はじめに
前回紹介した内容に沿った簡易集計と可視化を、Excelで行います。
流れ
3つのCSVデータを組み合わせて、中間テーブルを作成します。
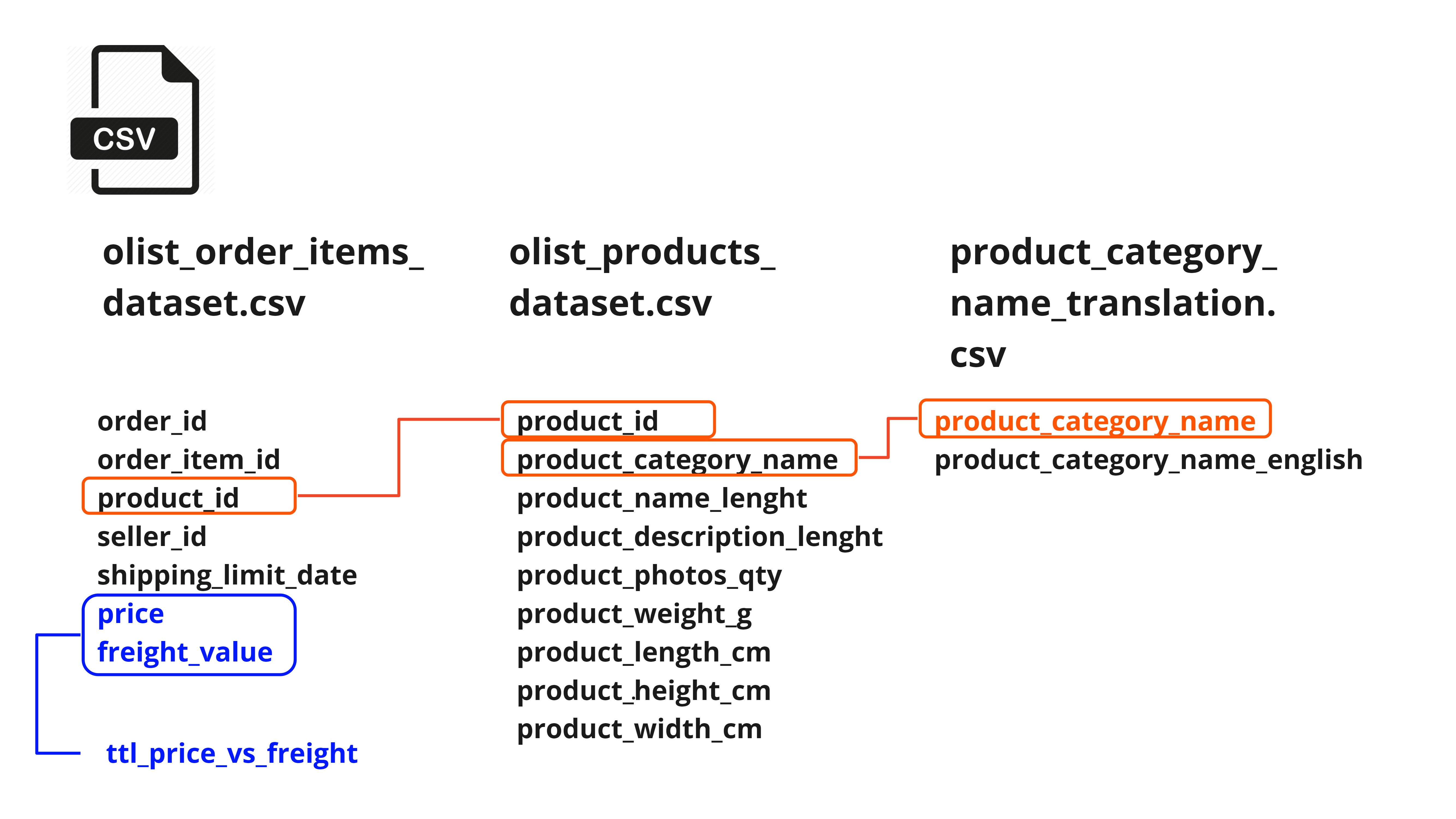
青色は、 各々のレコードに対して feight / (price + freight)で算出した、単価と送料の合計に占める送料の割合。オレンジは、キーとなる値を紐づけて取得した英語のカテゴリ名。
この中間テーブルを参照元にして、pivotテーブルとpivotグラフを作成します。
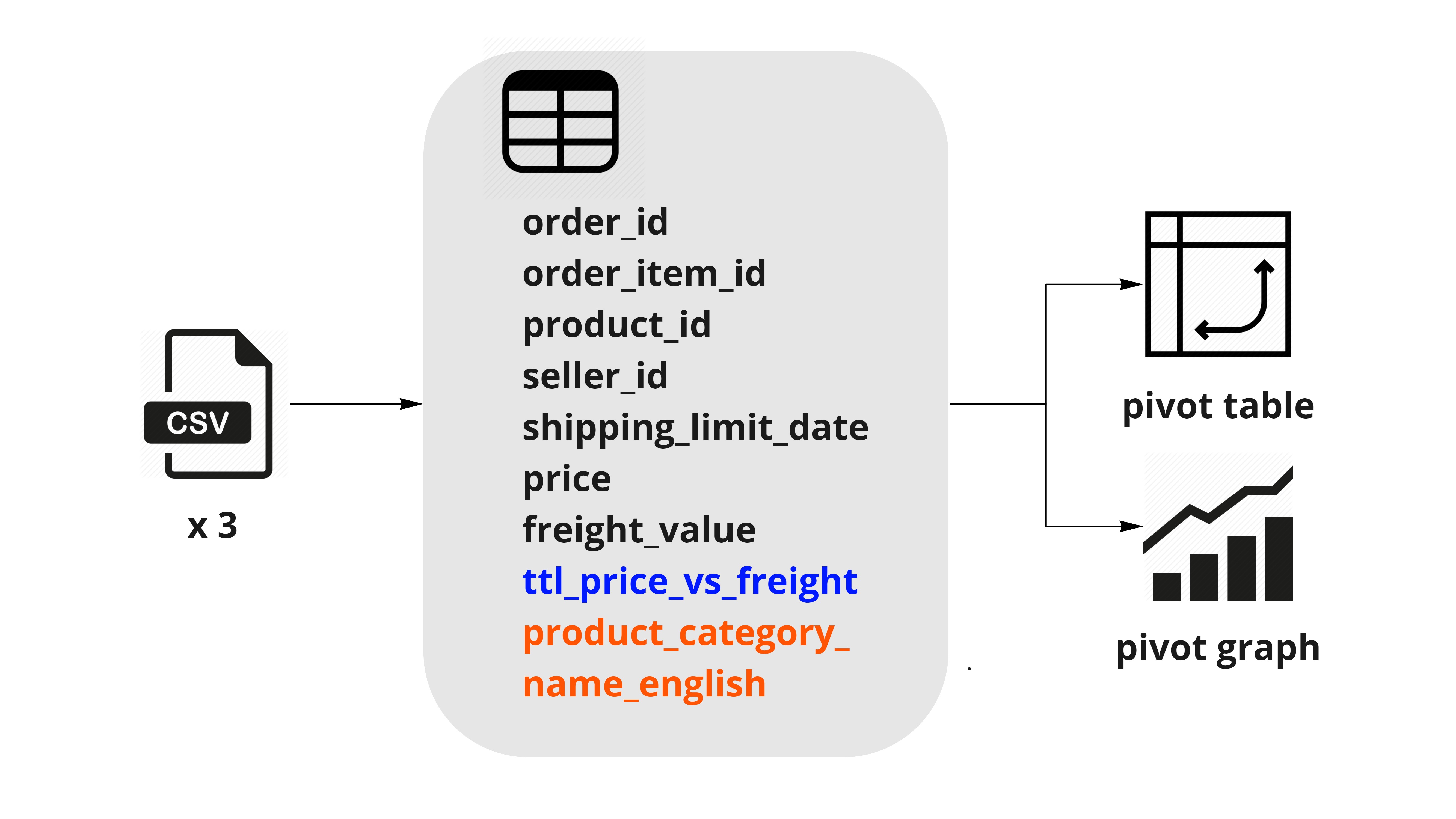
手順
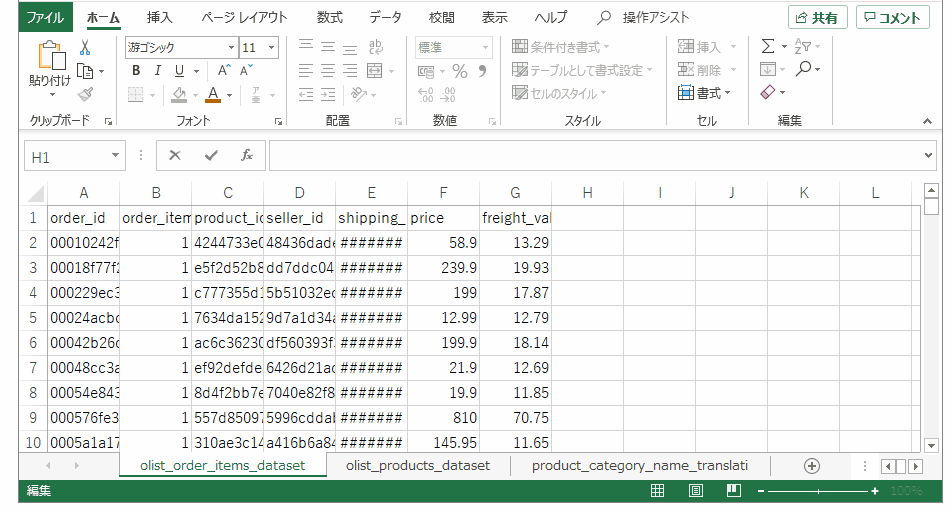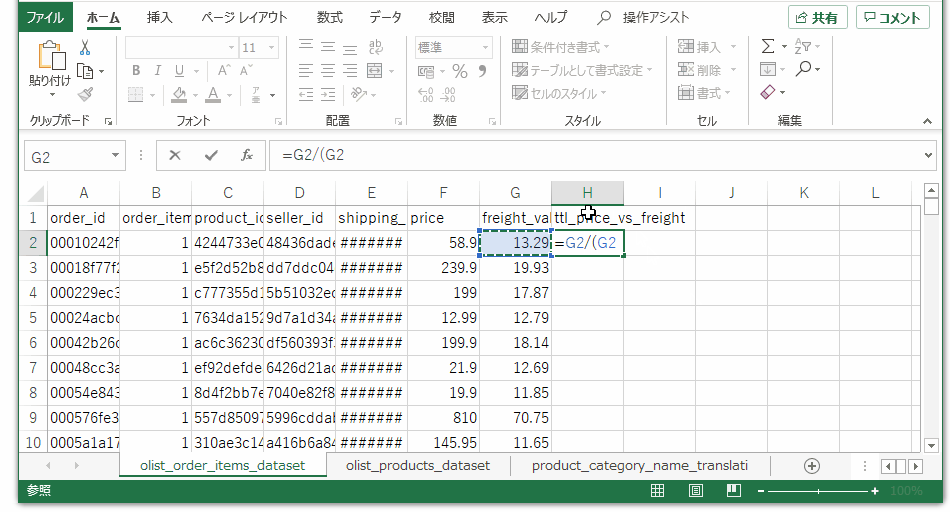