MLStudioが2024年に廃止するようです。
https://docs.microsoft.com/en-us/azure/machine-learning/migrate-overview
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
これを機にほかのサービスへの移行を考えていたのですが、AzureMLにデザイナーという機能があり、MLStudioのようにブロックで操作できるようでした。
サンプルがいくつかあるので、いくつか試していこうと思います。
今回は自動車価格の予測チュートリアルをやっていきたいと思います。
ワークスペース作成
まず初めにAzureMLワークスペースを作成します。

リソースの作成からAzureMachineLeaningを検索します。

出てきたページの作成を押し、必要情報を入力して作成しましょう。
詳しい内容はこちらにあります。
ワークスペースが作成されると、このように表示されてると思います。
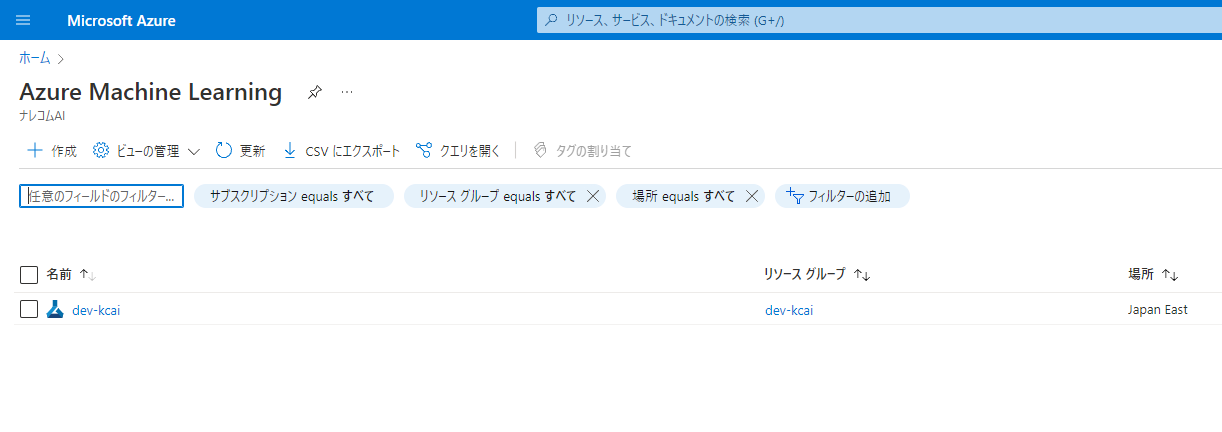
作成したワークスペースを開いてみるとスタジオの起動と真ん中に出てくるのでこちらをクリックして起動しましょう。
スタジオを起動するとこのようなページに移動すると思います。
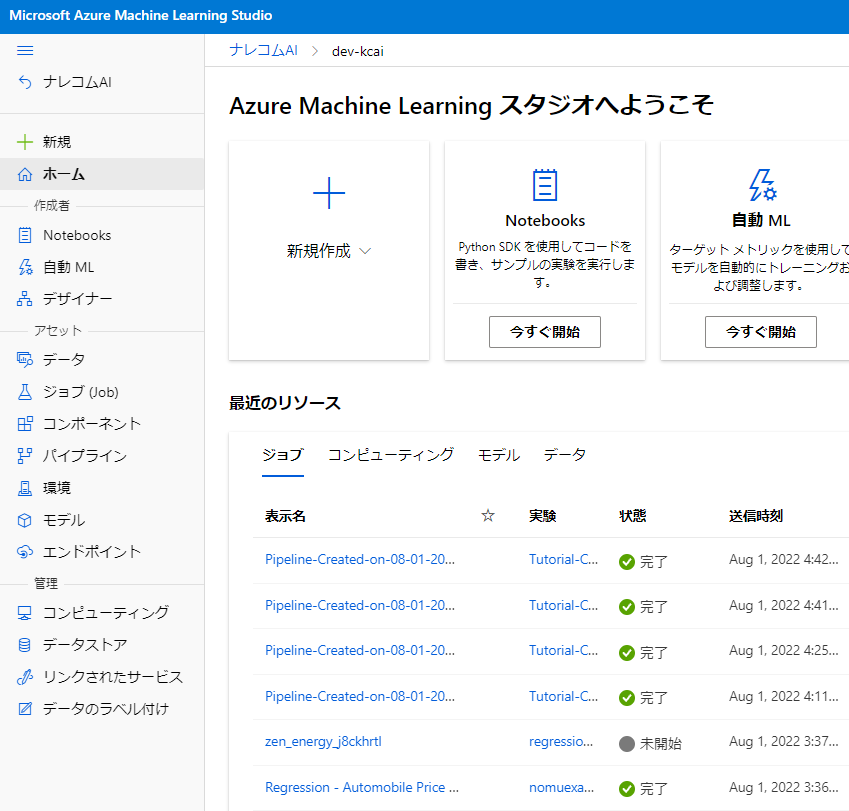
デザイナーでモデルを作る
今回はブロックでモデルを作成できるデザイナーという機能を利用していきたいと思います。
左のタブからデザイナーの項目をクリックして開いてみましょう。
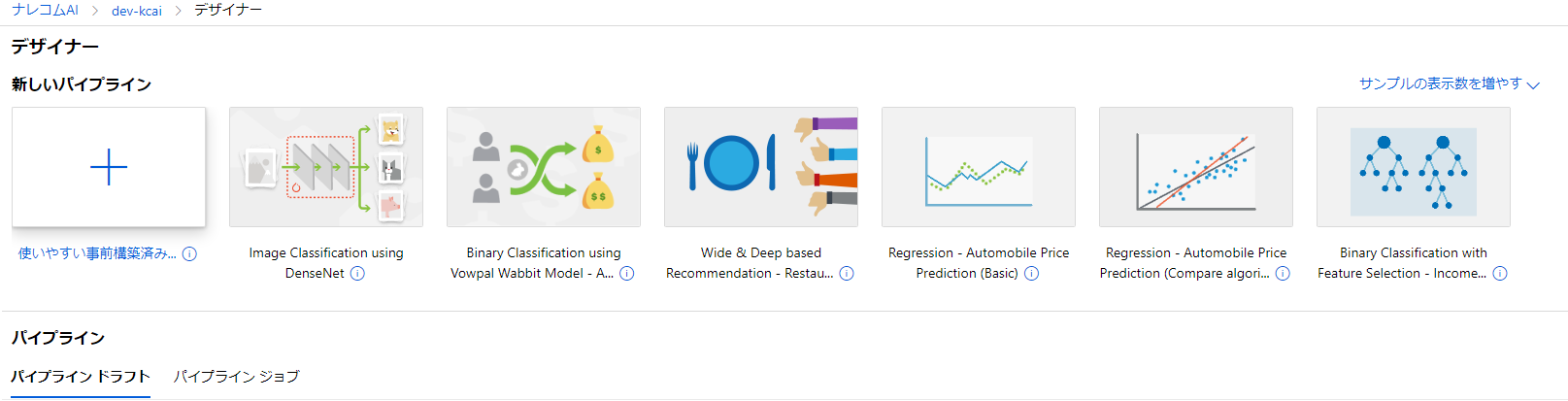
このような画面になると思います。
新しいパイプラインの項目にはいくつかサンプルが並んでいます。
これらはすでにサンプルのブロックが組みあがっているものになります。
今回利用するAutomobile Price Predictionについてもすでに出来上がったものが提供されています。
今回は一通りの流れを確認したいので一から作っていきたいと思います。
空のパイプラインを作りたいので左にある+ブロック(使いやすい事前構築済み…)をクリックします。
開くとこのような画面になります。
MLStudioで見慣れた画面で安心しますね…
それではブロックを投入しながらモデルを構築していきます。
サンプルデータの取得
