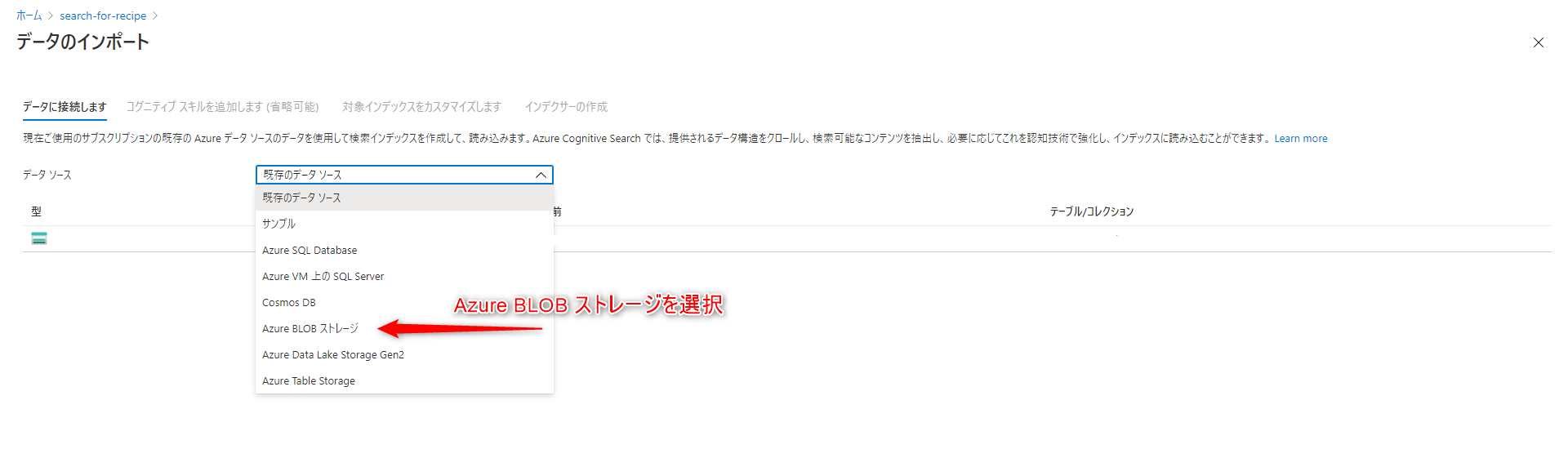
データソース:Azure BLOBストレージ
データソース名:任意
抽出されるデータ:コンテンツとメタデータ
解析モード:区切りテキスト
最初の行にヘッダーが含まれています:チェックを入れます。
区切り記号文字:,
接続文字列:「既存の接続を選択します」をクリック→データをアップロードしたコンテナーを選択します。
「次:コグニティブスキルを追加します」で次に進みます。
3-2-2. スキルの追加
3つの項目「Cognitive Servicesをアタッチする」、「エンリッチメントの追加」、「ナレッジストアへのエンリッチメントの保存」を設定していきます。
それぞれクリックで設定項目が開かれます。
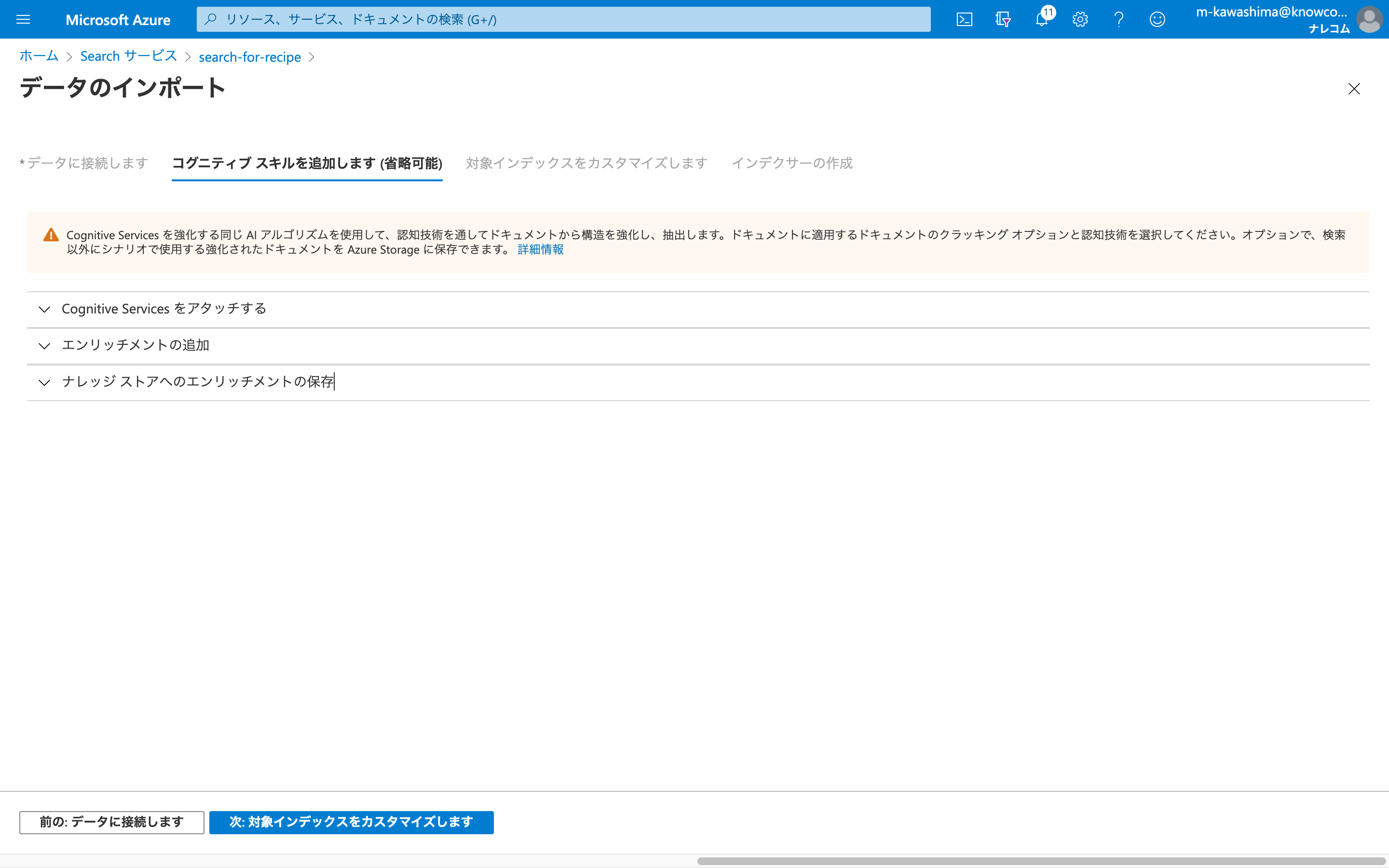
「Cognitive Servicesをアタッチする」
