はじめに
Azure Synapse Analytics、もしくは Data Factory でオンプレミスや Azure 仮想ネットワーク (VNet) 内のデータソースにアクセスする場合に必要なセルフホステッド統合ランタイム (セルフホステッド IR) の構成方法の説明となります。
検証には、Synapse Analytics を使用していますが、Data Factory の場合もほぼ同じ手順となります。
実装内容
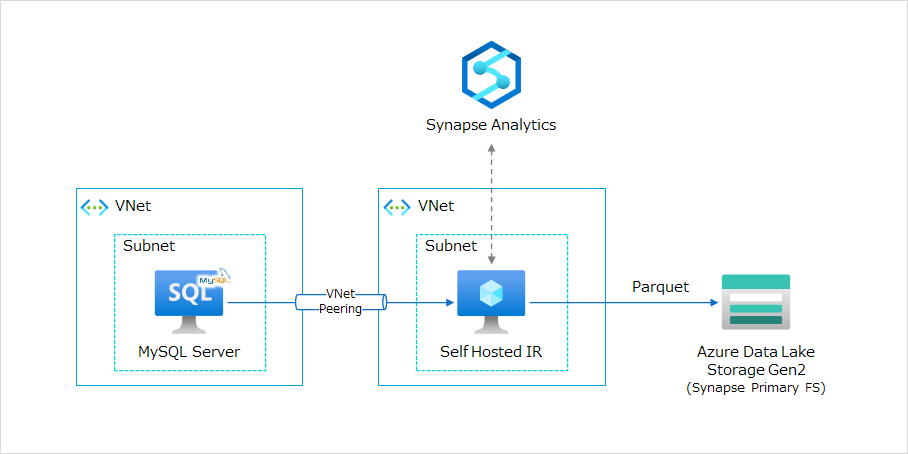
プライベートネットワーク上にある DB サーバからデータを抽出し、Azure Data Lake Storage Gen2 (ADLS Gen2) に Parquet 形式で書き出す想定での実装を行います。
検証環境では、以下の構成図の通り、セルフホステッド IR の稼働ホストとして Azure 仮想マシン (VM) を使用し、オンプレミスと閉域接続している想定で別 VNet 上の MySQL サーバに仮想ネットワークピアリングで接続しています。
簡単に検証をするのであれば、セルフホステッドIRと同一の VNet 内に適当な RDB の VM を作成すれば問題ありません。
なお、本記事はセルフホステッド IR の構成、設定がメインとなるため、Synapse Analytics、ADLS Gen 2といった、セルフホステッド IR 以外のリソースがすべて作成済みであることを前提とします。
