前回記事
Azure Databricks: 1. リソースの作成
Azure Databricks: 2. Databricksの基本事項
Azure Databricks: 3-1. DBFSにBlob Storageをマウント
サービスプリンシパルの作成
Azure DatabricksのDBFSにAzure Data Lake Storage Gen2 (ADLS Gen2)をマウントするには、サービスプリンシパルの設定が必要になるため,あらかじめ作成しておきます。
(サービスプリンシパルはアプリケーションに対して割り当てるユーザーIDのようなものです。)
「すべてのサービス」の「ID」カテゴリから「Azure Active Directory」を開きます。
メニューの「App registrations」を開き、「+新規作成」をクリックします。
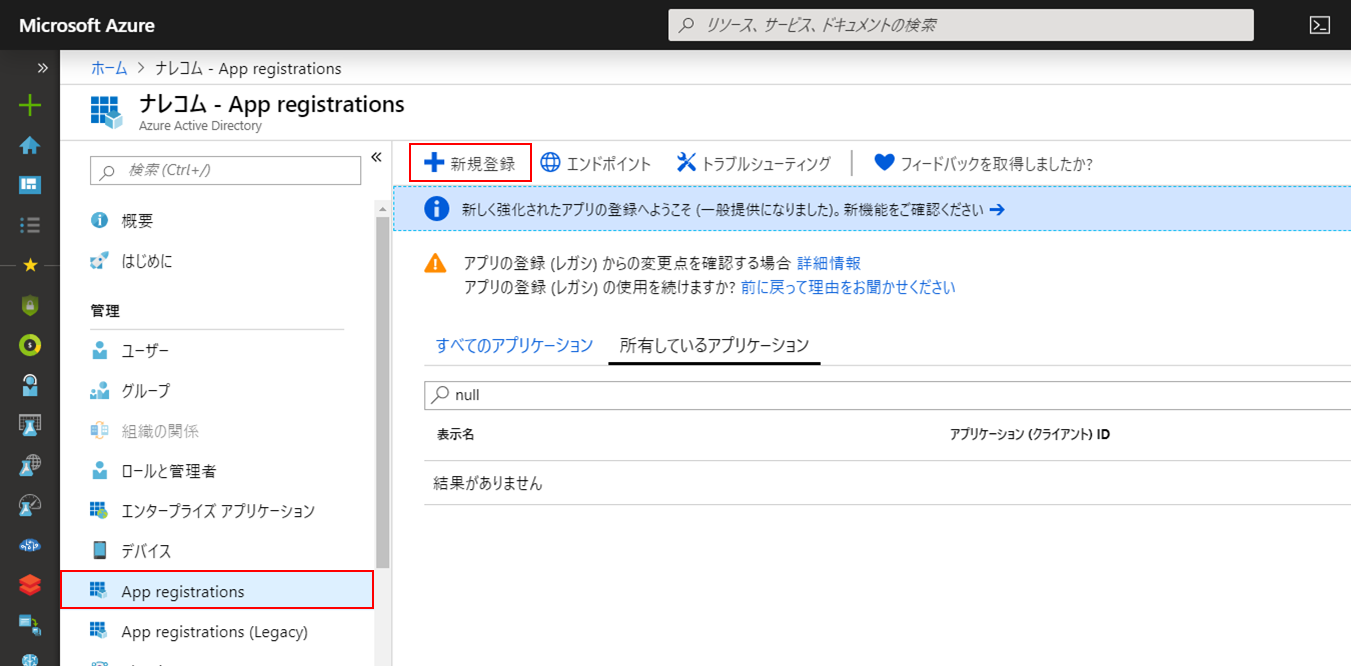
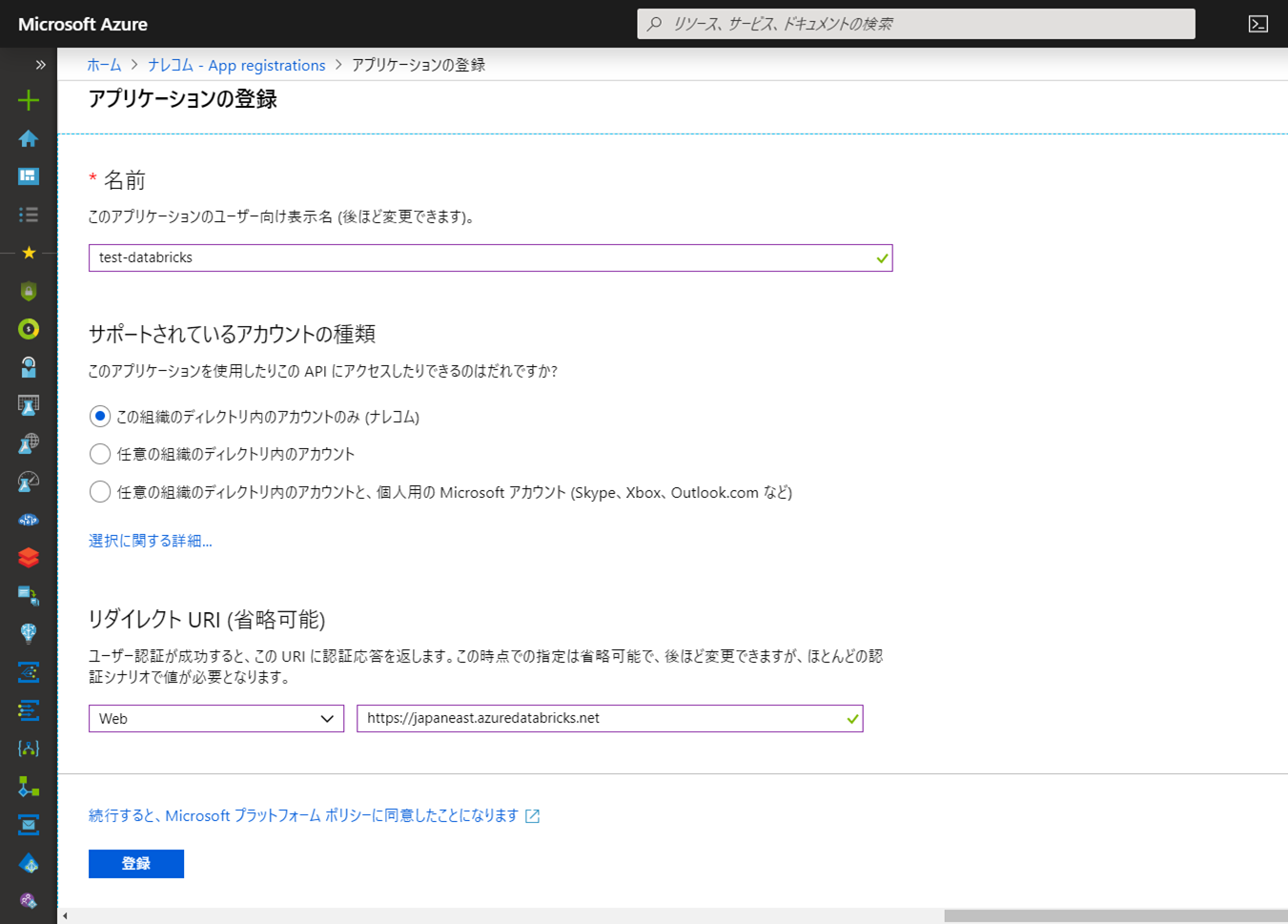
