
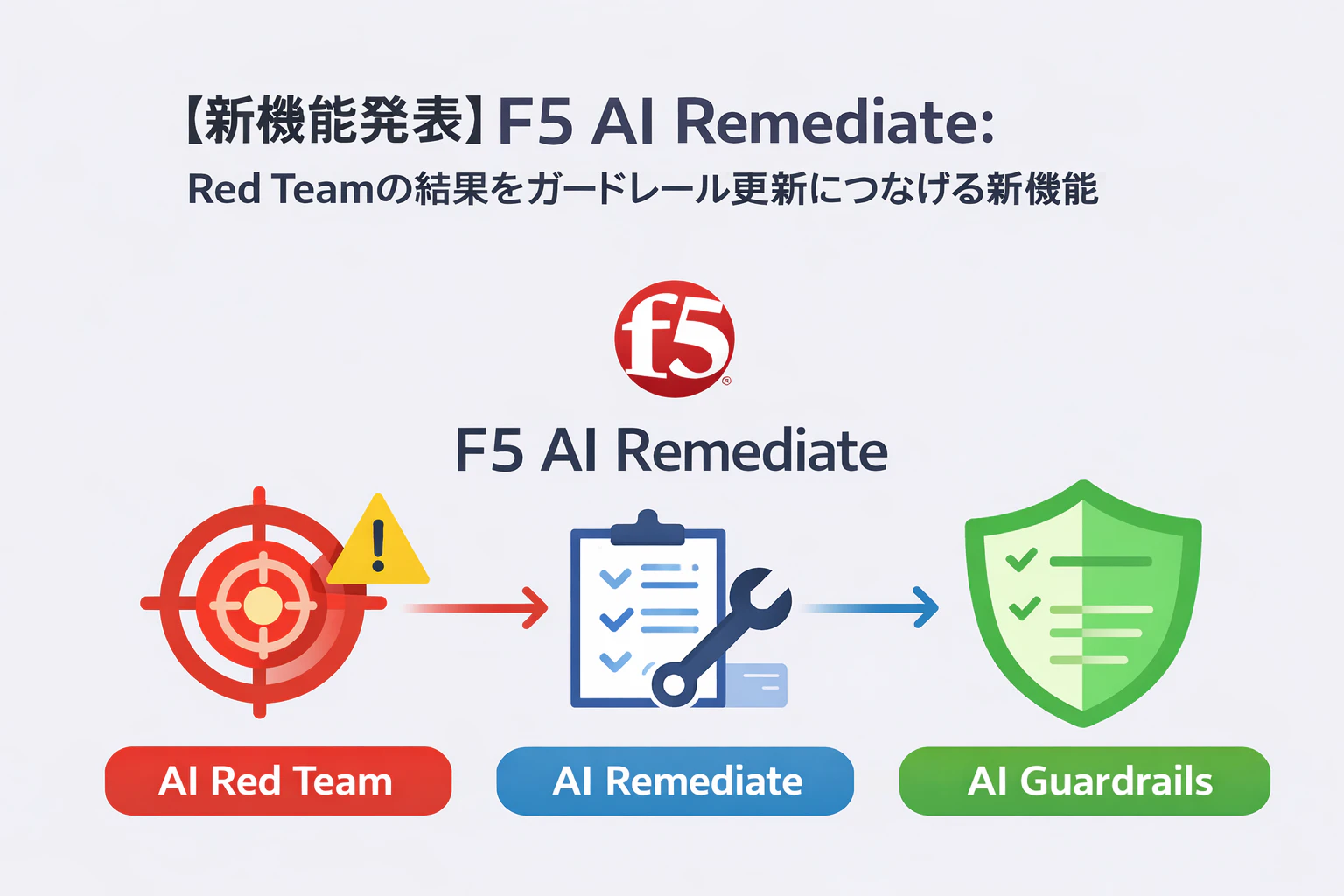
新しく発表された F5 AI Remediate とは
AI Red Team と AI Guardrails の間を埋める新レイヤー
AIセキュリティの議論では、どうしても「脆弱性を見つける」「本番で守る」の2つに注目が集まりがちですが、実務で本当に難しいのは、その間です。
- 問題は見つかった
- でも、どう保護に落とすのか分からない
- 対策は作れた
- でも、本番にどう反映するのかが属人的
この“間”を埋めるのが、F5 AI Remediate だと理解すると分かりやすいです。
F5の説明によると、AI Remediate は、F5 AI Red Team が見つけた攻撃的テストの結果(adversarial findings)を、F5 AI Guardrails で適用できる保護ルールへ変換する役割を担います。さらに、保護を適用する前に人が確認・承認する仕組み(human approval)を維持する設計になっています。
全体像
F5の生成AIセキュリティをざっくり並べると、こうなります。
-
F5 AI Red Team
AIアプリやモデルに対して攻撃的テストを行い、脆弱性や危険な挙動を見つける。 -
F5 AI Remediate
見つかったリスクを、実際に適用可能な保護へ落とし込む。 -
F5 AI Guardrails
本番環境で AI の入出力や動作を継続的に保護する。
つまり、役割は次のように分かれます。
見つける → 直す → 守る
この真ん中の「直す」が、今回の主役です。
なぜ AI Remediate が必要なのか
AIセキュリティは、脆弱性診断をして終わりではありません。
むしろ、現場では次のような状態になりがちです。
- レッドチーミングで問題が見つかる
- 報告書は出る
- でも対策ポリシーは手作業で設計する
- 再テストして、また微調整する
- 本番反映の判断も属人的になる
これでは、リスクが見えても、リスクが減るとは限らない です。
F5のブログでも、AI導入が加速する中で、課題は detection より remediation に移りつつあると説明されています。
AI-assisted development や自動デプロイで変更の量と速度が上がる一方、見つかったリスクを統制された形で protection に変える仕組みが弱い、という問題意識です。
要するに、AI Remediate は
「脆弱性を見つけたあと、どうやって本番保護に変えるか」
を製品として扱おうとしているわけです。
AI Remediate は何をするのか
F5の説明をシンプルにまとめると、AI Remediate は次のことをします。
- AI Red Team の findings を受け取る
- Guardrails で適用可能な protection に変換する
- 適用前に human approval を残す
- before / after の改善を測れるようにする
F5のデモページでは、AI Remediate は AI Red Team の insight を tested, production-ready controls に変換する と説明されています。さらに、response time を短縮し、runtime protection を強化し、audit-ready な指標を提供する ことも強調されています。
つまり、ただ設定ファイルを作るツールではありません。
セキュリティ運用の橋渡し をする存在です。
イメージしやすい流れ
実際の流れをシンプルにすると、こうです。
1. AI Red Team で問題を見つける
たとえば、プロンプトインジェクションや機密情報の漏えい、危険な応答パターンなどをテストで検出します。
F5 AI Red Team は、自動化された adversarial testing を通じて、一般的な脅威から特殊な脅威までを継続的に検証する位置づけです。 ([F5, Inc.][2])
2. AI Remediate で対策パッケージ化する
見つかった攻撃パターンを、そのまま「要注意一覧」にするのではなく、Guardrails で enforce できる形に変換します。
