はじめに
先日、Azure Machine Leaning のプレビュー機能として「モデルカタログ」が公開されました。こちらは質問応答やテキスト分類など様々な学習済の言語モデルが登録されており、中には最近話題のGPT(…の、古いバージョン)も含まれていたりします。
今回はその中から、Databricks 社がLLMのオープン化を掲げて開発しているモデル「Dolly-v2-12b」について取り上げます。DollyはCC-BY-SAライセンスの元で公開されており、商用利用を含め誰でも無料で利用できる(v1は学習データにChatGPTを使っていたので規約により商用利用できなかった)ことが売りになっています。開発経緯・目的について詳しくはDatabricks公式サイトをご覧ください。
まずはHugging Faceに掲載されているモデルの解説を見てから、その後で実際にAzure上で使ってみます。
Model Card
出典:databricks/dolly-v2-12b | Huggingface
概要
dolly-v2-12bはDatabricks上で訓練された、命令追従型(instruction-following)大規模言語モデルです。
Dollyはpythia12-bを基に、InststructGPTの論文にあるタスク(ブレインストーミング、分類、オープン/クローズQ&A、生成、情報抽出、要約)から、Databricksの社員が生成した15000個の質問応答コーパスによってfine-tuningして訓練されています。
dolly-v2-12bは最先端のモデルではありません。しかし、ベースとなったモデルの特徴とは異なる、驚くほど質の高い対話を行うことができます。
Dolly-v2はより小規模なモデル(dolly-v2-7b(pythia-6.9bベース)、3b(pythia2.8bベース))も利用可能です。
制限
訳注:以下単純に”dolly”と表記した場合は、dolly-v2-12bの事を指します。
パフォーマンス
dollyは最先端の生成モデルではありません。そして、より最新、あるいは大規模なコーパスによるモデルと競合するような設計ではありません(定量的なベンチマークは現在実施中です)。
dollyモデルファミリーは現在も活発に開発が進んでおり、欠点が網羅されている訳ではありませんが、知見の記録と共有のため、既知の制限や誤動作についてここに記載します。
dollyが特に苦手としているのは、
- 構文が複雑なプロンプト
- プログラミング(コード作成)
- 計算・日付と時刻
- 事実誤認・幻覚
- 自由回答
- 特定の長さのリストの列挙
- 文体の模倣
- ユーモアのセンス
また、オリジナルのモデル(pythia)と比べて、書式の整った手紙などを作成する機能が備わっていないことも分かっています。
データセット