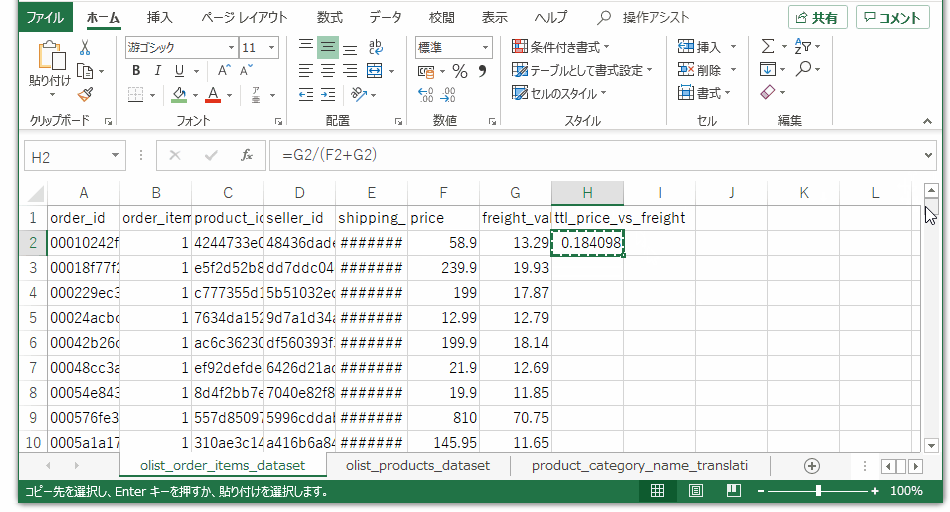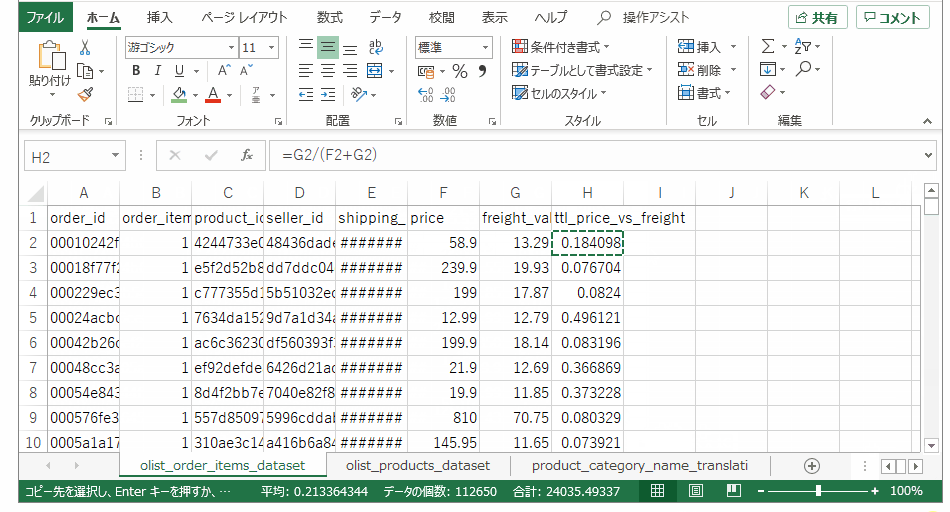
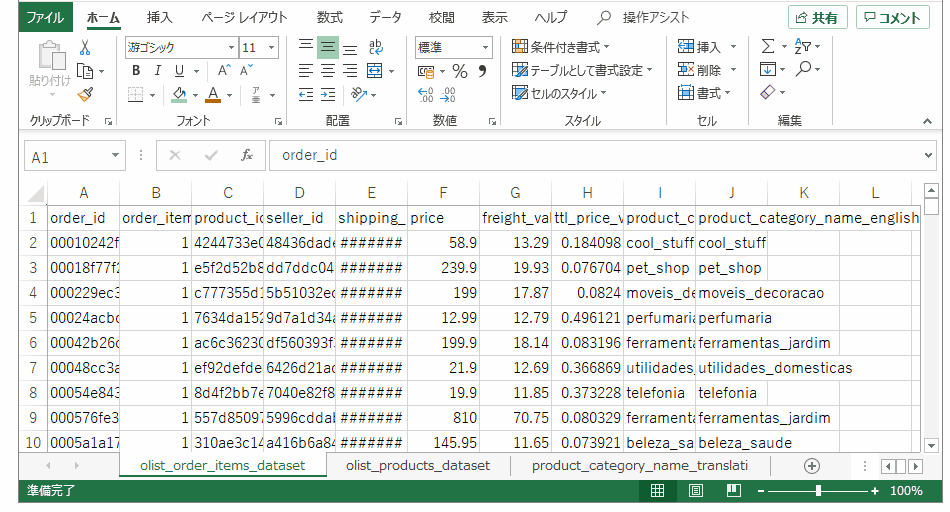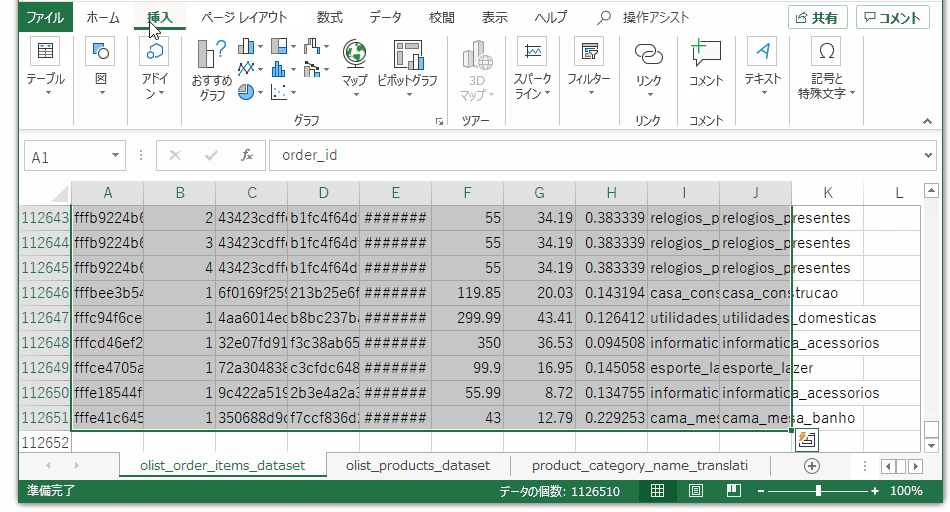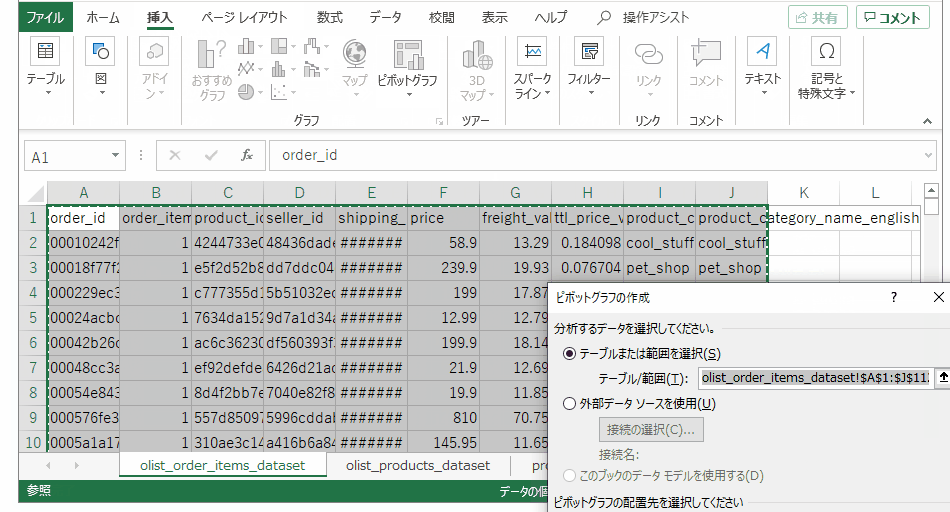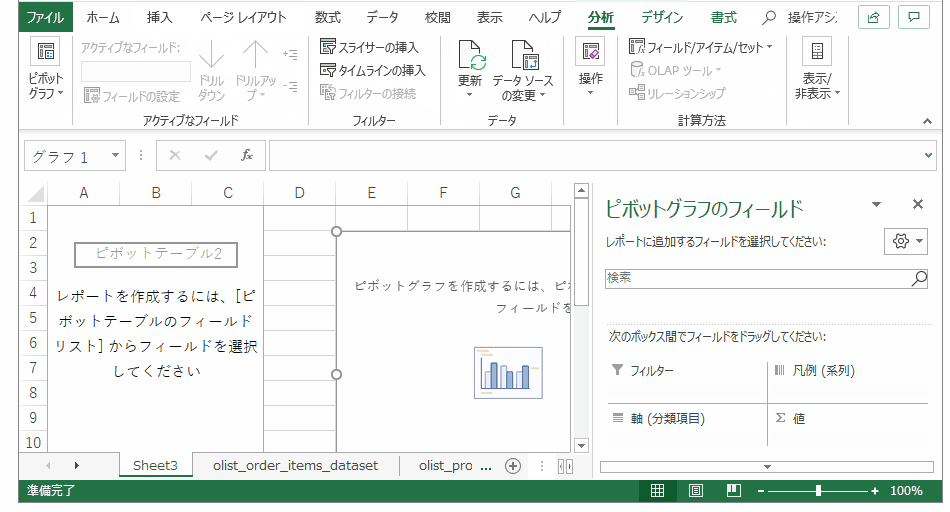
テーブルを跨いでしまうと後続の処理が遅くなってしまうので、まずは一つのファイルにCSVデータをまとめます。左から売上テーブル、製品テーブル、翻訳テーブルを配置。

注文テーブルの最右列に、送料の占める割合を計算する数式を入れます。一つのセルに数式を入れ、行末までコピペします。
