渡邊です。
Apache Sparkベースの分析プラットフォーム「Databricks」がAzure上で使用出来るようになりました。
今回はこの「Azure Databricks」をなるべく簡単な構成で使ってみます。
1. 構成図
構築する環境の構成は下図の通りです。
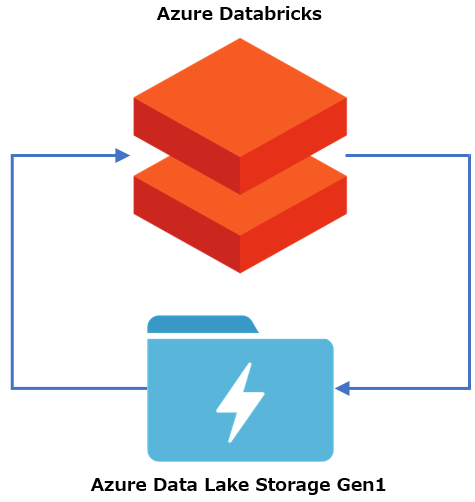
2. 全体の流れ
下記の流れで進めていきます。
・Azure Data Lake Storage Gen1作成
・サービスプリンシパル作成
・データのアップロード
・Azure Databricks ワークスペース作成
・ノートブック作成
・Sparkクラスター作成
・データの抽出・変換・出力
・出力データの確認
・SparkクラスターのTerminate
3. Azure Data Lake Storage Gen1作成
最初に「リソースグループ」を作成します。リージョンは「米国東部 2」とします。
その後、「リソースの作成」から「Azure Data Lake Storage Gen1」を選択します。
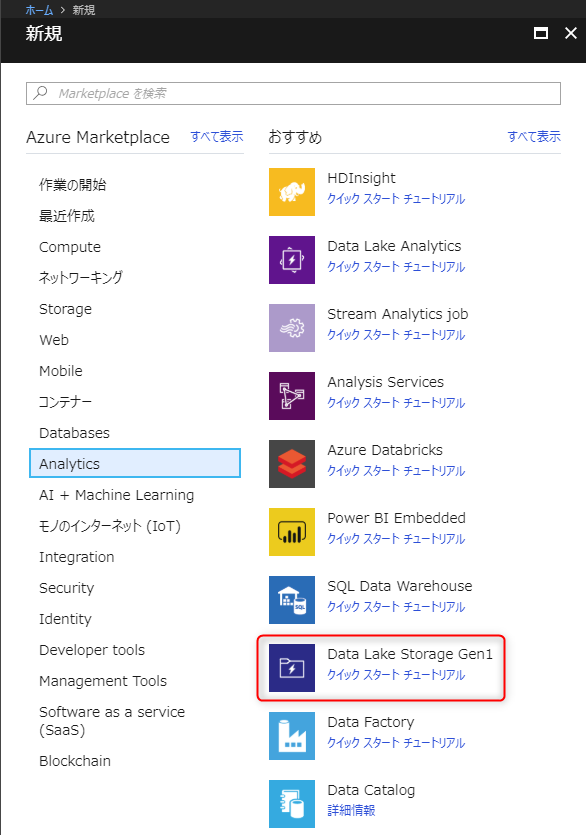
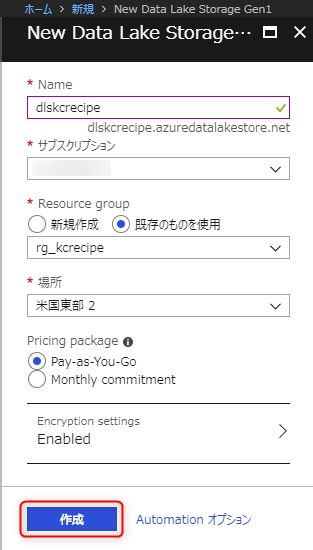
必要な項目を入力して「作成」ボタンを押下します。
Name: 作成するAzure Data Lake Storage Gen1の名前
Resource group: 先程作成したリソースグループ
場所: 今回は「米国東部 2」とします。
4. サービスプリンシパル作成