「無料」を選択すると、スキル適用できるドキュメント数が20個に限定されます。
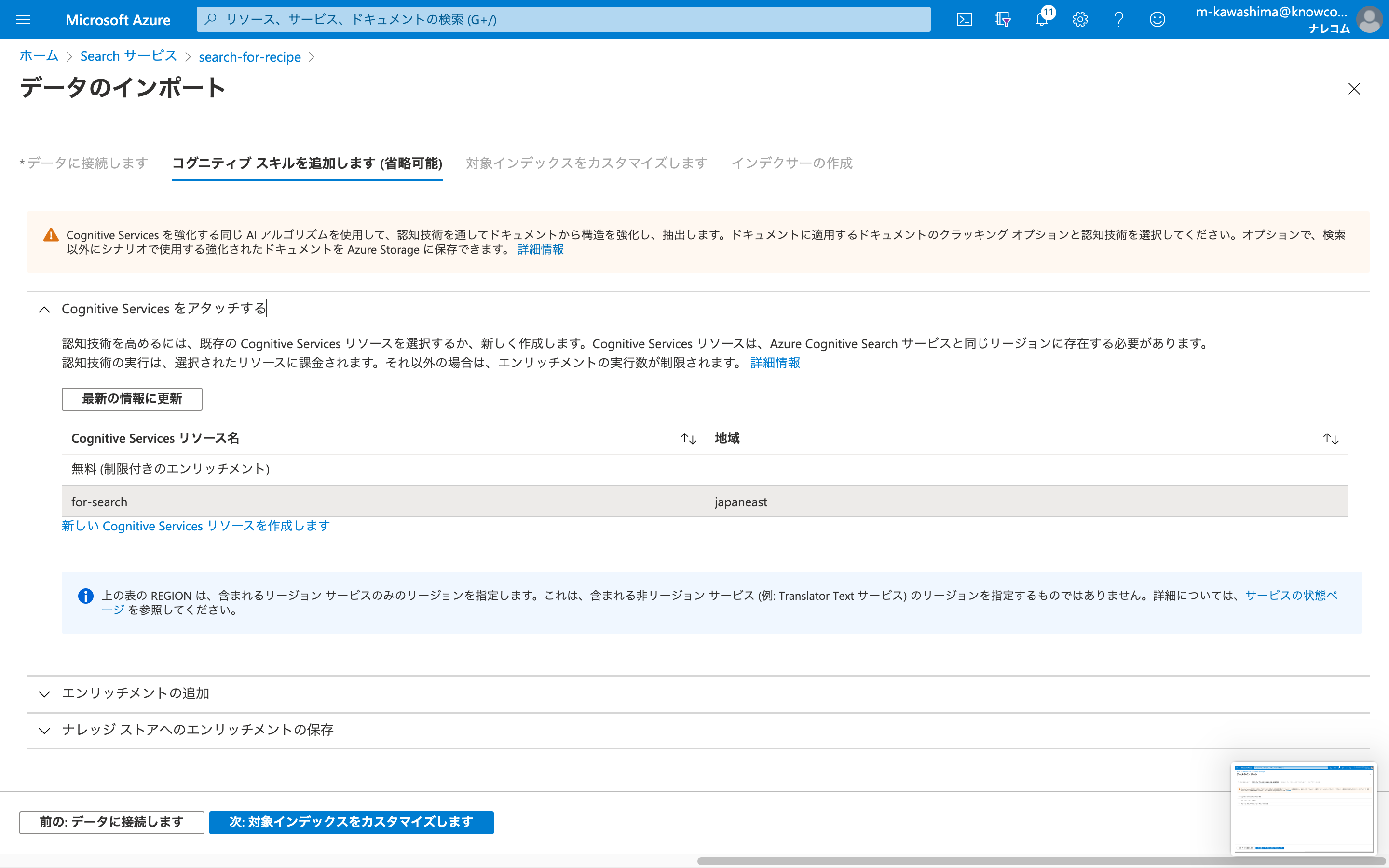
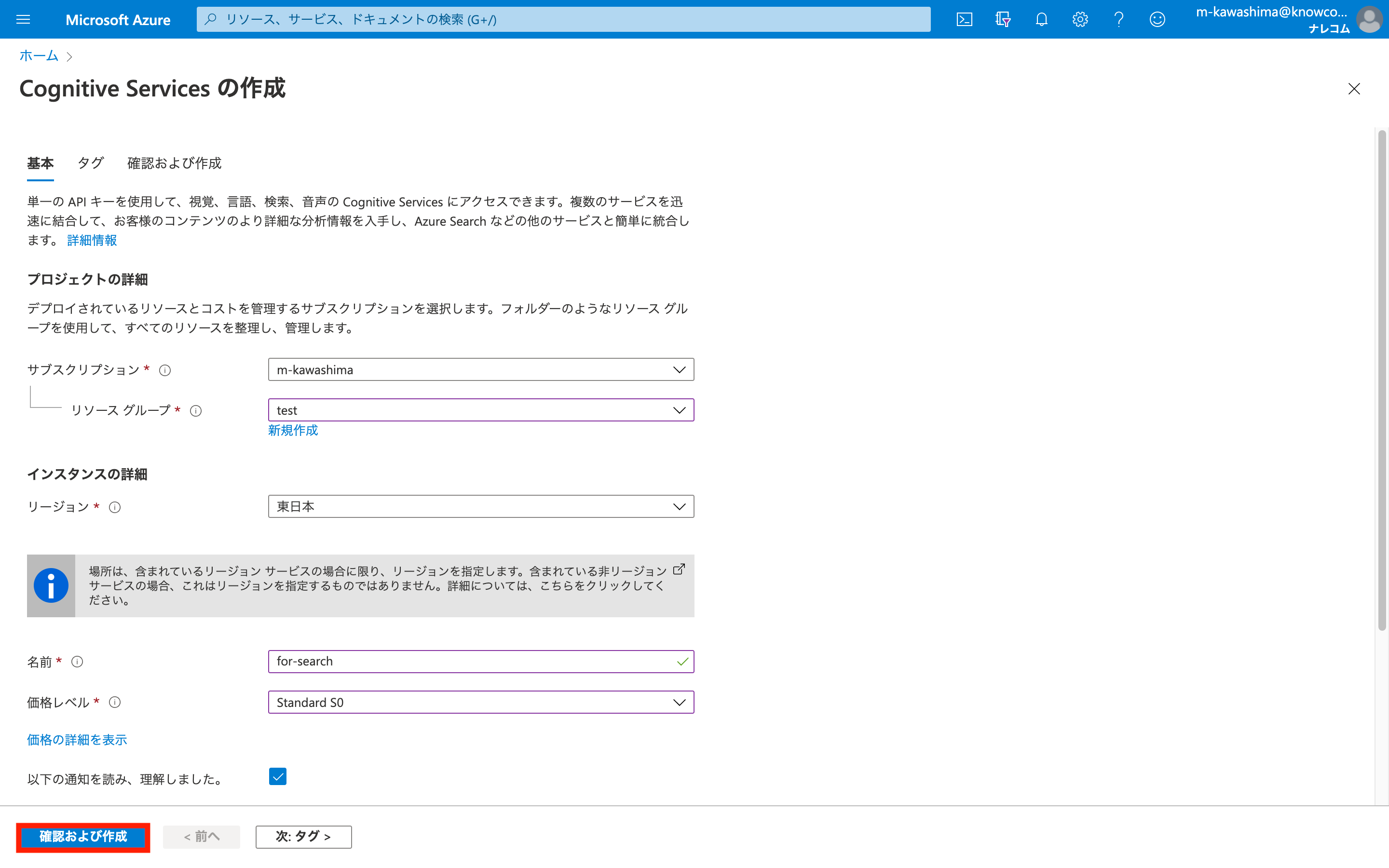
※Cognitive Servicesリソースを新規で作成する場合
価格レベルはS0を使うことができます。

数秒待ちます。
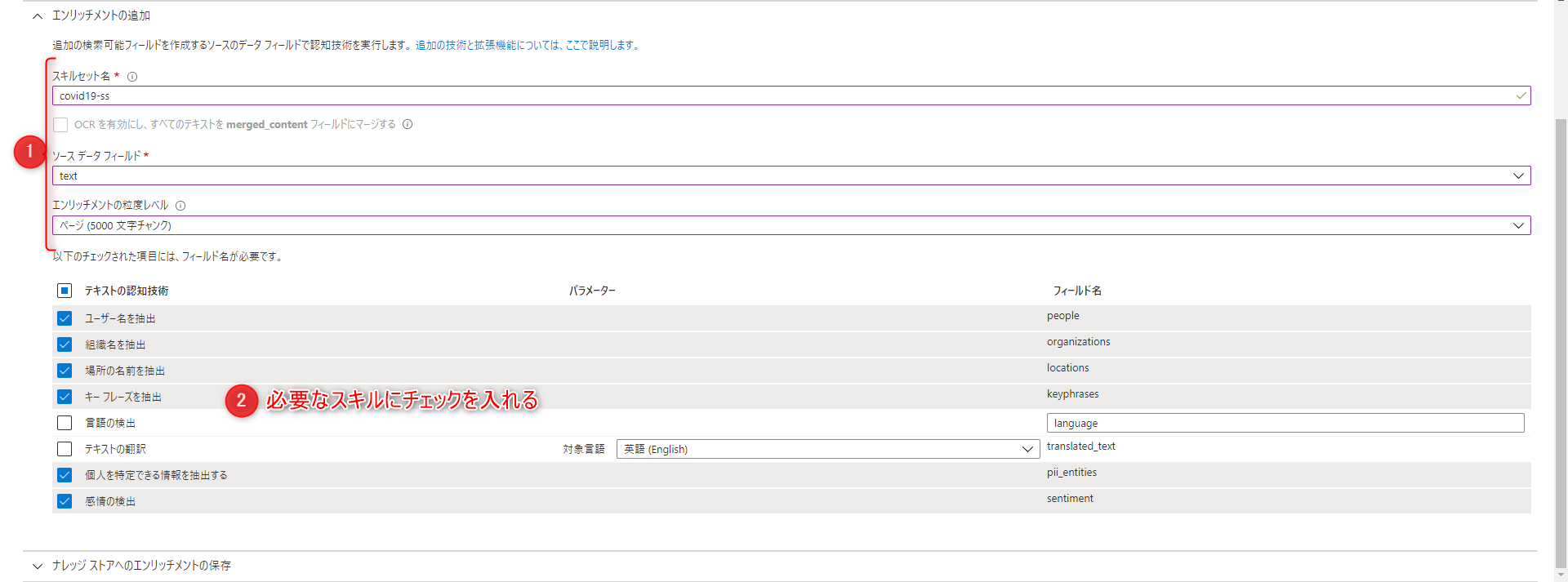
「エンリッチメントの追加」
スキルセット名:任意
ソースデータフィールド:text(感情分析などのスキルを適応させる列を指定します。今回はツイート本文の列である”text”を指定しています。)
エンリッチメントの粒度レベル:ページ(5000文字チャンク)
必要なスキルにチェックを入れます。
「ナレッジストアへのエンリッチメントの保存」を開きます。