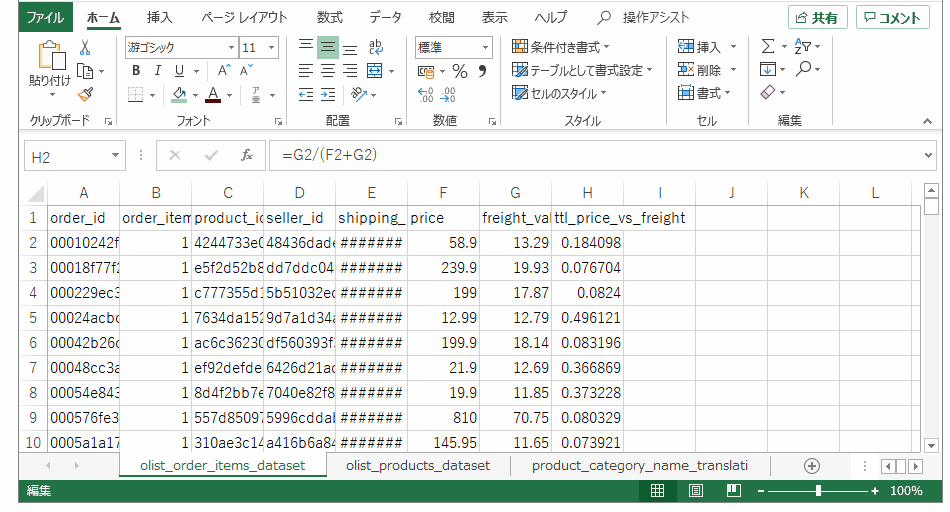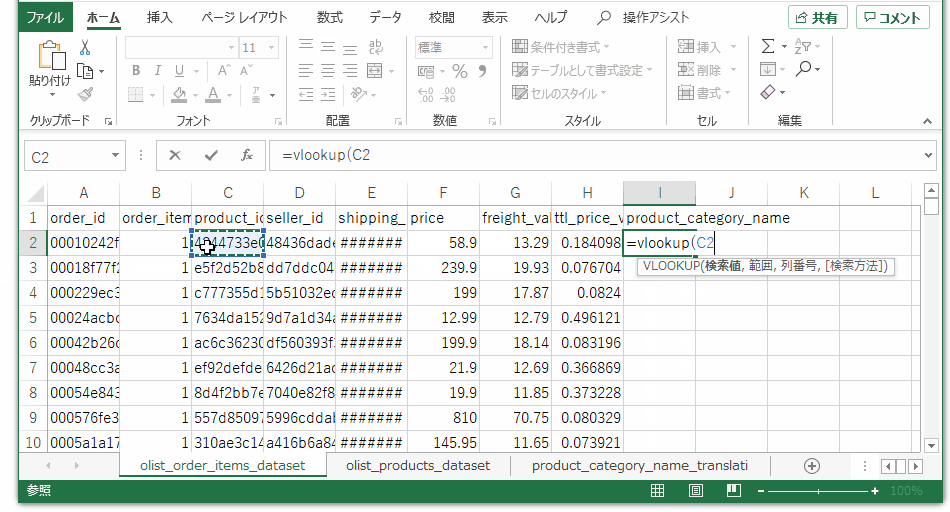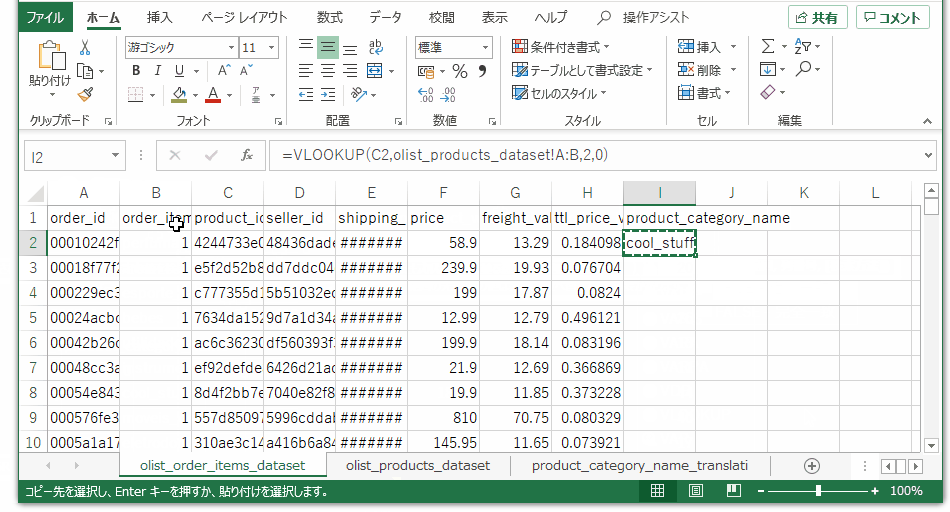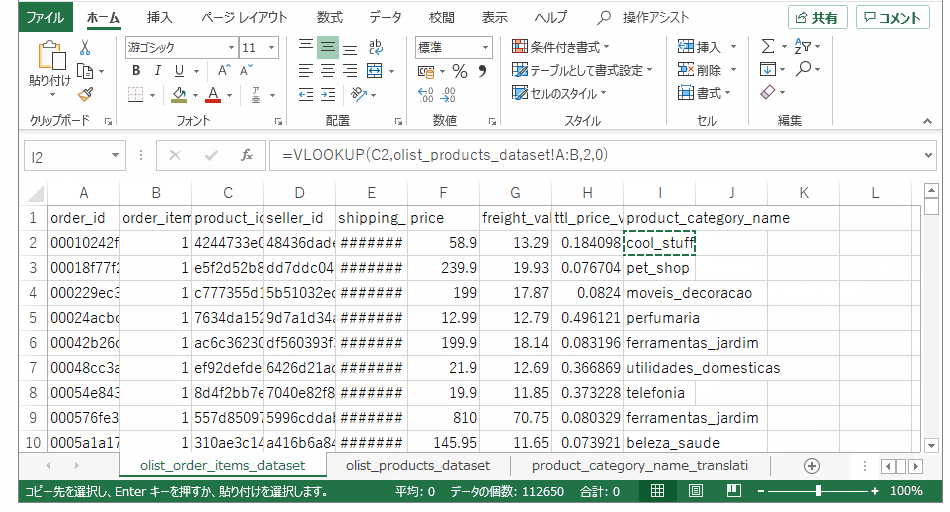
同じく注文テーブルで、product_idをキーにして、製品カテゴリ(ポルトガル語)データを引っ張ってきます。皆さんおなじみvlookupです。
次は製品カテゴリ(ポルトガル語)をキーにして、製品カテゴリ(英語)を引っ張ってきます。
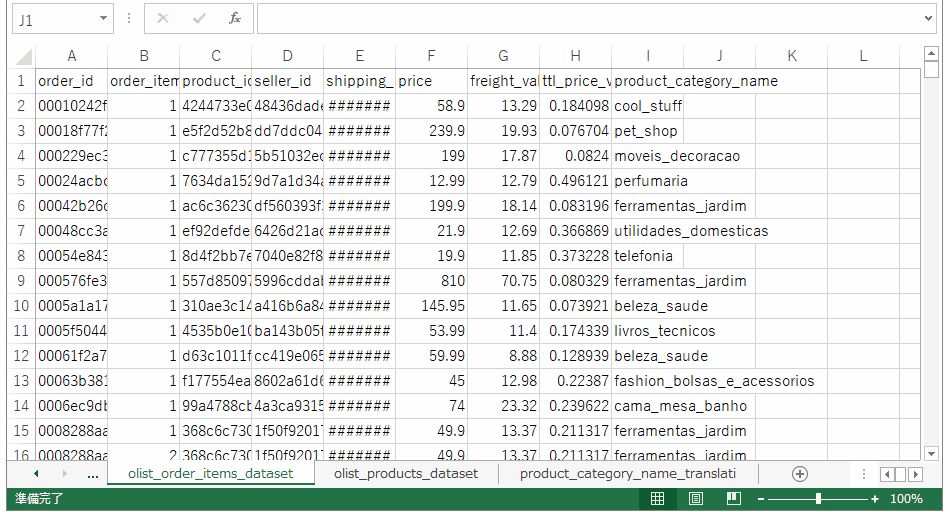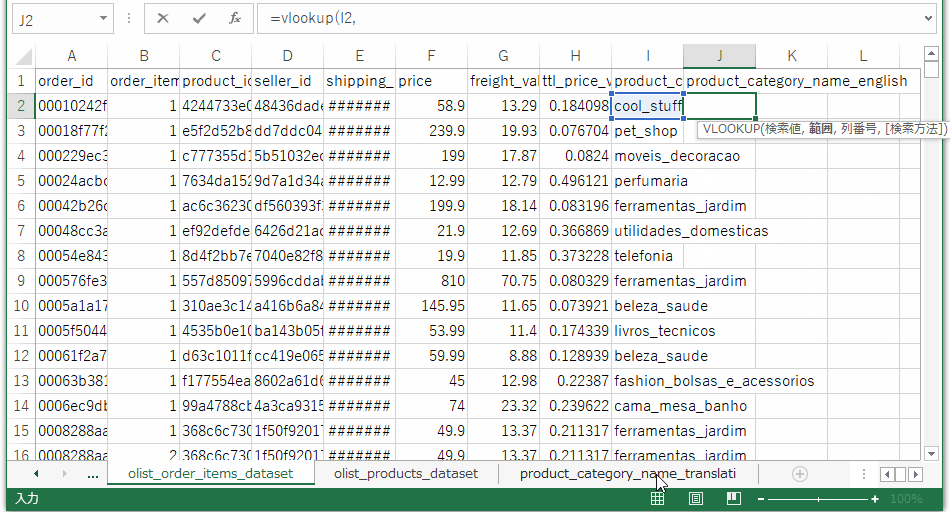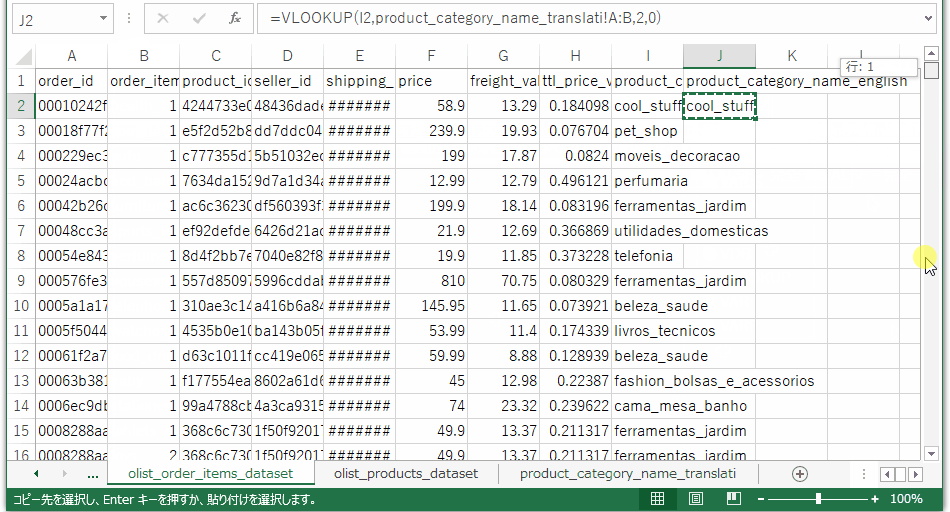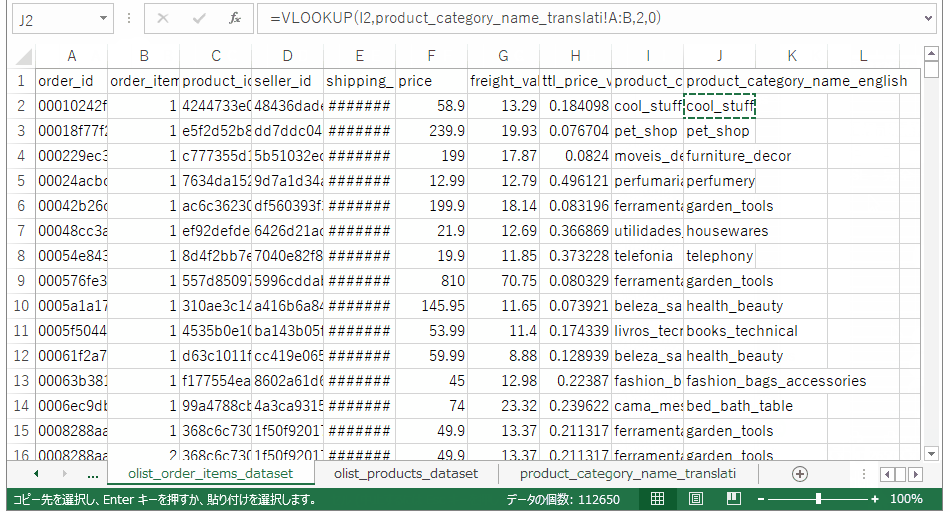