サービスプリンシパルを作成します。
「Azure Active Directory」から「アプリの登録」を選択します。
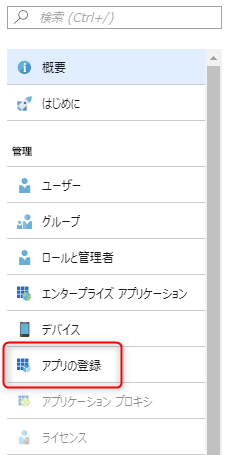
「新しいアプリケーションの登録」を選択します。

必要な項目を入力して「作成」ボタンを押下します。
名前: 作成するサービスプリンシパルの名前
サインオンURL: 任意。ここでは「https://eastus2.azuredatabricks.net」を入力します。
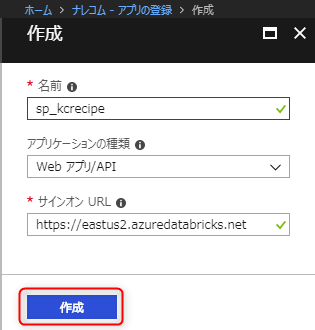
「アプリケーションID」は後程使用するので控えておきます。
「設定」を選択します。
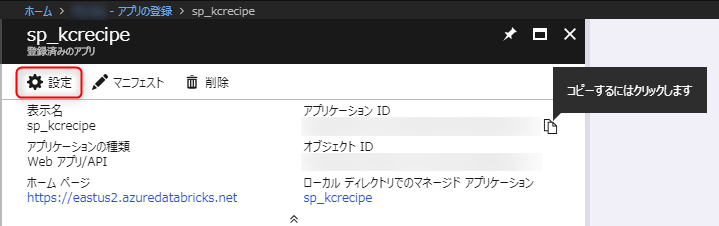
「キー」を選択します。
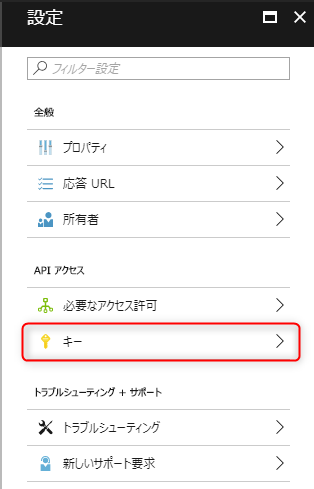
「キーの説明」「期間」を入力します。
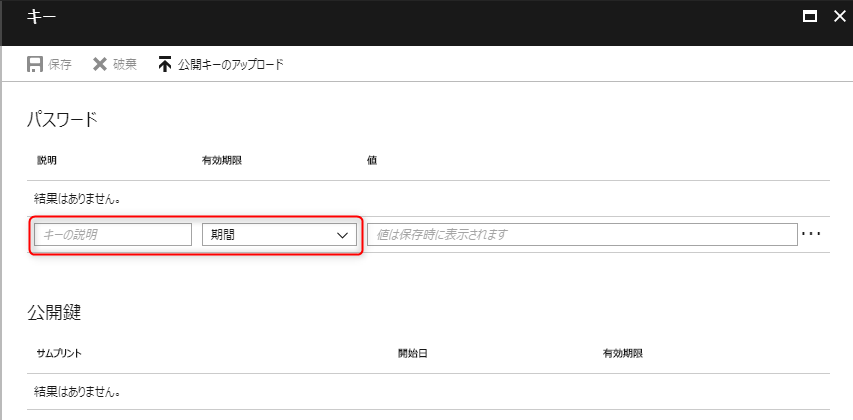
「保存」を選択します。
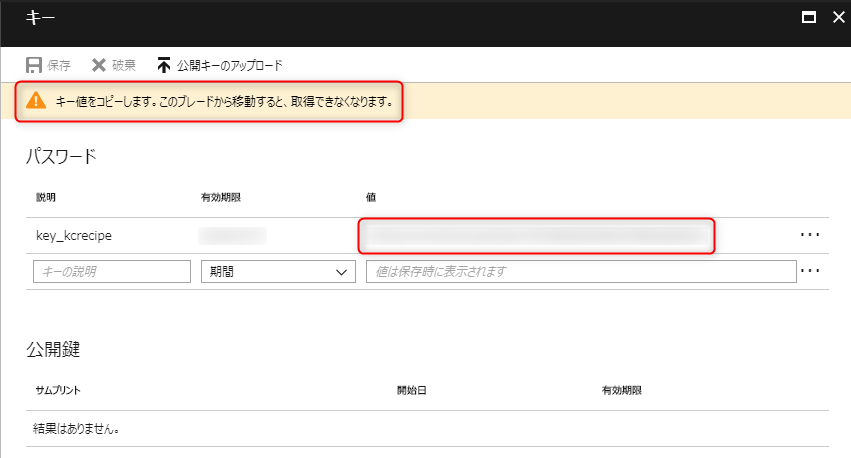
「値」の文字列を控えておきます。後程使用します。
「Azure Active Directory」に戻って、「プロパティ」を選択します。
「ディレクトリID」を控えておきます。後程使用します。

作成した「Azure Data Lake Storage Gen1」の画面で「アクセス制御(IAM)」を選択します。
「追加」を選択します。

「役割」を選択します。