セルフホステッド IR 用 VM、およびネットワークについては以下の条件にて作成したものを使用します。
ネットワーク
以下内容で作成した VNet、Subnetを使用しています。
| 項目 | 設定値 |
|---|---|
| VNet | 192.168.8.0/22 |
| Subnet | 192.168.8.0/26 |
Subnet には以下の Network Security Group (NSG) を適用しています。
セルフホステッド IR の詳細なネットワーク要件は、こちら を確認してください。
- Inbound Security Rules
| Priority | Name | Port | Protocol | Source | Destination | Action |
|---|---|---|---|---|---|---|
| 100 | Allow_RDP | 3389 | TCP | {My IP} | Any | Allow |
| 65000 | AllowVnetInBound | Any | Any | VirtualNetwork | VirtualNetwork | Allow |
| 65001 | AllowAzureLoadBalancerInBound | Any | Any | AzureLoadBalancer | Any | Allow |
| 65500 | DenyAllInBound | Any | Any | Any | Any | Deny |
- Outbound Security Rules
| Priority | Name | Port | Protocol | Source | Destination | Action |
|---|---|---|---|---|---|---|
| 65000 | AllowVnetOutBound | Any | Any | VirtualNetwork | VirtualNetwork | Allow |
| 65001 | AllowInternetOutBound | Any | Any | Any | Internet | Allow |
| 65500 | DenyAllOutBound | Any | Any | Any | Any | Deny |
Azure VM
セルフホステッド IR の最小要件を満たす構成にてVMを作成しています。
以下の要件以外は作成環境に応じて適宜変更してください。
| 項目 | 設定値 | インストール要件 |
|---|---|---|
| イメージ | Windows Server 2019 Datacenter – Gen1 | 以下のうちいずれかのOS
|
| サイズ | Standard F4s v2 (4 vcpu, 8 GiB RAM) | 4 Core 2 GHz CPU, 8 GB RAM 以上 |
セルフホステッド IR の登録
はじめに、Synapse Studio にセルフホステッド IR を登録し、統合ランタイムをホストマシンにインストールするための情報を生成します。