すべての言語モデルの例にもれず、dollyはコーパスの特徴と制限がモデルに影響しています。
- pythiaの訓練データセット(The Pile)はWeb上から取得された文書から作成されており、多くのWebコンテンツベースのデータセットと同様不快なコンテンツを含んでいます。
そのため、有害なコンテンツを明示的に生成するよう指示した場合はもとより、明示していない場合にも暗黙に偏見、あるいは有害なコンテンツが出力される場合があります。 - dollyをチューニングするための訓練データは2023年3月から4月にかけてDatabricksの社員が作成した自然言語の会話であり、QAや要約などで参照する文章にWikipediaのものが含まれています。
我々の知る限りではわいせつ物や知的財産、個人情報などは含まれていませんが、誤字脱字や事実誤認、ウィキペディアンに見られるバイアスが含まれている可能性があります。
最後に、このデータセットはDatabricks社員の興味や恣意的な選択を含んでいる可能性があり、全世界の人口を代表するものではありません。
Databricksは、すべての個人と組織の可能性を最大限に引き出せる、有用かつ正直で無害なAI技術を開発するため、継続的な研究活動に取り組んでいます。
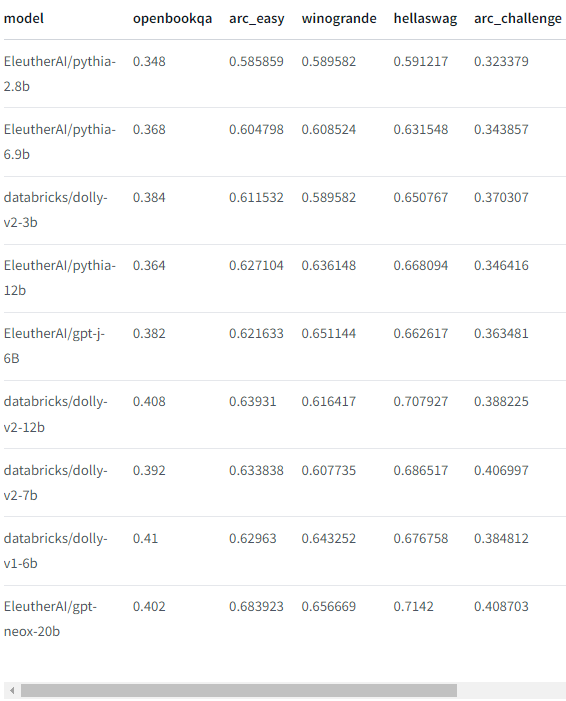
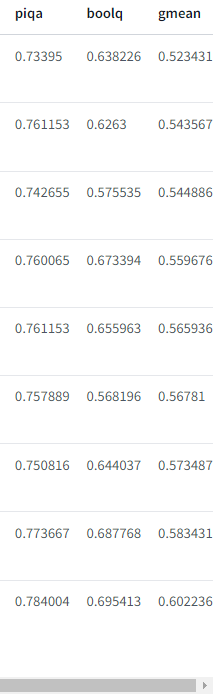