これを設定することにより Power BI との連携が可能になります。
ストレージアカウント接続文字列:「規定の接続を選択します」をクリックします。
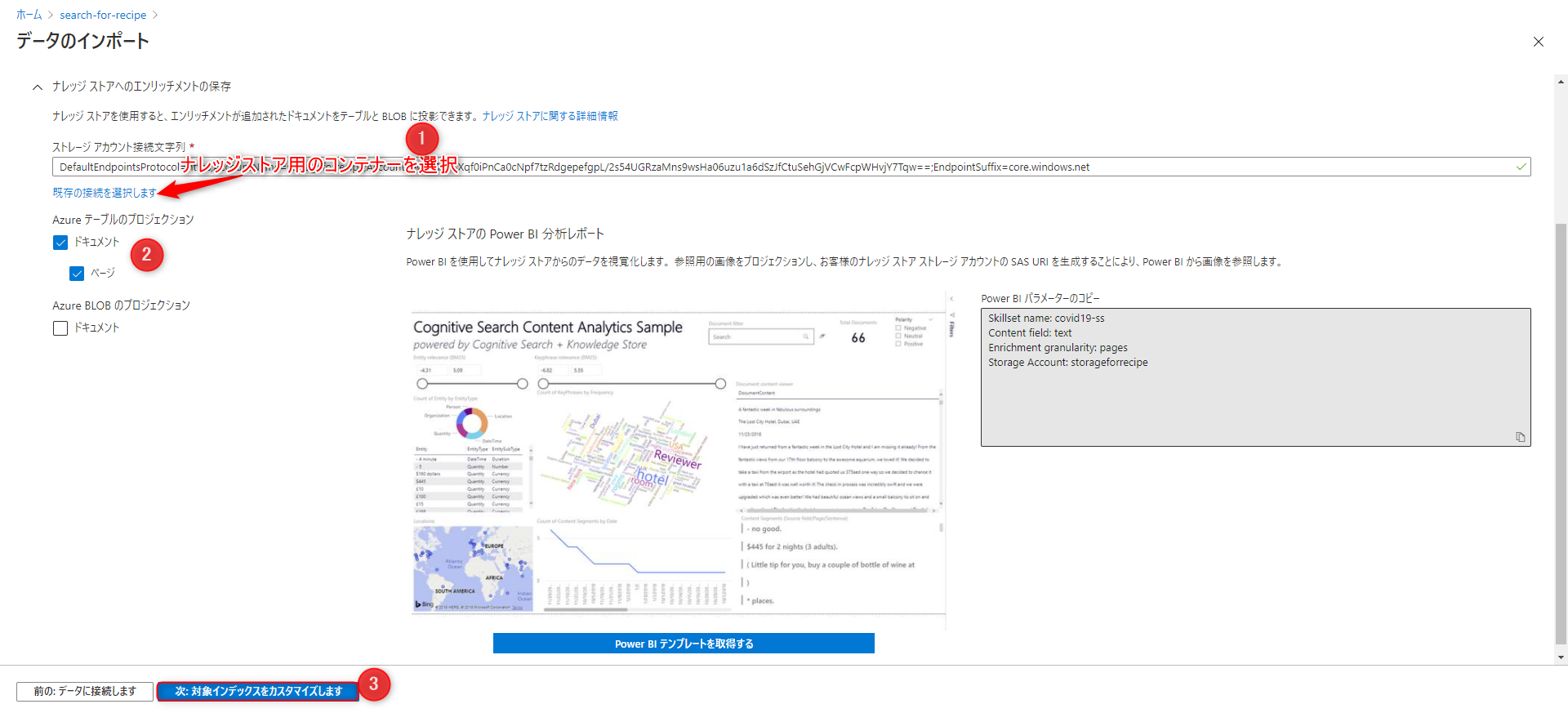
ナレッジストア用のコンテナーを選択します。
コンテナーを用意していない場合は、「+コンテナー」を押して作成します。
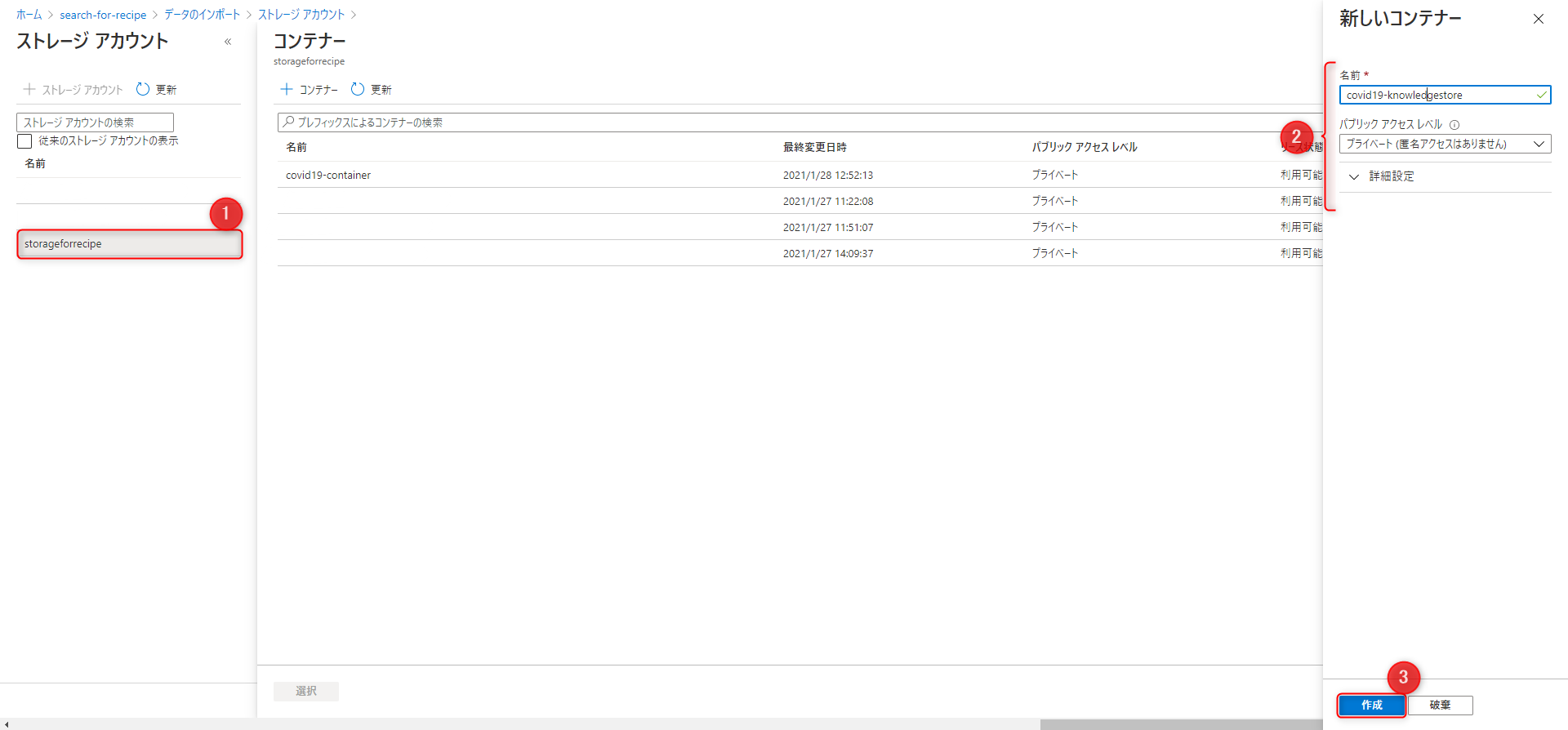
設定ができたら「次:対象インデックスをカスタマイズします」で次に進みます。
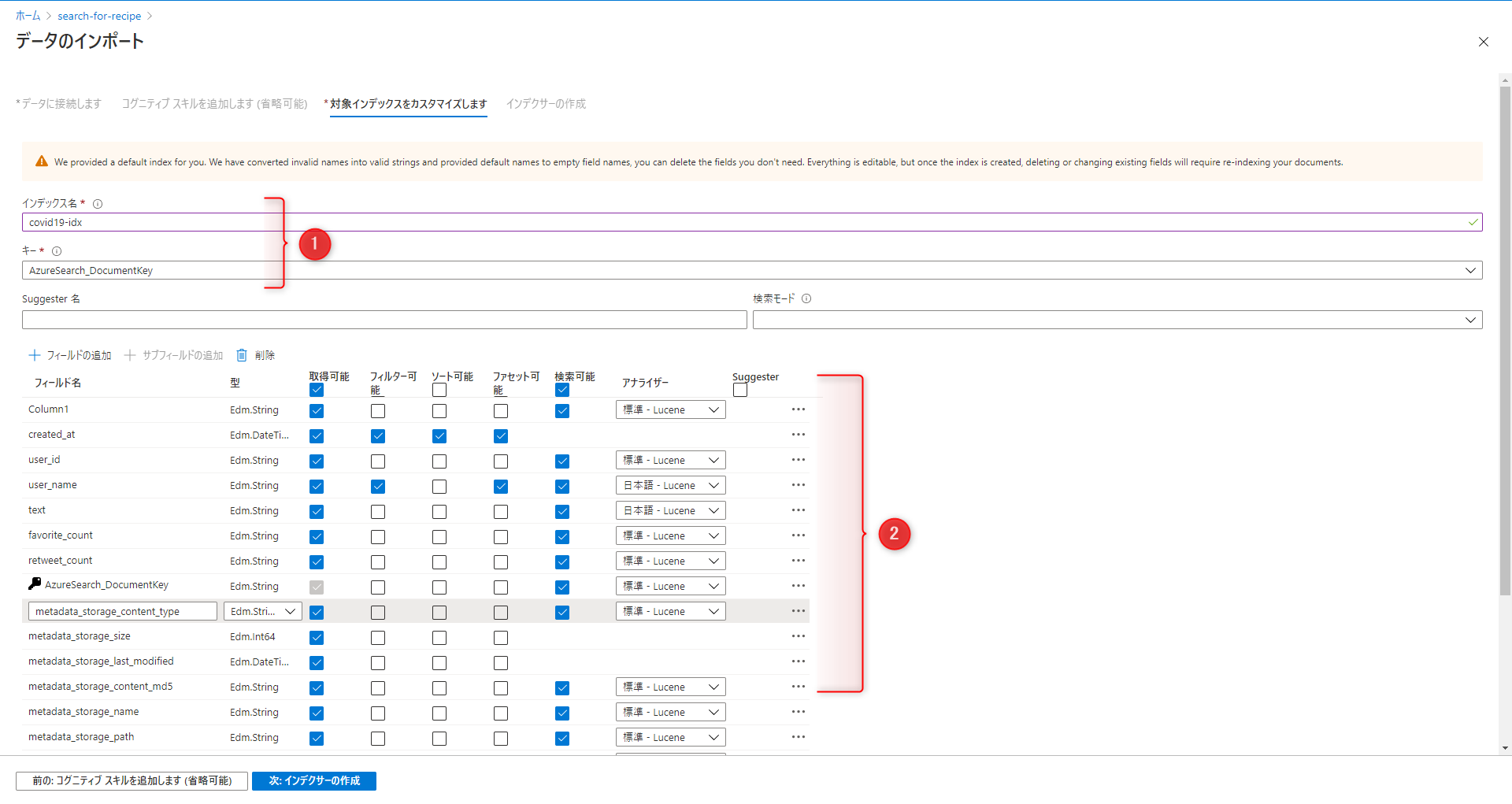
3-2-3. インデックスをカスタマイズ
インデックス名:任意
キー:AzureSearch_DocumentKey
フィールドには、データ型と属性があります。 上部に並んだチェック ボックスは、フィールドがどのように使用されるかを制御する “インデックスの属性” です。