「名前」に任意の名称を入力し、「リダイレクトURI」にAzure DatabricksのURL( https://japaneast.azuredatabricks.net/ )を入力して「登録」をクリックします。
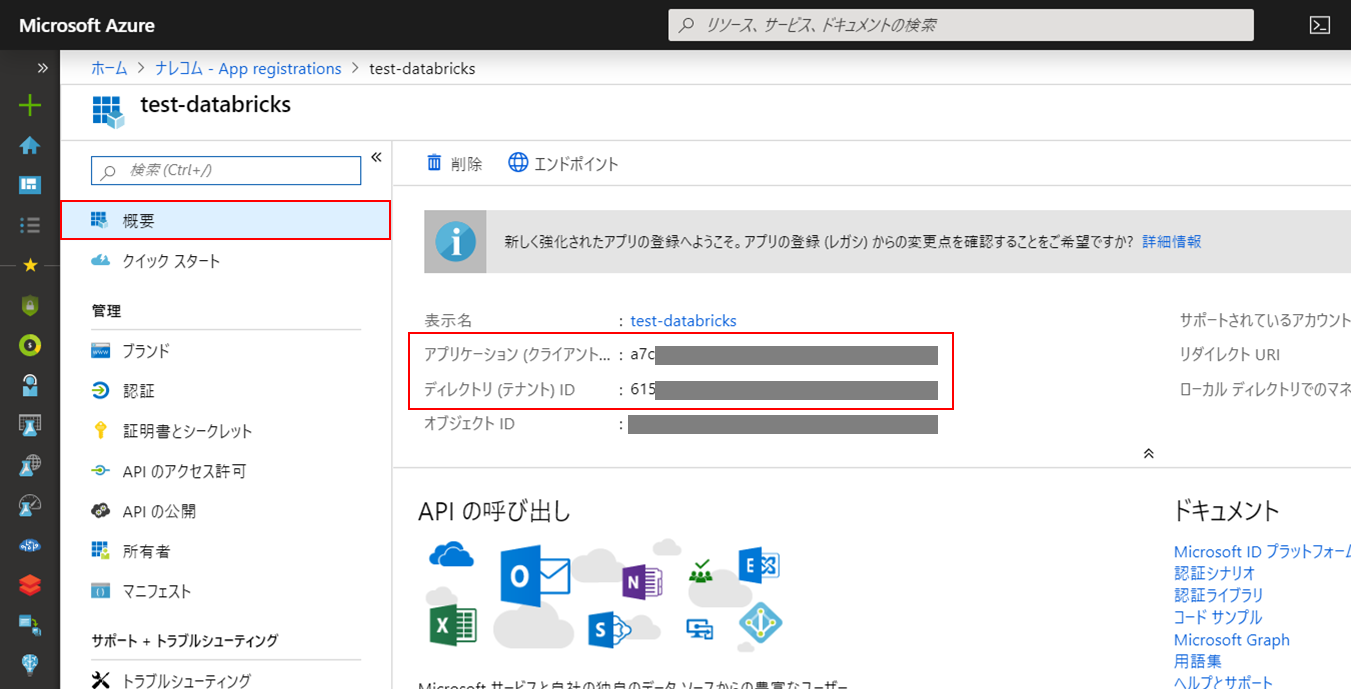
登録後に表示される「アプリケーション(クライアント)ID」と「ディレクトリ(テナント)ID」はマウント時のパラメータとして必要になるため、コピーして控えておきます。
続いて、サービスプリンシパルのクライアントシークレットを作成します。
メニューの「証明書とシークレット」を開き、「+新しいクライアントシークレット」をクリックします。
「説明」と「有効期限」を設定して「追加」をクリックします。
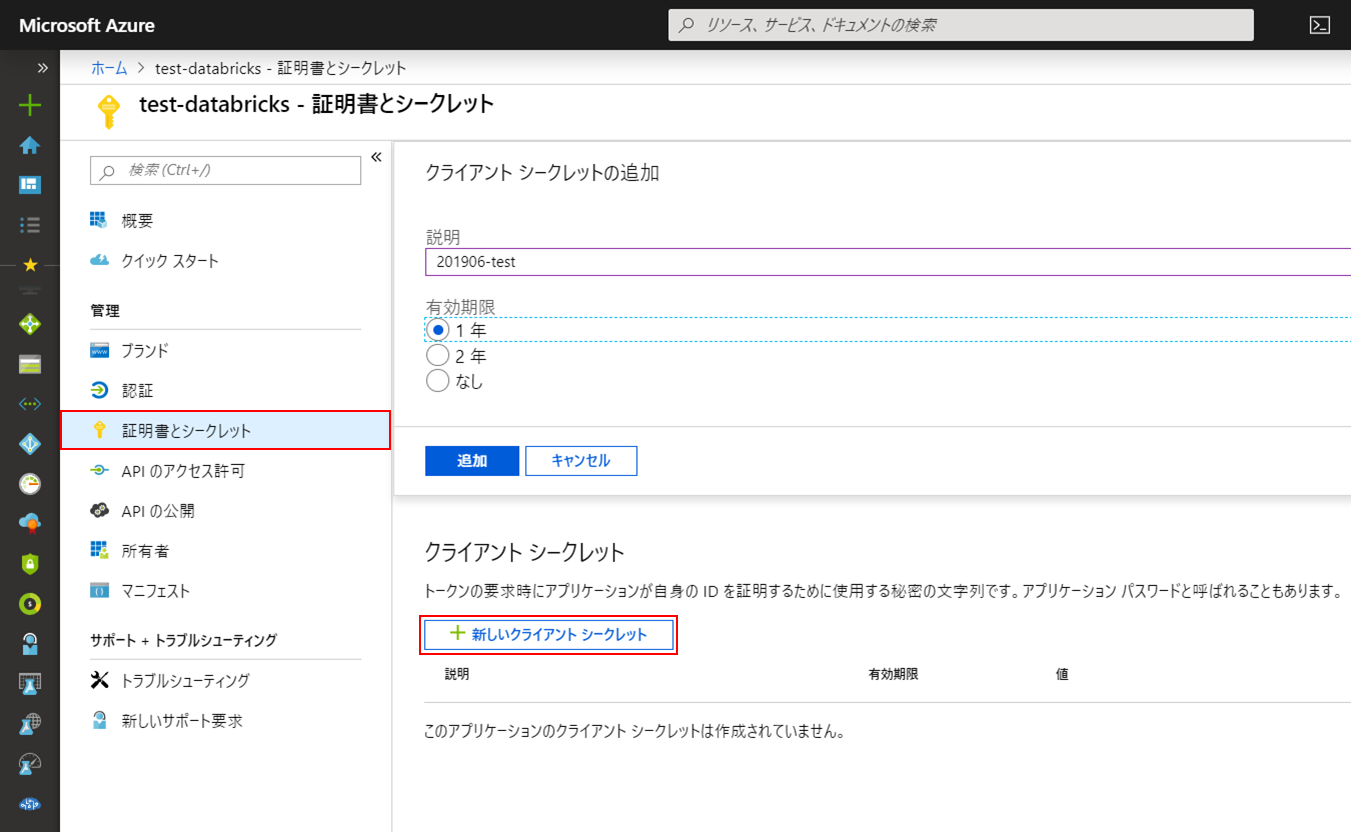
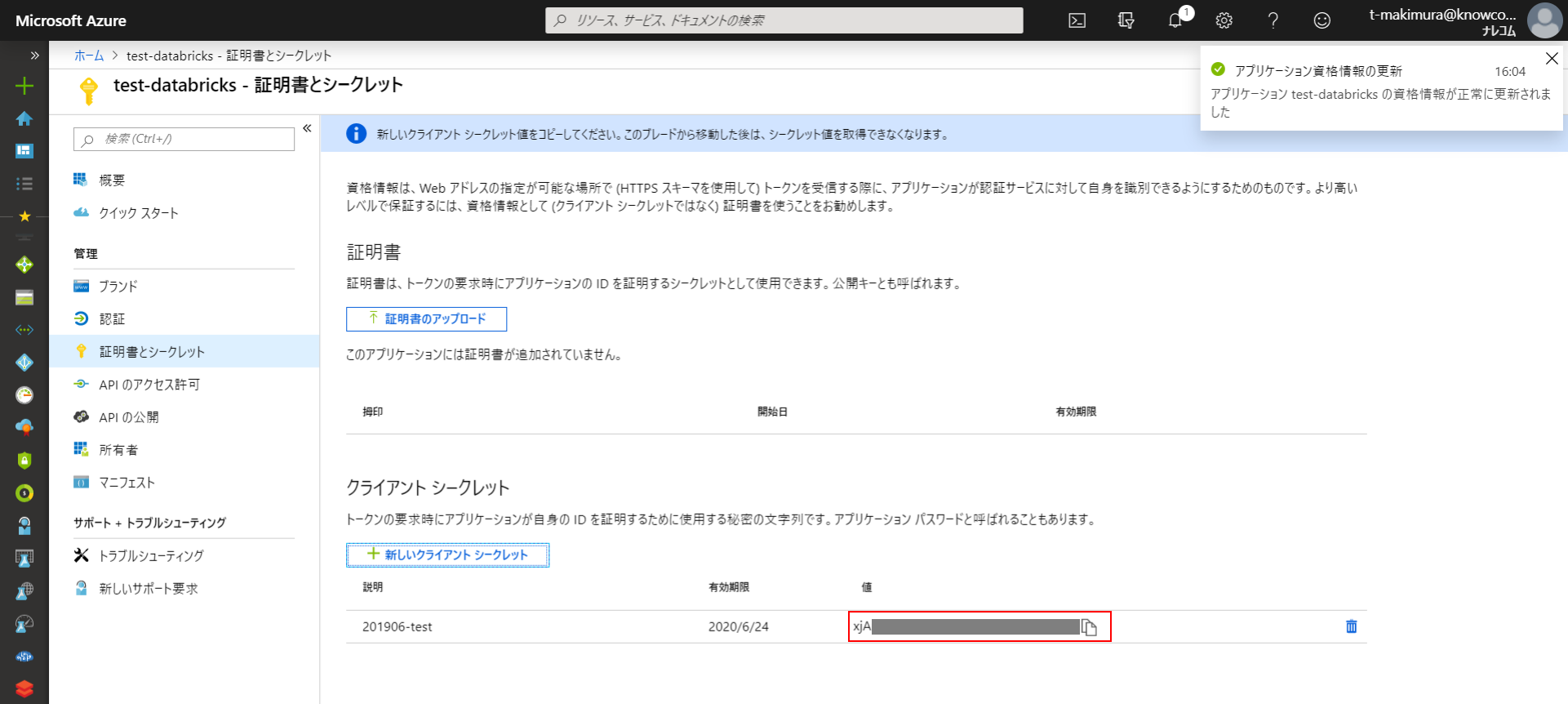
作成されるとクライアントシークレットの文字列が表示されます。この文字列は作成後最初の1回しか表示されないため、コピーして控えておきます。