まずはサンプルデータを持ってきます。
左の検索窓に「Automobile」と入れて検索します。
この時「データ」と「コンポーネント」タブがありますが、データのほうを選択しておきましょう。
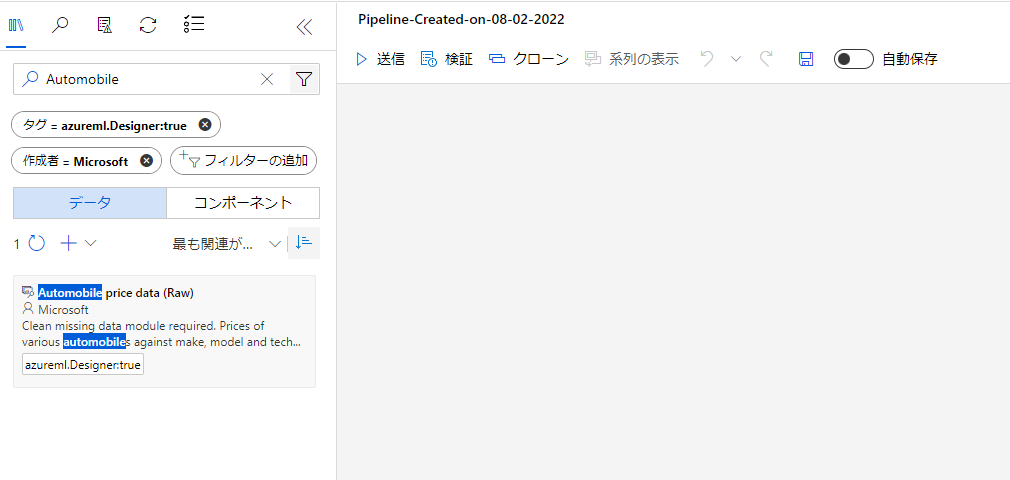
このようにブロックが出てきます。これを右にドラッグ&ドロップして配置します。
これでデータの準備ができました。データの内容を確認してみたいので配置したブロックを右クリックして「データを表示する」を押下して表示してみましょう。
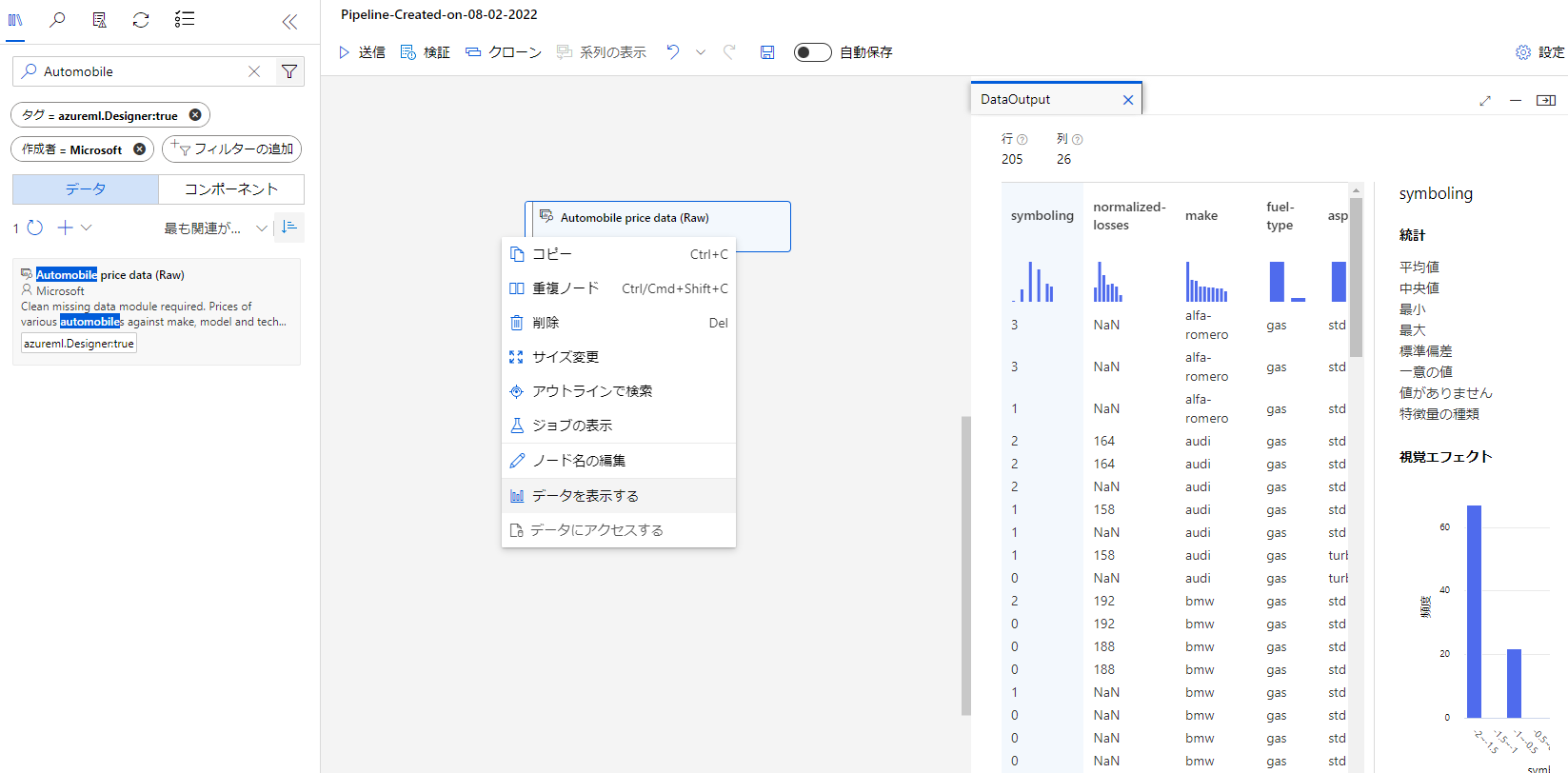
このようにデータの内容が可視化されていますね。
続いてデータの前処理をしていきましょう。
今回は列の削除と欠損の補完を行います。
不要データの削除
まずは列の削除をしていきましょう。先ほど「データ」を選択したタブを「コンポーネント」にして、「Select Columns in Dataset」を検索します。
出てきたブロックをドラッグドロップして配置しましょう。
配置できたらAutomobileブロックの下にある○とSelectColumnsの上にある○をドラッグしてつなげます。
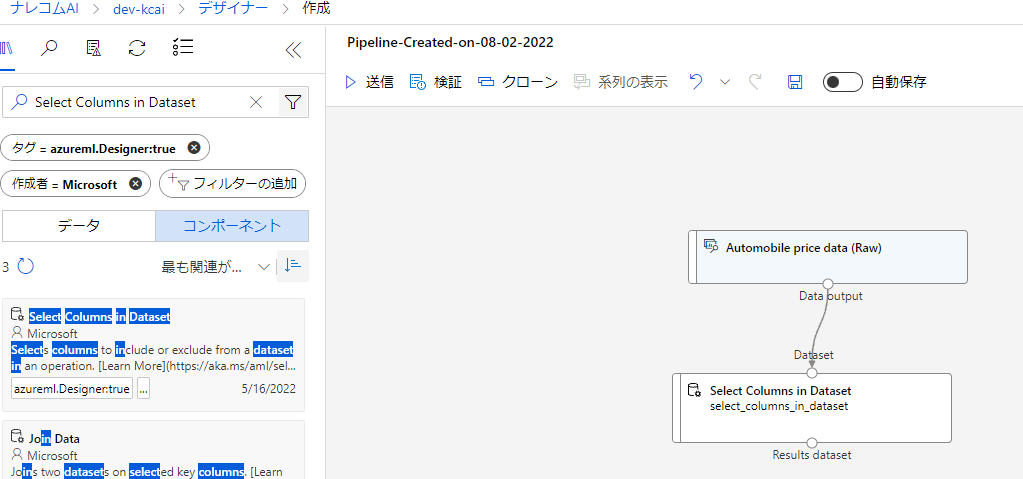
SelectColumnsのブロックをだプルクリックすると右に項目が表示されます。
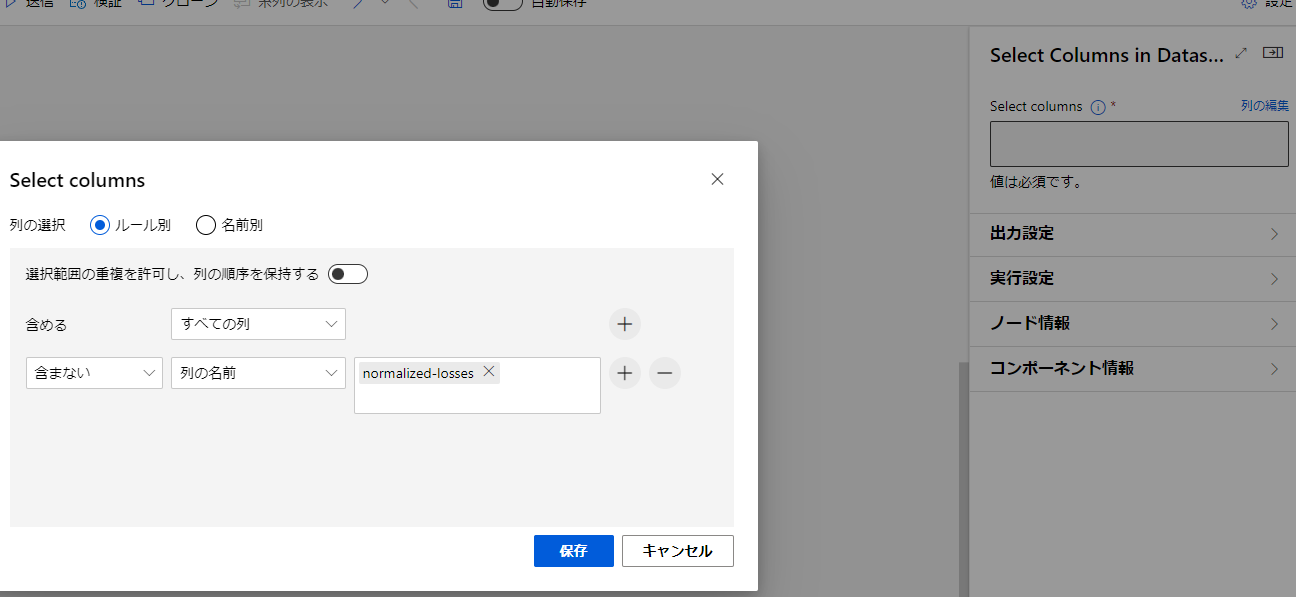
項目内にある列の編集をクリックし、ポップアップを表示します。
含めるではすべての列を選択します。
右の+ボタンをクリックしてルールを追加します。
左の項目を含まないにして、次に列の名前を選択します。
すると列の名前を入力する項目が表示されます。今回は「normalized-losses」という項目を除去したいのでこちらを入力します。
その後保存をクリックしましょう。
欠損データの処理
続いて欠損データの処理を行います。
検索から「Clean Missing Data」を検索し、ブロックを配置しましょう。
配置したらSelectColumnsとCleanMissingDataを繋げます。
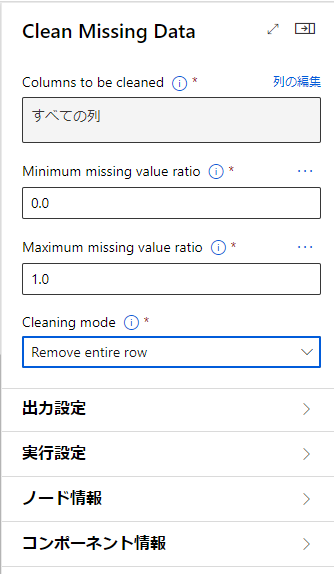
また、項目内のCleaningModeを「Remove entire row」にしましょう。