作成したサービスプリンシパル名で検索し、選択します。
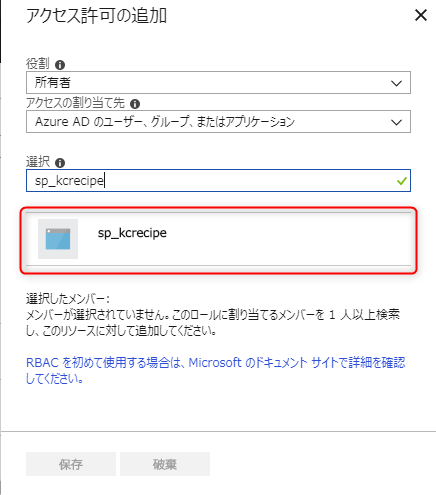
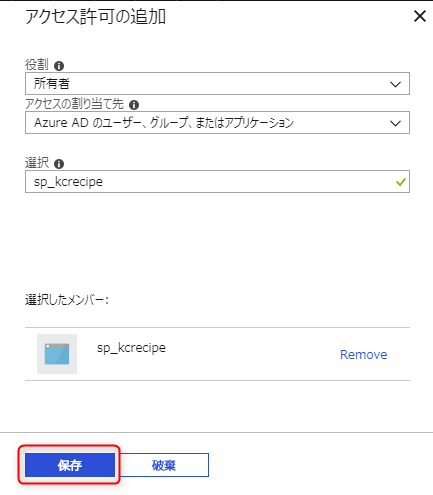
「保存」ボタンを押下します。
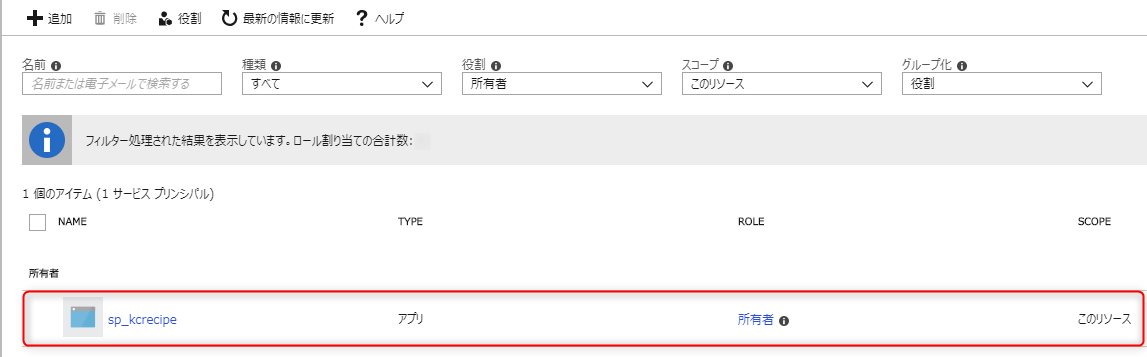
作成したサービスプリンシパルが追加されたことが確認出来ます。
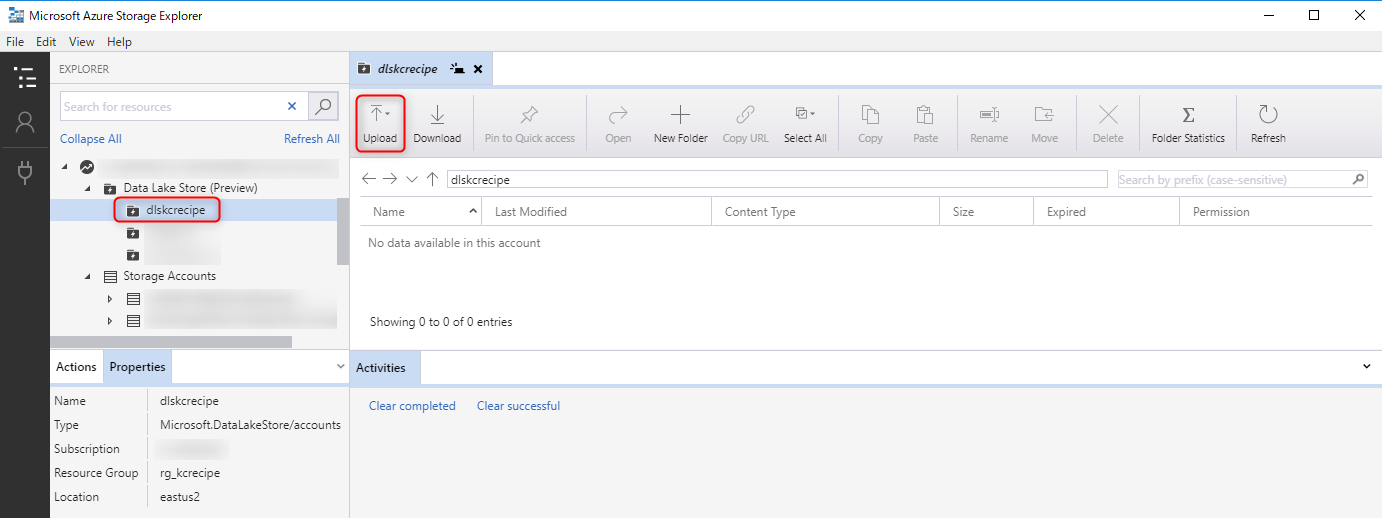
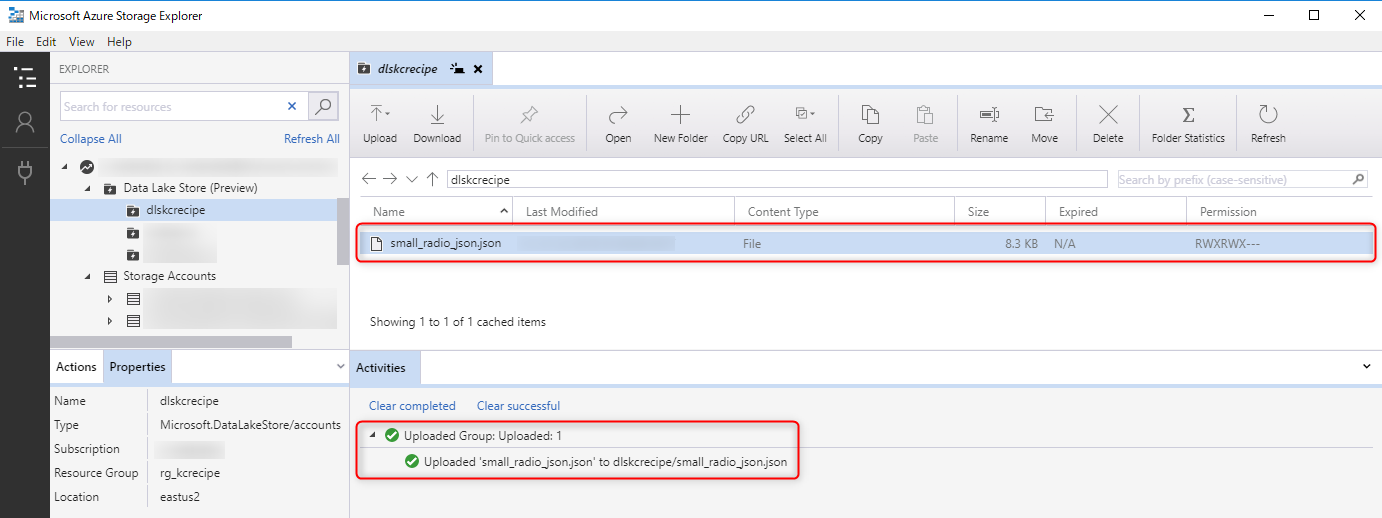
5. データのアップロード
Azure Storage Explorer(参考リンク[9][10])を使用して、作成した「Azure Data Lake Storage Gen1」にサンプルデータ(参考リンク[14])をアップロードします。
6. Azure Databricks ワークスペース作成
「リソースの作成」から「Azure Databricks」を選択します。
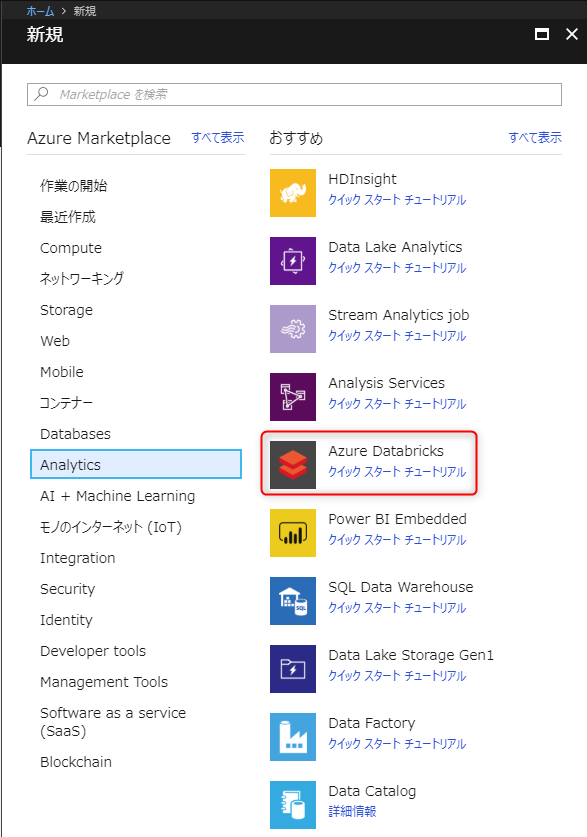
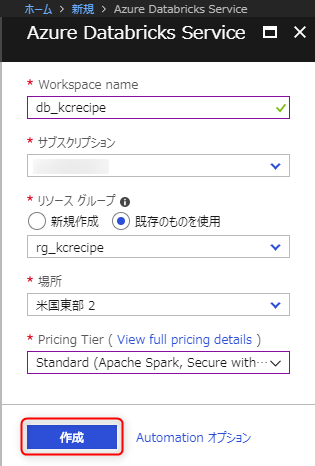
必要な項目を入力して「作成」ボタンを押下します。
Workspace name: Databricksのワークスペースの名前
リソース グループ: 作成したリソースグループ
場所: 今回は「米国東部 2」とします。
Pricing Tier ( View full pricing details ): 今回はStandardを選択します。