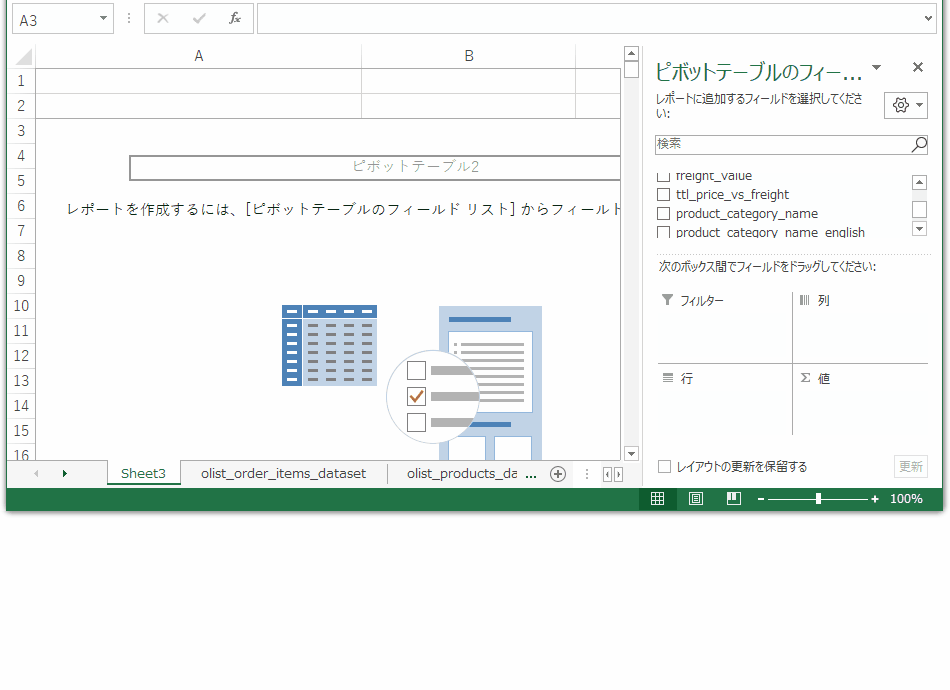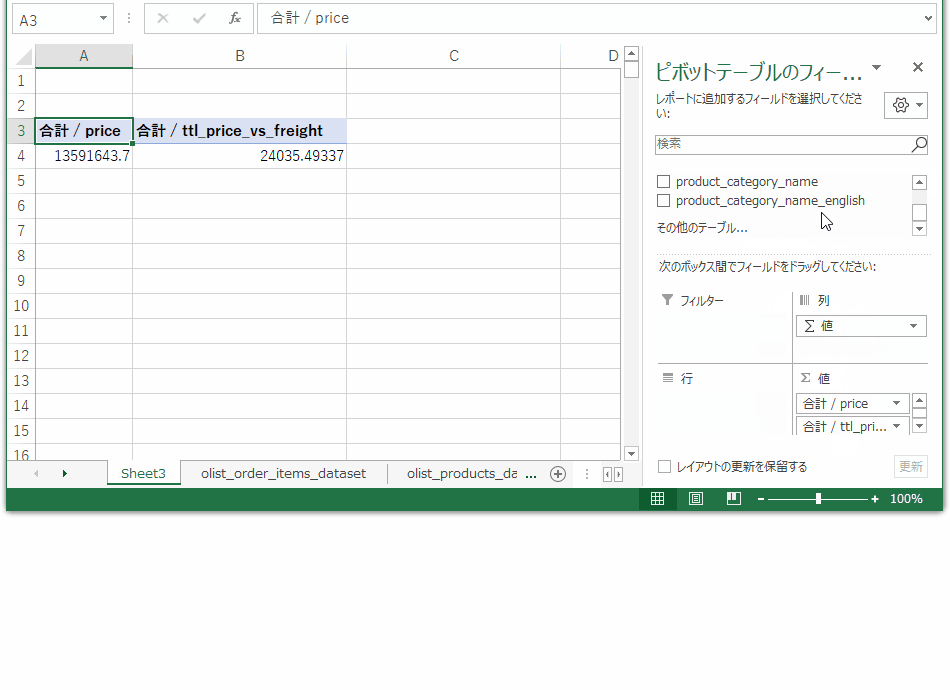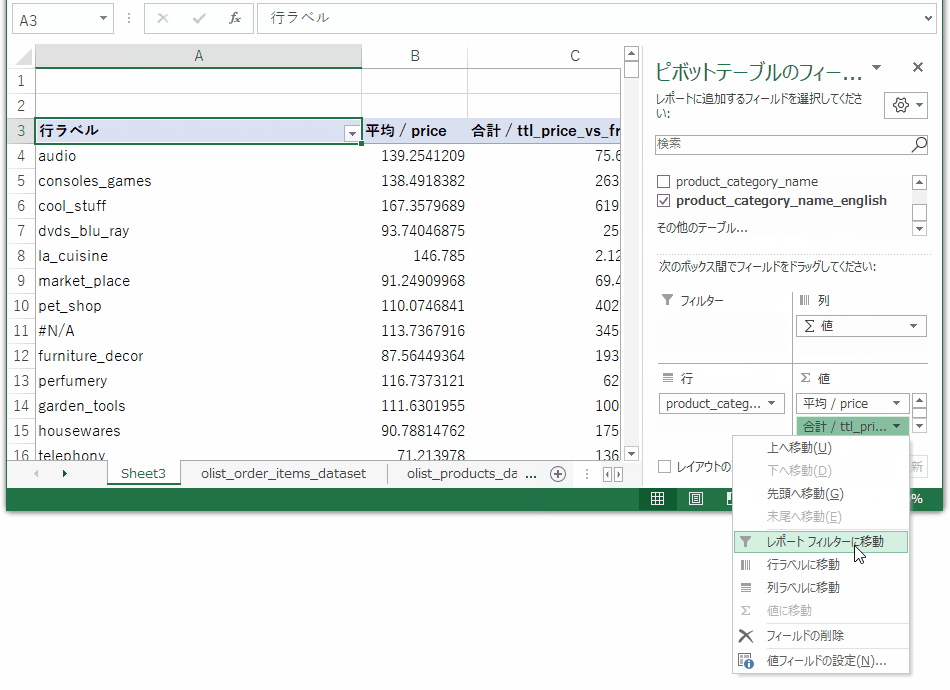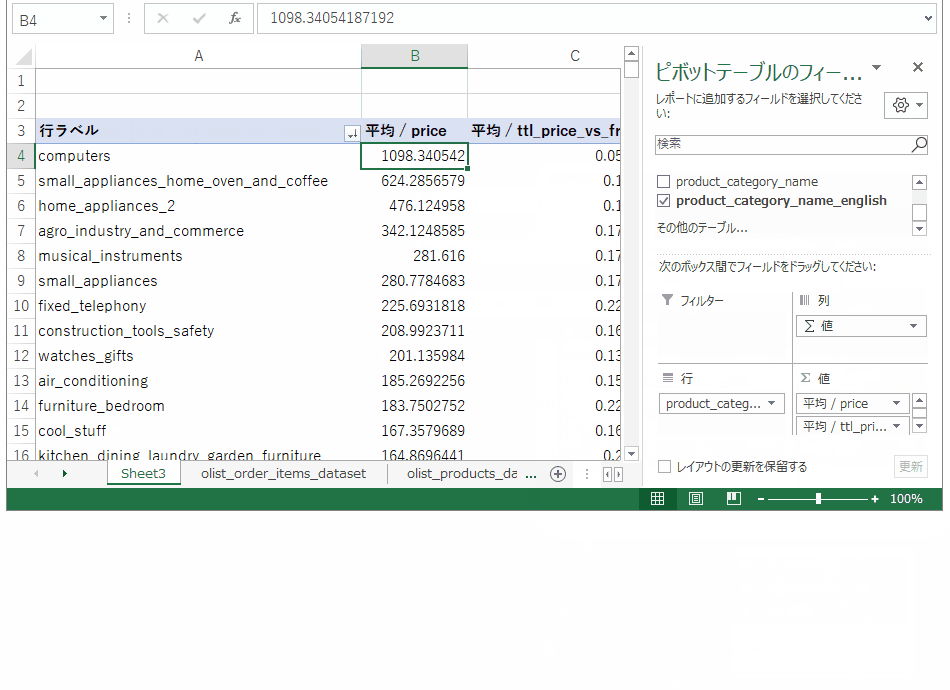
これでひとまず使おうと思っている情報は一つのテーブルに集約できました。売上ボリュームの大きいカテゴリを出すために、注文テーブルのセル範囲を選択して、pivotグラフ、pivotテーブルを作成します。
グラフの要素を選びます。フィールドリストの値に単価、行にカテゴリを持っていき、テーブルを単価の合計が大きい順にソートします。