クライアントシークレットもマウント時の必要パラメータとなります。
(秘密情報の管理にAzure Key Vaultを使用する場合はクライアントシークレットをキーコンテナーに登録しておきます。)
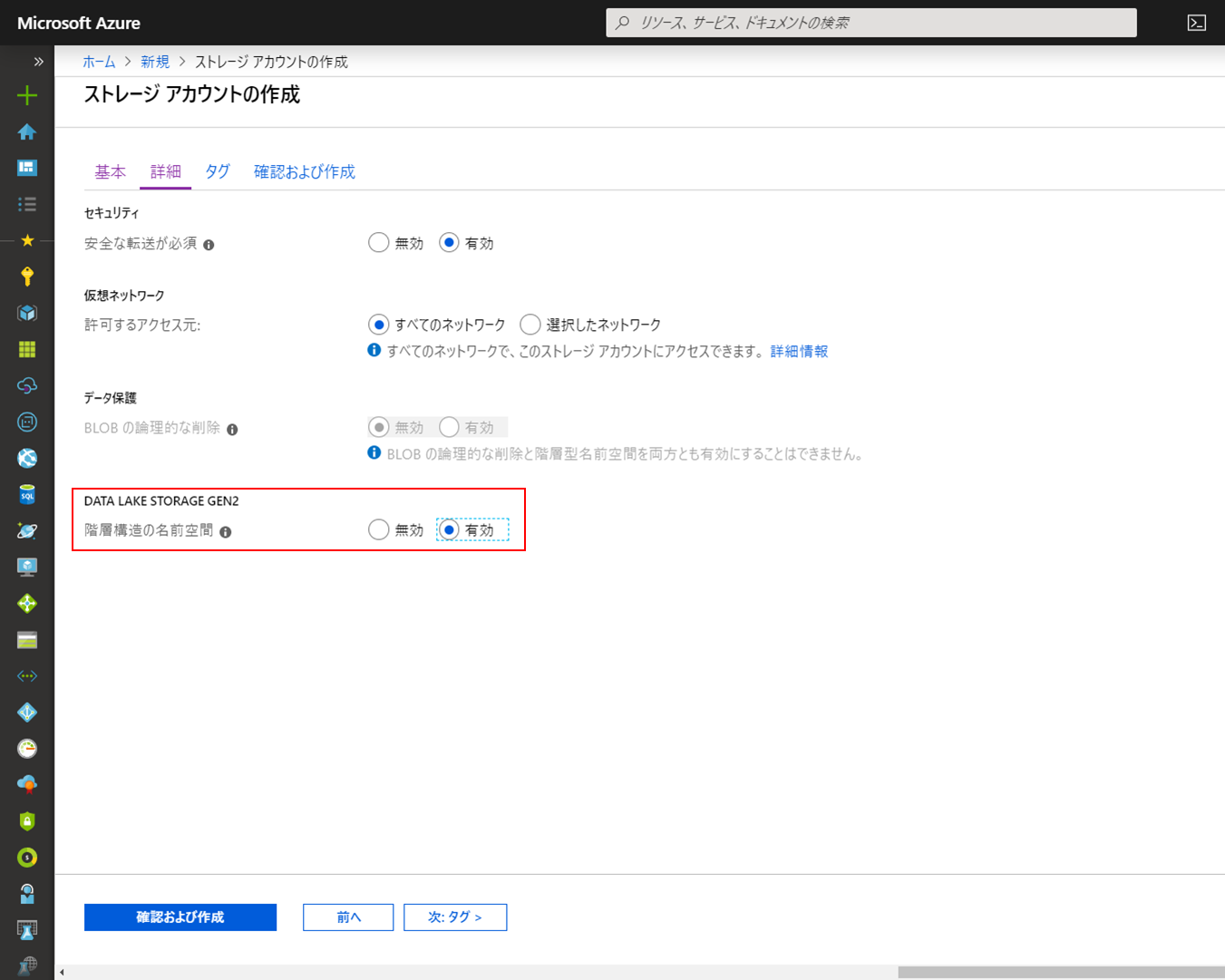
Azure Data Lake Storage Gen2 (ADLS Gen2)とファイルシステムの作成
ADLS Gen2はAzure Storageのオプション扱いであるため、作成はストレージアカウントの作成の手順に準じます。
作成の変更点は、作成の「詳細」設定で「階層構造の名前空間」を有効化することです。
(ADLS Gen2は後から有効化できないため、使用する場合は新規でストレージアカウント作成が必要です。)
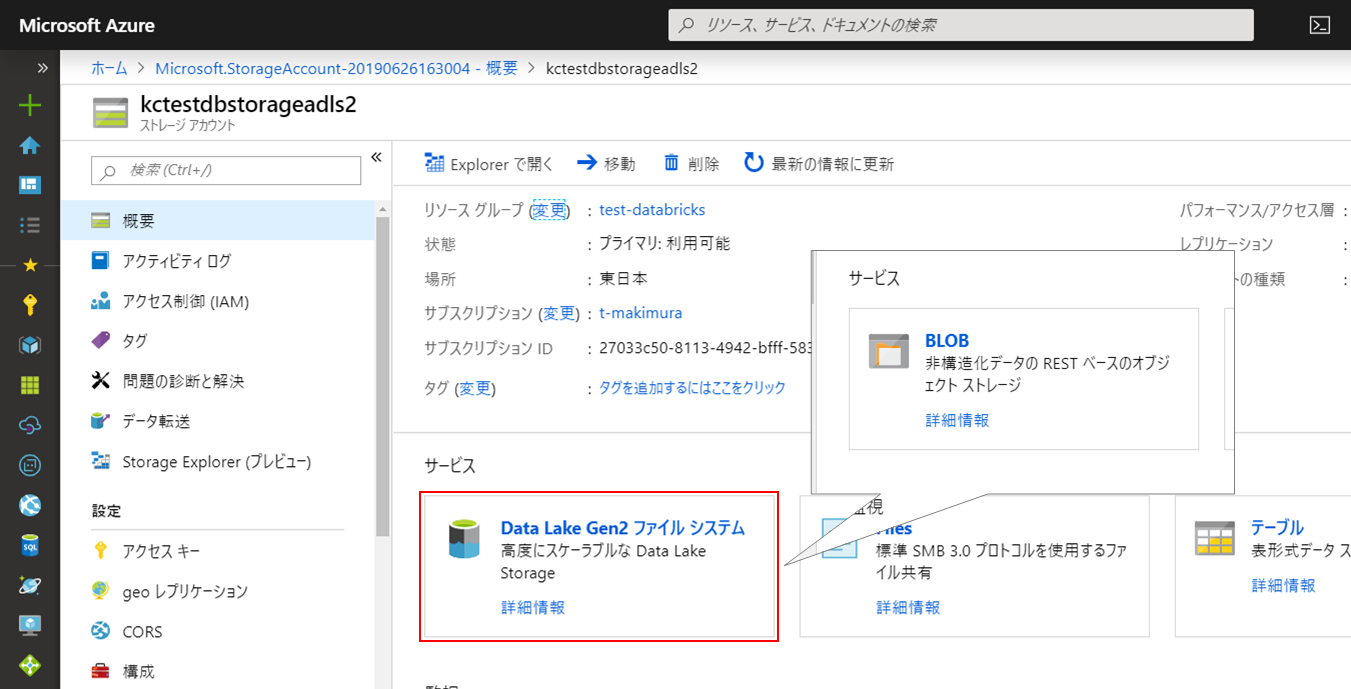
作成が完了したら、作成したリソースを開きます。
「階層構造の名前空間」を有効化していると、概要の「サービス」が「Blob」から「Data Lake Gen2ファイルシステム」に変化しています。