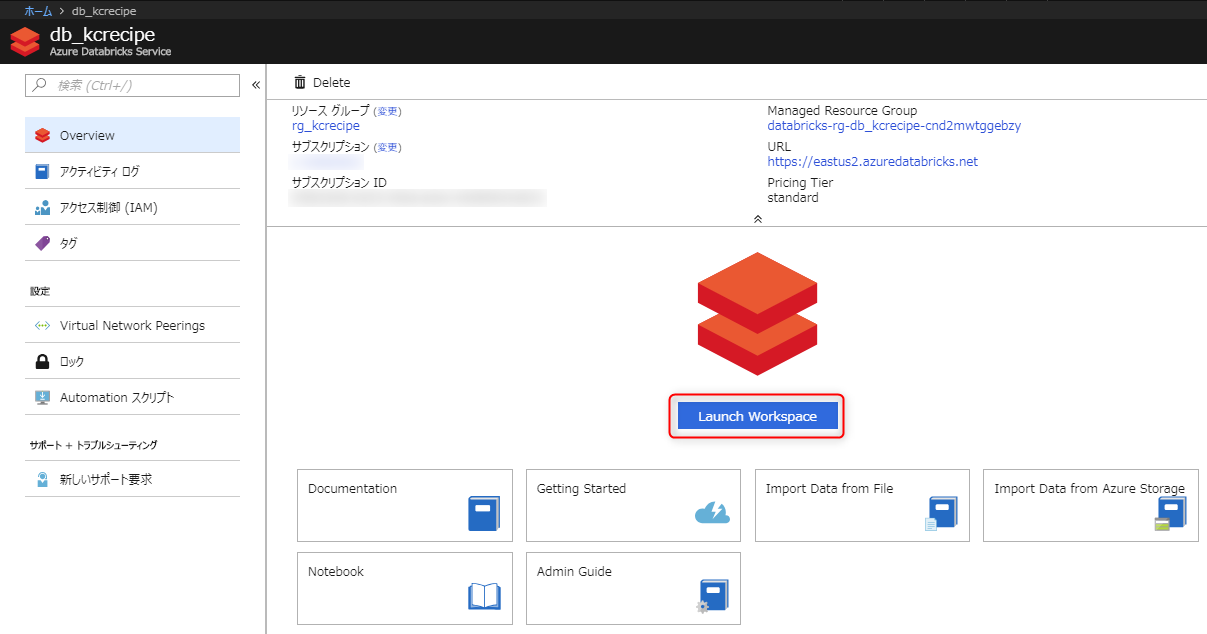
ワークスペースが作成されたら、「Launch Workspace」ボタンを押下します。
サインイン画面に遷移します。自動でサインインします。
サインイン出来たらAzure Databricksのポータル画面に遷移します。
7. ノートブック作成
Databricksのポータル画面で「Workspace」を選択します。
必要な項目を入力して、「Create」ボタンを入力します。
Name: ノートブック名
Language: 使用するプログラミング言語。今回は「Python」を選択します。
ノートブックが開きます。
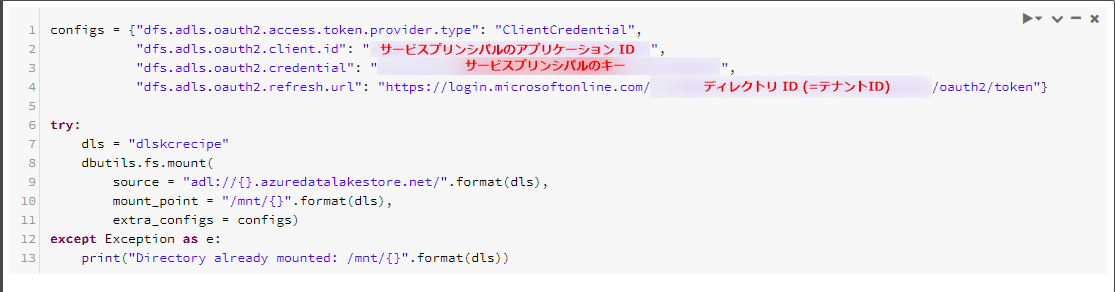
DatabricksでAzure Data Lake Storage Gen1上のファイルを読み込んだり、書き出したりする場合、Databricks Filesystem(DBFS)としてマウントする必要があります。
具体的には下図のようなプログラムを組む必要があります。ここで先程控えた三点「サービスプリンシパルのアプリケーションID」「サービスプリンシパルのキー」「ディレクトリID」が必要になります。
以降は次のようなプログラムを組みます(参考リンク[4])。







8. Sparkクラスター作成
Databricksのポータルから「Clusters」を選択します。

「Create Cluster」ボタンを押下します。
クラスターの設定画面に遷移します。