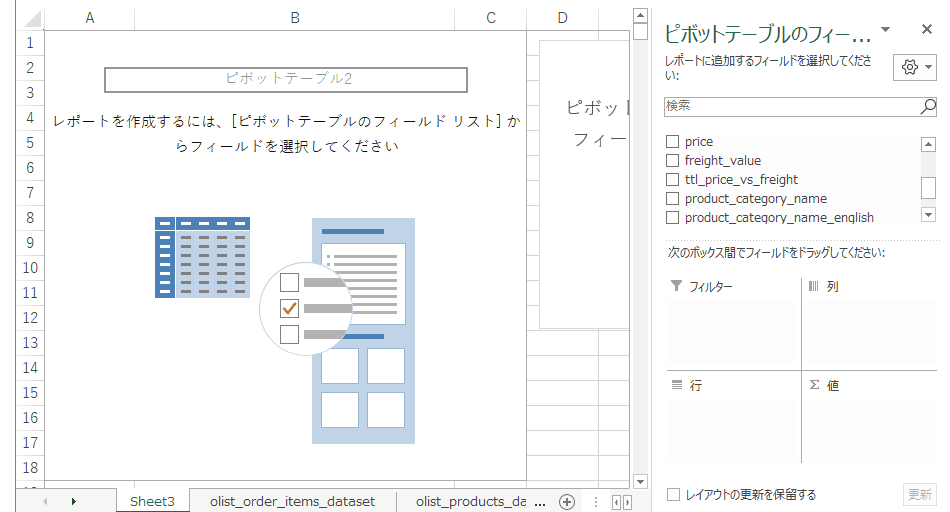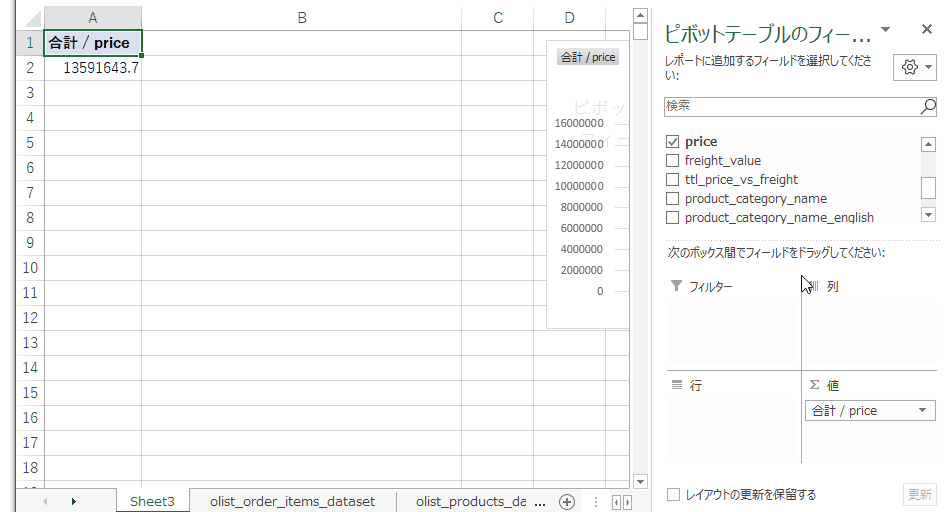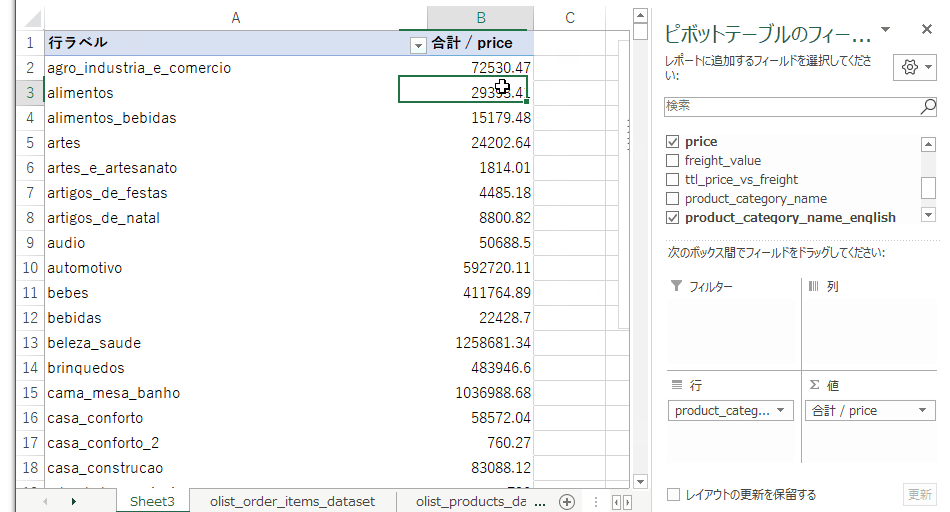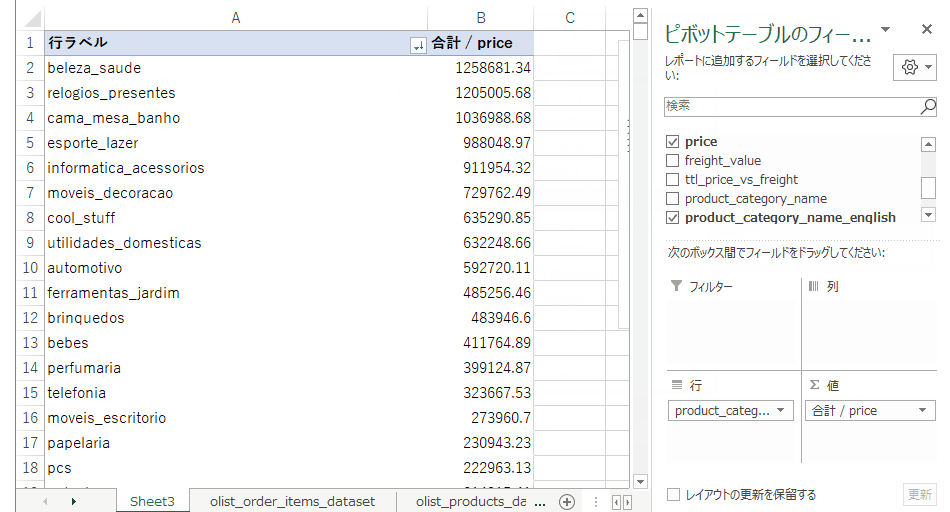
この作業で得られた売り上げのトップ10カテゴリがこちら。
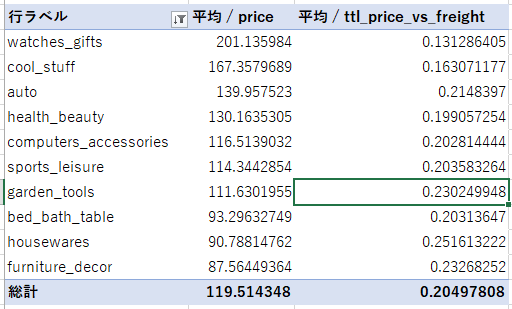
次に、トップ10の中から要件に合う3つのカテゴリを選定するために、別のPivotを作成します。Pivotの参照セルは先ほどと同じ。フィールドリストの値に単価と送料に占める割合を入れ、行にカテゴリを入れ、集計データの平均値を算出するように設定を変更します。
先ほど出した売上トップ10のカテゴリが表示されるよう、行ラベルをフィルタリングします。(gifファイルは例として1カテゴリだけフィルタリング)