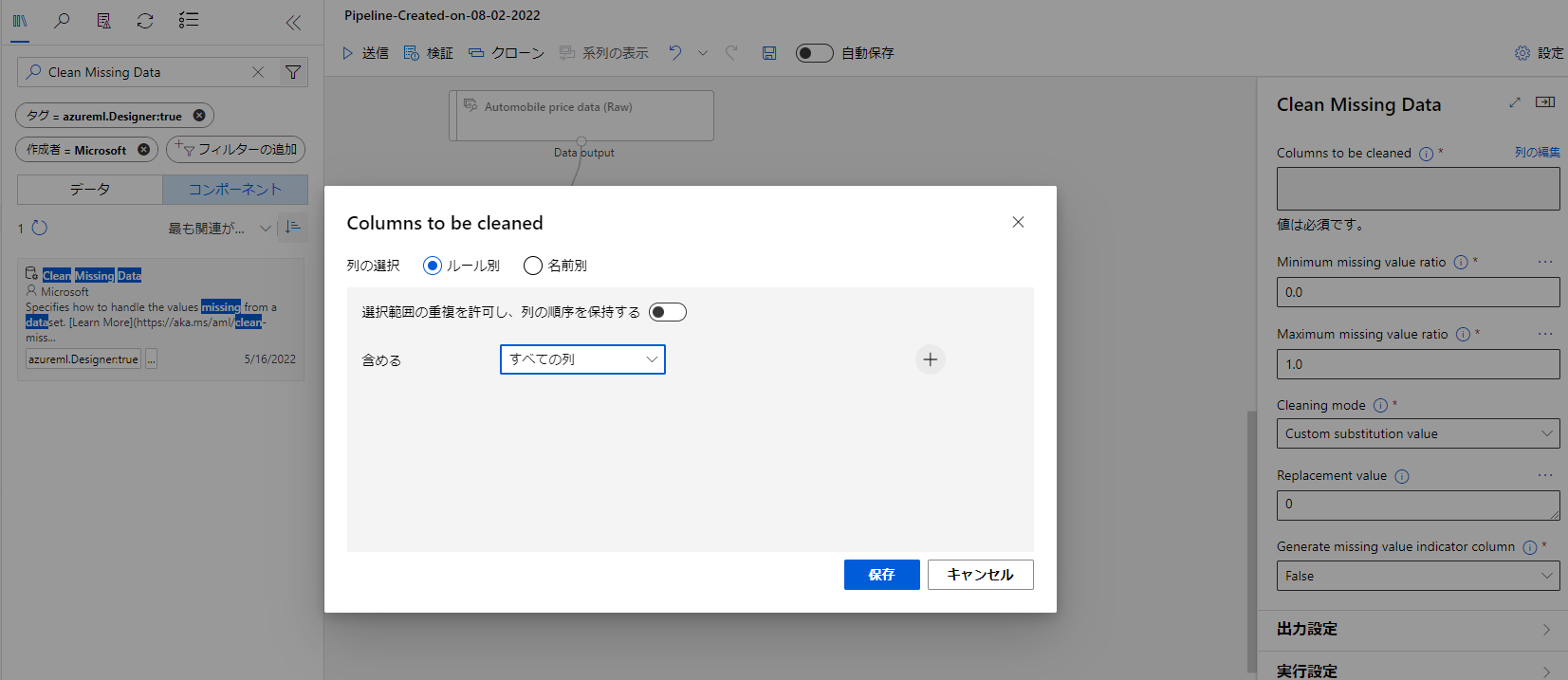
先ほど同様ブロックをダブルクリックして右の項目から列の編集を選び、ポップアップの含むの項目をすべての列にしましょう。
データの分割
前処理できたので、こんどはデータの分割をします。
片方を学習に、もう片方をテストに使います。
検索から「Split Data」を調べ、ブロックを配置します。
CleanMissingDataブロックの左のCleaned datasと書いてある○からSplitDataに線を繋げます。
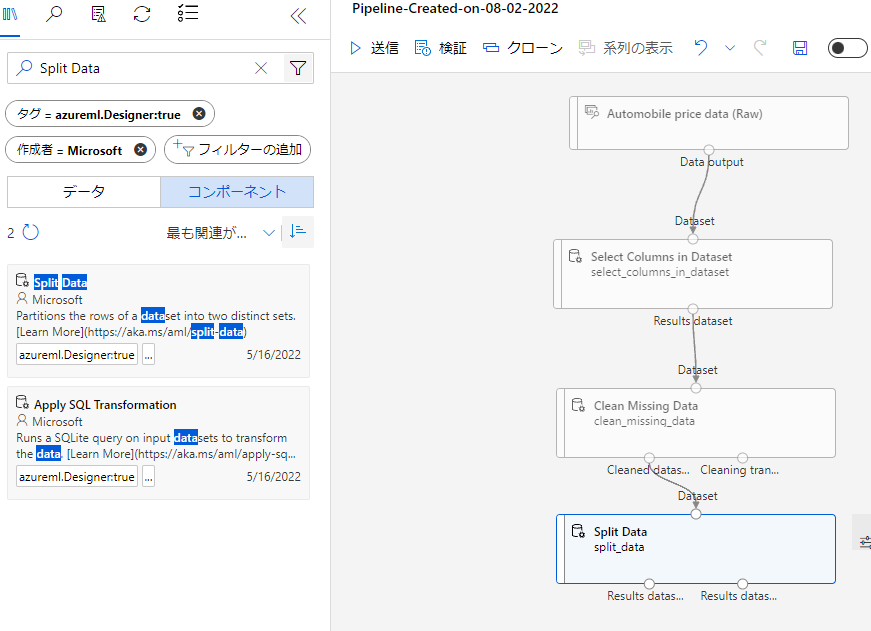
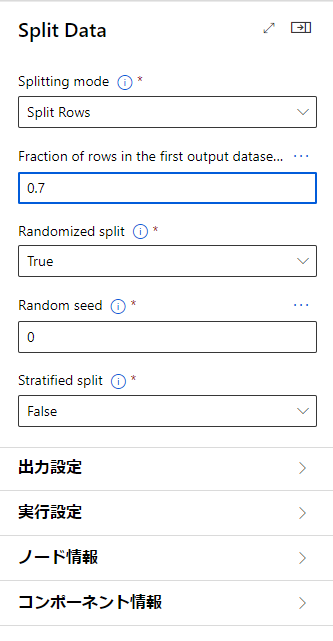
SplitDataをダブルクリックして項目を表示したら「Fraction of rows in the output dataset …」の項目を0.7にしましょう。
これは分割する際のデータの割合で、初めに出力するデータを全体の70%にすることを指定しています。
学習アルゴリズムの追加
続いて学習するためのアルゴリズムを配置します。今回は「LinerRegression」を利用したいと思います。
検索して出てきたブロックを配置します。
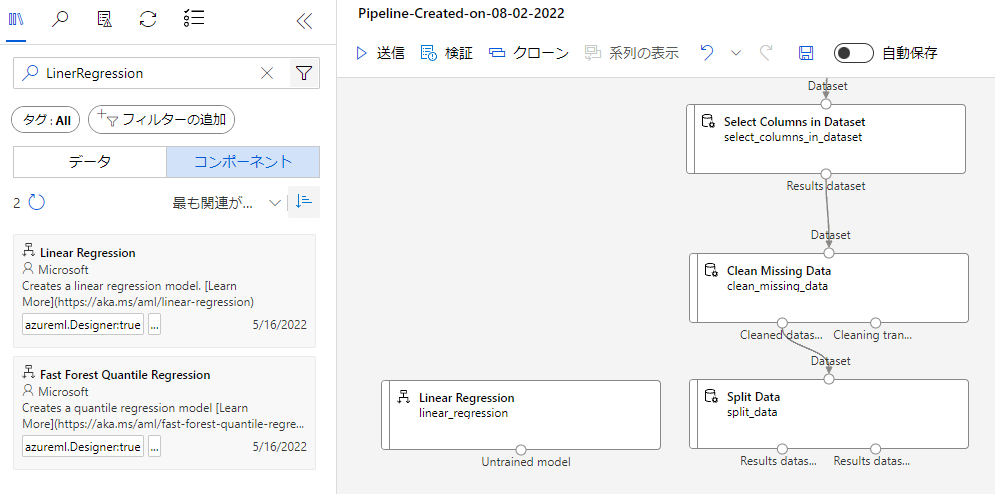
学習させるためにはTrainModelブロックが必要です。こちらも検索して配置しましょう。
配置したら、左上の○とLinerREgressionを、右上の○はSplitDataの左下の○とを繋げましょう。
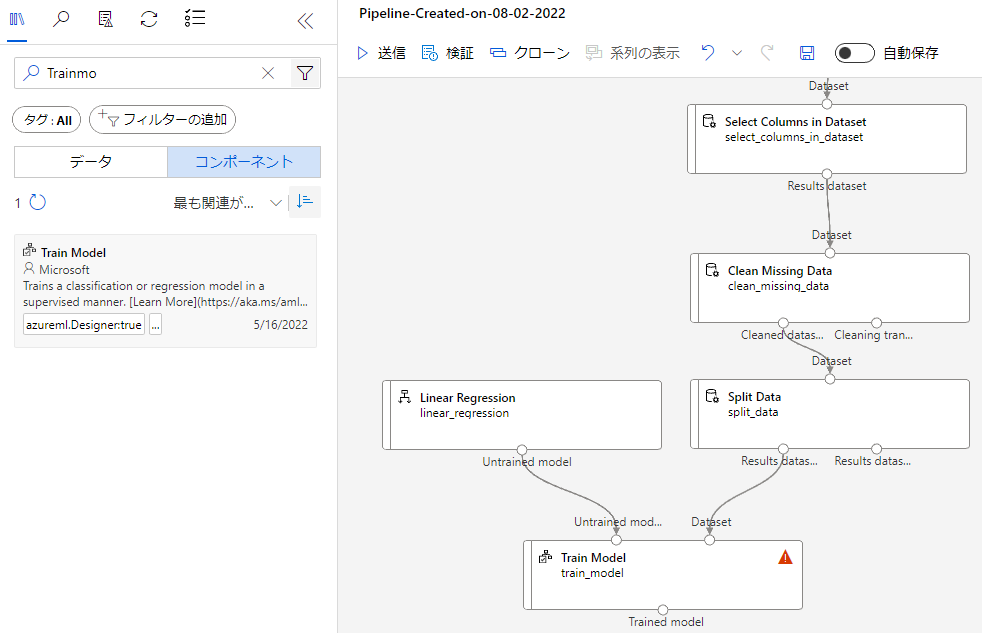
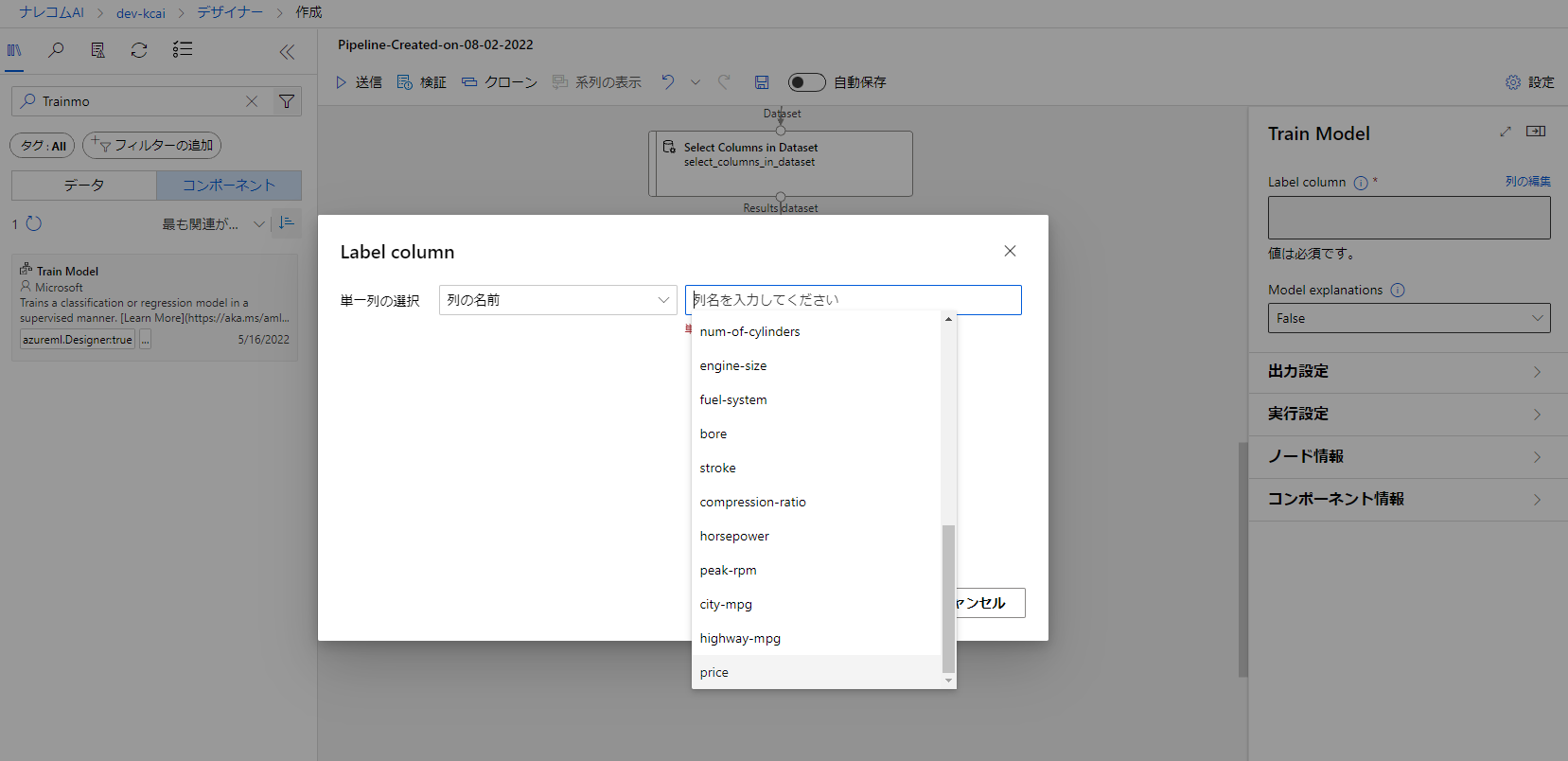
このままだと予測する値が決まっていないので、TrainModelをダブルクリックして項目を開き、LabelColumn横にある列の編集から指定します。
今回は「price」を予測したいのでこちらを選択します。その後保存します。
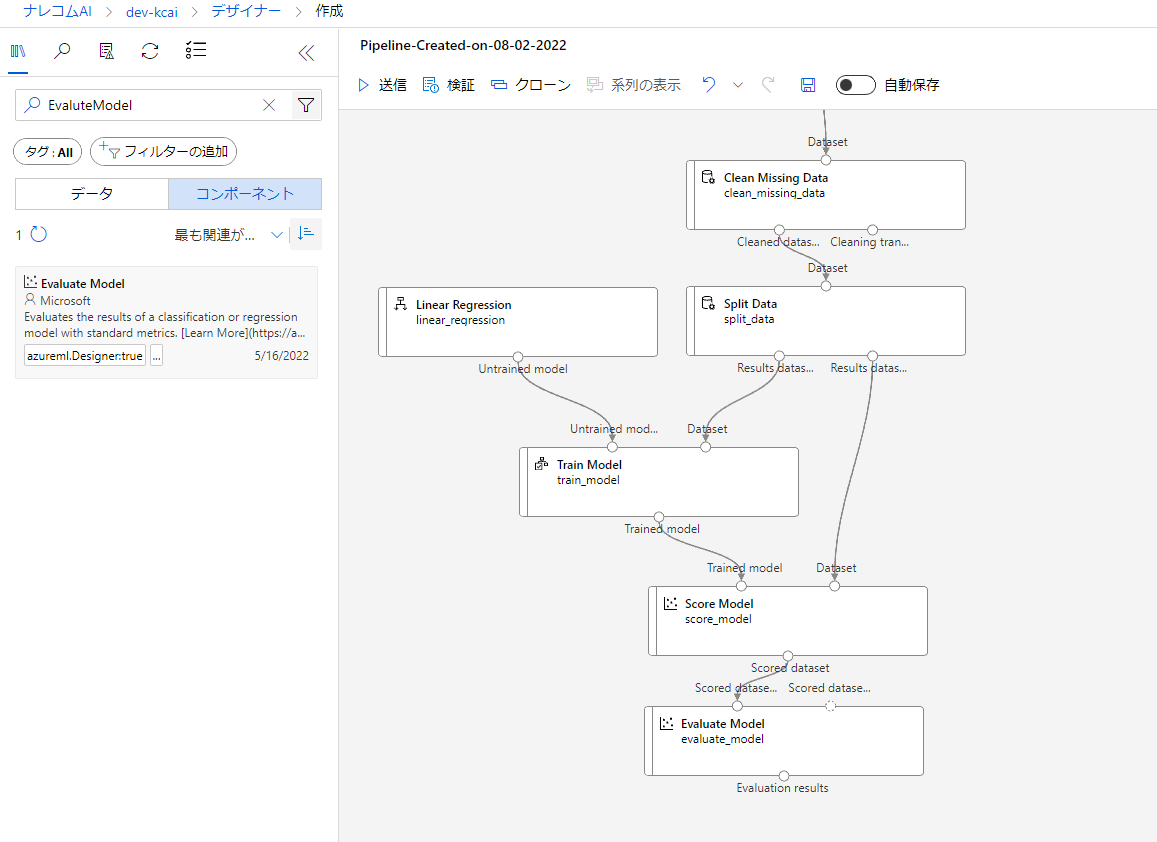
モデルのテストと評価
作成したモデルのテストを行うために「ScoreModel」ブロックを追加します。
左上の○とTrainModelの○を、右上の○とSplitDataの右下の○を繋げます。
また、テスト結果をもちいてモデルの評価を行いたいので「EvaluteModel」ブロックを追加します。