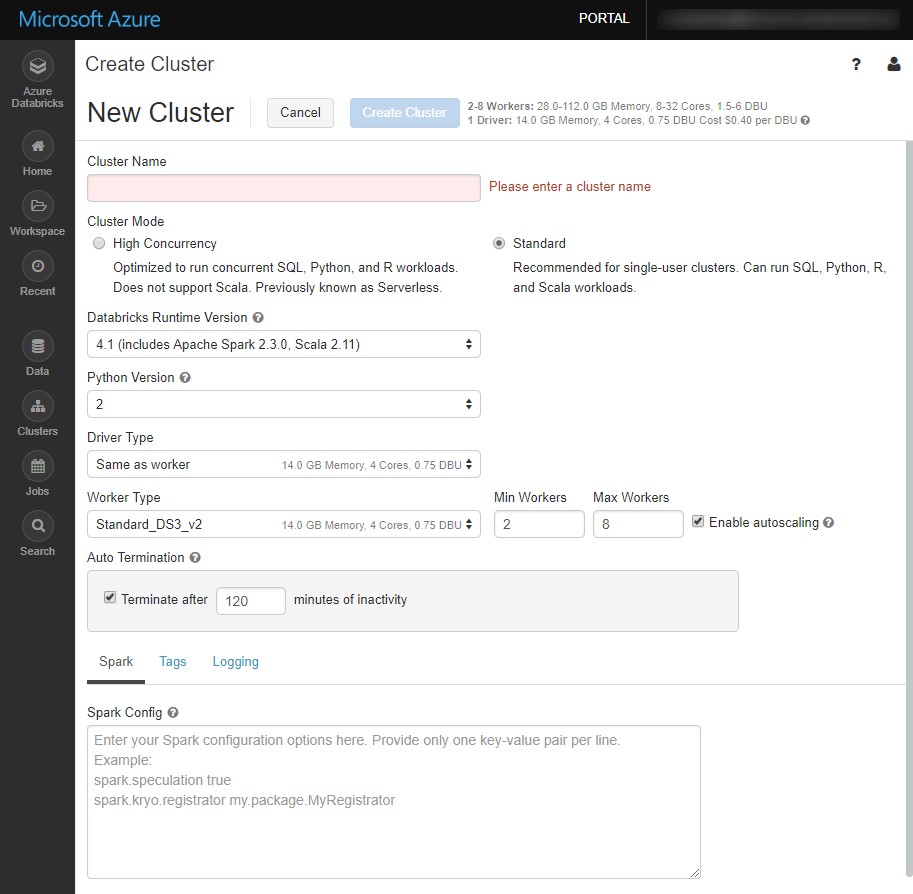
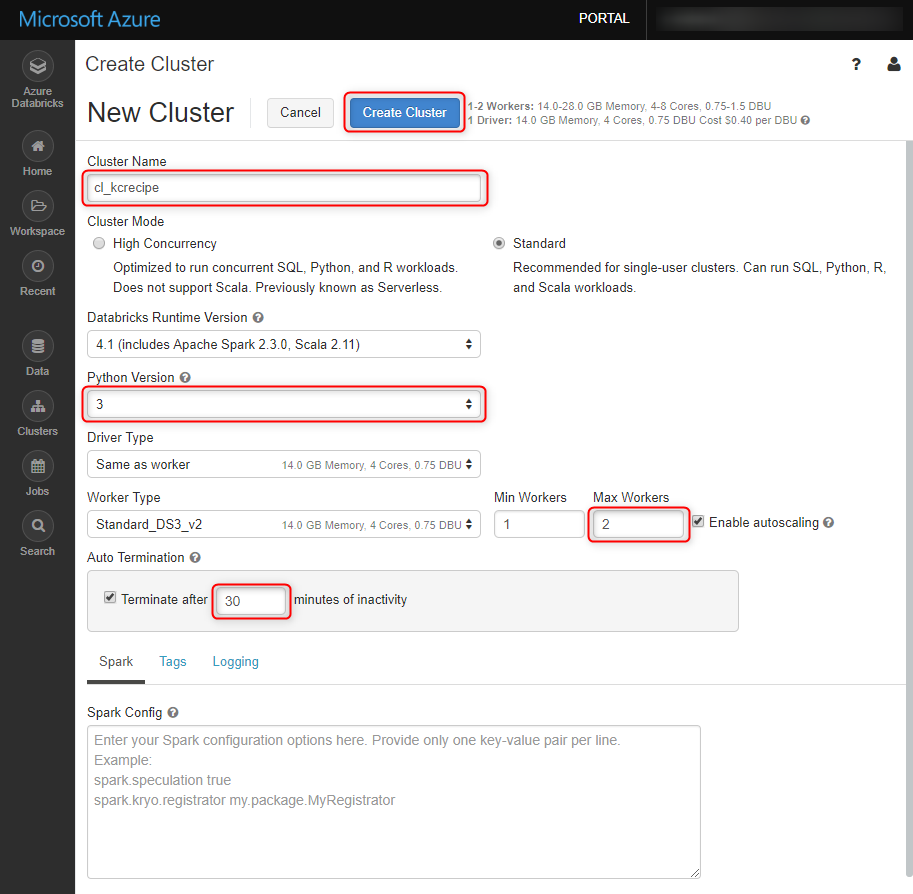
今回は下図のように設定します(デフォルトから変更した部分を赤枠で囲っています)。
Cluster Name: クラスター名
Python Version: Pythonのバージョン
Max Workers: 自動スケーリング時の最大Workerノード数
Auto Termination: アイドル状態のまま設定時間が経過すると、自動的にクラスターが停止される。
「Create Cluster」ボタンを押下します。
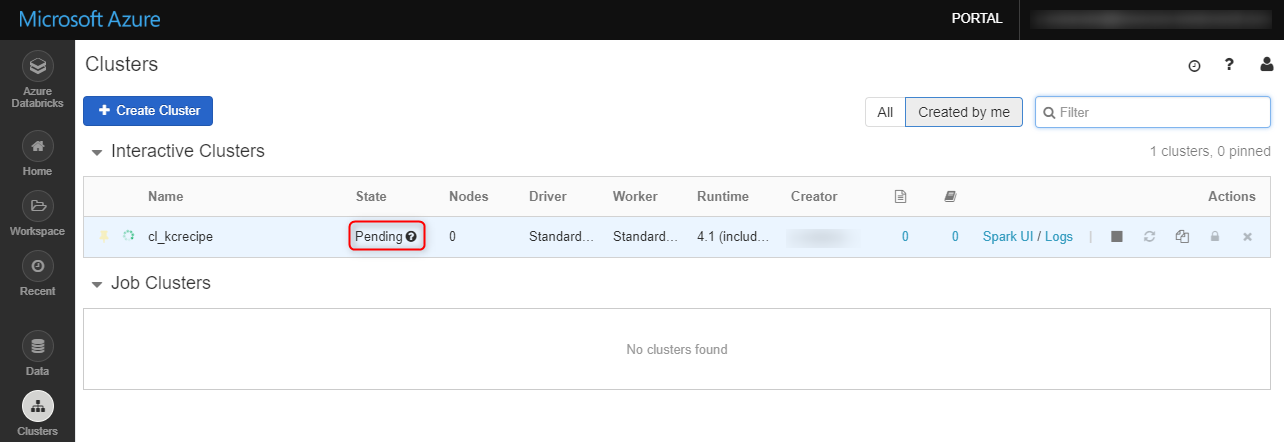
クラスターの「State」が「Pending」になります。
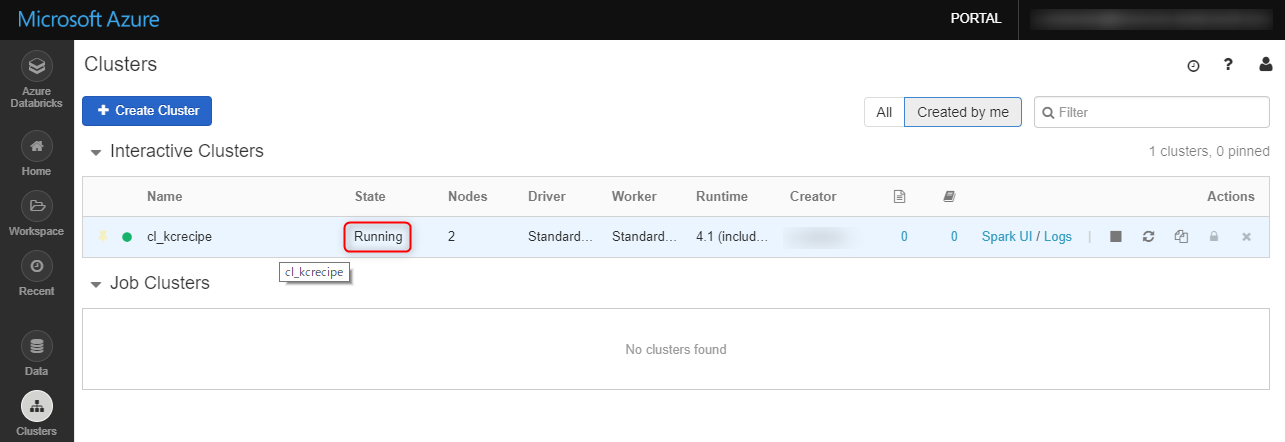
暫く待つと、「State」が「Running」になります。
9. データの抽出・変換・出力
作成したノートブックを開き、「Detached」をクリックします。
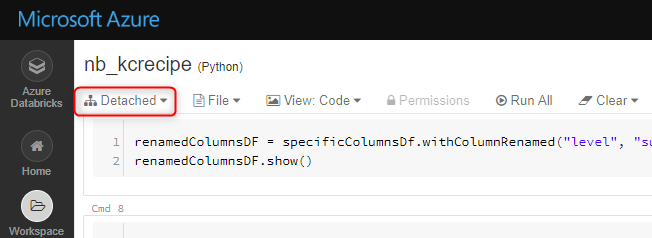
ノートブックをアタッチするクラスターが表示されます。先程作成したクラスターを選択します。

ノートブックがクラスターにアタッチされました。これでノートブック上のプログラムを実行出来ます。
今回は「Run All」を選択し、先頭から末尾までの全てのセルを順次実行します。
※セルを選択して、「Shiftキー」+「Enterキー」でセル毎に実行することも出来ます。