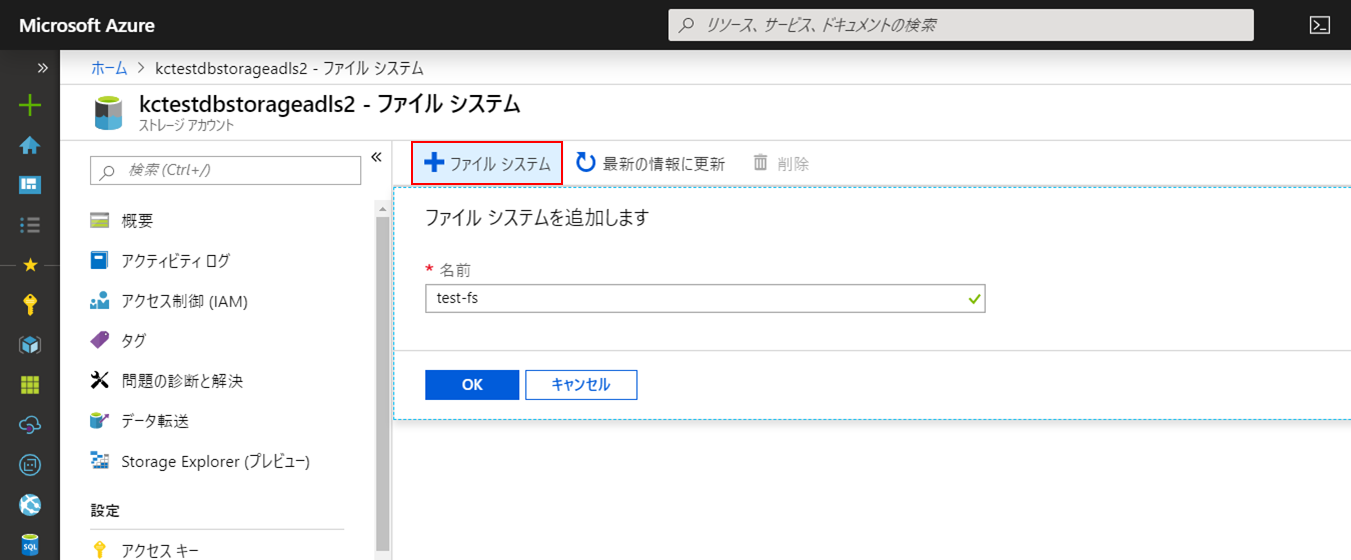
ファイルシステムの作成
ADLS Gen2にファイルシステムを作成します。
「Data Lake Gen2ファイルシステム」をクリックしてADLS Gen2メニューを開きます。
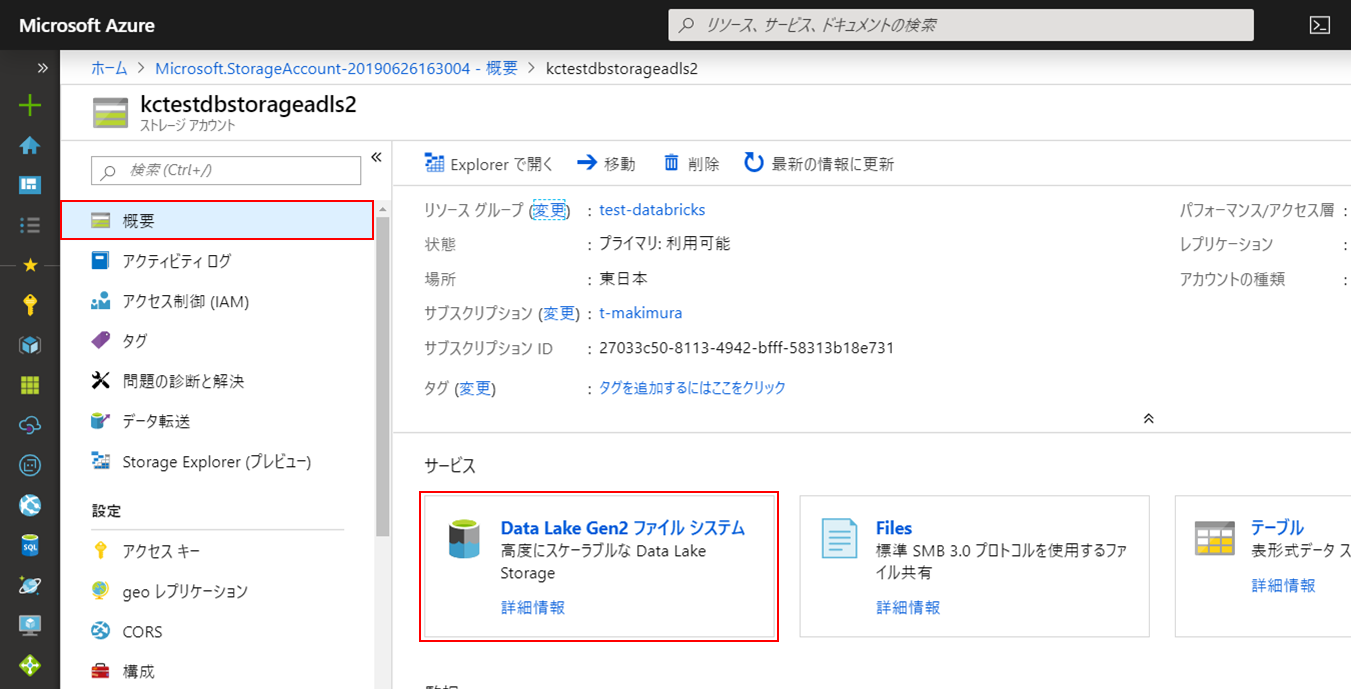
「+ファイルシステム」をクリックし、「名前」に任意の名称を入力して作成を行います。
ADLS Gen2へのアクセス権限の付与
サービスプリンシパルに対するADLS Gen2のアクセス権限の付与します。
作成したファイルシステムを開きます。
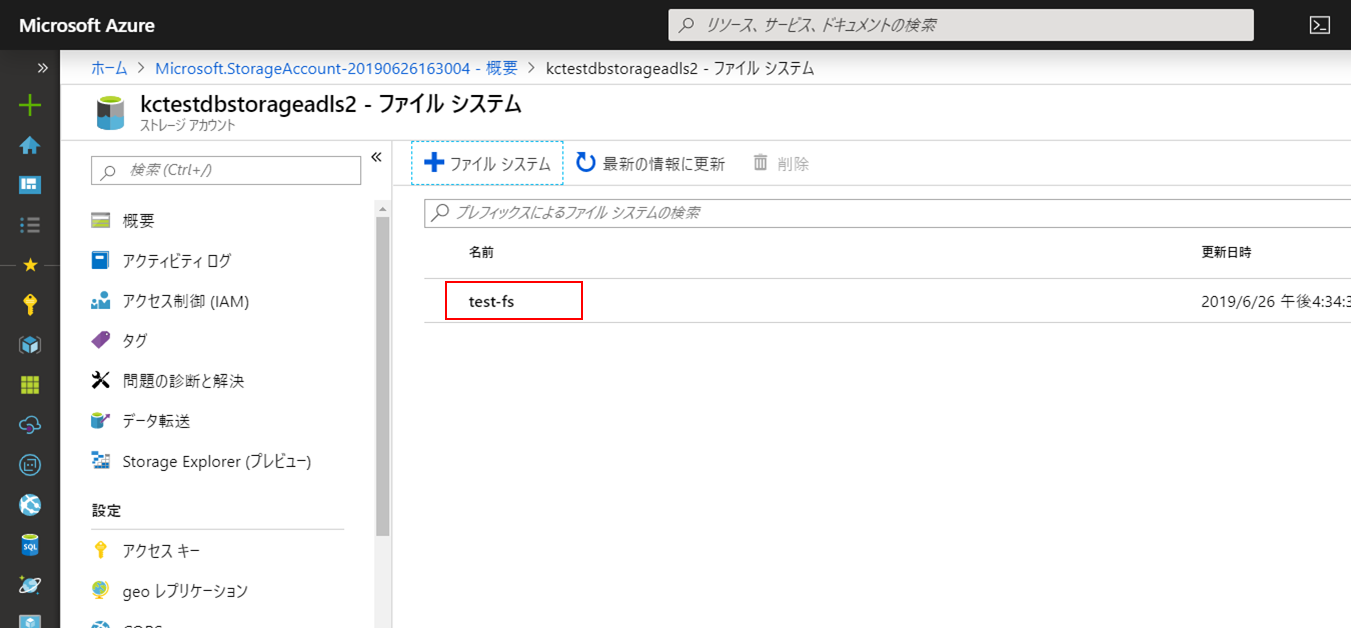
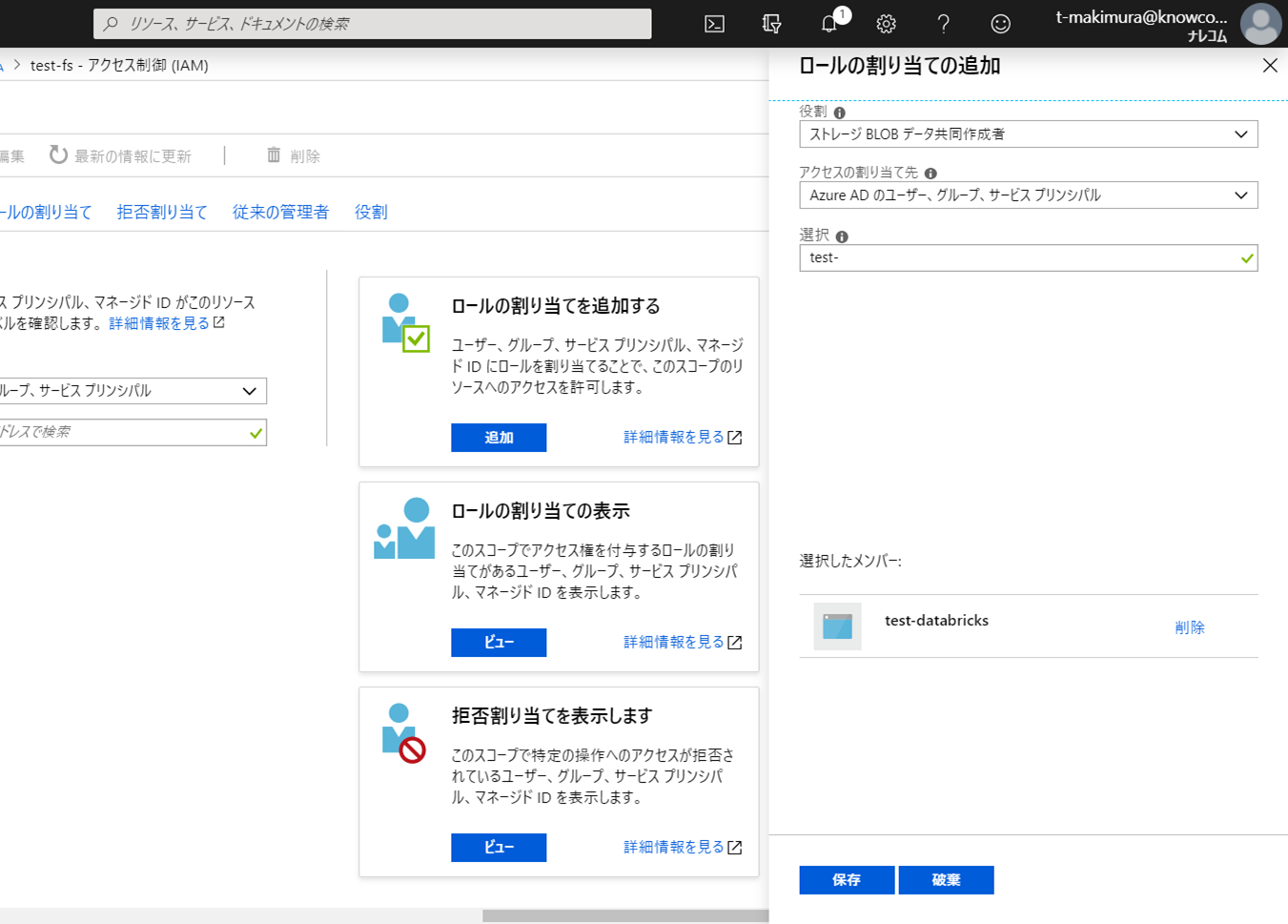
メニューから「アクセス制御(IAM)」を開いて「ロールの割り当てを追加する」をクリックします。
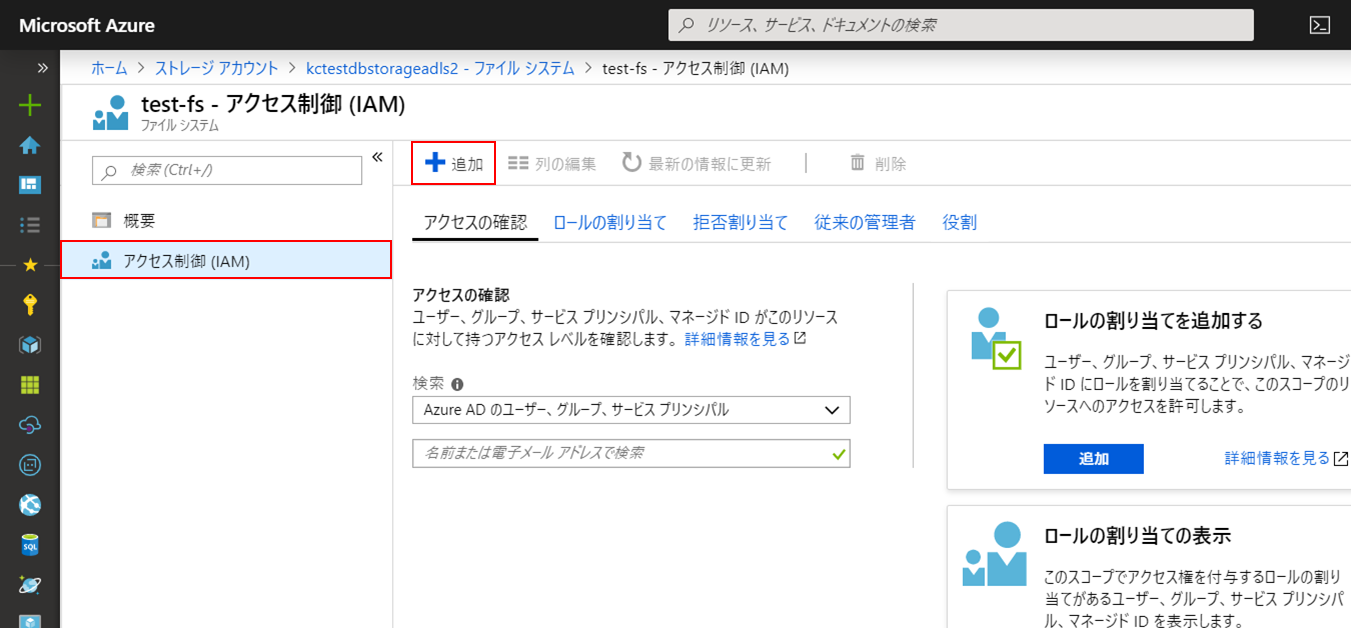