引用元:https://docs.microsoft.com/ja-jp/azure/search/search-get-started-portal
取得可能:検索結果で取得したい項目かどうか
フィルター可能、ソート可能、ファセット可能:フィルタリング、並べ替え、ファセットのナビゲーション構造にフィールドを使用するかどうか
検索可能:フルテキスト検索の対象かどうか
アナライザー:
デモアプリのサイドバーに表示させたい項目には、「フィルター可能」「ファセット可能」いずれもチェックを入れます。
「」で次に進みます。
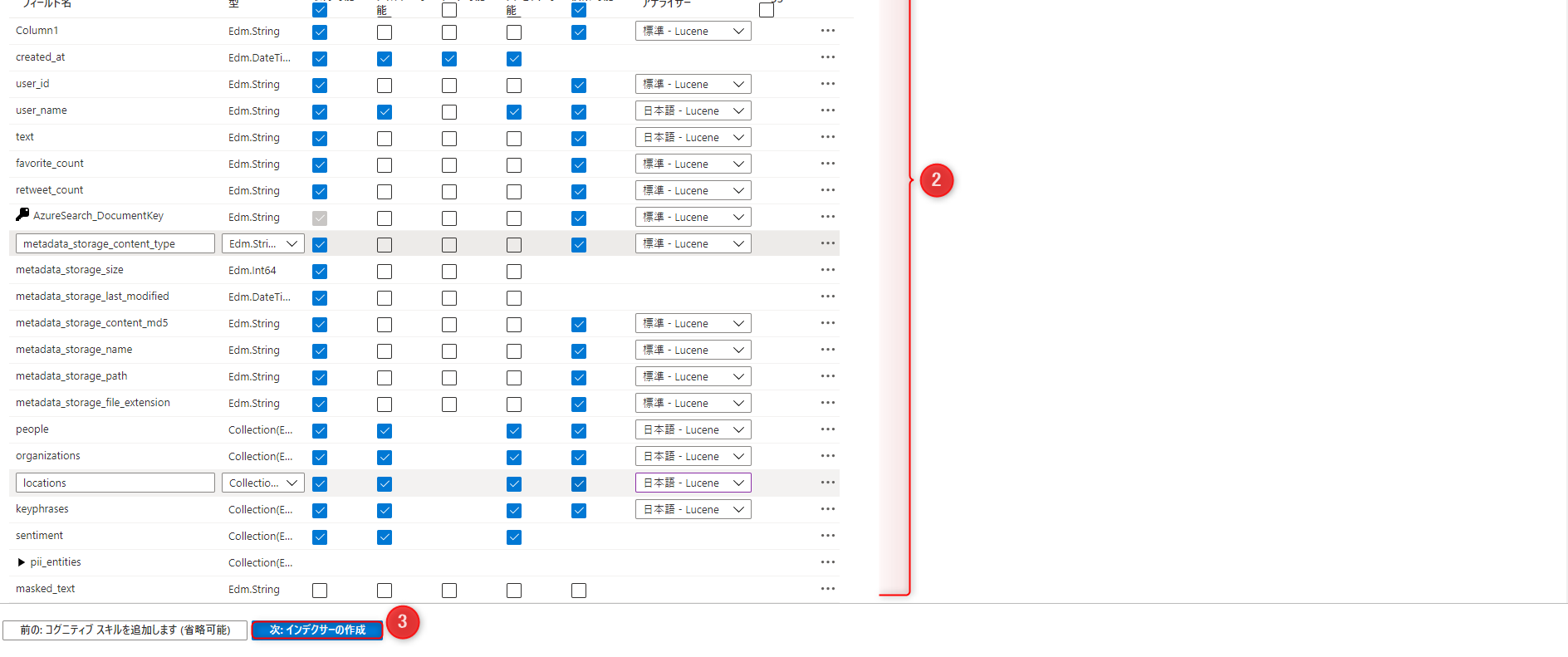
3-2-4. インデクサーの作成
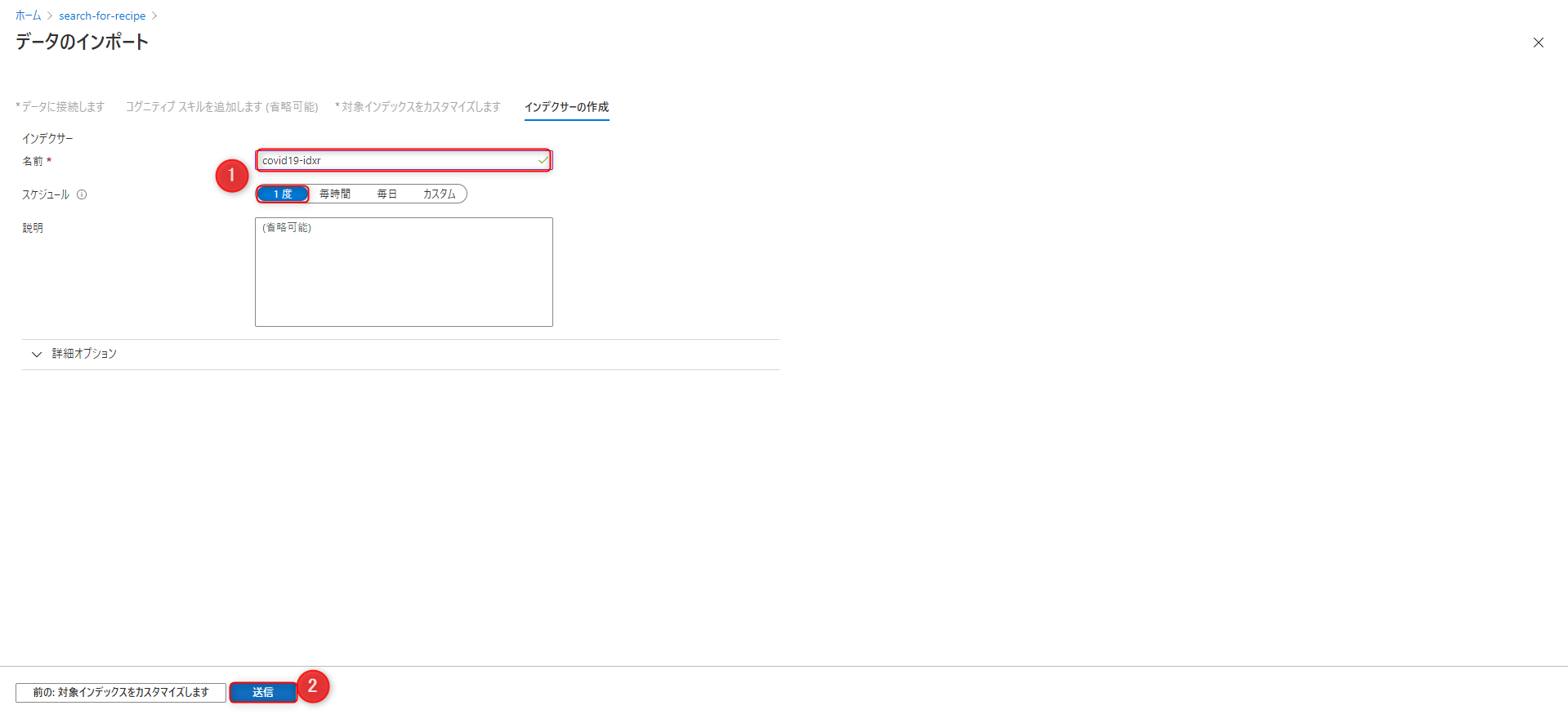
インデクサー名:任意
スケジュール:一度