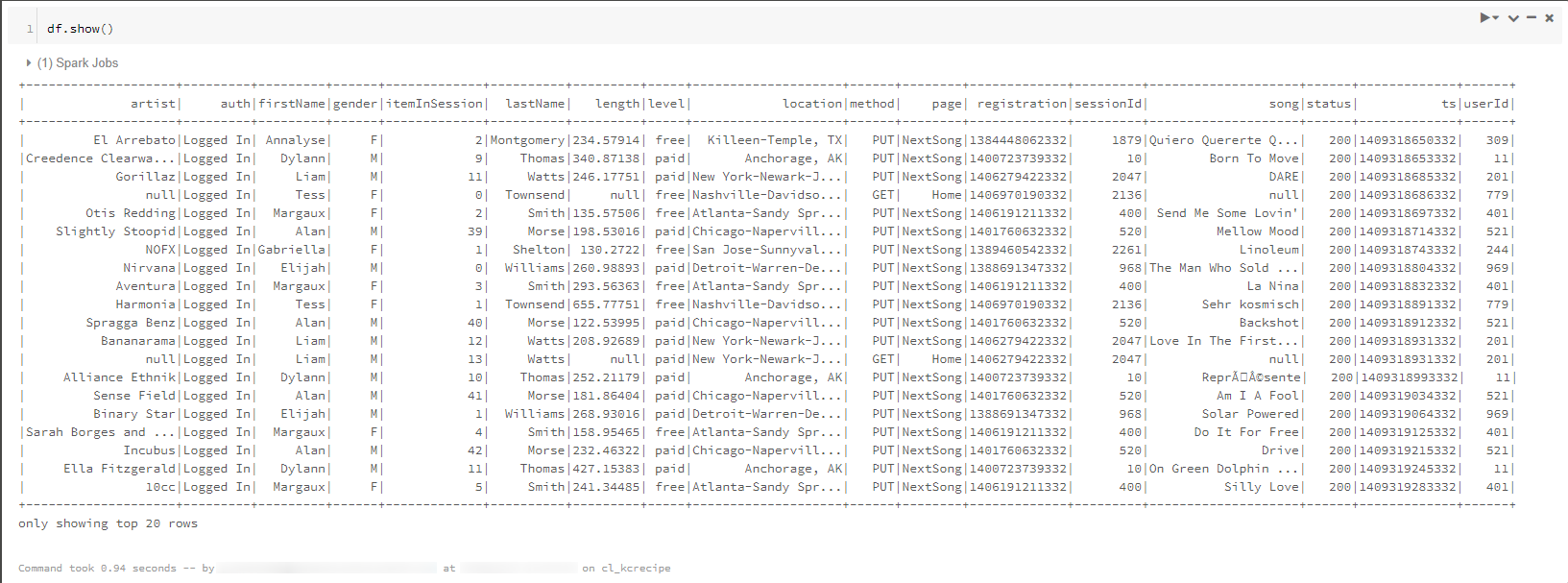
サンプルデータをDataFrameに格納し、内容の一部を表示させています。
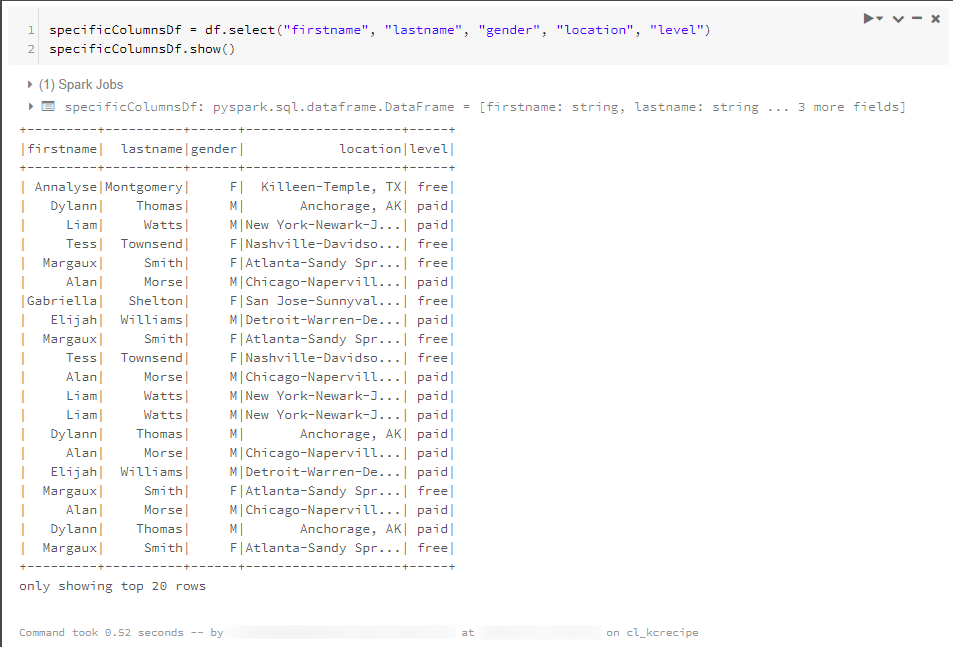
一部の列を選択して別のDataFrameに格納し、内容の一部を表示させています。
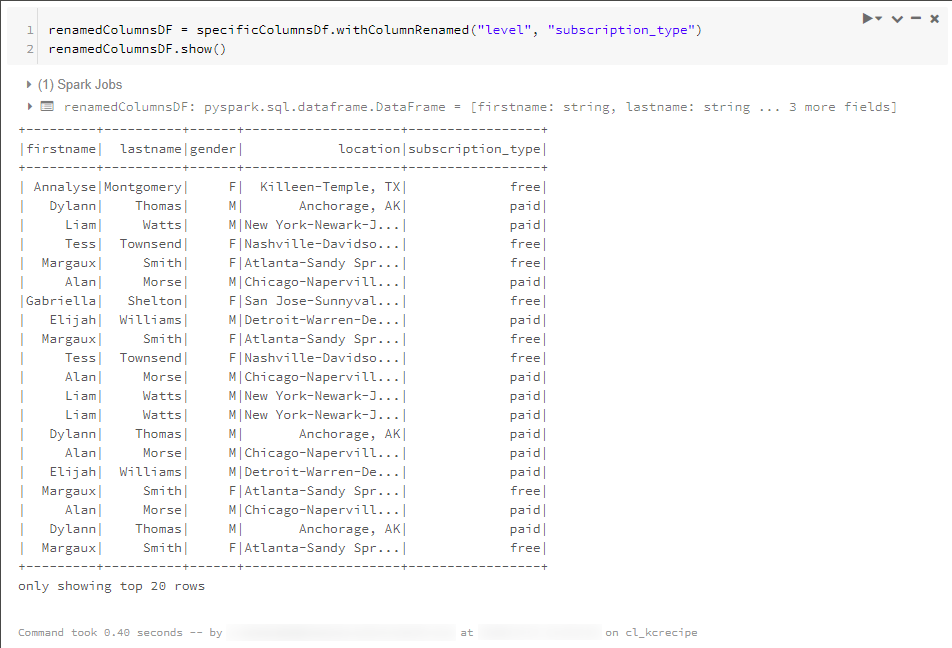
列名を変更して別のDataFrameに格納し、内容の一部を表示させています。
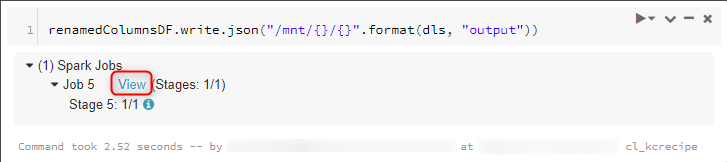
DataFrame「renamedColumnsDF」を、Azure Data Lake Storage Gen1上にJSONファイルとして出力します。
「View」をクリックすると、ジョブに関する情報を閲覧出来ます。

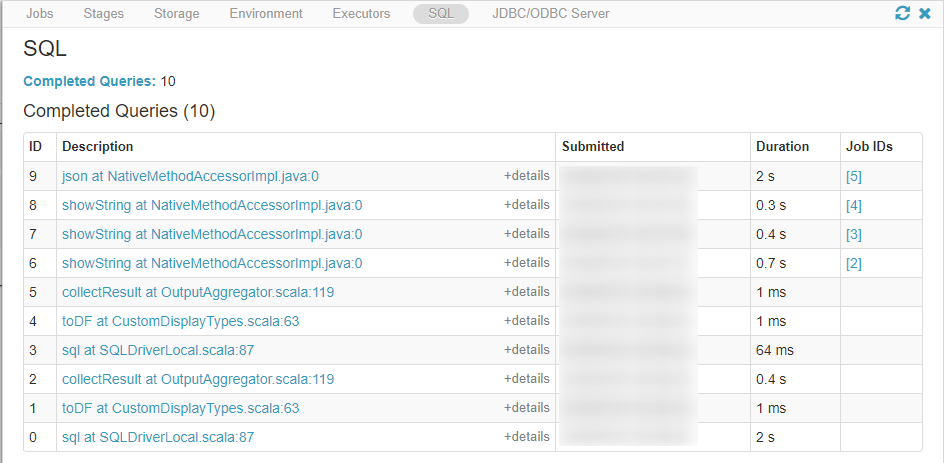
10. 出力データの確認
出力先ディレクトリにファイルが出力されていることが確認出来ます。
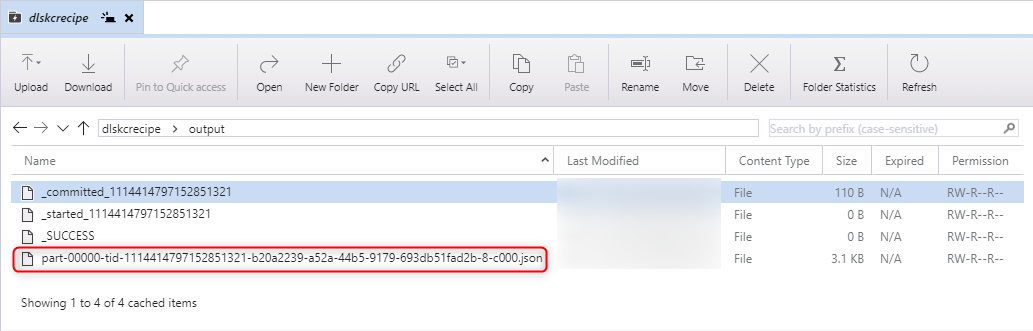
11. SparkクラスターのTerminate
クラスターは、Auto Terminationを有効にすれば、アイドル状態のまま設定した時間が経過すると自動的にTerminate(停止)されます。しかし、手動でTerminateすることも出来ます。
今回はクラスターを手動でTerminateします。対象のクラスターにマウスオーバーして、「■」ボタンを押下します。