左上の○とScoreModelの○を繋げましょう。
ジョブの実行
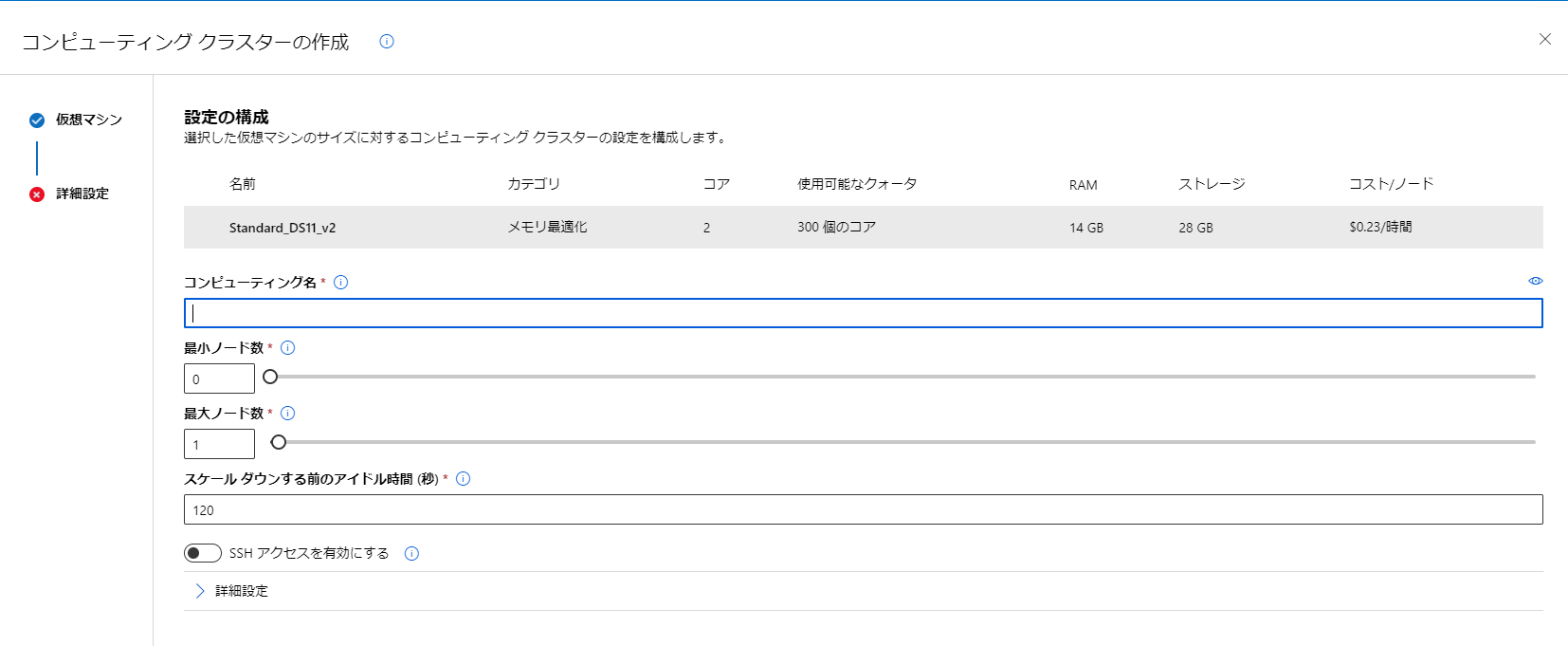
ジョブの実行をするため、クラスターの作成をしましょう。
画面右上にある設定を開き、「AzureMLコンピューティングクラスター…」から作成を行います。
クラスタの種類によってコストが変わってくるので、データ量などを確認しながら選ぶといいかなと思います。
今回は一番上のものを作成します。
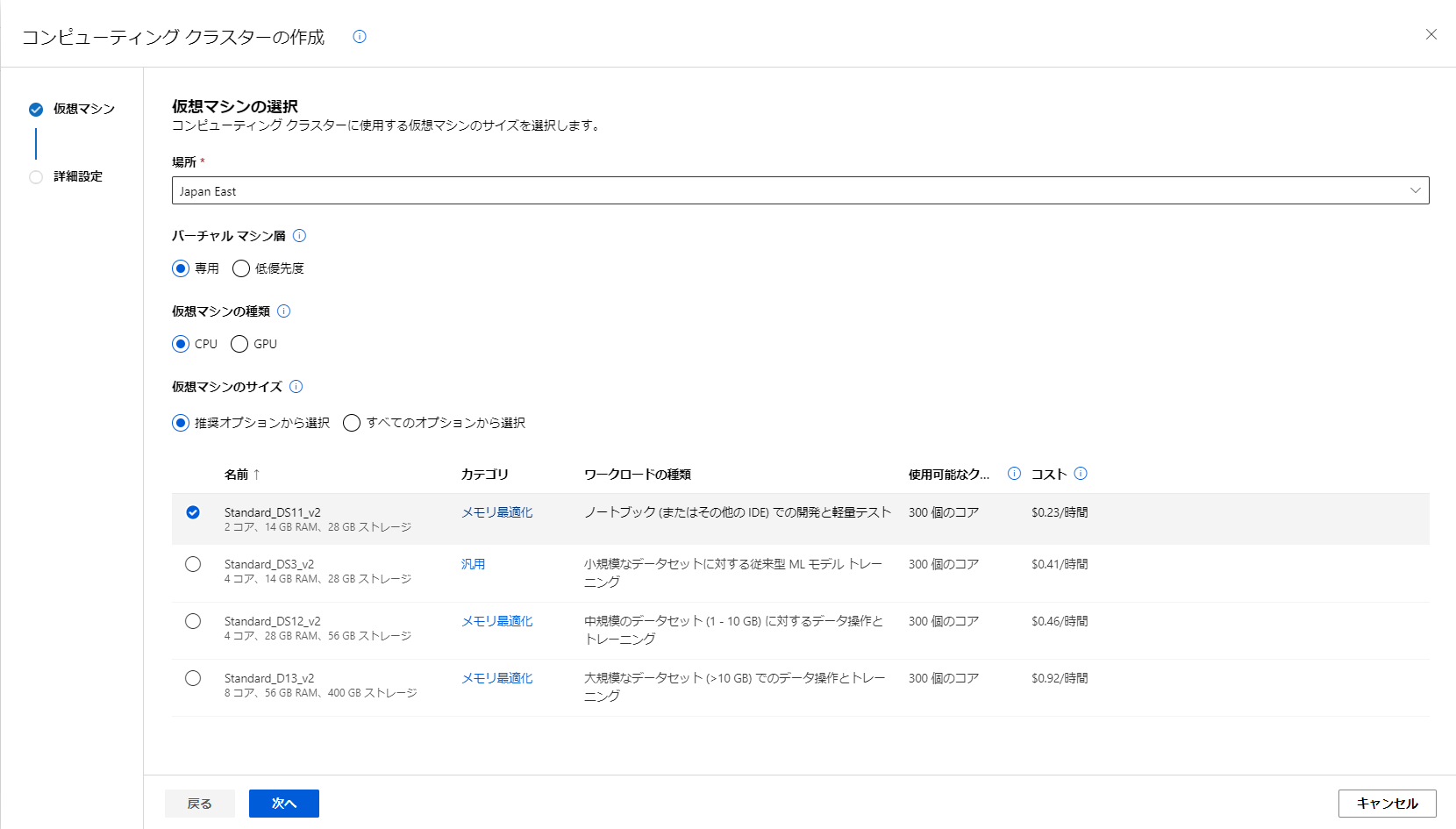
選択後コンピューティング名を設定し、作成します。
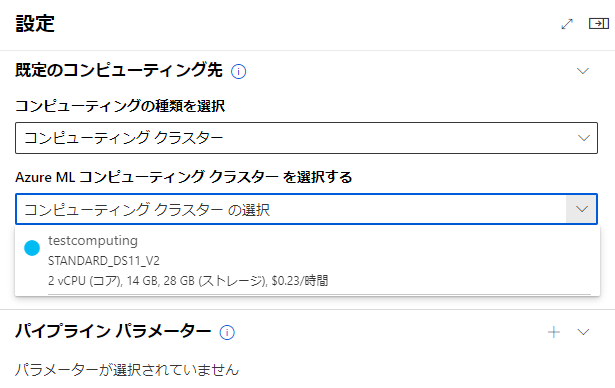
先ほどの設定画面に戻り、「AzureMLコンピューティングクラスタを選択する」から作成したクラスターを選びます。
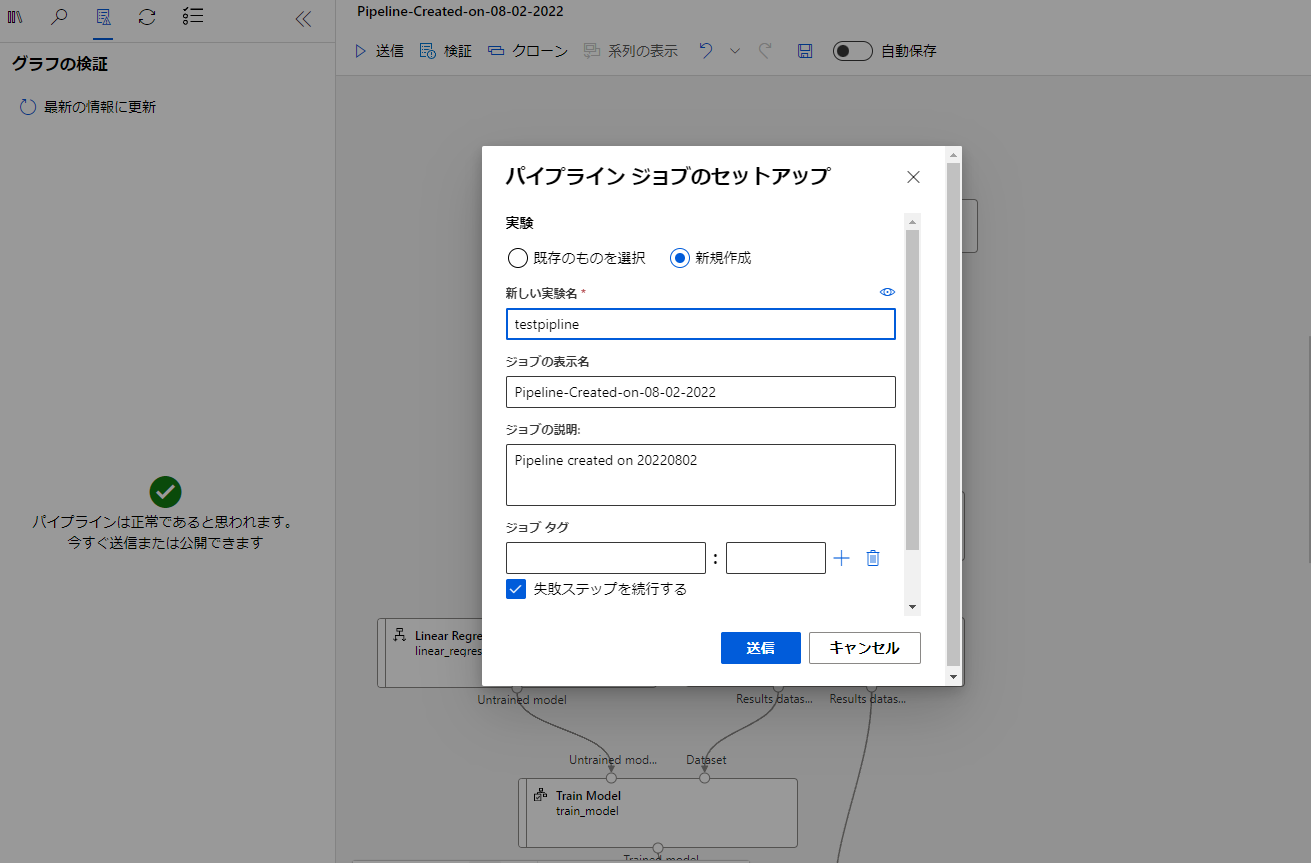
クラスタが設定できたら上部にある「送信」をクリックしてジョブを開始させます。
パイプラインの設定で新規作成から実験名を記入し送信します。
左にサービスからの応答を待機してますという項目が出ます。
少し経つと表示が変わり、このようになるのでジョブの詳細をクリックしましょう。
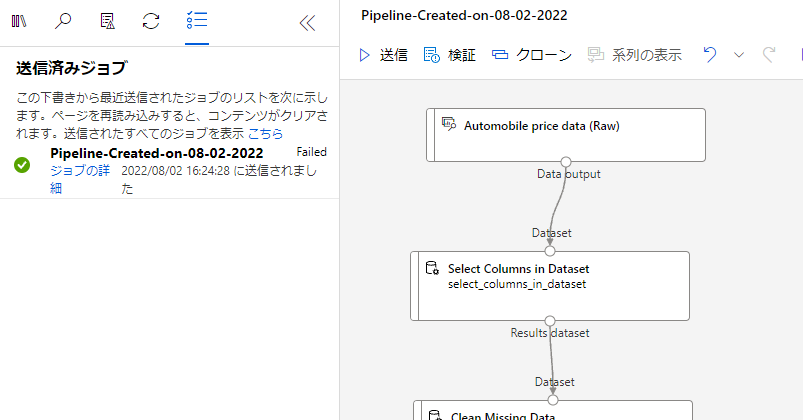
実行内容が確認できますね。
実行中のブロックは左に縞模様ができているみたいです。
この画面で実行の確認や結果の確認をすることができます。
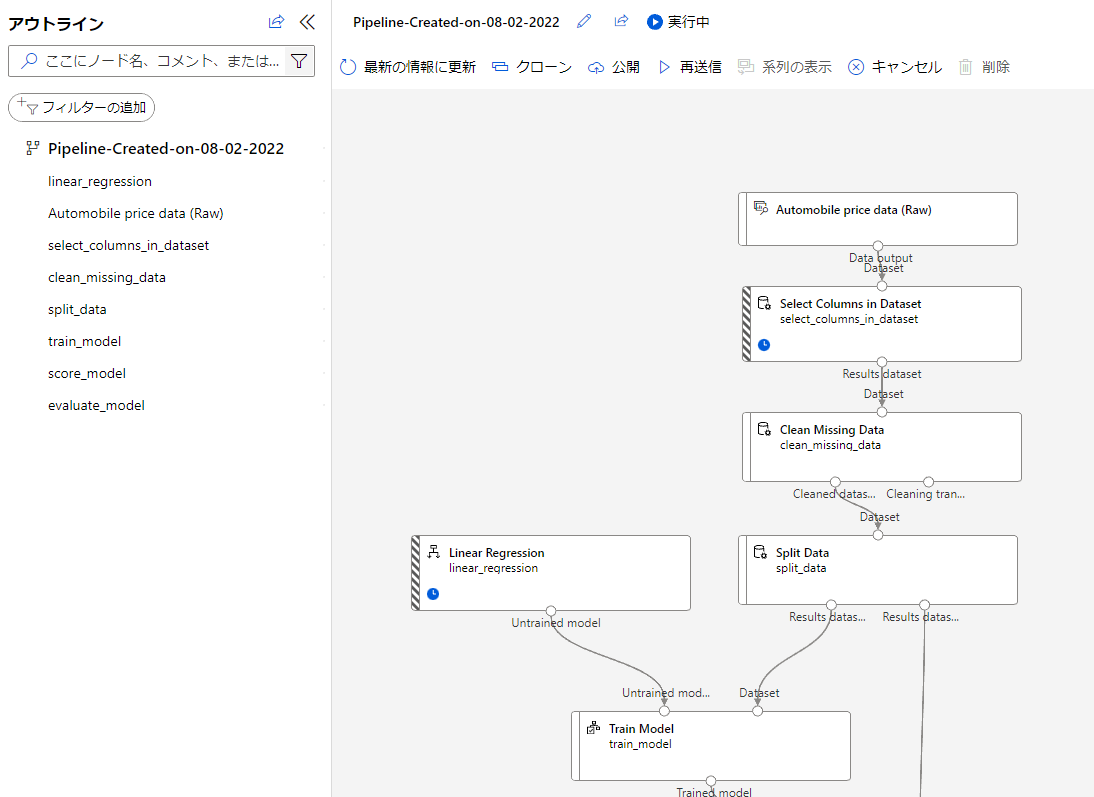
実行が完了したら結果を見てみたいと思います。
まずはテストの結果を見ましょう。ScoreModelを右クリックして「データを表示する」を押下し、ScoredDatasetをクリックしましょう。
すると右に項目が表示されます。
項目内のScoredLabelsの項目が予測結果になります。
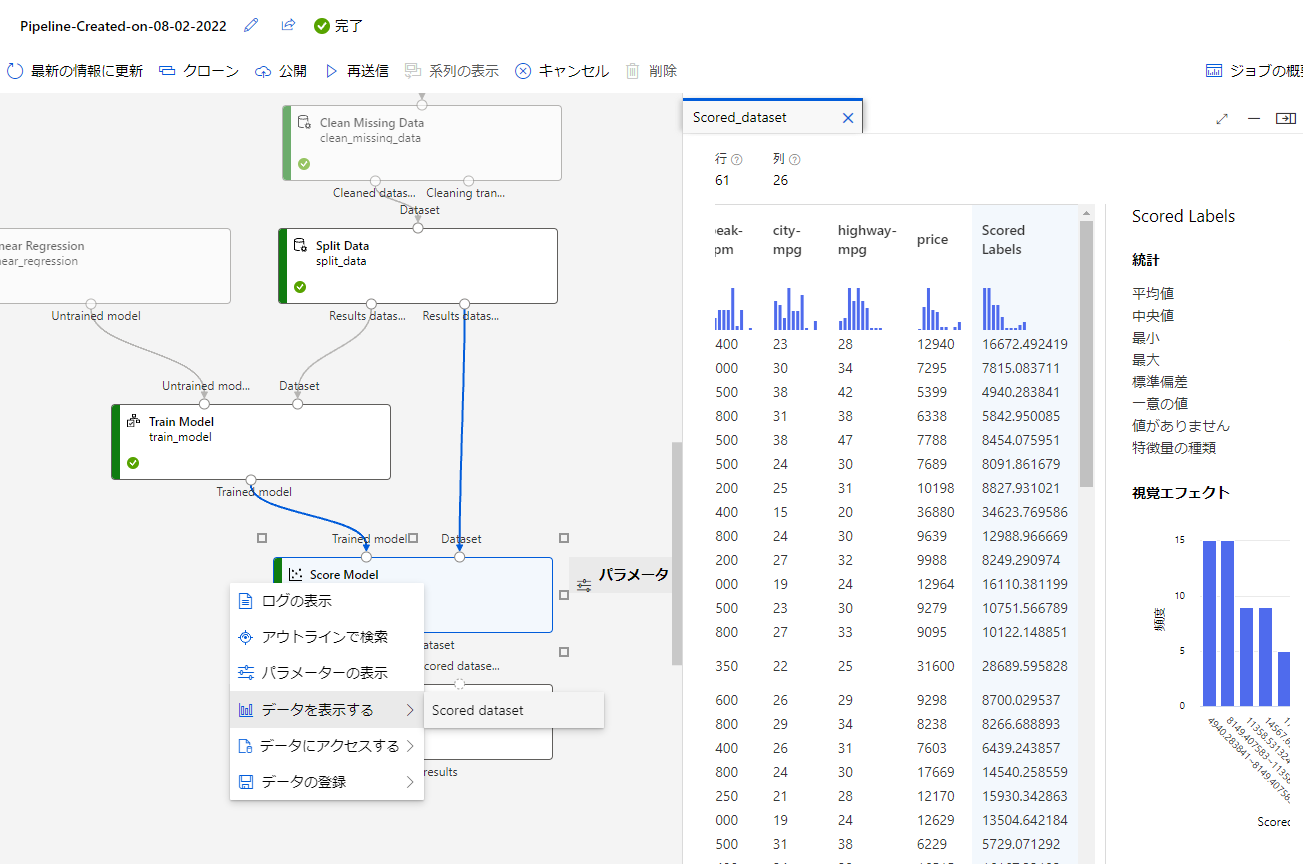
モデルの評価についても同様に確認してみましょう。
EvaluteModelをダブルクリックして項目を表示します。項目上部のタブでメトリックを選択しましょう。
すると評価指標を確認することができます。
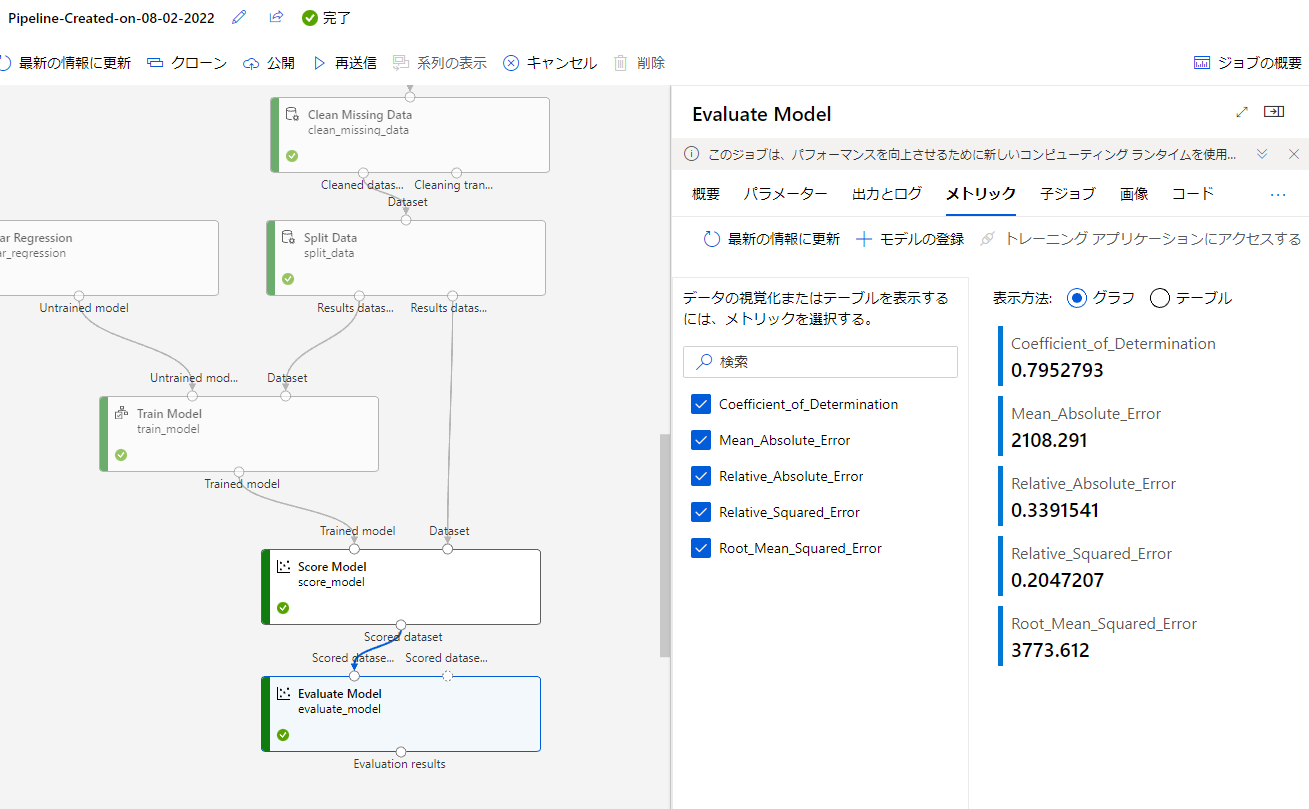
モデルの運用