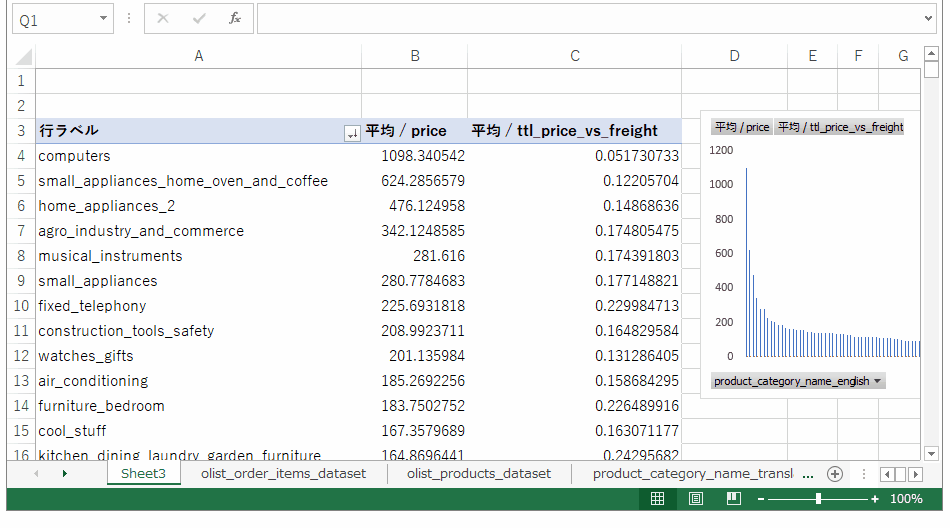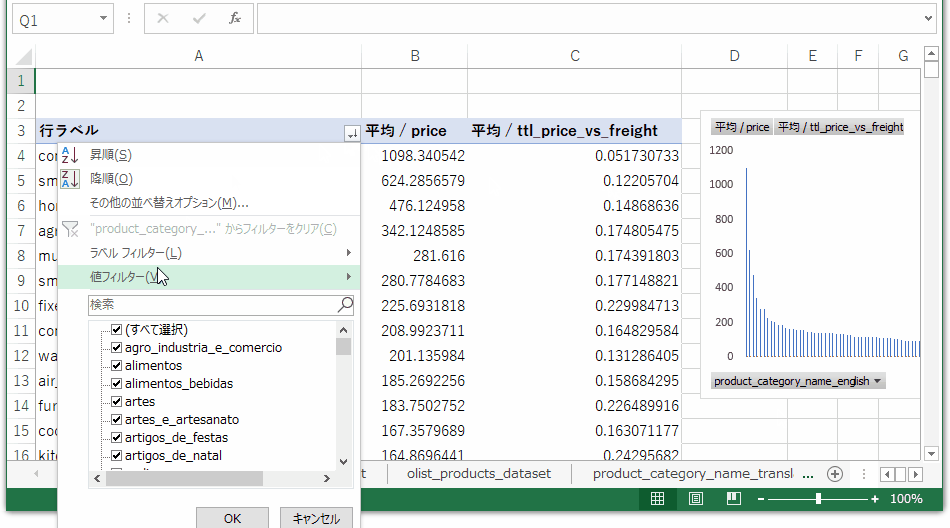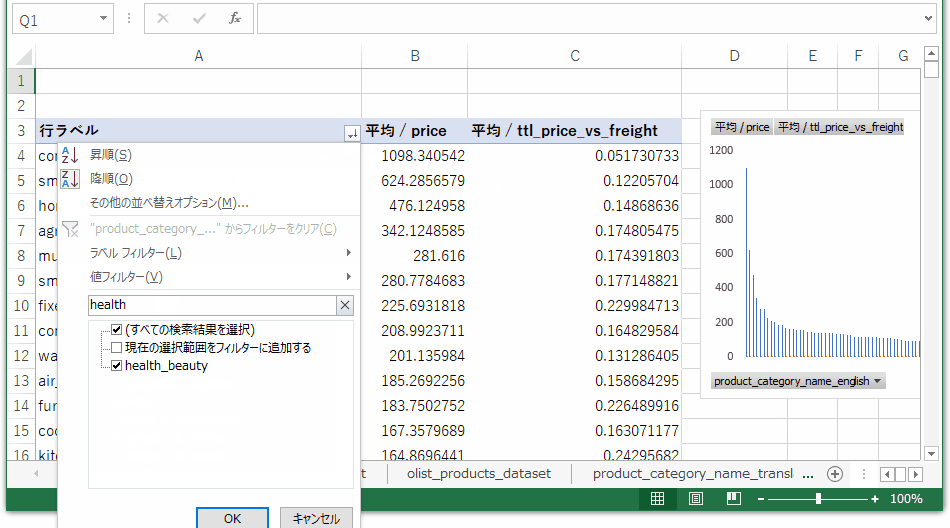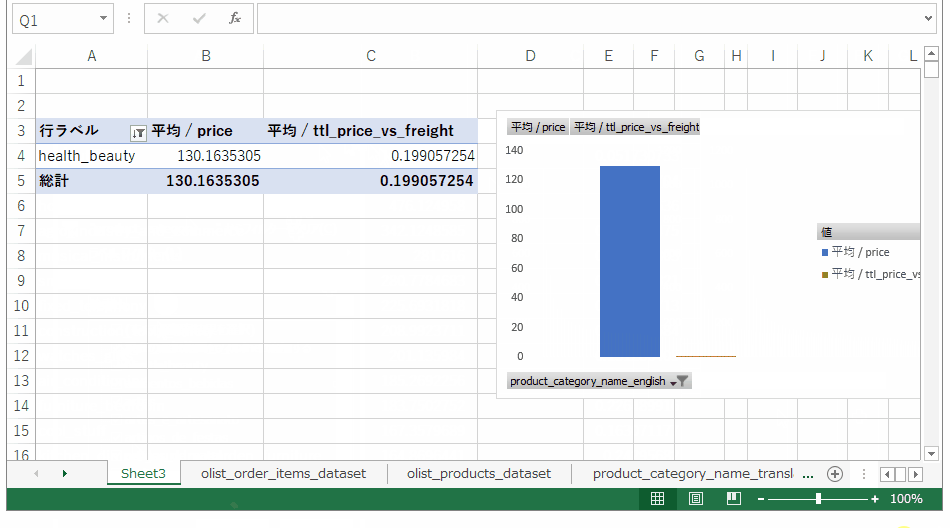
単価を棒グラフで、送料に占める割合を折れ線グラフに変更し、行ラベルなどのグラフ要素を配置します。
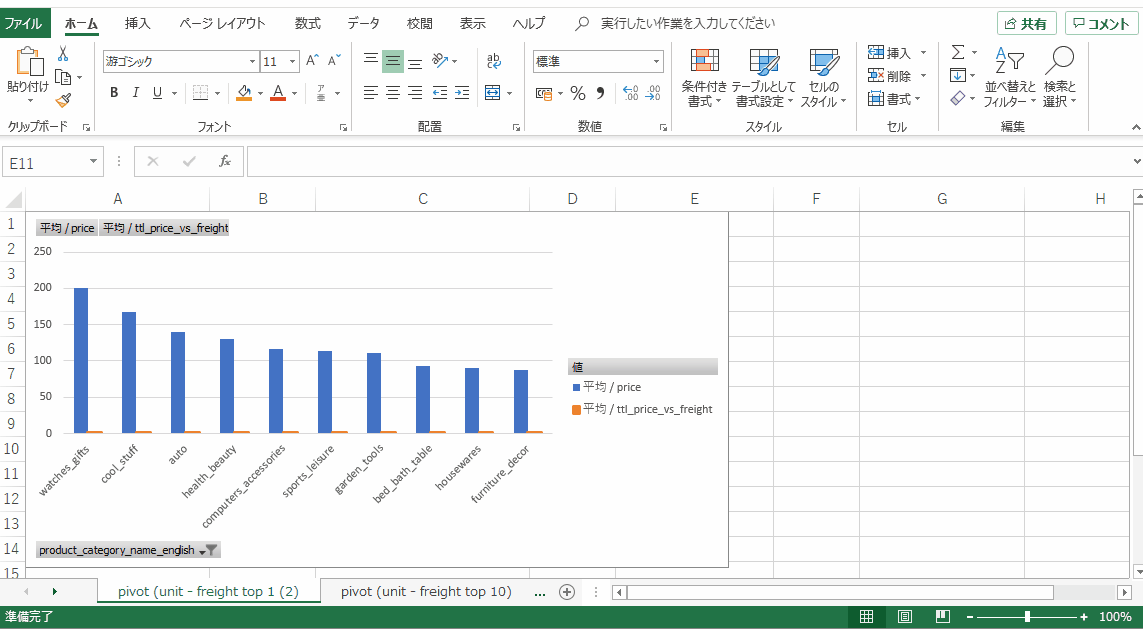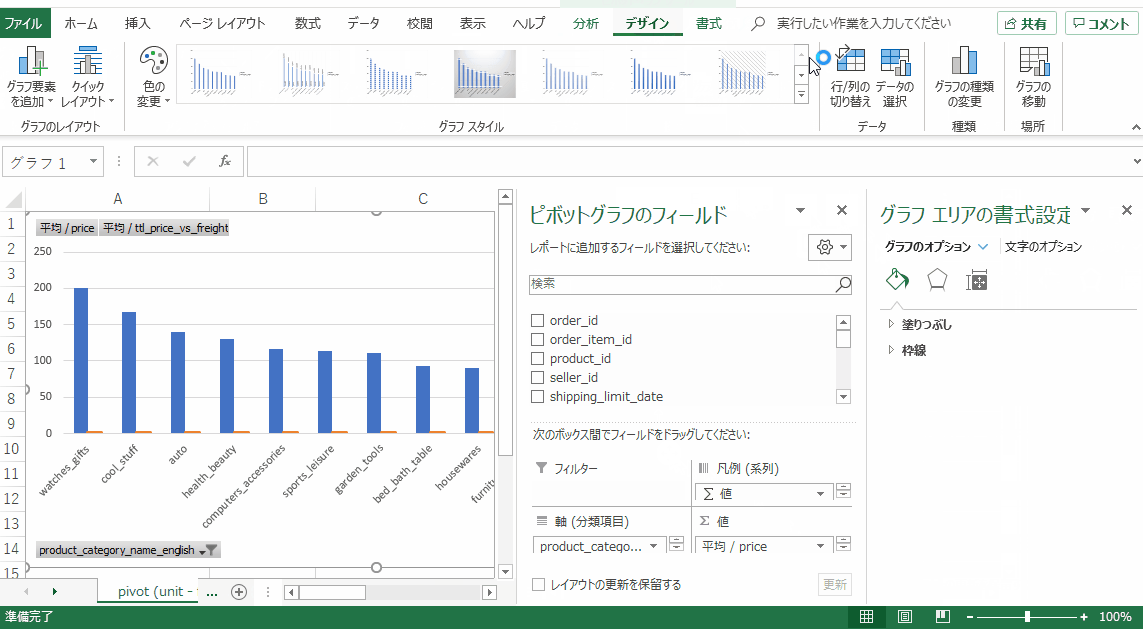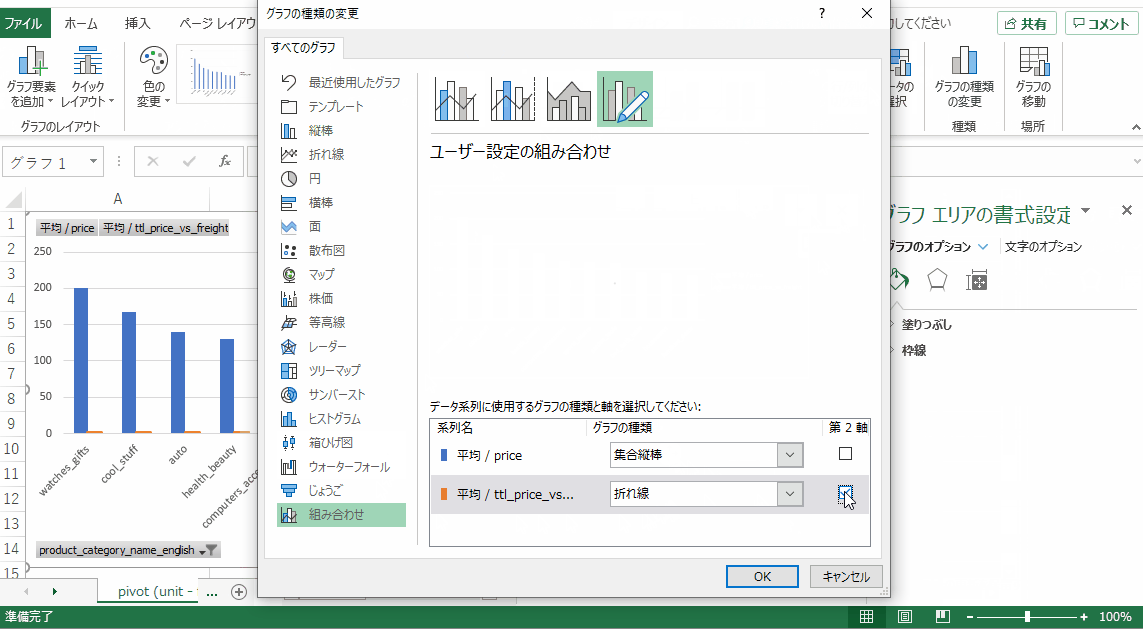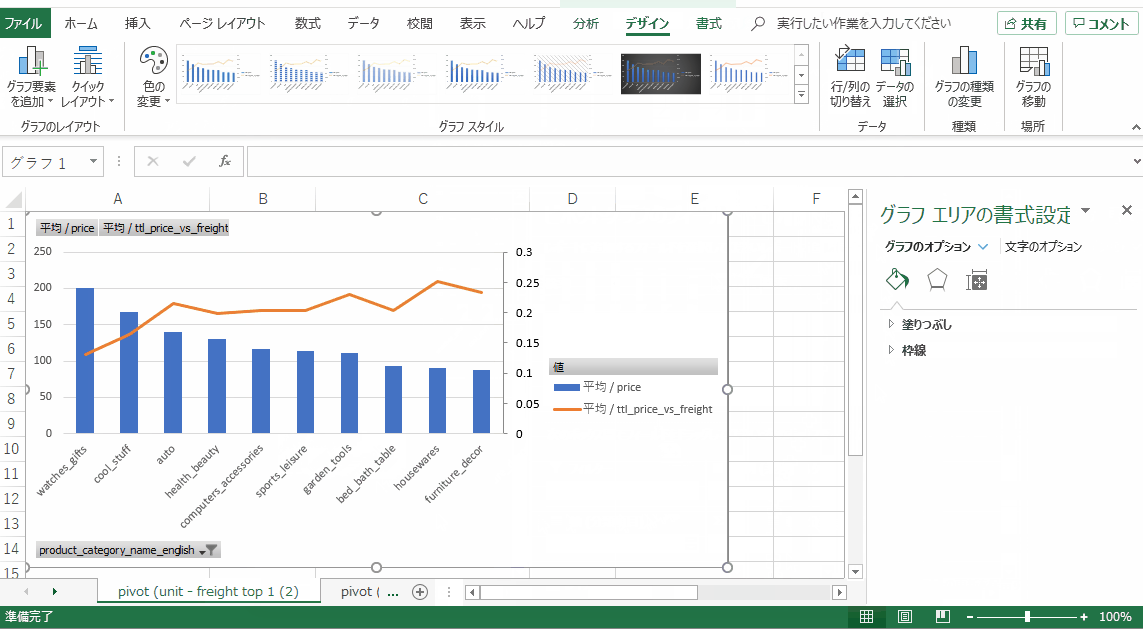
その結果。
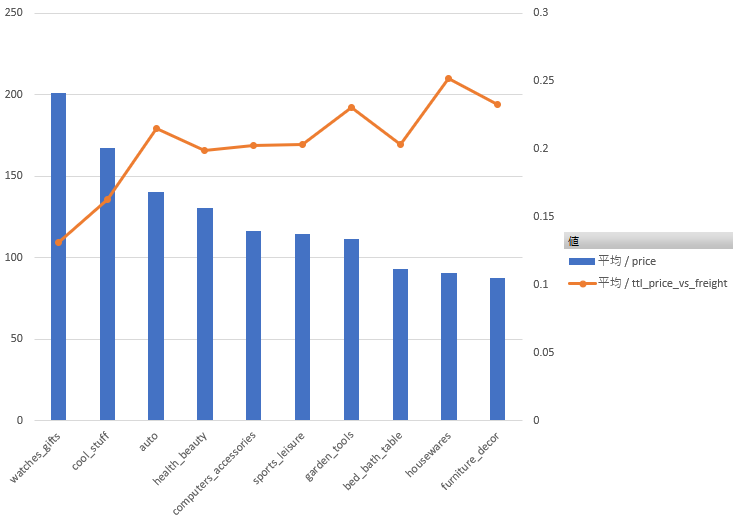