Synapse Studio を開き、ページ左の「管理」をクリックします。
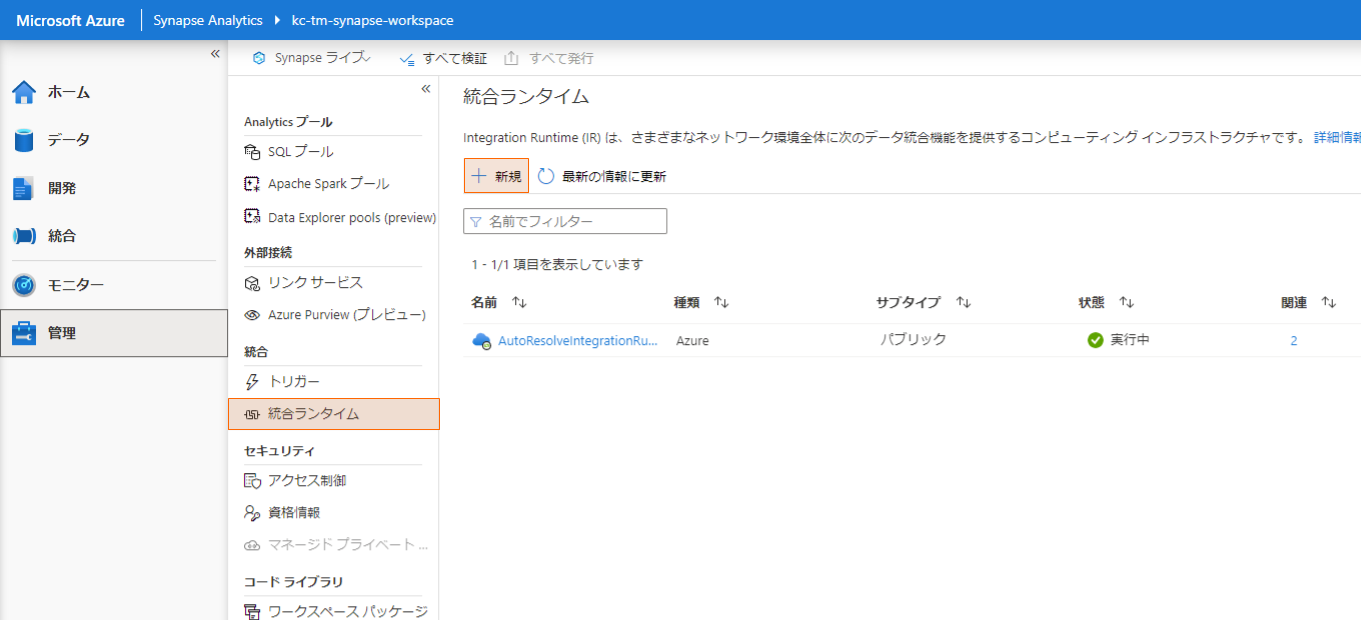
メニューから「統合ランタイム」を選択し、「+新規」をクリックします。
「統合ランタイムのセットアップ」のランチャーで「セルフホステッド」を選択して「続行」をクリックし、「名前」に統合ランタイム環境を識別する一意の名前を入力し、「作成」をクリックします。
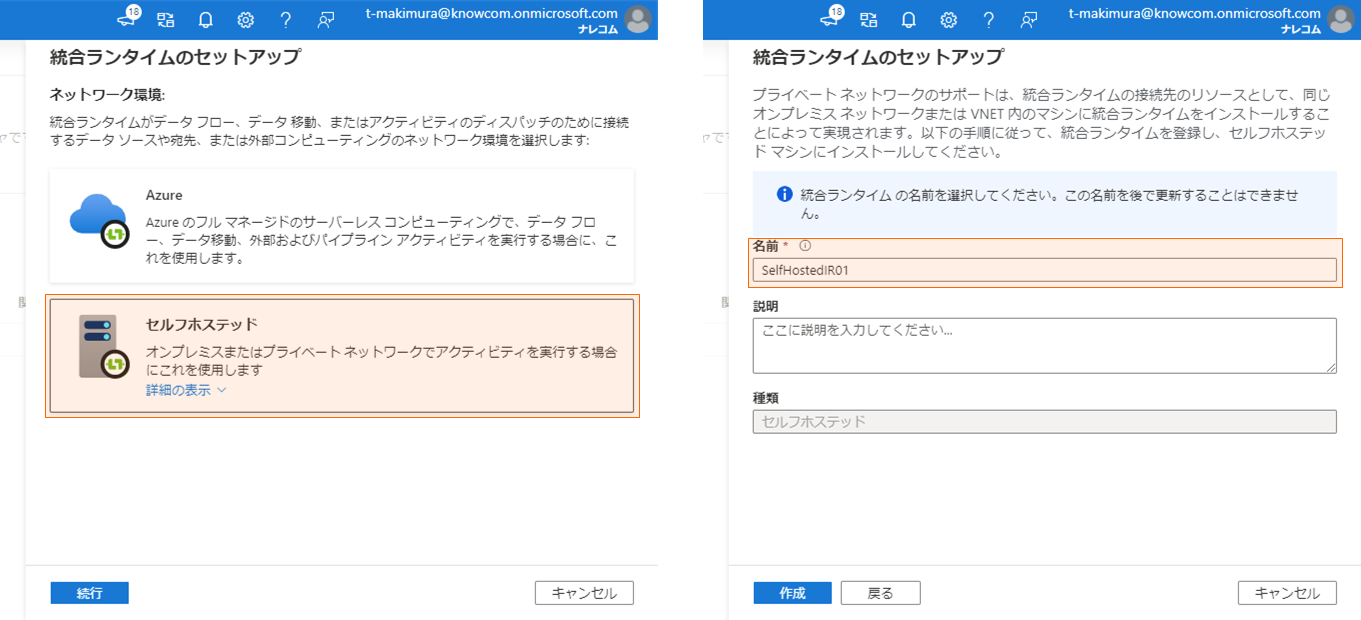
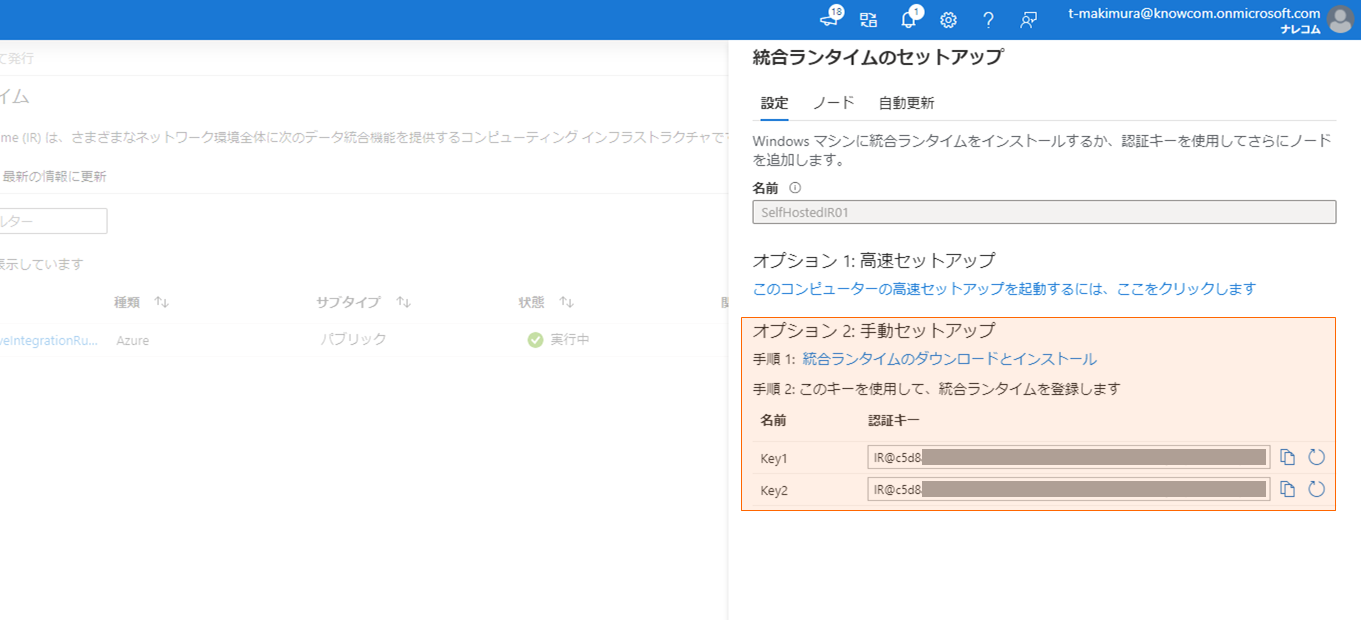
作成後に表示される「オプション 2: 手動セットアップ」に従い、「統合ランタイムのダウンロードとインストール」のリンク先から統合ランタイムインストーラをローカルPCにダウンロードし、「認証キー」のいずれかをコピーして控えておきます。
統合ランタイムのインストール
統合ランタイムをインストールする Azure VM に RDP でログインします。
ローカルPCにダウンロードしておいた統合ランタイムインストーラを RDP 経由でリモートサーバに配置します。
ローカルPC上のファイルをコピーし、リモートサーバのデスクトップに貼り付けます。
インストーラを起動して、統合ランタイムのインストールを進めます。
インストールが完了すると、以下のようなウィンドウが開きます。
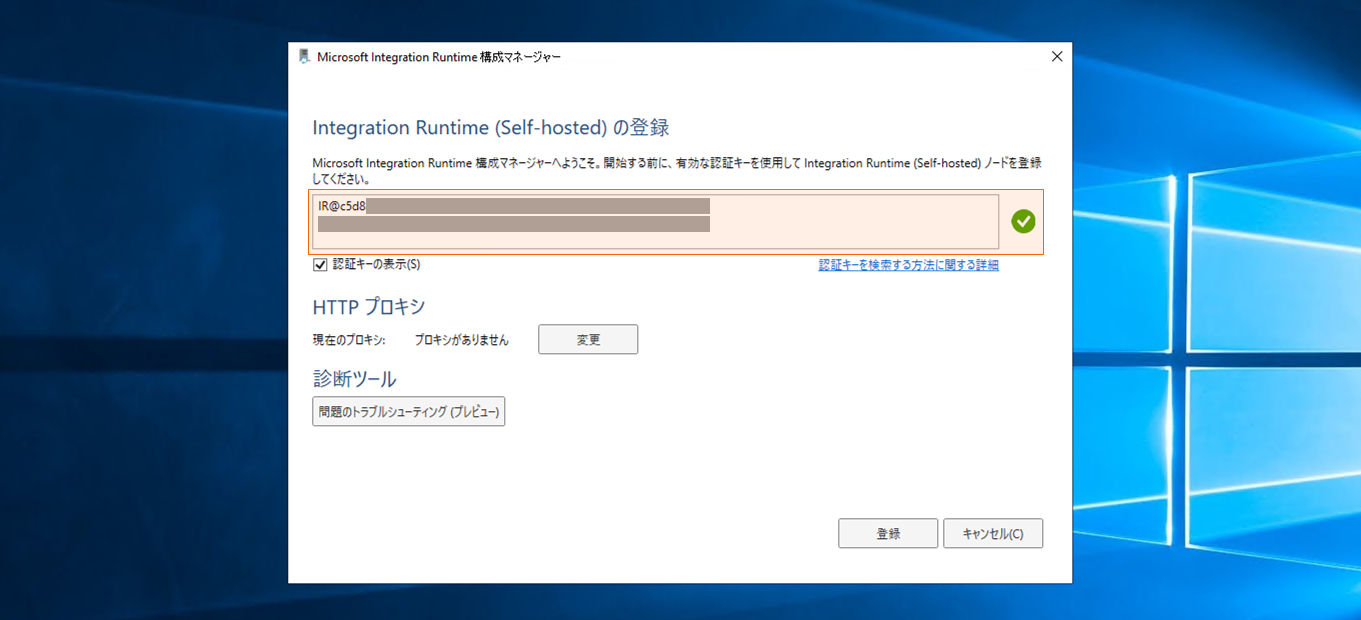