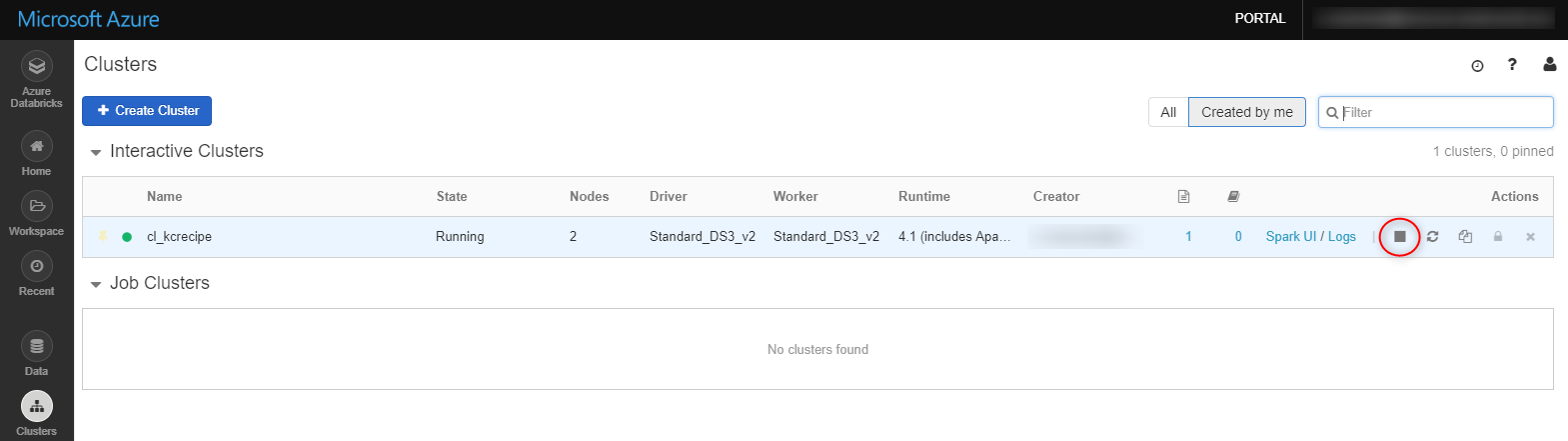
「Confirm」ボタンを押下します。
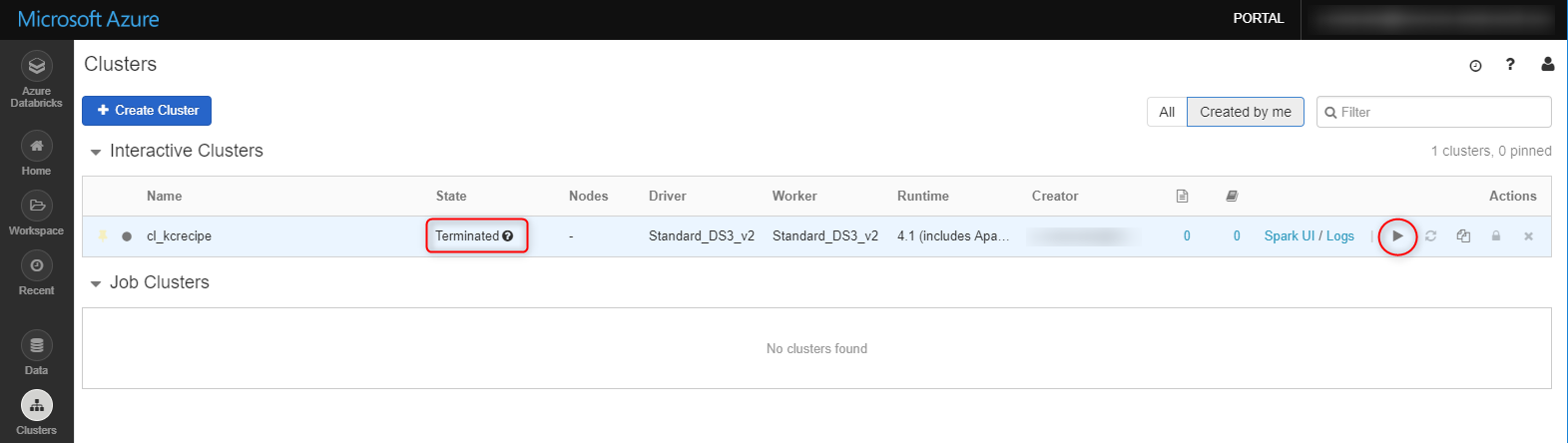
クラスターの「State」が「Terminated」になり、停止されます。
おわりに
以上、Azure Databricksをなるべく簡単な構成で使ってみました。
今回取り上げたのは、Azure Databricksの機能の一部であり、他にも様々なことが出来ます。
例えば、今回選択した「Python ( PySpark )」の他に、「Scala」「SQL」「R」の言語が使用出来ます。また、あらかじめ設定した時刻にプログラムを実行する、スケジュール実行も可能です。
最後までご覧頂きありがとうございました。
参考リンク
下記URLのページを参考にさせて頂きました。ありがとうございます。
[1]Azure Databricks | Microsoft Azure
[2]Azure Databricks の価格 | Microsoft Azure
[3]Azure Databricks のドキュメント | Microsoft Docs
[4]チュートリアル: Azure Databricks を使用したデータの抽出、変換、読み込み | Microsoft Docs
[5]Welcome to Azure Databricks — Databricks Documentation
[6]Azure Data Lake Storage Gen1 — Databricks Documentation
[8] 20180627 databricks ver1.1
[9] Azure Storage Explorer – クラウド ストレージ管理 | Microsoft Azure
[10] Azure Storage編 ~Microsoft Azure Storage ExplorerでAzure Storageを操作してみた~|Azure Storage| | ナレコムAzureレシピ
[11]ビッグ データ分析用の Data Lake Storage | Microsoft Azure
[12]Azure Data Lake Store の概要 | Microsoft Docs
[13]pyspark.sql module — PySpark master documentation
[14] usql/small_radio_json.json at master · Azure/usql · GitHub
その他お知らせ
弊社ではAzure Databricksの導入支援やトレーニングのご支援等も実施しております。お気軽にご相談いただければありがたいです。
■Azure Databricks によるビッグデータ解析ソリューション
https://azure.kc-cloud.jp/service002.html
■Azure Databricks 活用事例
http://www.knowledgecommunication.jp/news/138.html
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