このグラフから、
・ある程度売上ボリュームがある (トップ10以内)
・比較的単価が高い
・配送料の割合が低い
の要件を満たすカテゴリを3つ選定するとすれば、
・watched_gifts
・cool_stuff (DVDなどらしいです。なぜにcool_stuffなのか…)
・health_beauty
あたりでしょうか?なんとなくそれっぽい結果が出ました。
それではこの類の簡易分析・可視化をする場合のExcelの長所短所をまとめてみます。
pros
・習得コストが低い
・参照できるドキュメントが多い
・データ量が少ない場合にはさくっと可視化できる
cons
・運用コストが高い
・元データに対する変更 (列の挿入や行の追加) に弱い
・再現性を高めるために必要なコストが高い
・慣れてる人ほどこれに気が付かない
・ビジネスロジックが埋もれやすい
・数式が入れ子になっていて、結局この列で何を計算してるのか、不明瞭になりやすい
・他人が見たら意味不明なシートが出来上がることがある
・not スケーラブル
・処理の可否がローカルマシンのスペックに依存する
・回避する方法はあるものの、それはそれで結構習得コストが高い
・最大で 約100万行 x 1.6万列 をサポートしているが、今回のような用途ではまず使用不可
まとめ
Excelはお手軽で良いのですが、複数テーブルを結合したりといった分析には不向きですね。分析結果を共有したりするのも苦手です。次回はAzure Notebookでやってみます。お楽しみに!
参考サイト
Kaggle.com
Brazilian E-Commerce Public Dataset by Olist
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