これらを設定し、「送信」でインデクサーが実行されます。
3-3. 言語設定
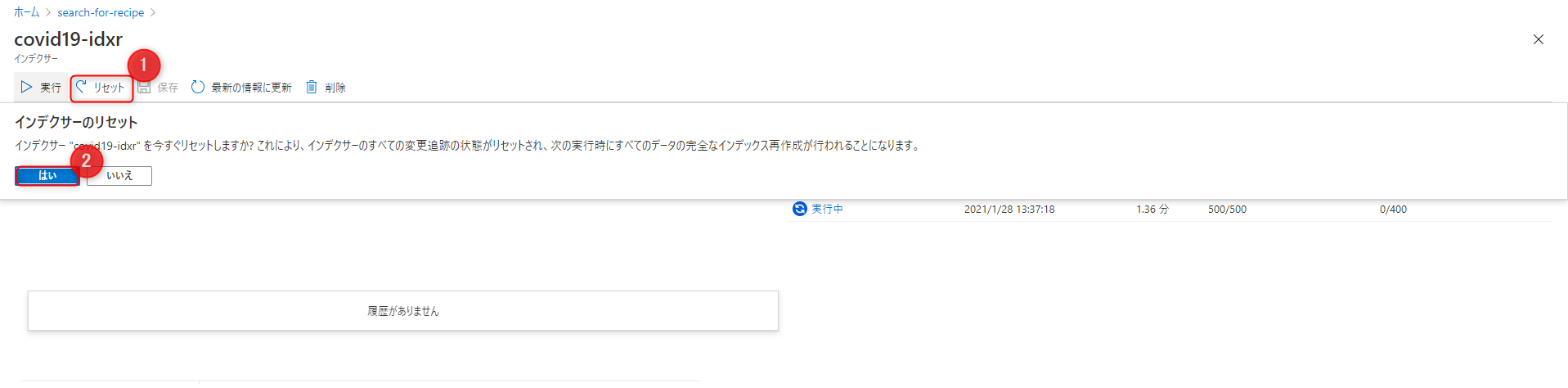
このままだと言語設定が英語のままスキルが実行されてしまうため、一旦実行中のインデクサーを止め、言語を設定してからインデクサーを再度実行する必要があります。
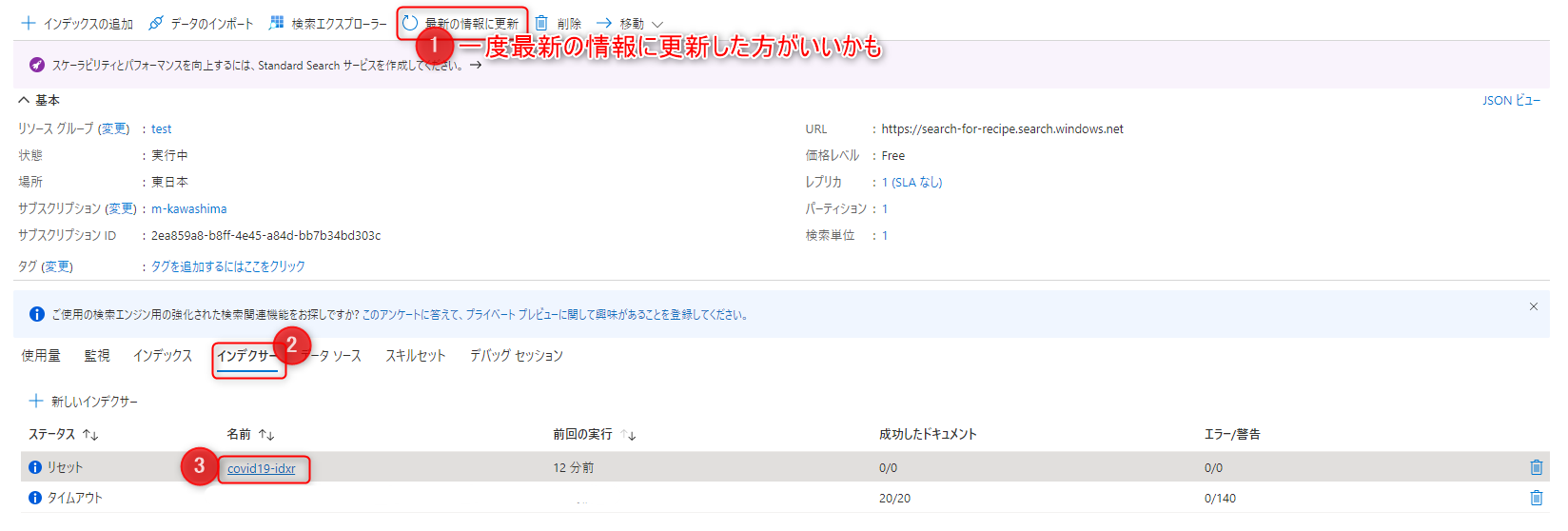
「インデクサー」を開きます。

インデクサーをリセットします。
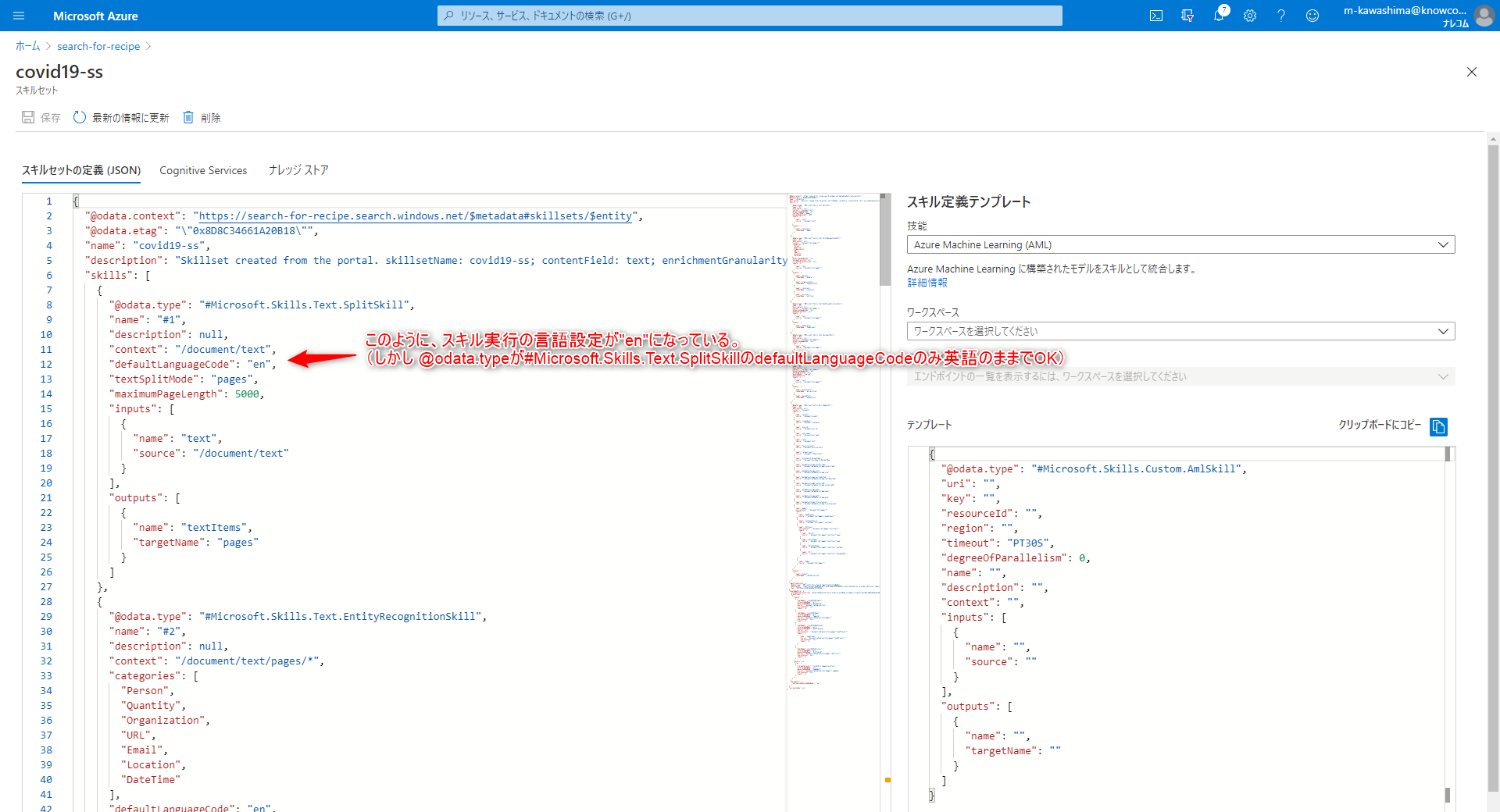
「スキルセット」を開きます。

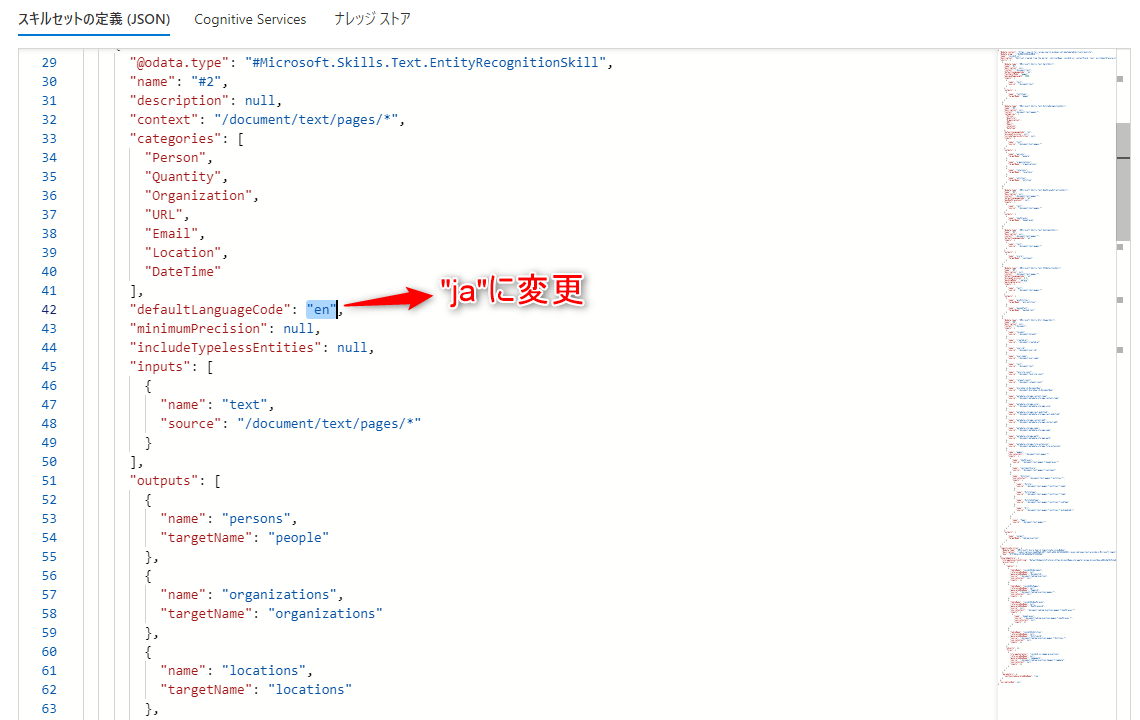
言語を英語→日本語に変更します。
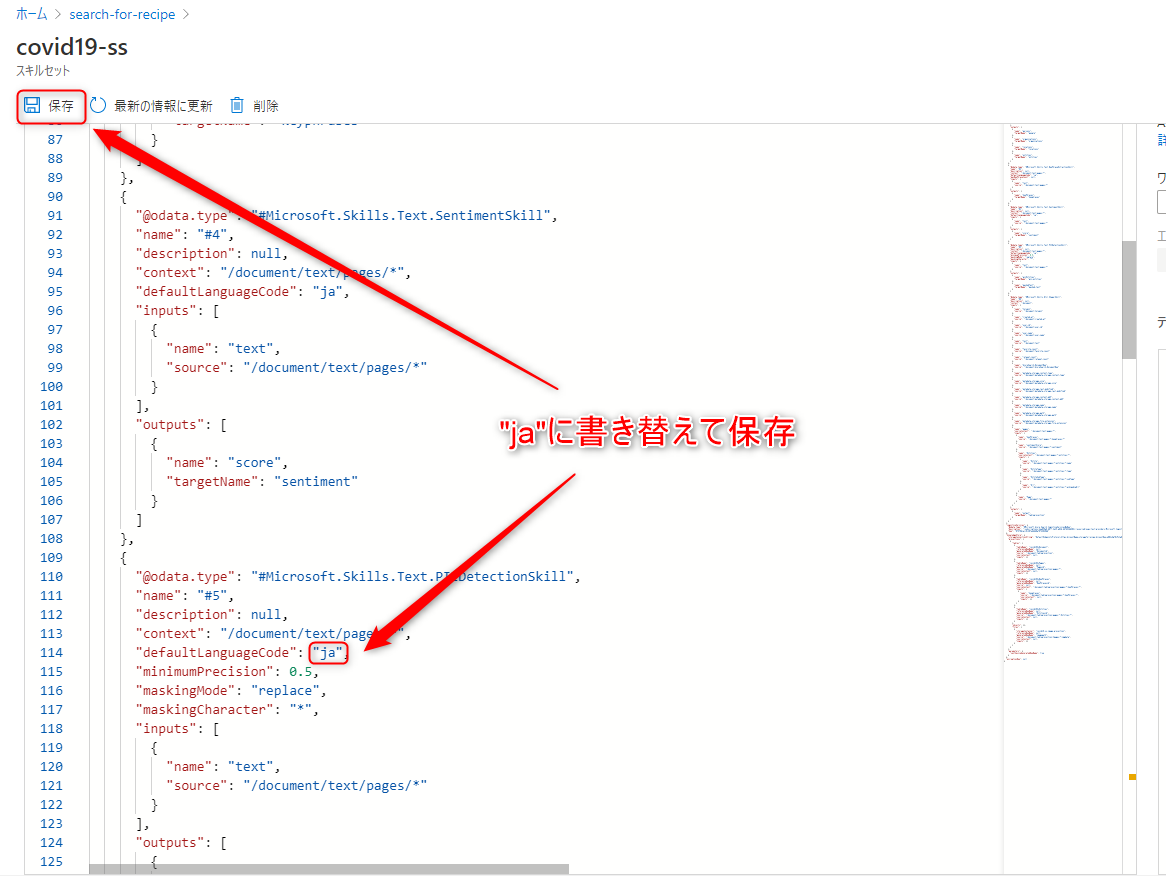