実際にこのモデルを運用する際にはAPIを通して実行したり、バッチ処理を行うなどが考えられます。
今回はAPIを利用するリアルタイム推論パイプラインを利用したいと思います。
実行画面右上にある推論パイプラインをクリックして、「リアルタイム推論パイプライン」を選択しましょう。
推論パイプラインの項目がない場合は左にある「最新の情報に更新」をクリックすると表示されました。
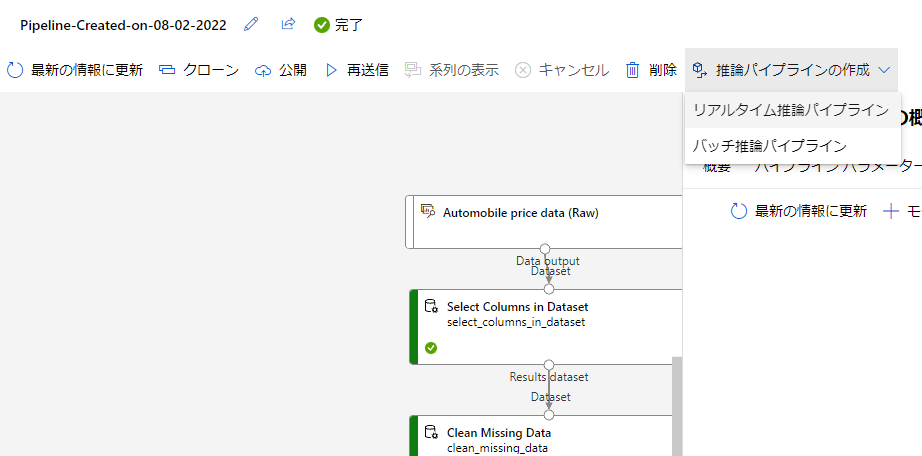
こちらをクリックすると自動でパイプラインの形が変化します。
変化後、送信をクリックして再度パイプラインを実行します。この時既存の実験を選択することで、後で確認する際に実験ごとに確認できわかりやすくなると思います。
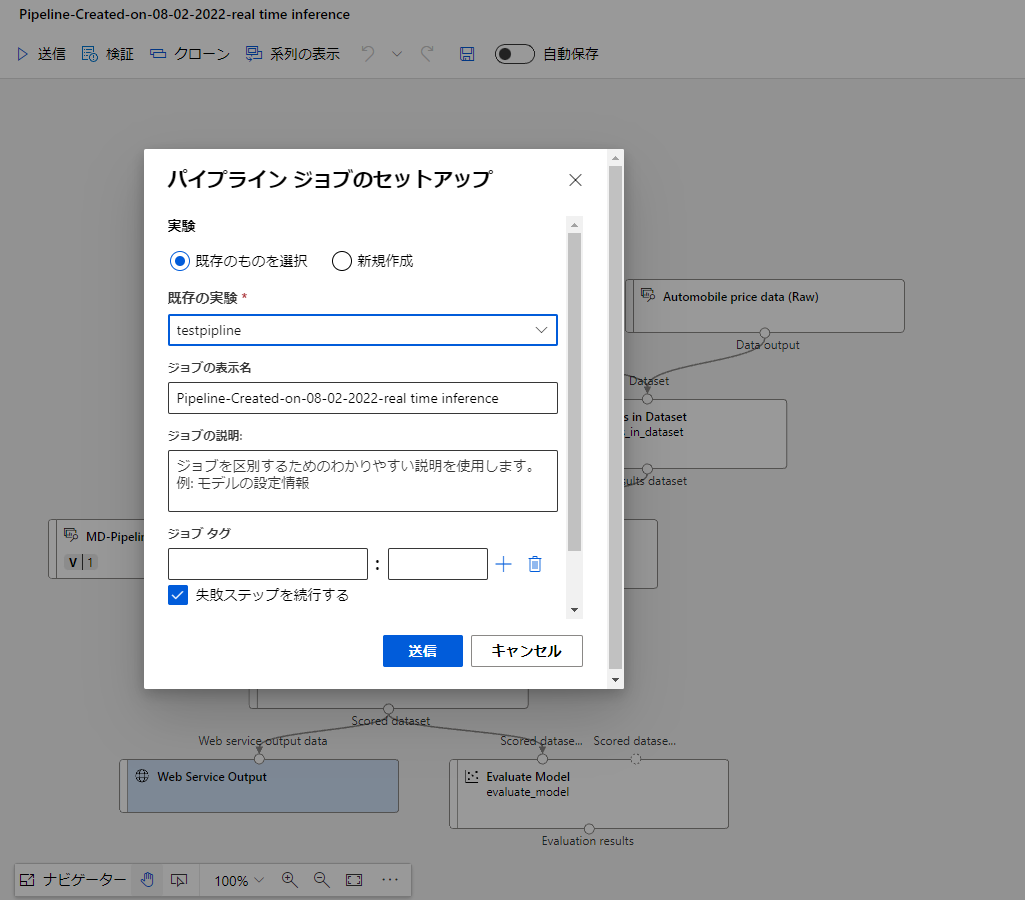
先ほど同様少し時間がたつと左側のサービスの応答を待っていますという項目が変わるので、ジョブの詳細をクリックして開きましょう。
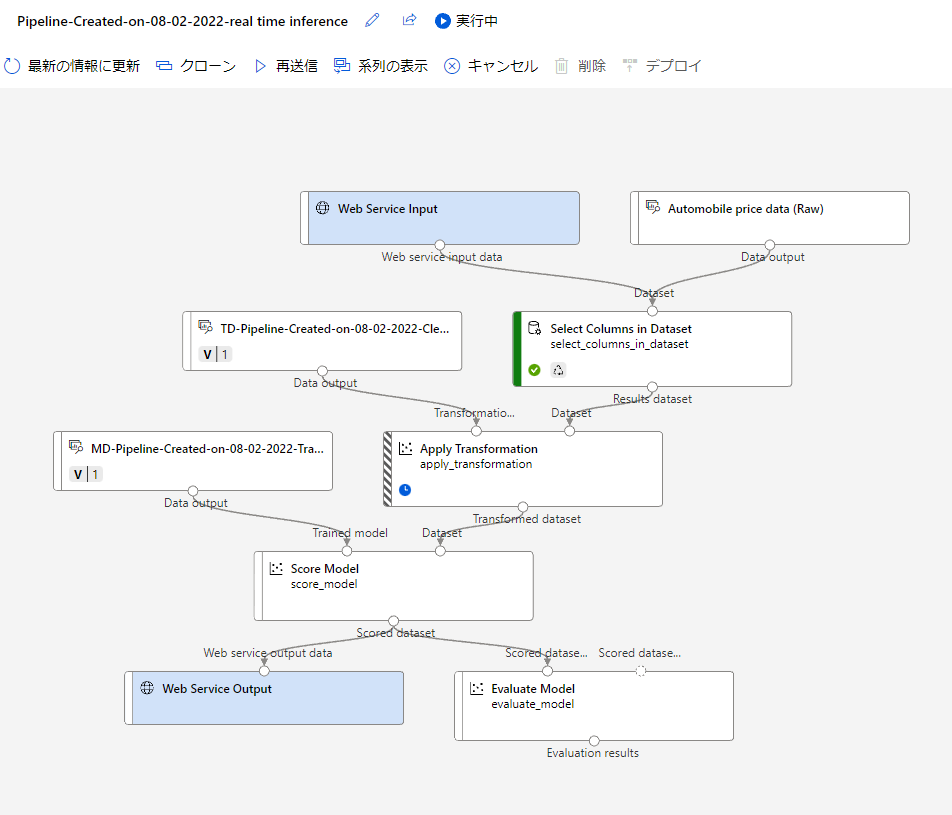
先ほど同様に実行の状況が確認できます。
実行が終了したら最新の情報に更新してみましょう。右上にデプロイの表示が出ると思います。
こちらの設定には推論用のコンピューティングを作成する必要があります
左のタブからコンピューティングを選択し、推論クラスターの項目を開きます。
新規をクリックして作成を始めます。
場所は利用地点に近いものを選ぶといいかなと思います。
その後VMのサイズを選択します。一番上のものを選ぶとエラーが出てしまったので、2つ目のものを選ぶことにしました。
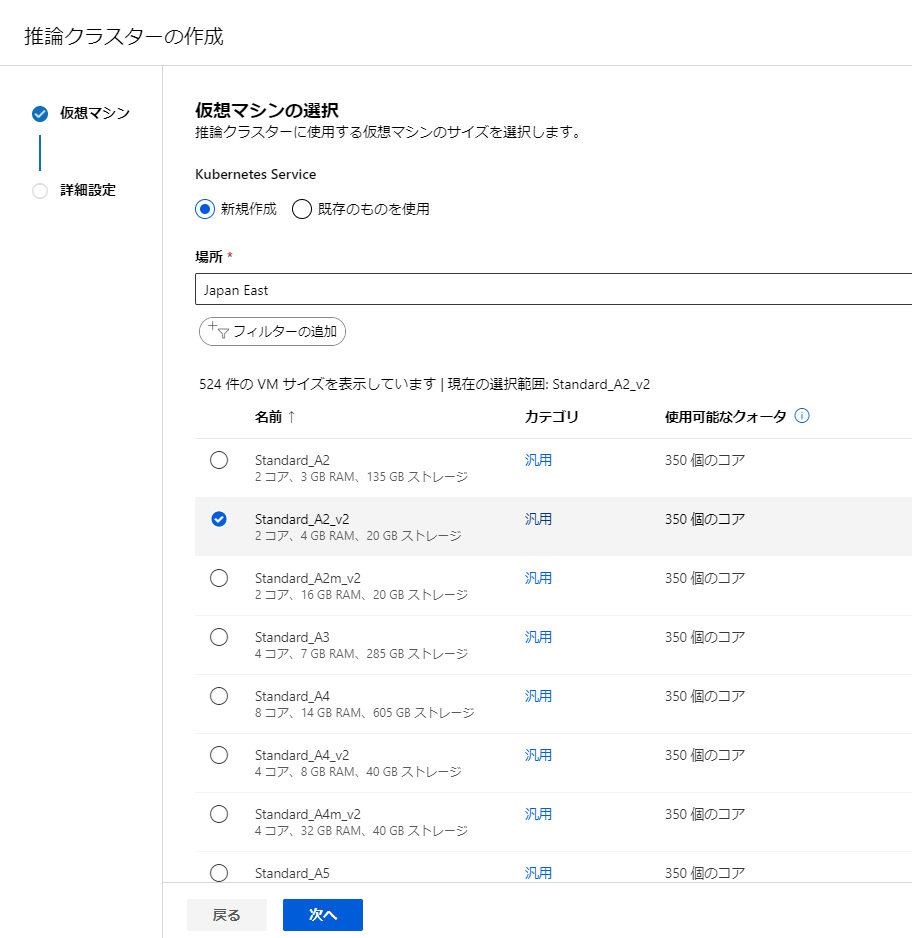
設定後は作成をクリックしましょう。
作成には少し時間がかかります。
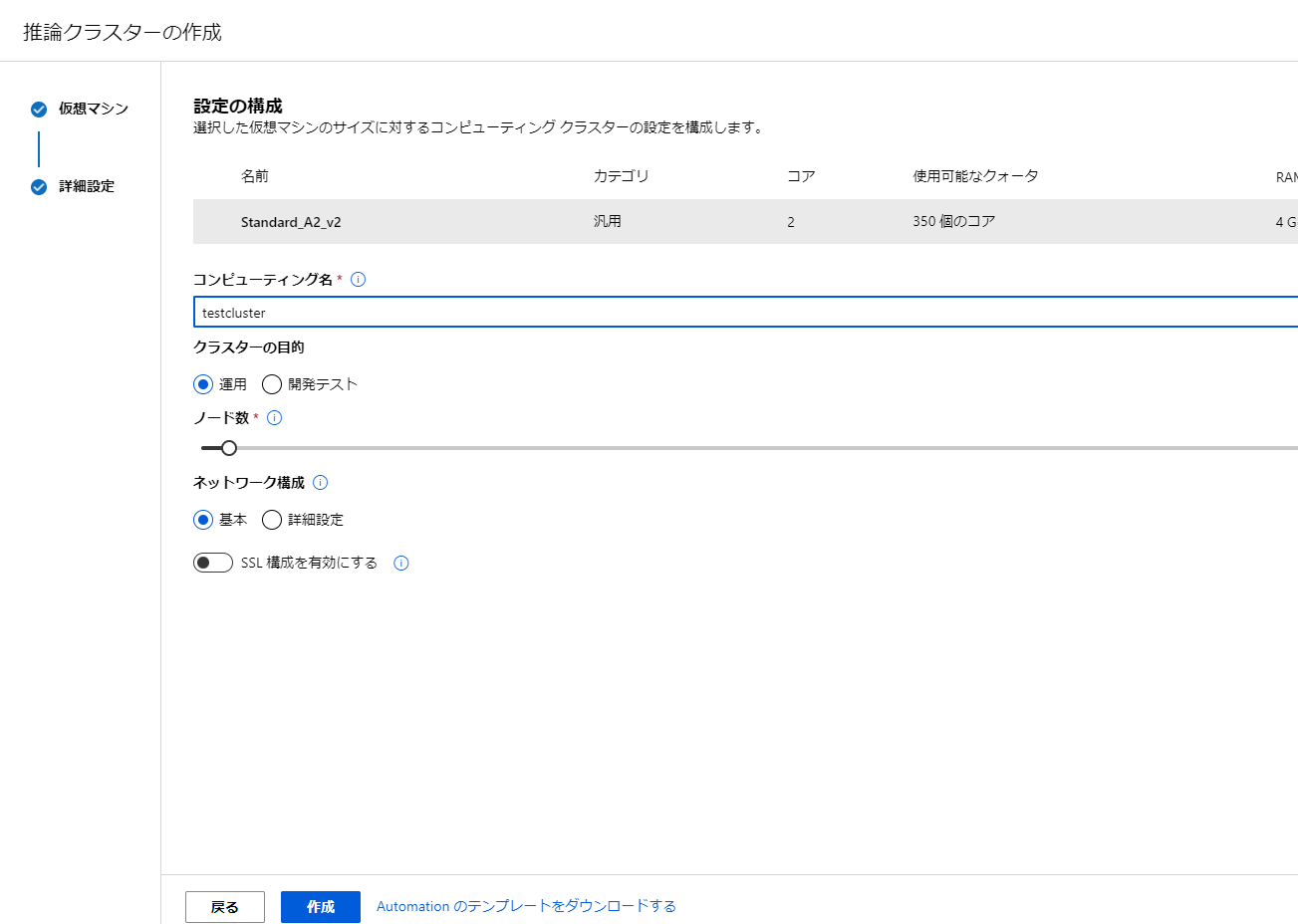
作成が終了したら、元の画面に戻りましょう。
jobから先ほど設定した実験をクリックして開きます。実行したパイプラインが表示されてると思います。後ろにRealtime…とくっついているものを選びましょう。
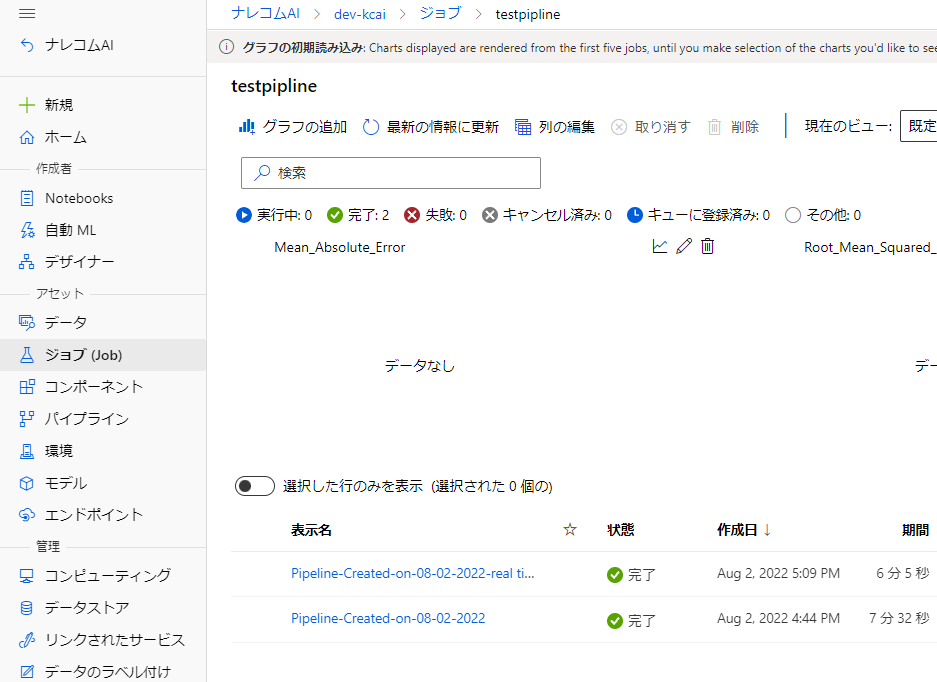
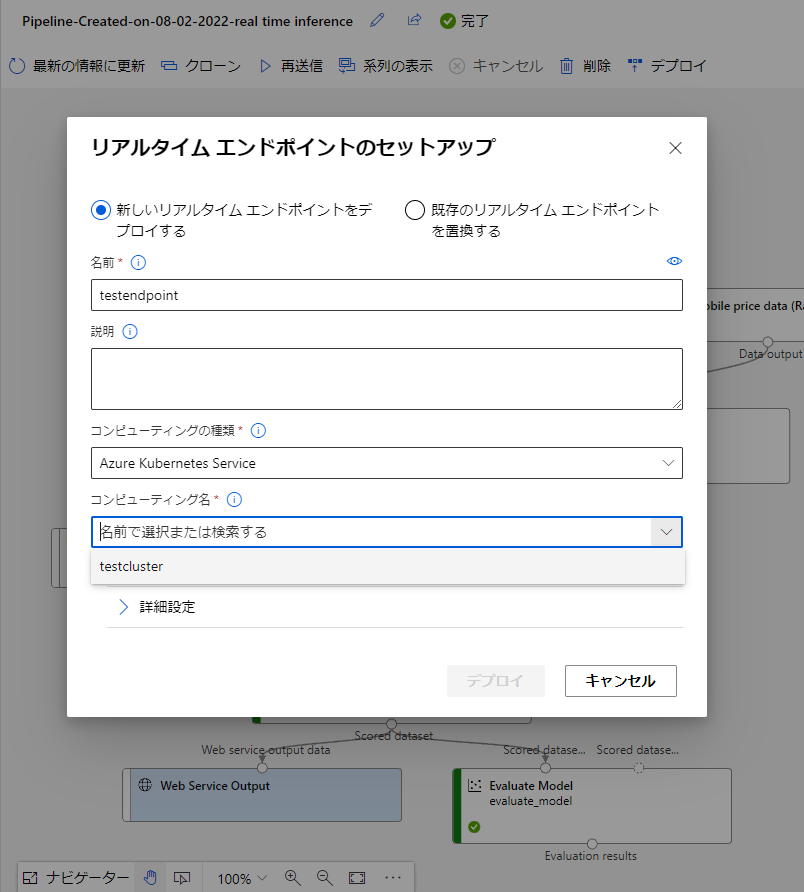
戻ったら右上にあるデプロイをクリックしてセットアップを行いましょう。