「役割」を「ストレージBLOBデータ共同作成者」に変更し、「選択」で作成したサービスプリンシパルを選択して「保存」をクリックします。
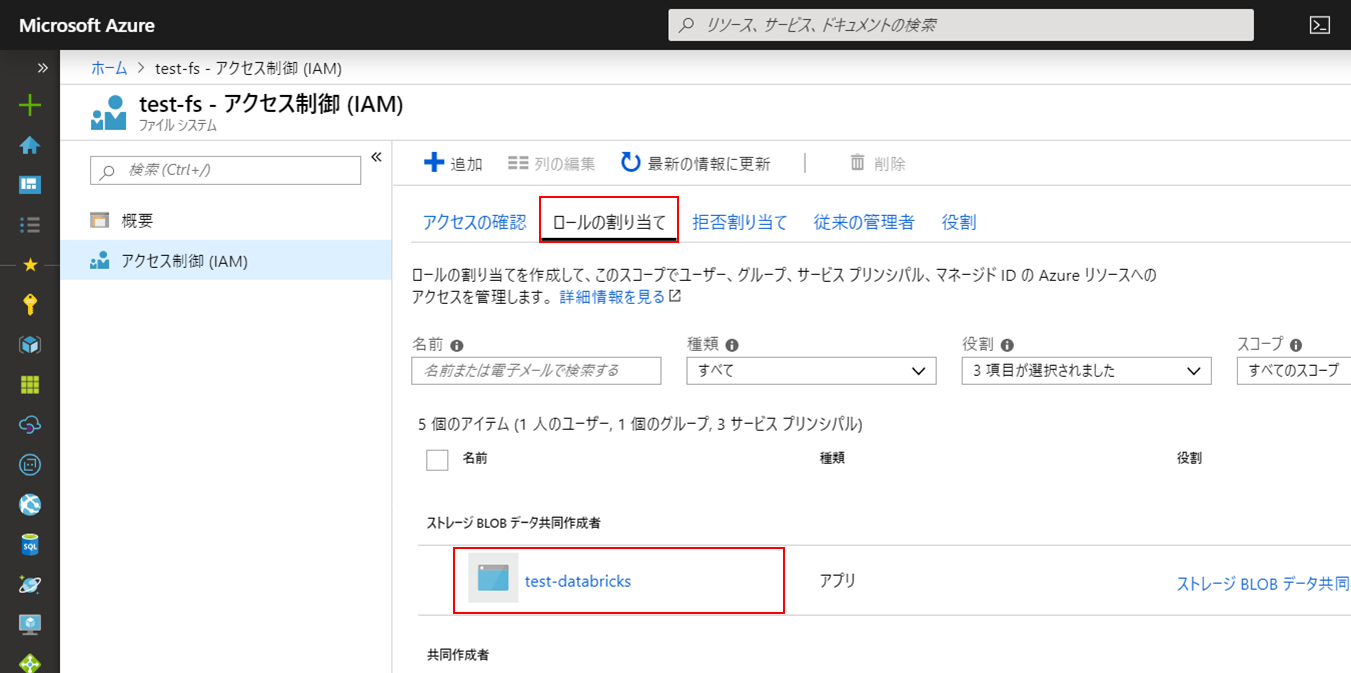
「ロールの割り当て」タブをクリックするとサービスプリンシパルに割り当てられた権限が確認できます。
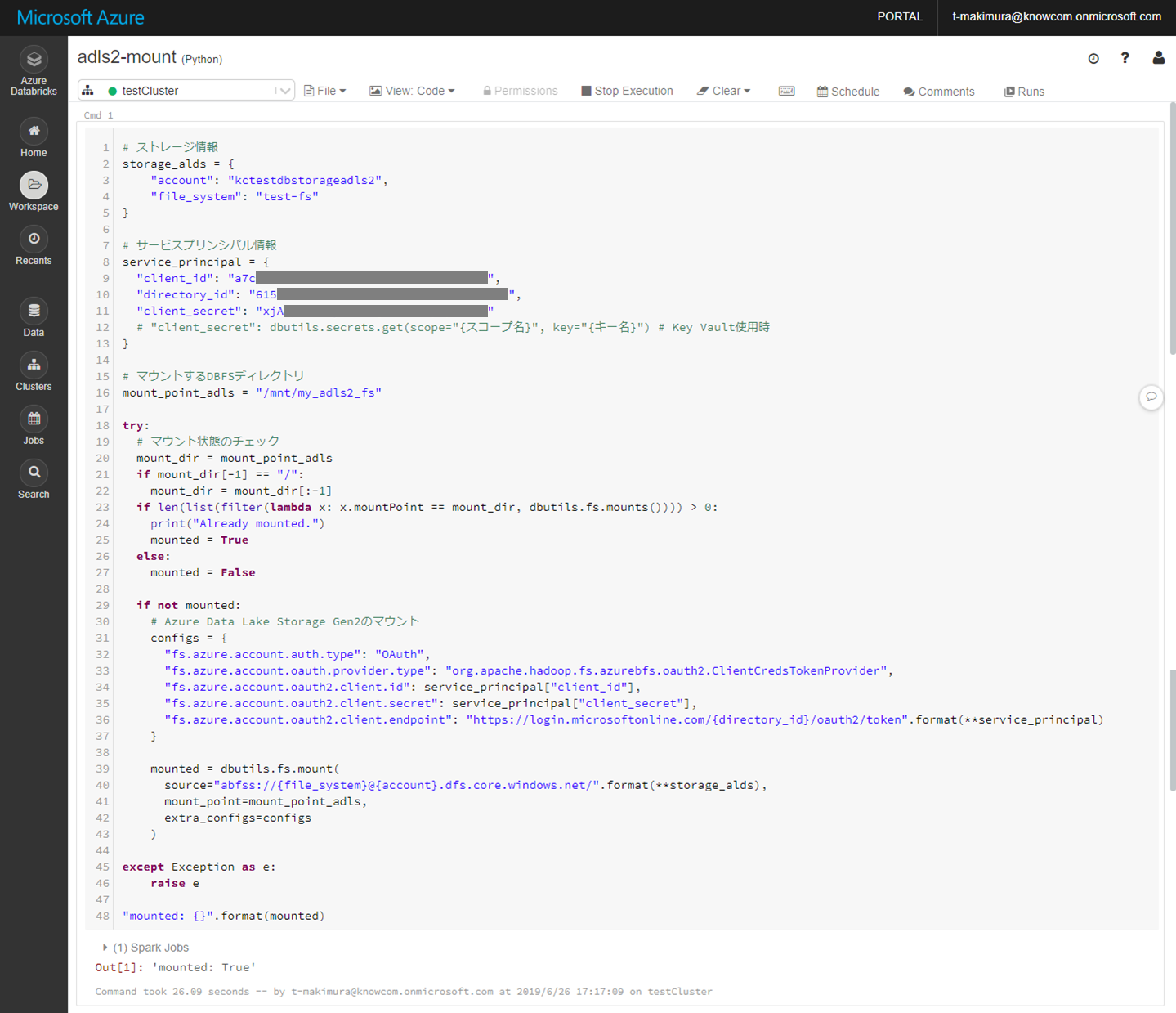
ADLS Gen2をDBFSにマウント
DBFSにADLS Gen2をマウントするには、下記のスクリプトを使用します。
(ストレージ、サービスプリンシパル情報、マウント先DBFSディレクトリは作成したリソースに合わせて変更してください。)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
Cmd 1 # ストレージ情報 storage_alds = { "account": "{ストレージアカウント名}", "file_system": "{ファイルシステム名}" } # サービスプリンシパル情報 service_principal = { "client_id": "{アプリケーション(クライアント)ID}", "directory_id": "{ディレクトリ(テナント)ID}", "client_secret": "{クライアントシークレット}" # "client_secret": dbutils.secrets.get(scope="{スコープ名}", key="{キー名}") # Key Vault使用時 } # マウントするDBFSディレクトリ mount_point_adls = "/mnt/{マウント先ディレクトリ}" try: # マウント状態のチェック mount_dir = mount_point_adls if mount_dir[-1] == "/": mount_dir = mount_dir[:-1] if len(list(filter(lambda x: x.mountPoint == mount_dir, dbutils.fs.mounts()))) > 0: print("Already mounted.") mounted = True else: mounted = False if not mounted: # Azure Data Lake Storage Gen2のマウント configs = { "fs.azure.account.auth.type": "OAuth", "fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", "fs.azure.account.oauth2.client.id": service_principal["client_id"], "fs.azure.account.oauth2.client.secret": service_principal["client_secret"], "fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/{directory_id}/oauth2/token".format(**service_principal) } mounted = dbutils.fs.mount( source="abfss://{file_system}@{account}.dfs.core.windows.net/".format(**storage_alds), mount_point=mount_point_adls, extra_configs=configs ) except Exception as e: raise e "mounted: {}".format(mounted) |
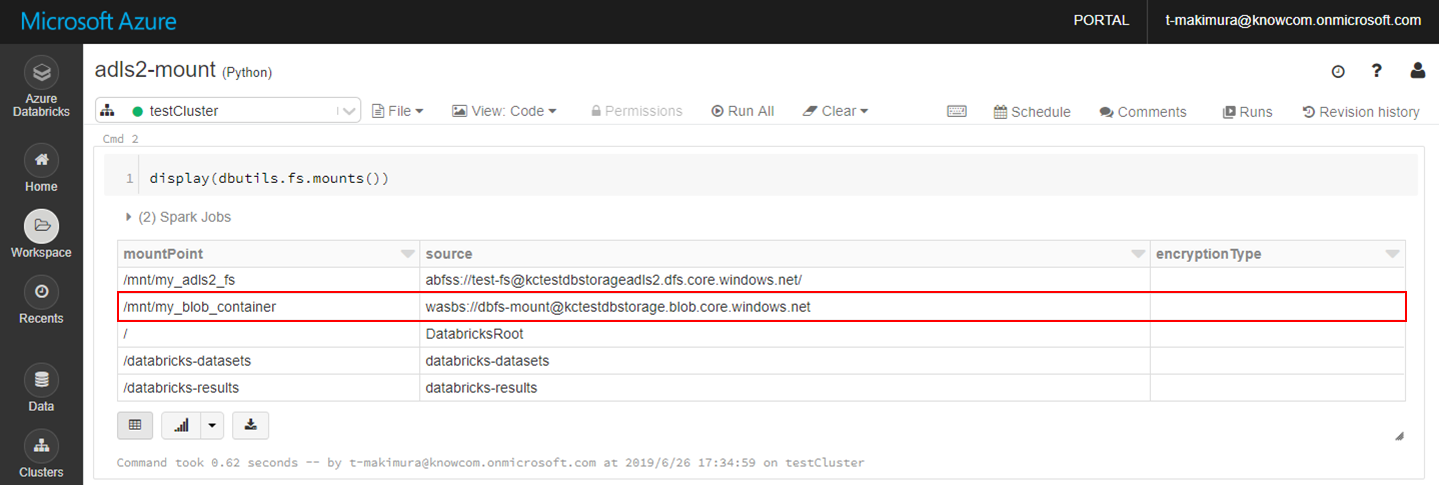
参考
3分でわかるAzureでのService Principal
ナレコムAzureレシピ – Azure Databricksを使ってみた
Databricks Documentation – Data Sources – Azure Data Lake Storage Gen2
チュートリアル:Spark を使用して Azure Databricks で Data Lake Storage Gen2 のデータにアクセスする
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