“@odata.type”: “#Microsoft.Skills.Text.SplitSkill” 以外の defaultLanguageを、enからjaに書き替え、「保存」で変更を保存できます。
再度「インデクサー」を開きます。
インデクサーを再度実行します。
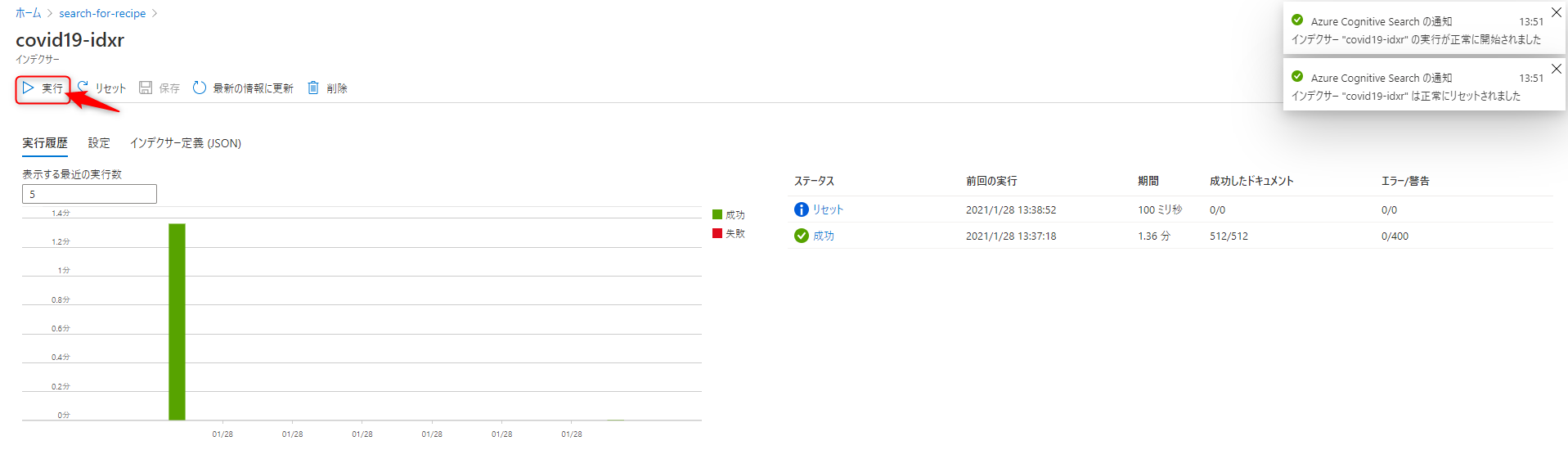
インデックスが作られました。
512個のツイートで1分少し要しました。
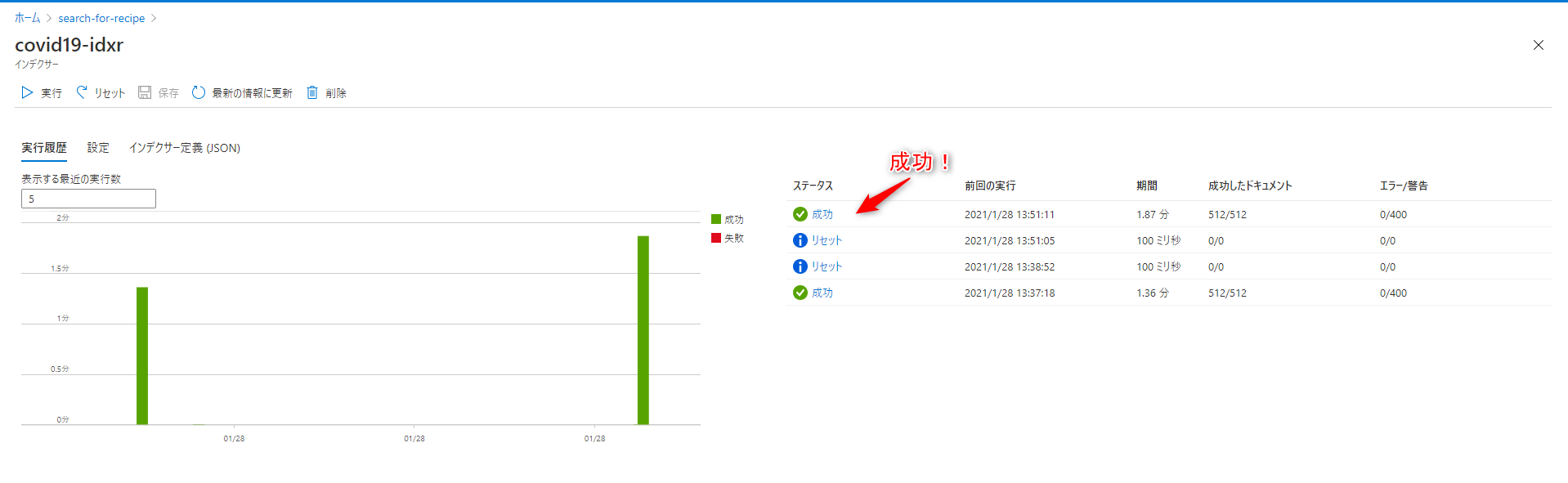
3-4. 検索エクスプローラーでクエリを実行
インデックスを開きます。

「検索」をクリックすると、下に検索結果の一覧が表示されます。
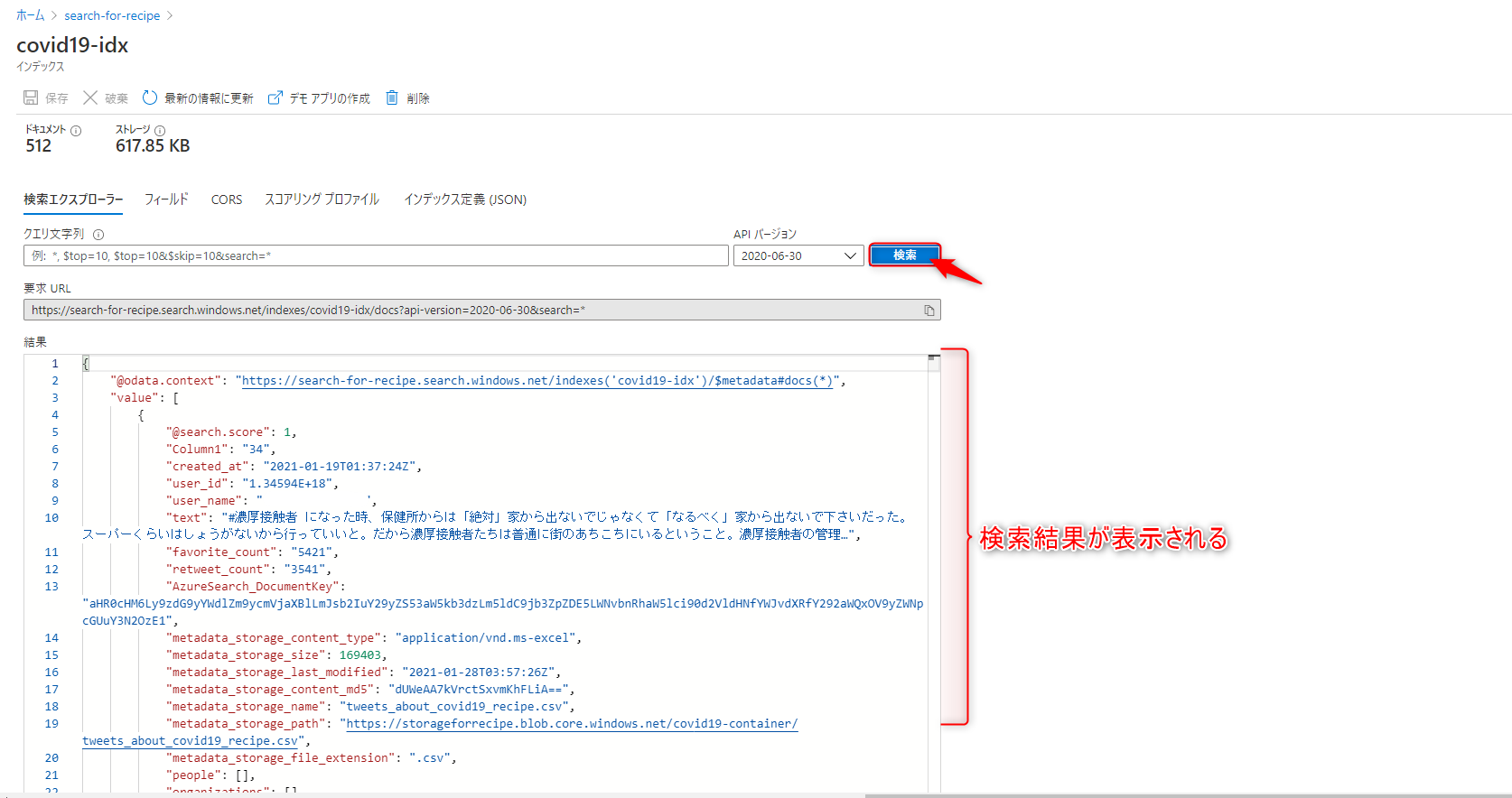
次は簡単な検索クエリを書いて結果をみてみます。
$search=コロナ&$select=created_at,text,sentiment,keyphrases,locations,people