ベンチマーク
以下に、EleutherAI LLM評価ハーネスを使用した各モデルのベンチマーク結果を示します。
前述したとおり、dolly-v2-12bが最先端という訳ではなく、いくつかのベンチマークではdolly-v1-6bモデルを下回っているのが実証されています。
これはチューニング用データセットの構成やサイズに起因すると考えられていますが、性能のばらつきの原因に関する確証を得るためには、さらに研究が必要です。
実際に使ってみた
デプロイ
モデルカタログでは学習済みモデルが公開されており、Azure ML のデプロイ機能を用いれば即座に試せる環境を作ることができます。早速カタログからDollyを探してみましょう。
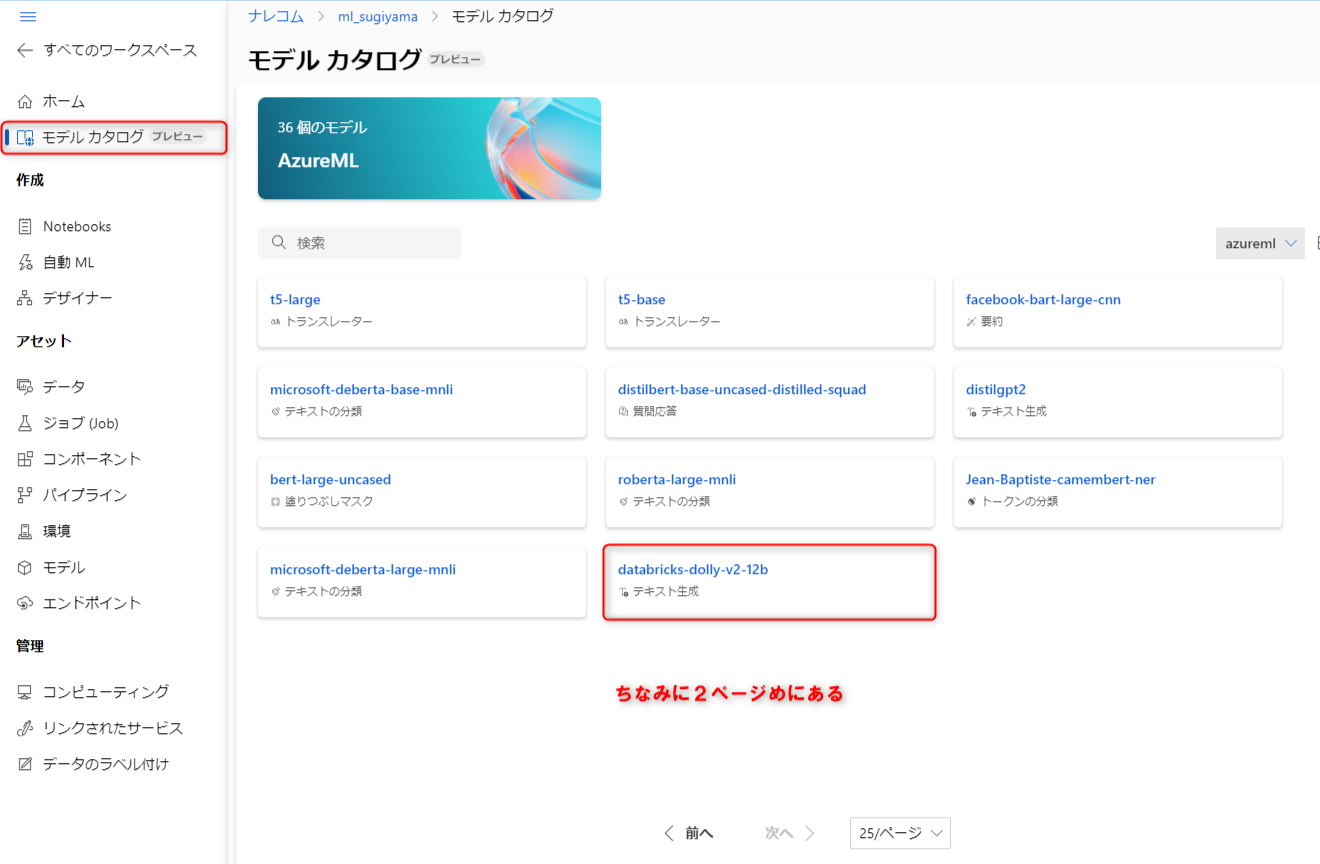
モデル概要の画面にすでにテスト用ボックスが用意されているモデルもあります。Dollyにはないので「デプロイ」を選択してエンドポイントを作ります。
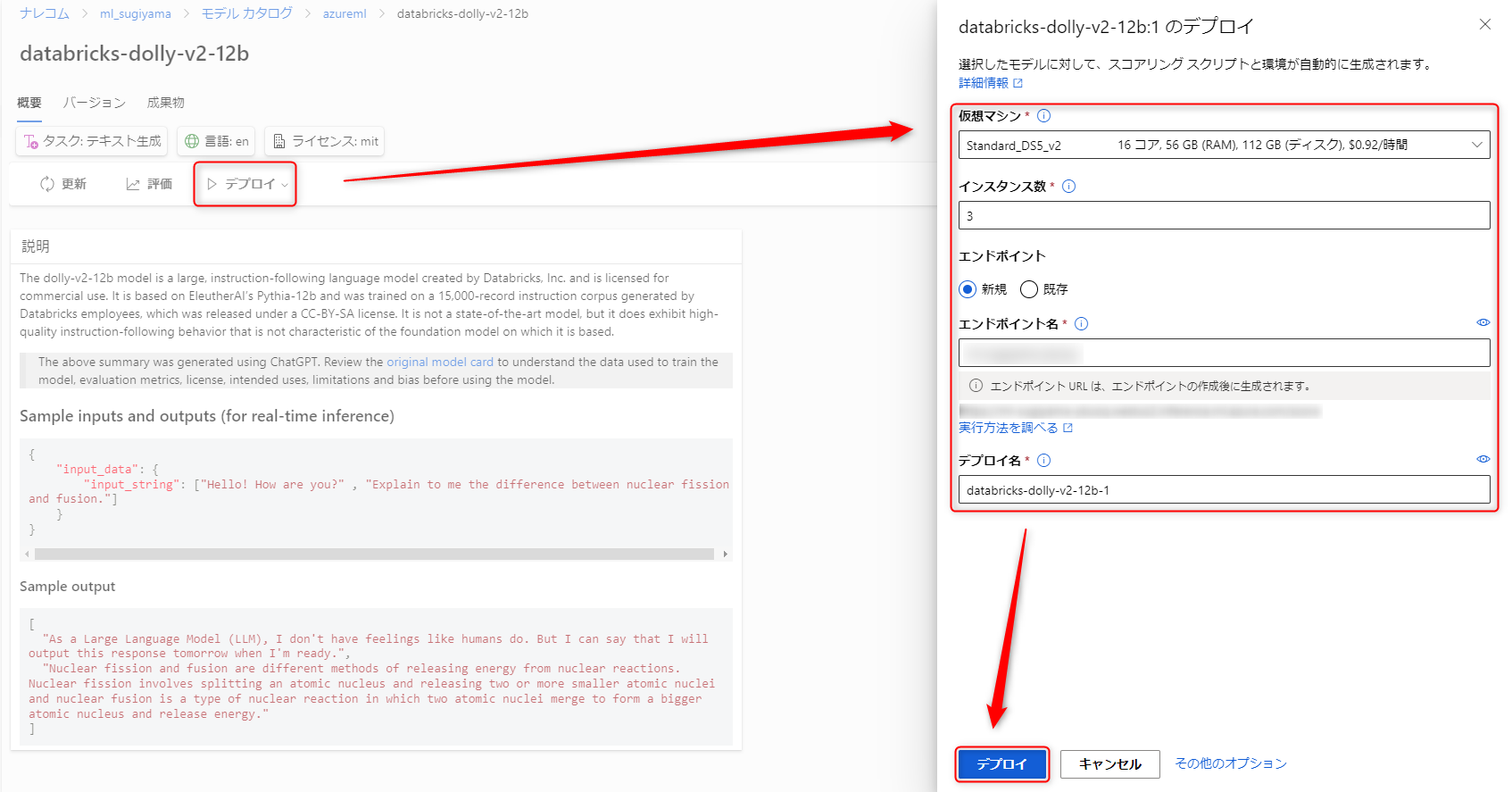
テスト
デプロイが完了するとエンドポイントの画面に「テスト」タブが追加されます。
まずはサンプル通りに打ち込んでみます。
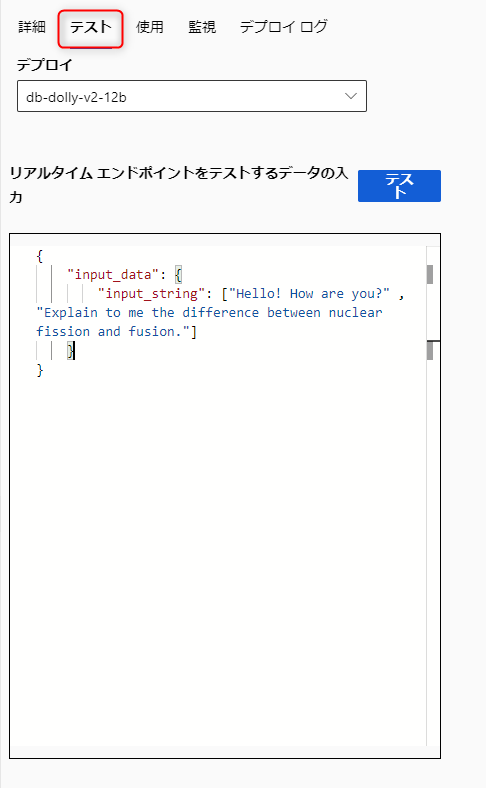
しばらくすると結果が返ってきました。返答自体に問題はなさそうに見えます。

日本語は使えるか?