テキストボックスに Synapse Studio のセルホステッドIR 登録時に控えておいた認証キーを入力し、登録をクリックします。
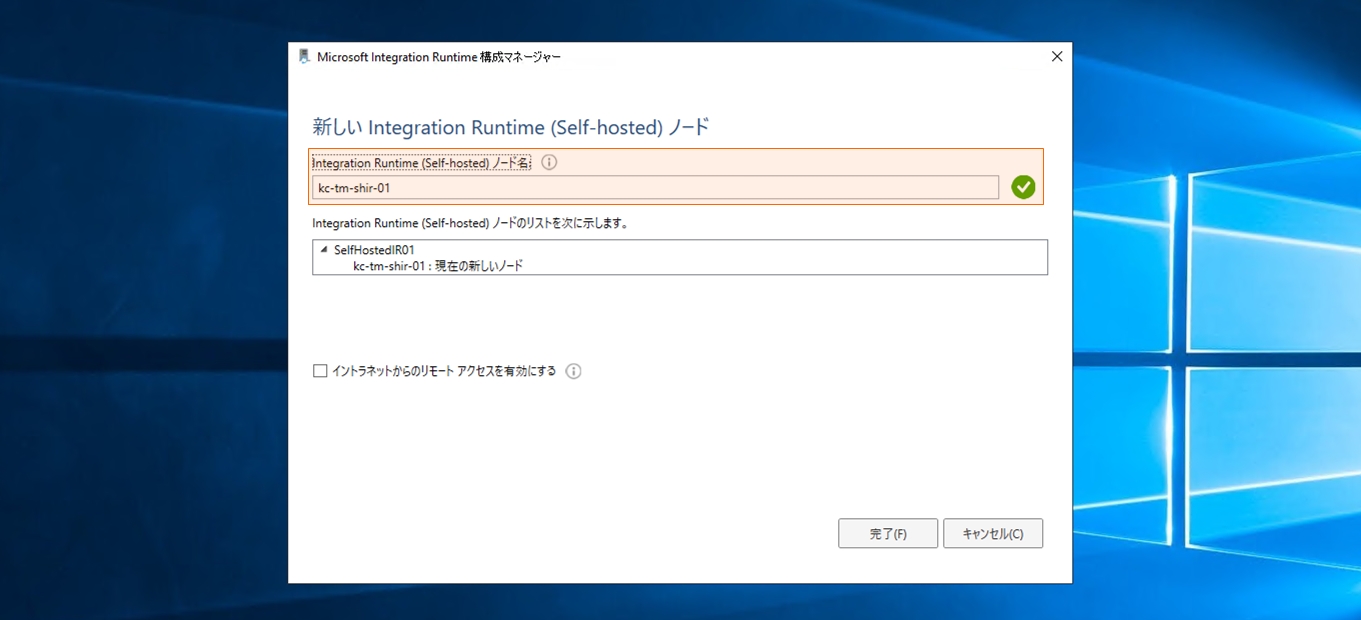
「Integration Runtime (Self-hosted) ノード名」を任意の名称に変更し、「完了」をクリックします。
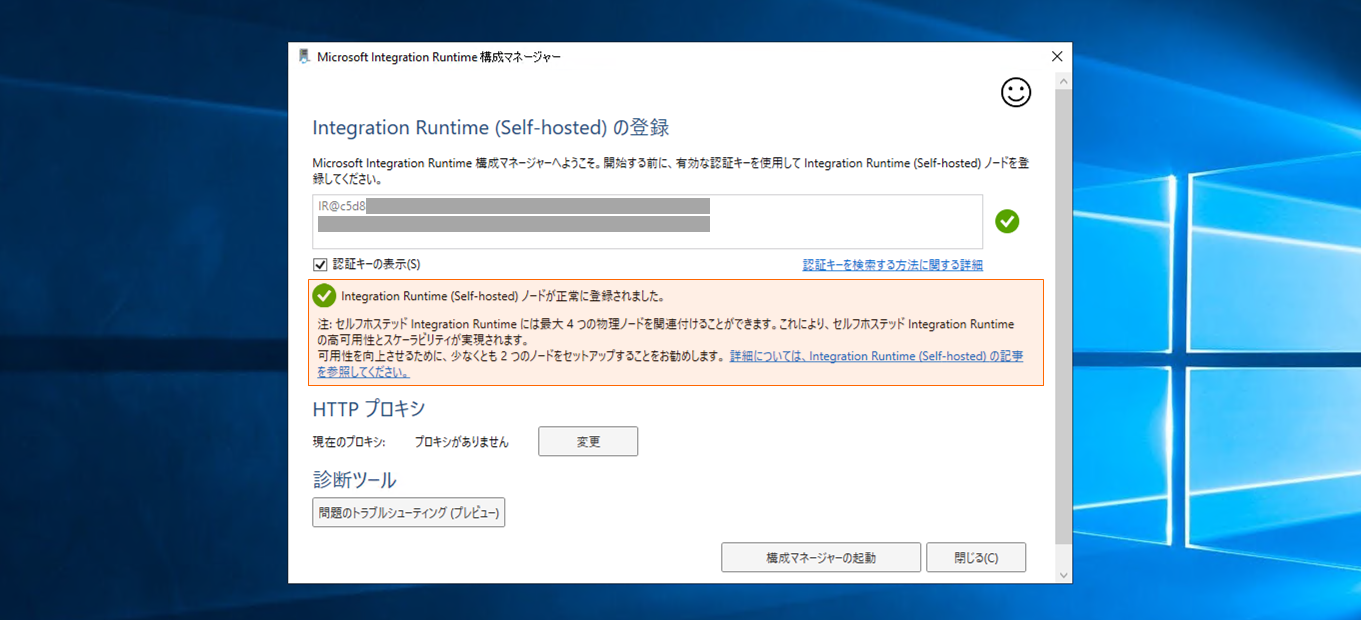
正常に登録されたら、「構成マネージャーの起動」をクリックして完了させます。
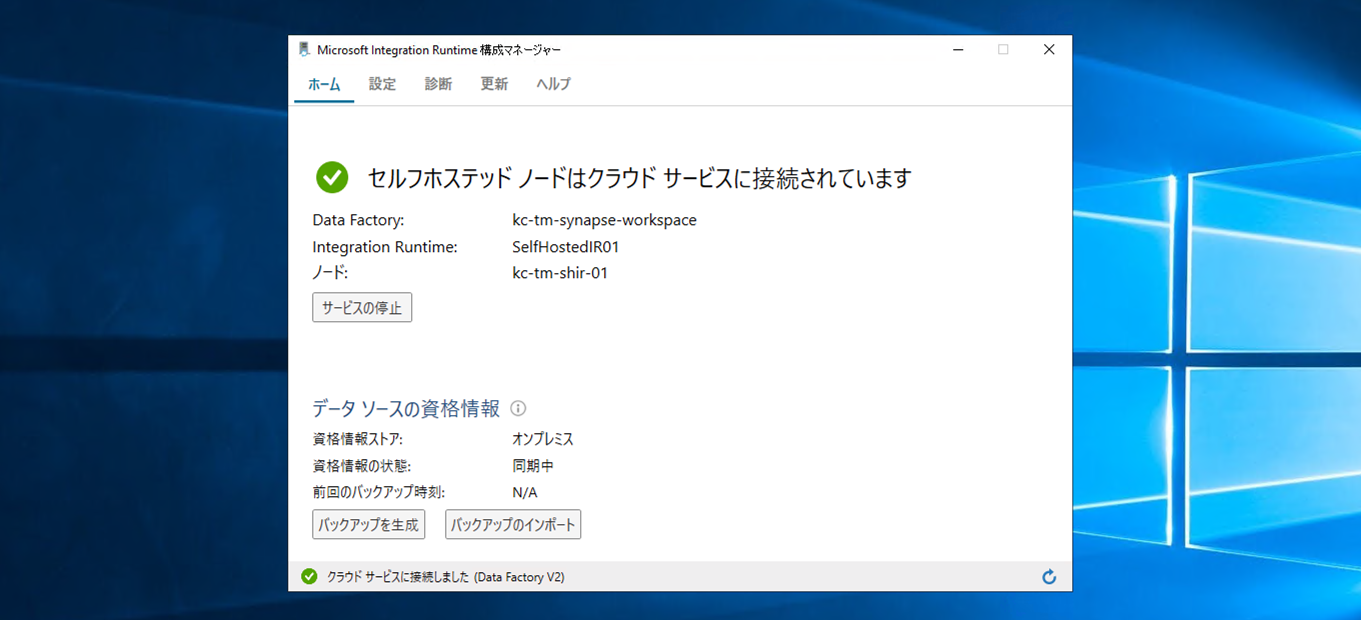
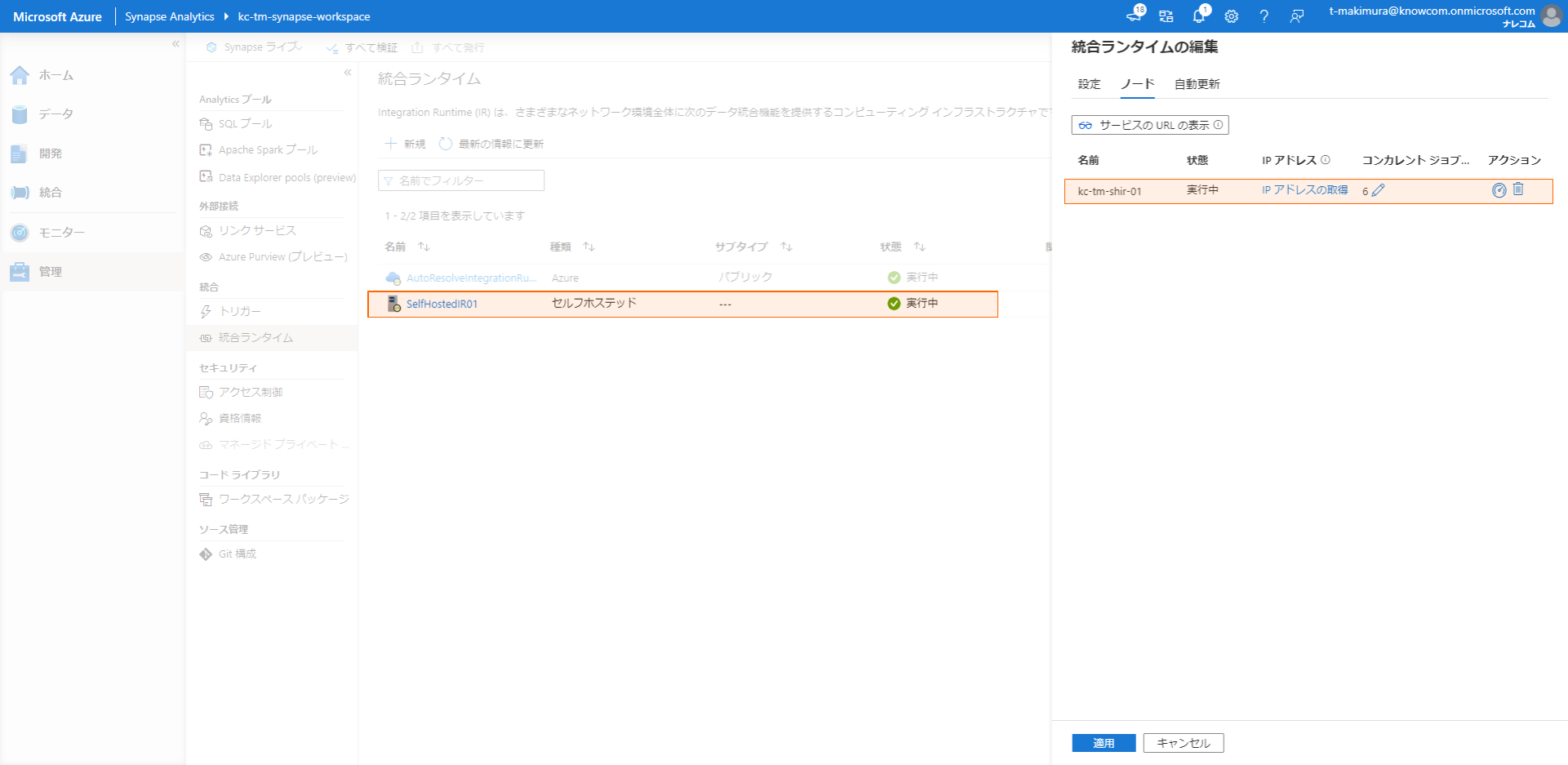
Synapse Studioの「統合ランタイム」で登録したセルフホステッドIRを開き、「ノード」タブをクリックすると登録されたセルフホステッド IR ノードを確認できます。
Java Runtime のインストール
セルフホステッド IR で Parquet 等の特定形式のデータを扱う場合は、ホストマシンに Java Runtime をインストールしておく必要があります。
Java Runtime としては、JRE、もしくは OpenJDK を使用することができますが、ここでは OpenJDK を使用します。
OpenJDK を使用する場合は、任意のビルドの「OpenJDK 8」と「Microsoft Visual C++ 2010 再頒布可能パッケージ」をホストマシンにインストールします。