名前を設定し、コンピューティング名の箇所に先ほど作成したクラスターを選択します。
その後デプロイしましょう。
作成されたエンドポイントを確認してみましょう。
左の項目からエンドポイントを選択すると確認ができます。
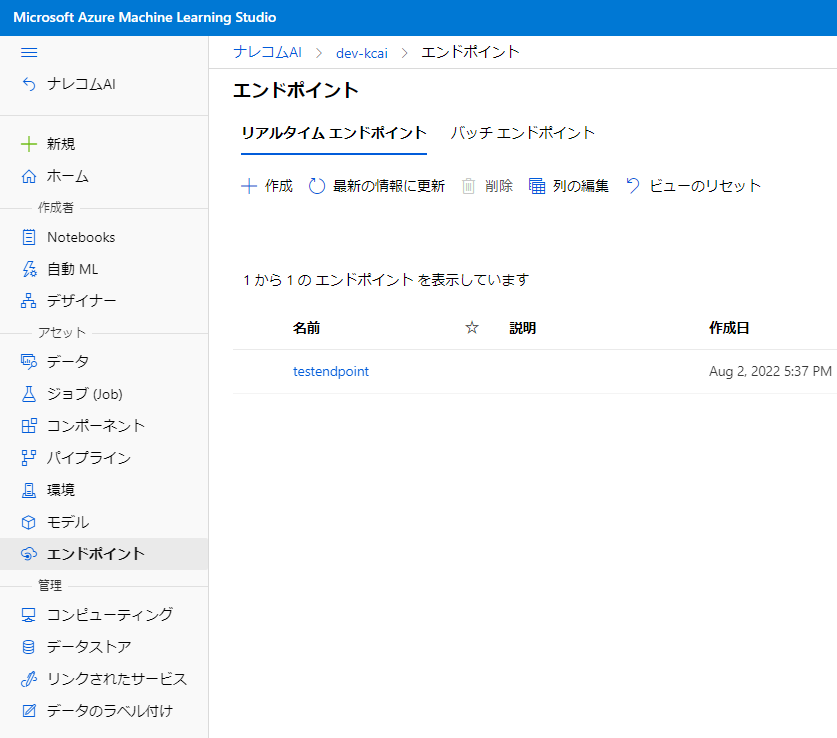
作成したエンドポイントを開いてみると、Restエンドポイントが表示されてると思います。
こちらに対してPOSTすることで推論結果を取得することができます。
エンドポイントのテスト
参考にしているチュートリアルではweb上でテストができるようなのですが、自分の環境だとできなかったため、pythonから実行してエンドポイントを確認してみたいと思います。
実行するにはデプロイ状態がhealthyである必要があるため、準備が整うまで待機しましょう。
準備ができたら詳細、デプロイログのタブに「テスト」と「使用」のタブが追加されます。
使用では利用する際に用いるエンドポイントとキー、コードが載っています。
今回はこのコードのpythonを用いたいと思います。
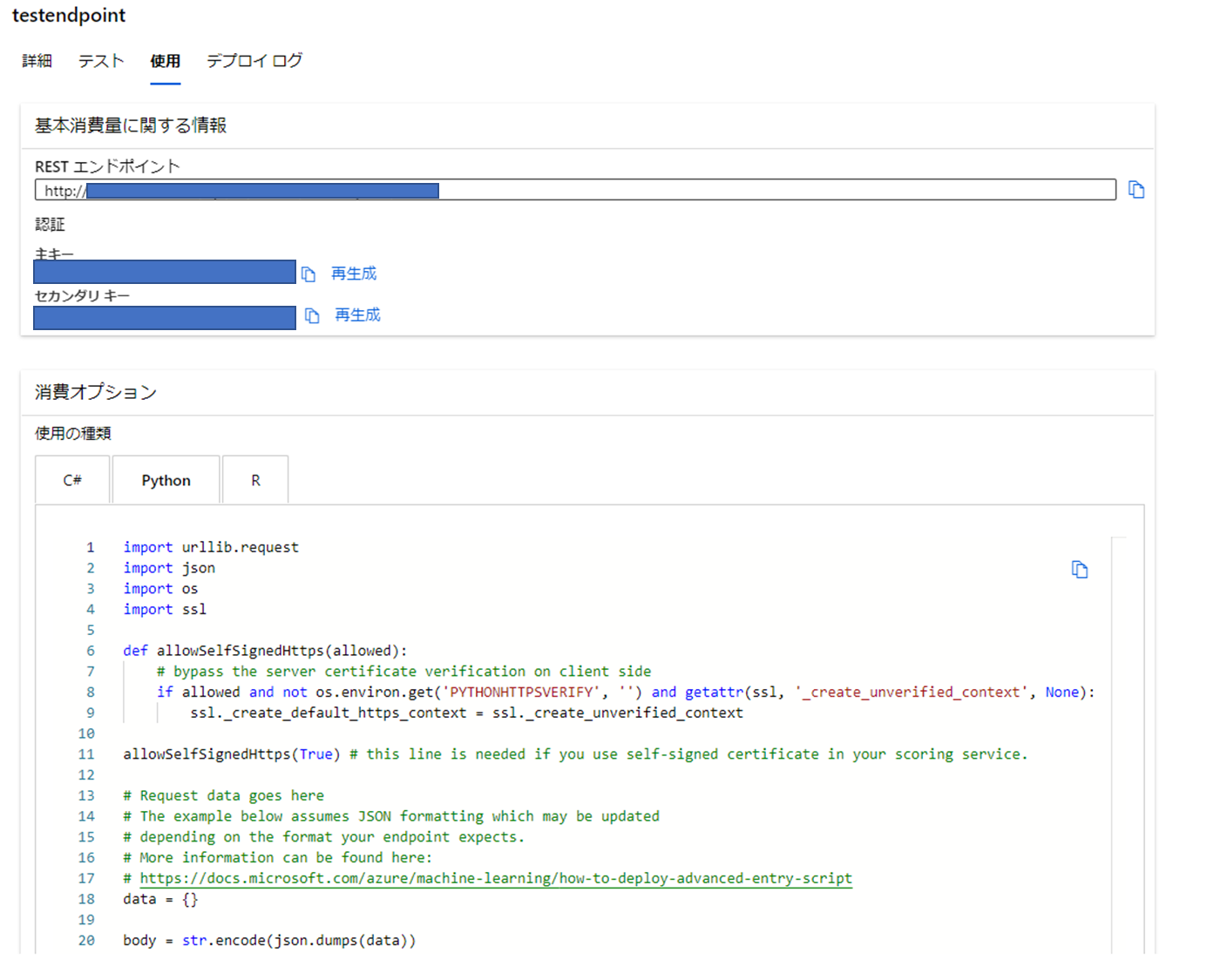
ではpythonコードをコピーしてコードの修正をしていきます。
修正箇所はAPIに投げるデータの部分です。投げるデータの概要は
|
1 2 3 4 5 6 7 |
{ "Inputs": { "WebServiceInput0": ["ここにデータ"], }, "GlobalParameters": {} } |
このような形式である必要があります。
また、入れ込むデータの形は、
|
1 2 3 4 5 6 7 |
{ "symboling": -2, "normalized-losses": 0.0, "make": "volvo", ... }, |
のように{"カラム名": データ}である必要があります。
また、実験時に用いたデータの型、カラムをすべてそろえてあげる必要があるので注意しましょう。(この辺も前処理でどうにかできるかもしれませんね)
では実際のコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