まだ使えません。英語で聞きましょう。

同じ質問を英語でするとちゃんとした返答が返ってくることからも分かります。

それらしい料理の名前がいくつも出てきますが、店名などの情報が全て実在しないものです。この辺りはデータセットで与えられる知識ではないので仕方ないです。
ちなみにGPT-4に聞くと以下のようになります。

比較すると、ChatGPT以降に見られる、間違う可能性のある情報をなるべく書かないというフィルターが存在してないように見受けられます。入出力に過度な制限を設けないという点はGPTとの差別化として行っている部分もあるので、今後どういう方向に進むか注目する必要があります。
まとめ
今回はAzureの新機能であるモデルカタログと、そちらのモデルの中からDollyについて紹介しました。モデルカタログにはほかにも多数のモデルが登録されているため、今後は他のモデルも試してみようと思います。
Dolly 自体については、開発が始まったばかりなので仕方ないですが、現時点ではやはり最新のGPTモデルには及ばない印象を受けました。しかし完全にオープンかつ無料で利用できるという点で業界でも独特な立ち位置につけるのではないかと思うので、今後さらに開発が進むことを期待したいです。
付録・Databricks からの利用方法
GPU搭載のマシンでtransformersライブラリを使ったモデルを使用するには、まずtransformesとaccelerateライブラリがインストールされていることを確認します。
Databricks上では以下を実行することで可能です。
|
1 2 3 |
%pip install "accelerate>=0.16.0,<1" "transformers[torch]>=4.28.1,<5" "torch>=1.13.1,<2" |
関数を使用してパイプラインをロードすることができます。以下のコードはこちらにあるInstructionTextGenerationPipelineをロードするためにtrust_remote_code=Trueにする必要があります。
メモリを節約するために、型がサポートされている場合はtorch_dtype=torch.bfloat16を入れることが推奨されます(性能に影響はないようです)。十分なメモリがある場合は省略してかまいません。
|
1 2 3 4 5 |
import torch from transformers import pipeline generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto") |
これで返答を得るためのパイプラインが使えます。
|
1 2 3 |
res = generate_text("Explain to me the difference between nuclear fission and fusion.") print(res[0]["generated_text"]) |
外部コードを利用しない場合は、instruct_pipeline.pyをダウンロードしてノートブックと一緒に保存して、ロードしたモデルとトークナイザーから自分で構築する方法もあります。
|
1 2 3 4 5 6 7 8 9 |
import torch from instruct_pipeline import InstructionTextGenerationPipeline from transformers import AutoModelForCausalLM, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-12b", padding_side="left") model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-12b", device_map="auto", torch_dtype=torch.bfloat16) generate_text = InstructionTextGenerationPipeline(model=model, tokenizer=tokenizer) |
LangChainを使う場合は、return_full_text=Trueを設定する必要があります。LangChainが全てのテキスト出力を必要とするのに対し、デフォルトでは最新のテキストのみを出力するからです。
|
1 2 3 4 5 6 |
import torch from transformers import pipeline generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", return_full_text=True) |
プロンプトにインストラクションだけではなくコンテキストを加えることができるようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from langchain import PromptTemplate, LLMChain from langchain.llms import HuggingFacePipeline # template for an instrution with no input prompt = PromptTemplate( input_variables=["instruction"], template="{instruction}") # template for an instruction with input prompt_with_context = PromptTemplate( input_variables=["instruction", "context"], template="{instruction}\n\nInput:\n{context}") hf_pipeline = HuggingFacePipeline(pipeline=generate_text) llm_chain = LLMChain(llm=hf_pipeline, prompt=prompt) llm_context_chain = LLMChain(llm=hf_pipeline, prompt=prompt_with_context) |
単純な質問の例:
|
1 2 |
print(llm_chain.predict(instruction="Explain to me the difference between nuclear fission and fusion.").lstrip()) |
コンテキストを加えた例:
|
1 2 3 4 |
context = """George Washington (February 22, 1732[b] ? December 14, 1799) was an American military officer, statesman, and Founding Father who served as the first president of the United States from 1789 to 1797.""" print(llm_context_chain.predict(instruction="When was George Washington president?", context=context).lstrip()) |