使用したものは以下の通りです。
- Adoptium OpenJDK 8 (Windows x64)
- Microsoft Visual C++ 2010 再頒布可能パッケージ
統合ランタイムインストーラと同様にそれぞれのインストーラをリモートサーバに配置し、デフォルト設定のままインストールを進めます。
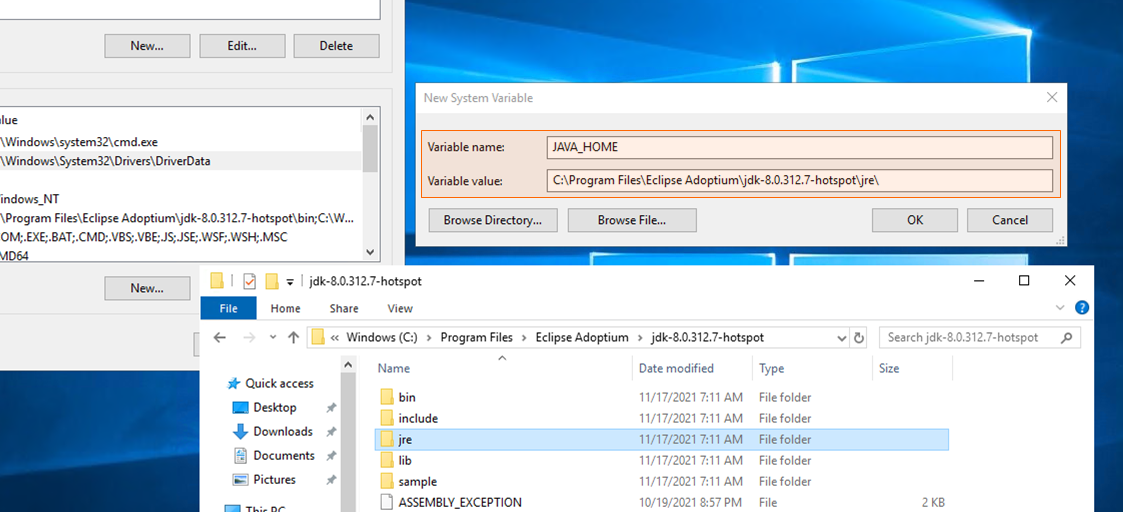
インストールが終わったら、OpenJDK インストール先フォルダ内の jre フォルダパスをシステム環境変数「JAVA_HOME」として追加します。
リンクサービスの登録
セルフホステッド IR で接続するプライベートネットワーク内の DB サーバをリンクサービスとして登録します。
ここでは MySQL サーバを使用しますが、接続先に応じて適宜設定内容を変更してください。
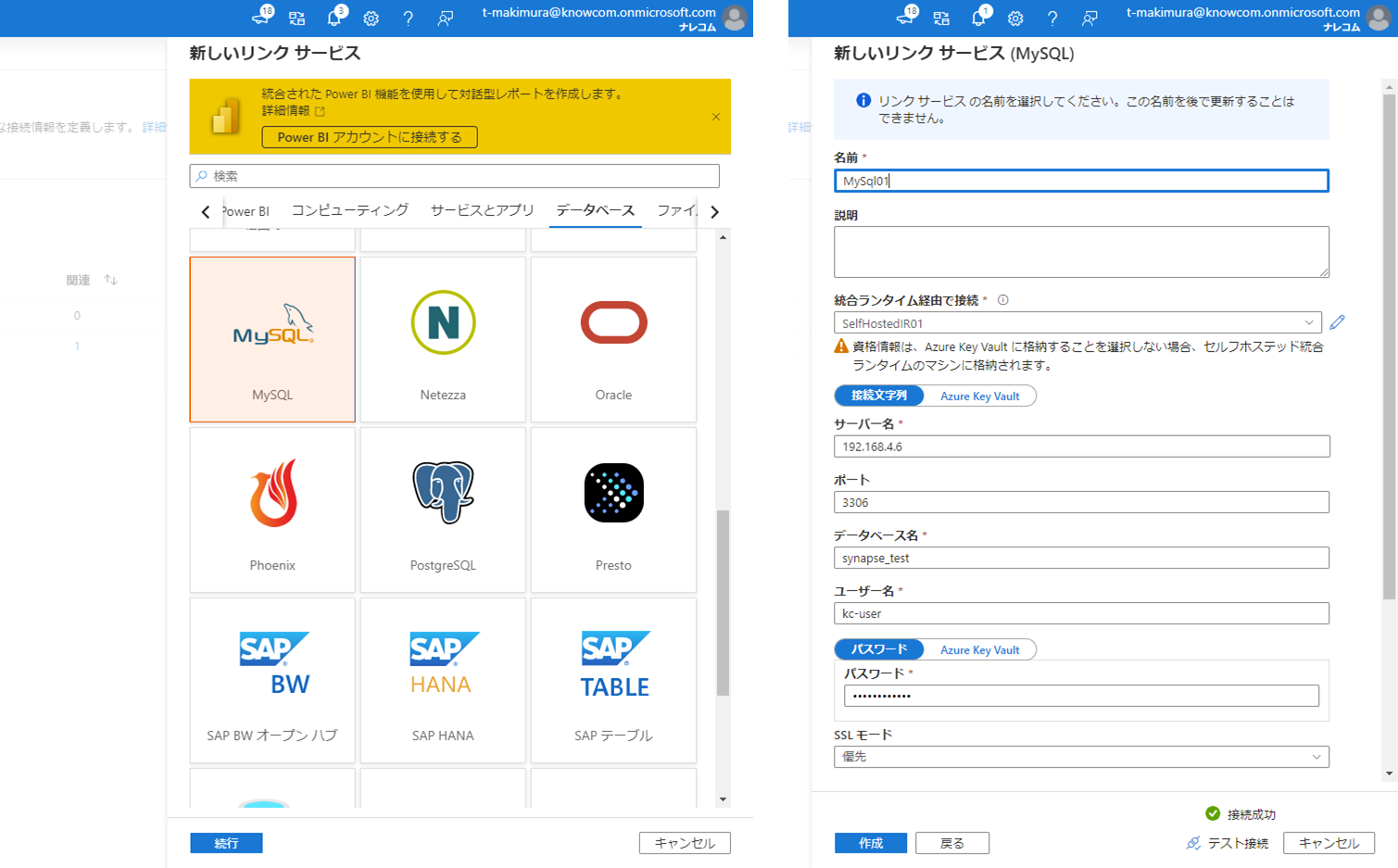
Synapse Studio の「管理」から「リンクサービス」を選択し、「+新規」をクリックします。
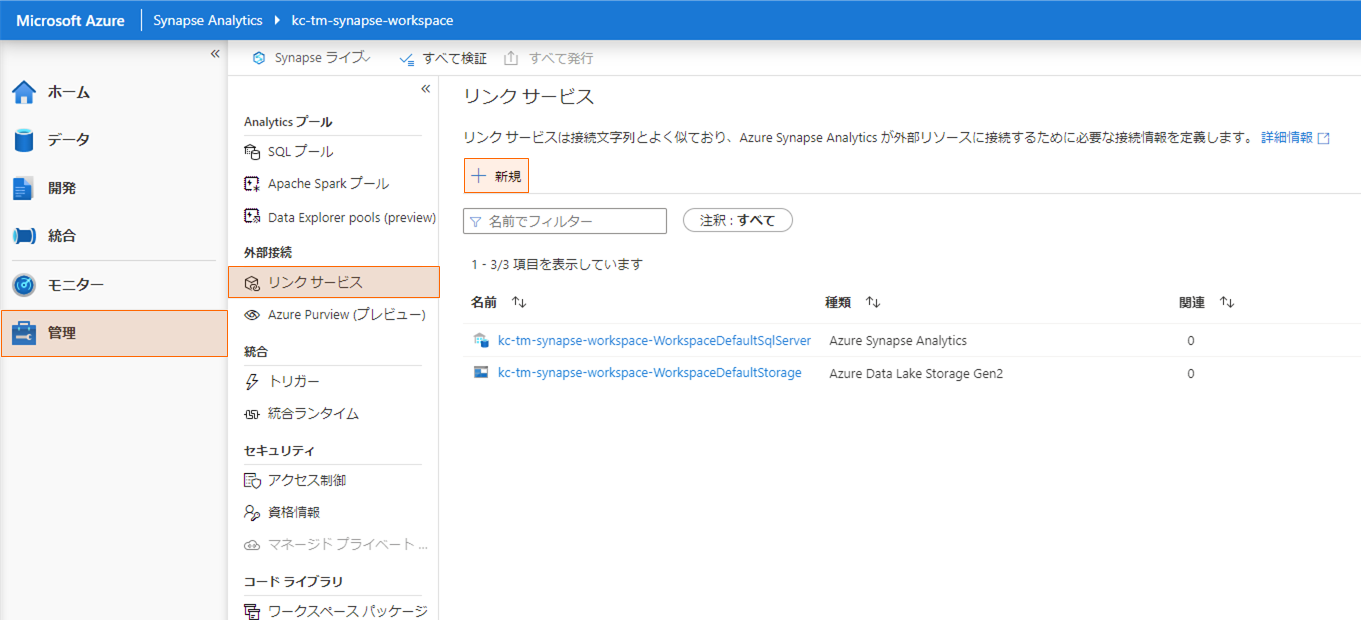
データストアの選択から「MySQL」を選択して「続行」をクリックし、フォームにDBの接続情報を入力します。
「統合ランタイム経由で接続」は作成したセルフホステッドIRを指定します。