3. 人が承認する
F5は human approval を残す設計を明示しています。
ここが大事で、完全自動でセキュリティ制御を本番に流し込むのではなく、統制を保ったまま remediation を高速化する 発想です。
4. AI Guardrails で本番反映する
最終的には Guardrails が本番環境で保護を担います。
Guardrails は、モデル非依存のランタイムセキュリティ層として、プロンプトインジェクションや jailbreak、データ漏えい、有害出力、コンプライアンス要件への対応を支える位置づけです。
この流れを一言で言うと、
“発見”を“運用可能な保護”へ変える
のが AI Remediate です。
どこが新しいのか
正直、セキュリティ製品の世界では「検出」は珍しくありません。
WAF でも、脆弱性診断でも、レッドチーミングでも、問題を見つけること自体はできます。
でも AI の世界では、次の難しさがあります。
- モデルの挙動が変わる
- プロンプトが変わる
- ユースケースごとに許容範囲が違う
- 出力の安全性評価が静的ルールだけでは終わらない
そのため、AIセキュリティは
検出 → 判断 → ポリシー化 → 再検証 → 本番反映
のサイクルがどうしても重くなりがちです。
AI Remediate の新しさは、このサイクルのうち
“判断からポリシー化” を短くする
ことにあります。
これは、単に便利というだけではなく、AIガバナンス上も意味が大きい です。
AIガバナンスの観点でも重要
AI Remediate は、単なる運用効率化ではありません。
F5の説明では、AI Remediate によって
- discovered risk と implemented mitigation の対応関係を残せる
- human approval を維持できる
- 改善を measurable に示せる
- 継続的に protection を検証できる
とされています。
これをガバナンスの言葉で言い換えると、
- 何を見つけたか
- 何を直したか
- 誰が承認したか
- どれだけ改善したか
を追いやすくする、ということです。
AIの導入が進むほど、
「守っているはずです」
では済まなくなります。
どう検出し、どう対処し、どう統制したのか
まで説明できることが重要になります。
AI Remediate は、その説明責任にも効く製品だと見ています。
AI Guardrails / AI Red Team との関係
ここを整理しておくと、全体像がかなり見えやすいです。
AI Red Team
- 脅威を見つける
- 攻撃をシミュレートする
- AIの弱点を可視化する
AI Remediate
- Findings を対策へ変換する
- 適用可能な control にする
- 人の承認を残す
AI Guardrails
- 本番環境で enforce する
- AI入出力を守る
- ポリシーを継続的に適用する
この3つは別製品というより、1つの運用ループ として理解した方が自然です。
生成AIセキュリティで見たときの価値
生成AIセキュリティの現場では、対策が次のどちらかに寄りがちです。
- 診断やレッドチーミング中心
- 本番のガードレール中心
もちろんどちらも必要ですが、その間が弱いと運用が続きません。
AI Remediate は、そのギャップを埋めることで、
- レッドチーミングを「やりっぱなし」にしない
- ガードレールを「場当たり設定」にしない
- remediation を監査可能にする
という価値を持ちます。
ここは、かなり実務的に効く部分だと思います。
まとめ
F5 AI Remediate をひとことで言うなら、
AI Red Team の発見を、AI Guardrails の保護へ変えるための運用レイヤー
です。
生成AIセキュリティでは、「見つける」だけでも、「守る」だけでも足りません。
大事なのは、その間をどう短く、どう統制し、どう継続運用できるかです。
その意味で、F5 AI Remediate は
AI Guardrails / AI Red Team を本当に使える仕組みに近づける製品
として見ると理解しやすいと思います。