import urllib.request import json import os import ssl def allowSelfSignedHttps(allowed): if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None): ssl._create_default_https_context = ssl._create_unverified_context allowSelfSignedHttps(True) data = { "Inputs": { "WebServiceInput0": [{ "symboling": -2, "normalized-losses": 0.0, "make": "volvo", "fuel-type": "gas", "aspiration": "std", "num-of-doors": "four", "body-style": "sedan", "drive-wheels": "rwd", "engine-location": "front", "wheel-base": 104.3, "length": 188.8, "width": 67.2, "height": 56.2, "curb-weight": 2912, "engine-type": "ohc", "num-of-cylinders": "four", "engine-size": 141, "fuel-system": "mpfi", "bore": 3.78, "stroke": 3.15, "compression-ratio": 9.5, "horsepower": 114, "peak-rpm": 5400, "city-mpg": 23, "highway-mpg": 28, "price": 12940 }, ], }, "GlobalParameters": {} } body = str.encode(json.dumps(data)) url = 'YourEndpoint' api_key = 'YOurAPIKey' headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)} req = urllib.request.Request(url, body, headers) try: response = urllib.request.urlopen(req) result = response.read() print(result) except urllib.error.HTTPError as error: print("The request failed with status code: " + str(error.code)) print(error.info()) print(error.read().decode("utf8", 'ignore')) |