入力が完了したら、「テスト接続」をクリックして接続できることを確認し、「作成」をクリックします。
セルフホステッドIRのテスト
セルフホステッドIRのテストとして MySQL サーバからデータを抽出し、Synapse Analytics の Primary ファイルシステムに Parquet ファイルとして出力します。
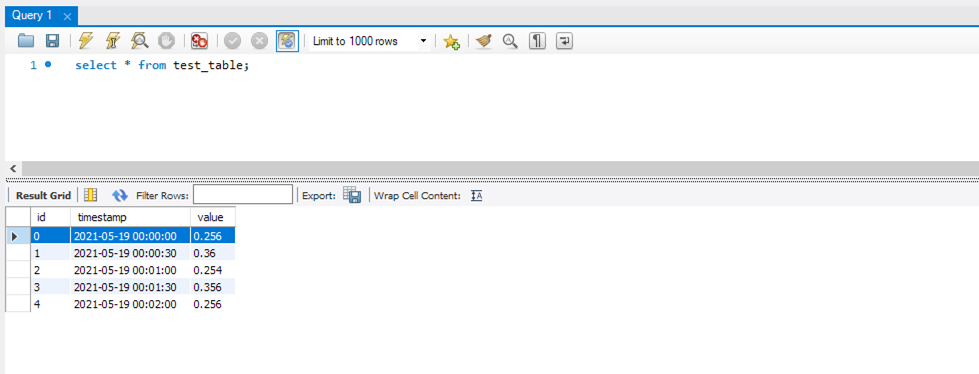
MySQL サーバには以下のようなテスト用テーブルを作成しています。
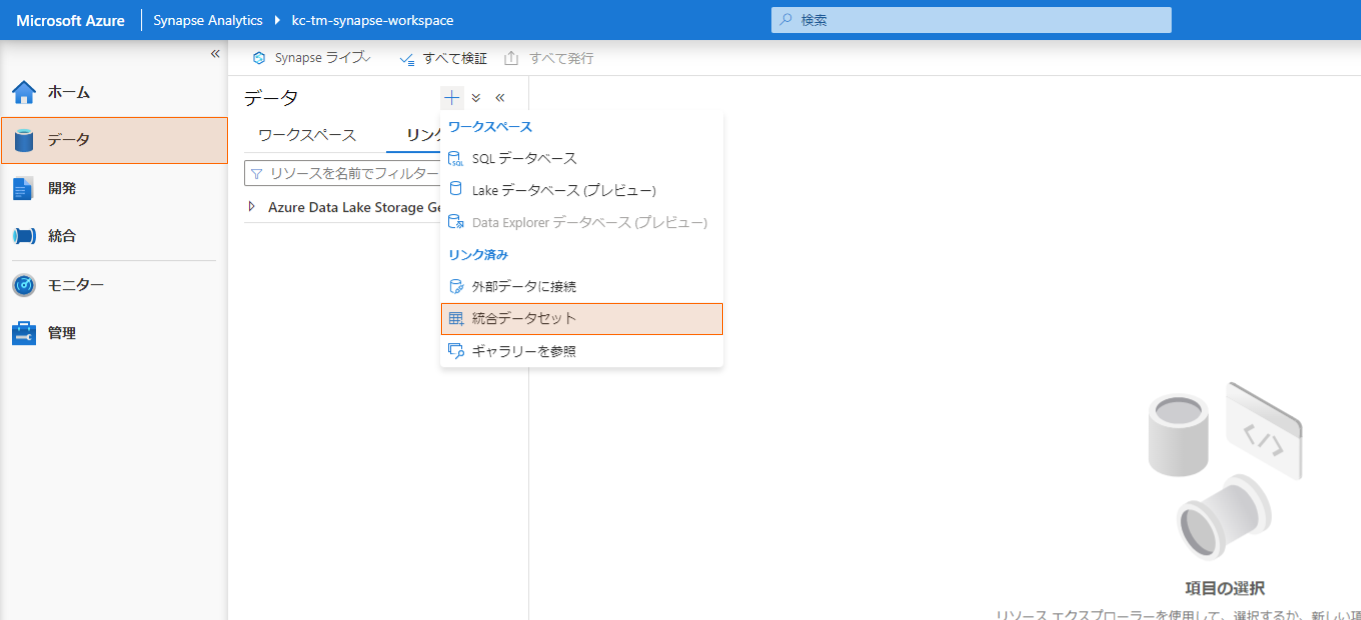
まず、ソース、シンクとなるデータセットを登録します。
「データ」を開き、+ボタンから「統合データセット」を選択します。
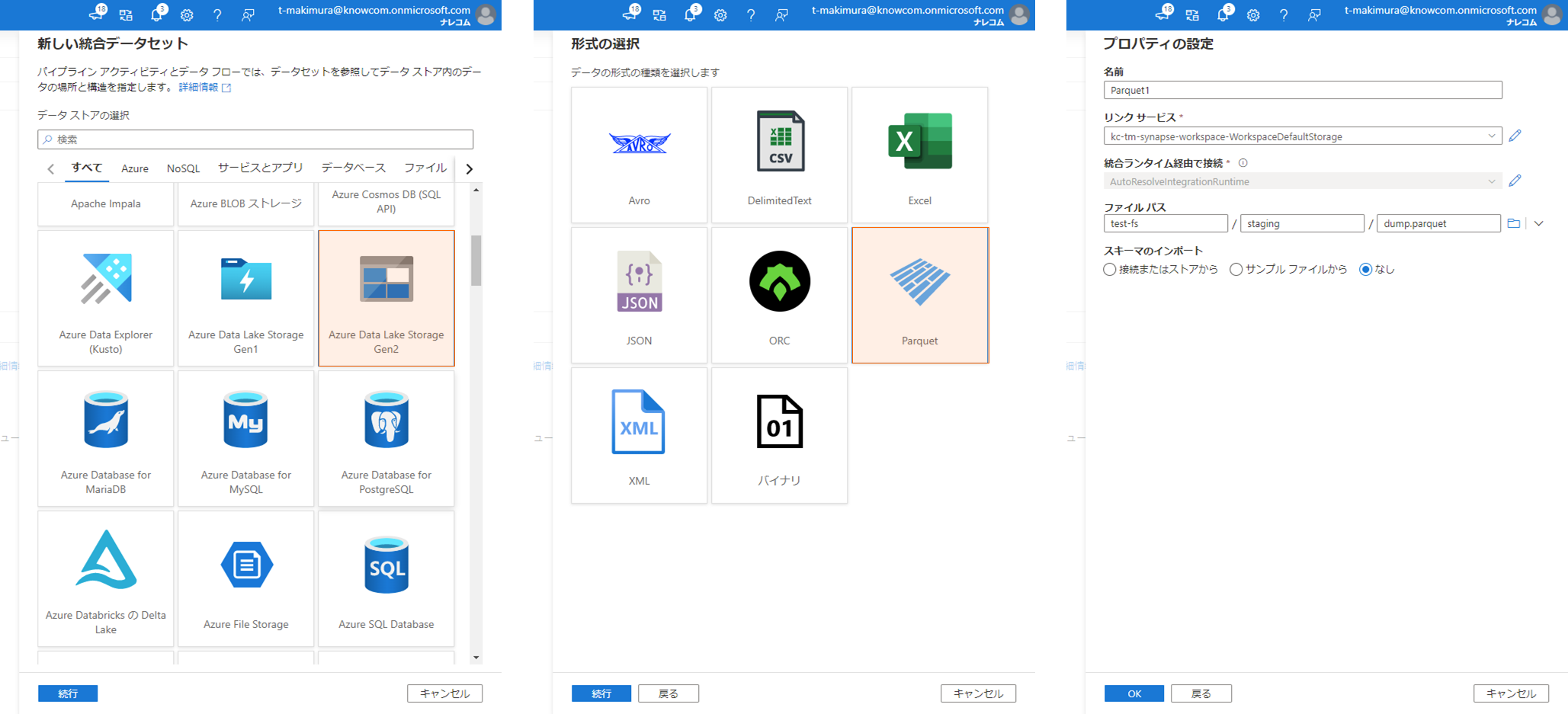
データストアの選択から「MySQL」を選択し、登録した MySQL サーバのリンクサービスとデータを取得するテーブル名を設定します。

シンク先となる Parquet ファイルの書き出し用統合データセットも同様に作成します。
データストアの選択から「Azure Data Lake Storage Gen2」を選択し、形式の選択で「Parquet」を選択します。
リンクサービスとして Synapse Analytics 作成時にデフォルトで作成されているストレージを選択し、「ファイルパス」の「ファイルシステム」に Synapse Analytics の Primary ファイルシステム名、「ディレクトリ」、「ファイル」に任意のパスを入力します。