これで”コロナ”を含むツイートを検索し、日時・本文・感情・キーフレーズ・場所・人物 の項目のみ結果に表示させることができます。
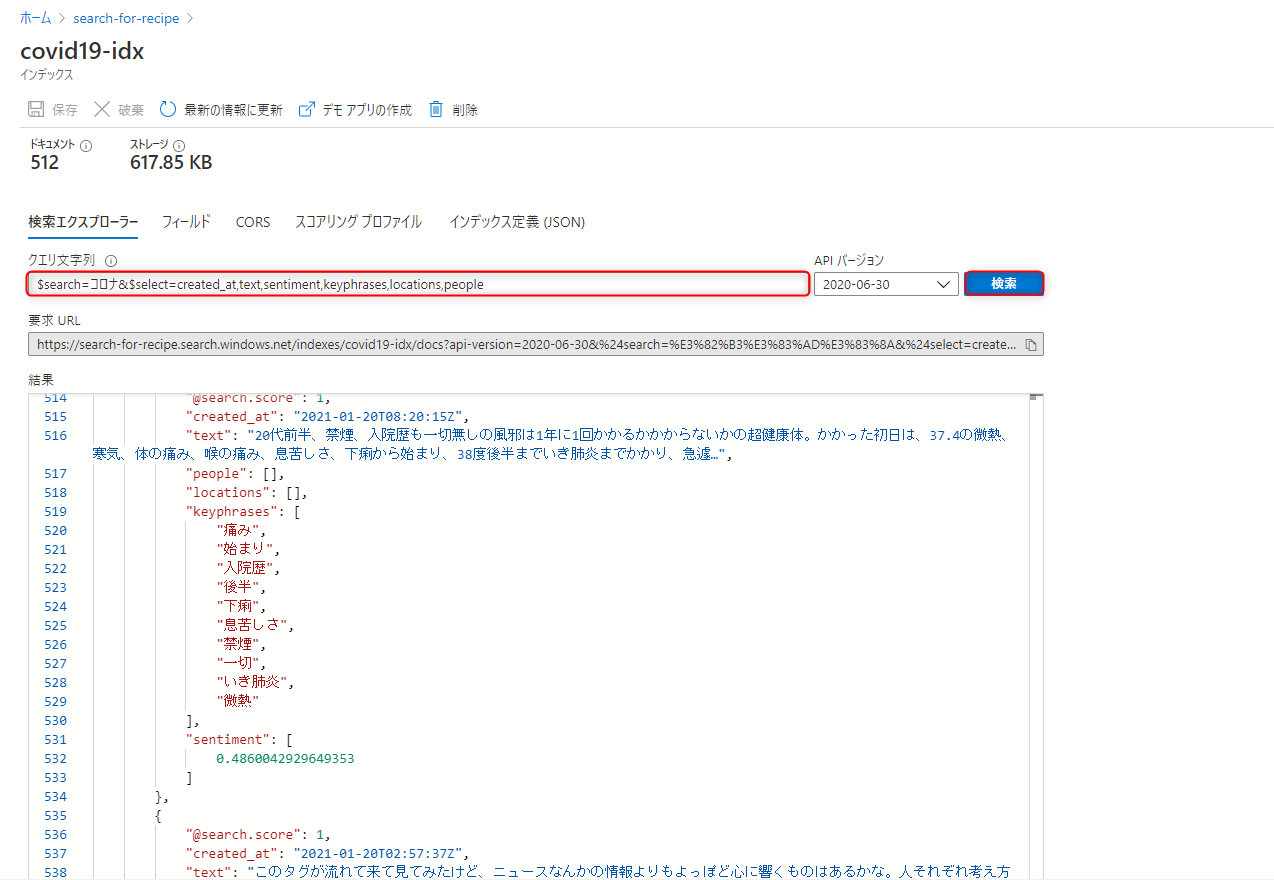
クエリパラメーターの詳細については、以下公式ドキュメントにてご確認いただけます。
https://docs.microsoft.com/ja-jp/azure/search/search-explorer
https://docs.microsoft.com/ja-jp/azure/search/search-query-overview
おわりに
本記事では、データの準備~検索インデックスの作成 までの手順をまとめました。
次回、Part2. デモアプリの作成 で検索アプリを作成し、
Part3. Power BI レポートの作成 で最初に示したワードクラウドなどを表示させていきます。
簡単なステップで試せるものですので、ぜひご覧ください。
参考リンク
https://docs.microsoft.com/ja-jp/azure/search/search-create-service-portal
https://docs.microsoft.com/ja-jp/azure/search/search-get-started-portal
https://docs.microsoft.com/ja-jp/azure/search/cognitive-search-quickstart-blob
https://docs.microsoft.com/ja-jp/azure/search/knowledge-store-create-portal
https://docs.microsoft.com/ja-jp/azure/search/search-explorer