こちらを実行すると下記のような結果が返ってきました。
「Scored Labels」が追加されていますね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
{ "Results": { "WebServiceOutput0": [ { "symboling": -2, "make": "volvo", "fuel-type": "gas", "aspiration": "std", "num-of-doors": "four", "body-style": "sedan", "drive-wheels": "rwd", "engine-location": "front", "wheel-base": 104.3, "length": 188.8, "width": 67.2, "height": 56.2, "curb-weight": 2912, "engine-type": "ohc", "num-of-cylinders": "four", "engine-size": 141, "fuel-system": "mpfi", "bore": 3.78, "stroke": 3.15, "compression-ratio": 9.5, "horsepower": 114.0, "peak-rpm": 5400.0, "city-mpg": 23, "highway-mpg": 28, "price": 12940.0, "Scored Labels": 16672.492419106384 } ] } } |
これで作成したエンドポイントの確認ができました!
まとめ
今回はAzureMLのデザイナー機能を使ったモデルの作成からエンドポイントの実行までやってみました。
最後の確認ではコードを触ったものの、モデルの実装からエンドポイントの作成まではノーコードでできたのではないでしょうか。
今回はすべて手作業で作成してみましたが、次回以降はすでにあるサンプルを動かしつつ、AzureMLでできることを探っていけるといいかなと思います。