データを MySQL サーバから抽出し、Parquet ファイルとして出力するパイプラインのを作成します。
「統合」に移動し、+ボタンから「パイプライン」を選択します。
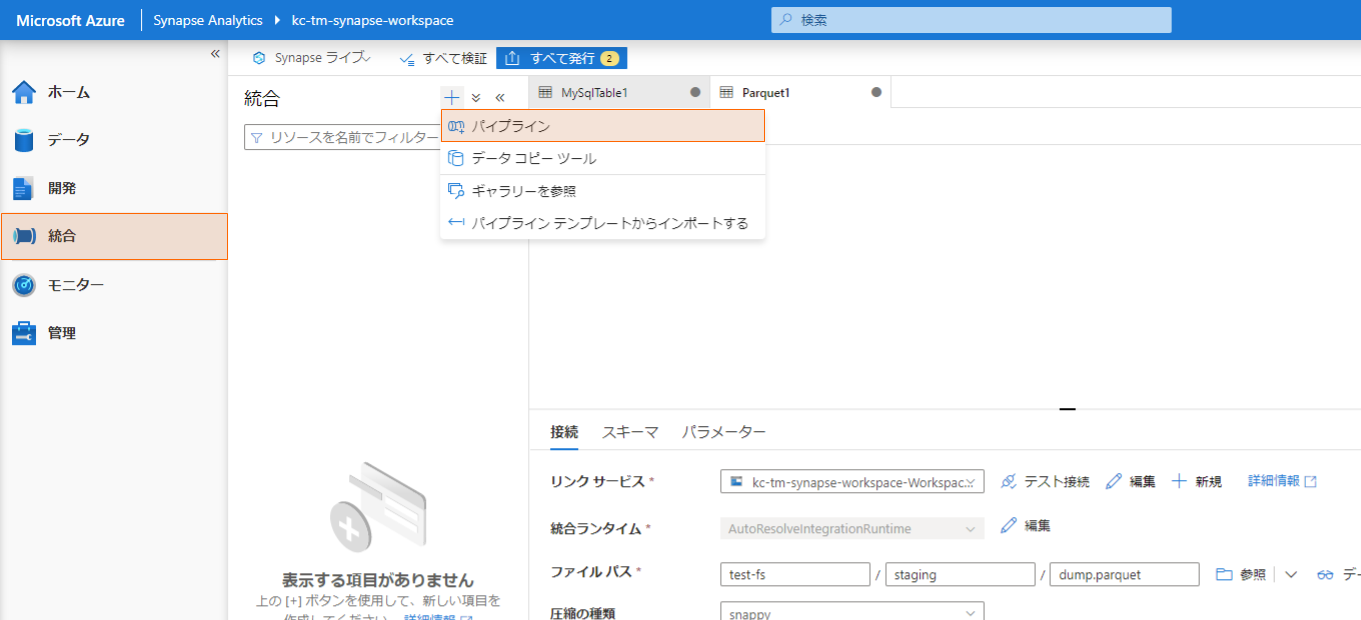
キャンバスに「データのコピー」をドラッグ&ドロップして配置し、アクティビティの「ソース」、「シンク」に上記で作成した MySQL および Parquet の統合データセットを割り当てます。
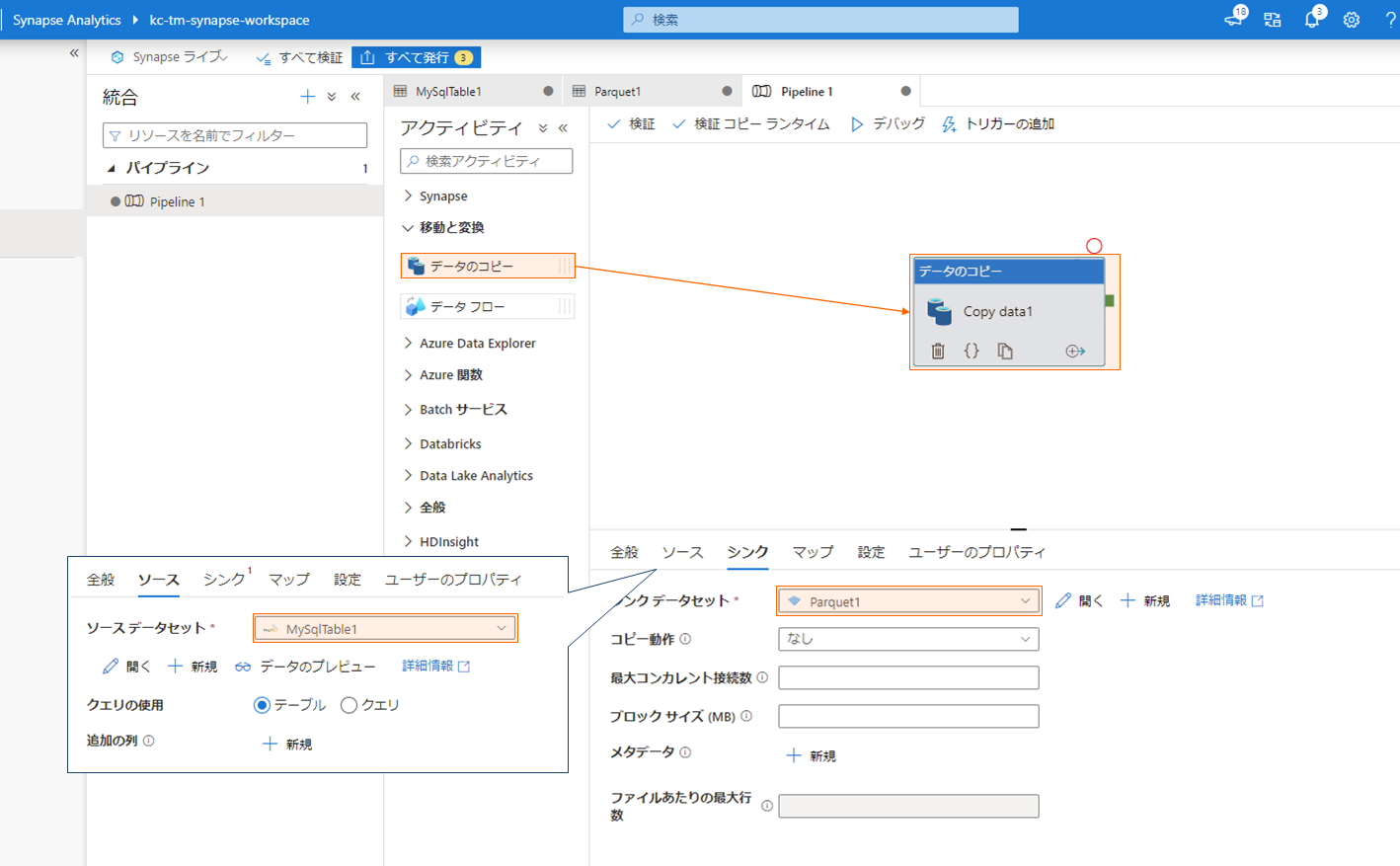
「デバッグ」をクリックしてパイプラインのデバッグを開始し、アクティビティが成功することを確認します。
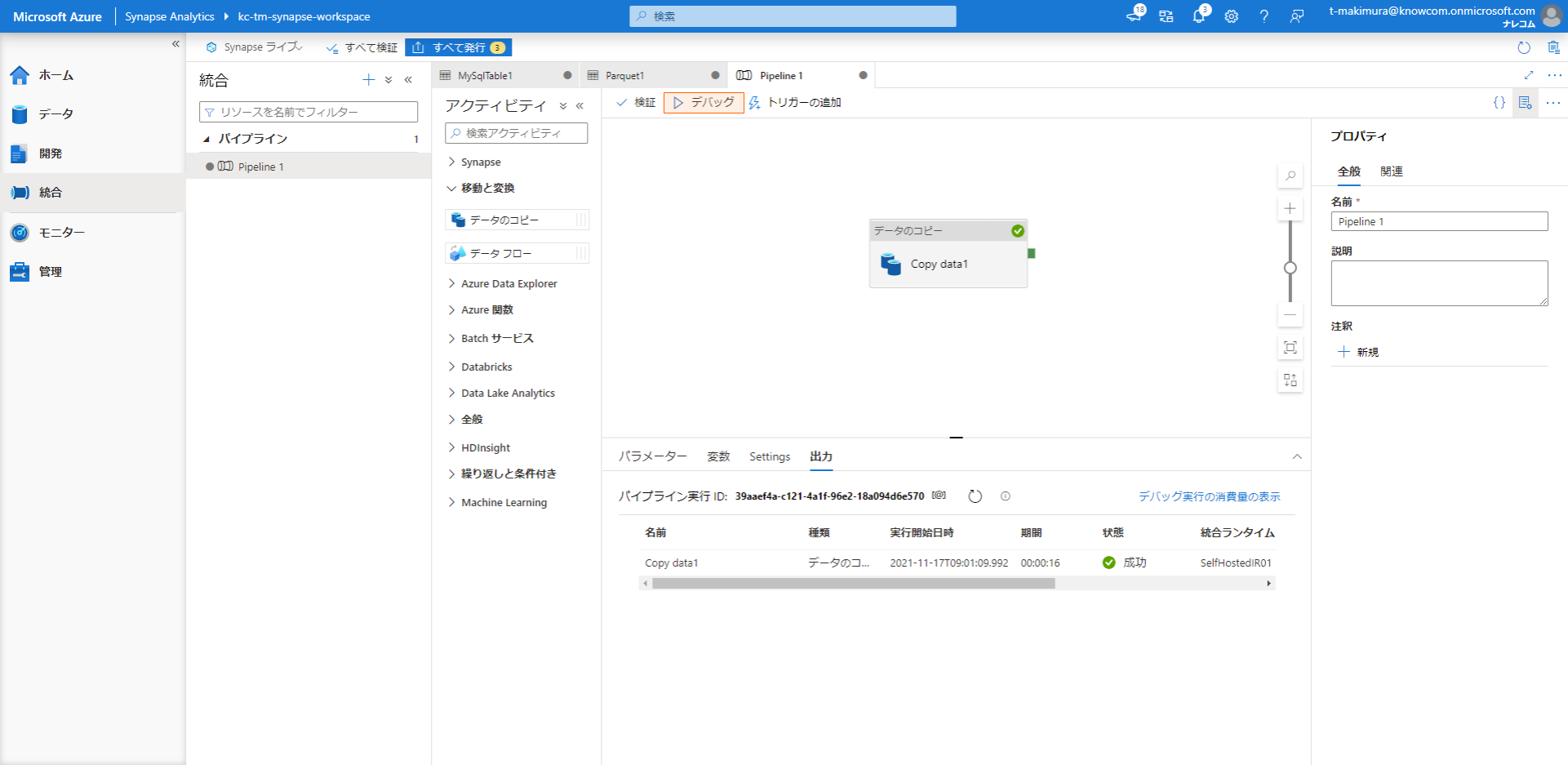
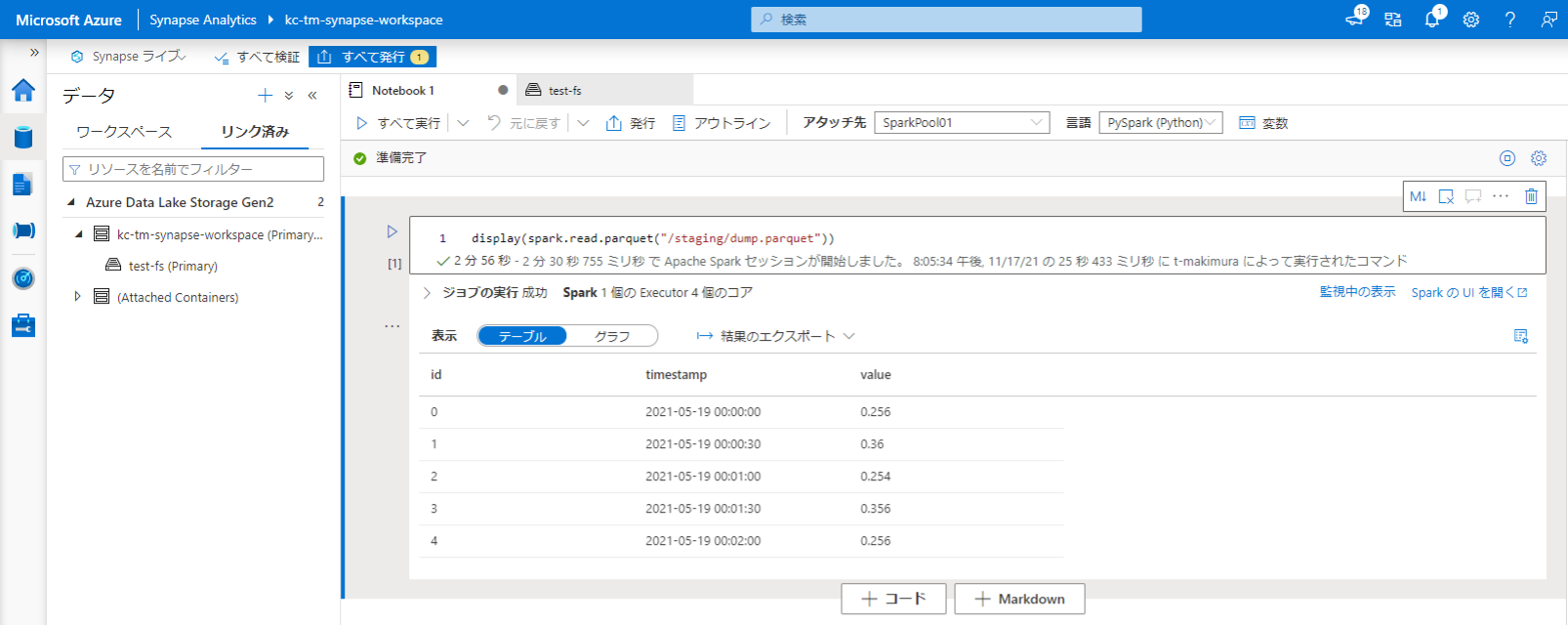
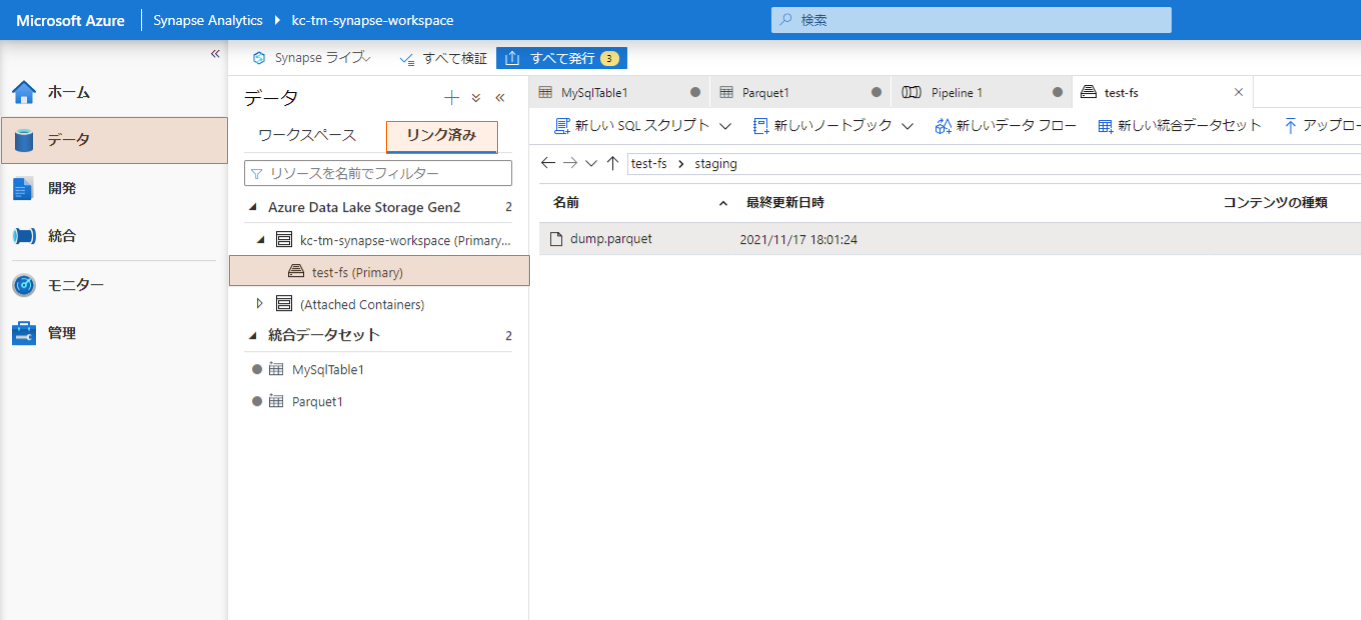
デバッグに成功すると、Synapse Analytics の Primary ファイルシステムに Parquet ファイルが出力されます。
「データ」の「リンク済み」から Primary ファイルシステムを開くと出力された Parquet ファイルを確認できます。
作成された Parquet ファイルを Notebook (PySpark) で確認すると DB の内容を取得できていることが確認できました。