はじめに
前回Azure MLのデザイナーで作ったこちらのパイプラインをPythonから実行してみます。
開発環境
- OS Windows 10(NVIDIA GTX 1650Ti,16GB RAM, i5-10300H CPU)
- Visual Studio Code 1.73.1
- Python 3.9
Pythonから実行するまで
PythonからAzure MLを使用するには「Azure CLI」をインストールする必要があります。
公式に載っている方法でインストールをしてください。
Windowsの場合は、こちらを開き、「Azure CLIの最新のリリース」をクリックしてインストールファイルを実行すればできます。
コマンドプロンプトからログインをします。
|
1 2 |
az login |
これでWebページに飛ぶので、ログインを完了したら前準備は終わりです。
Azure MLのデザイナーを起動
それでは前回作成したデザイナーを開きます。
(作成方法やジョブの実行方法は前の記事をご覧ください!)
今回はパスを指定することで、
- 学習させる入力データ
- 結果データの出力先
を決めていけるようにしていきます。
前回からのブロック変更箇所
- Import Dataコンポーネント
- Export Dataコンポーネント
これらのコンポーネントを追加、パス設定を変更します。
コンポーネントの追加
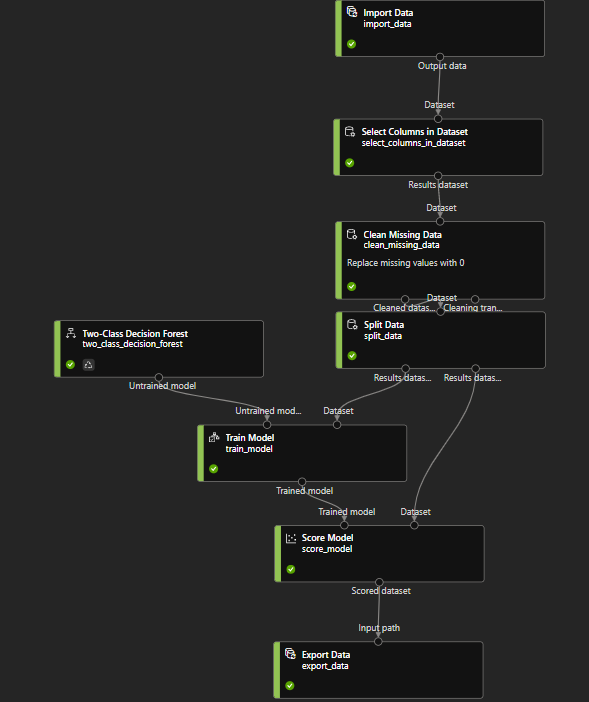
追加したパイプラインがこんな感じです。
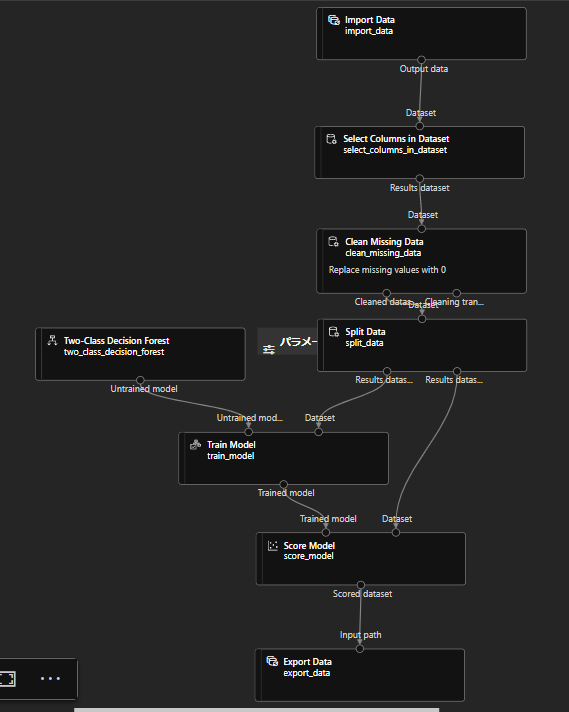
前回は入力データを「TPS-AUG-2022」としていたところを、Import Dataコンポーネントに変更しています。そして、Score Modelの結果をExport Dataで取り出せるようにしました。
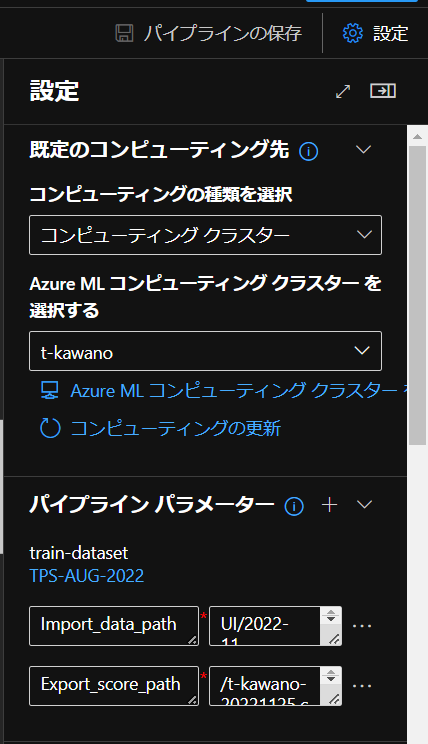
パイプラインパラメータの変更
次に追加した2つのコンポーネントの設定を変更します。
まず、Import Dataについては、学習データをどこから持ってくるか設定する必要があります。
学習データが入っている「データソース」、「データストア」を選択後、
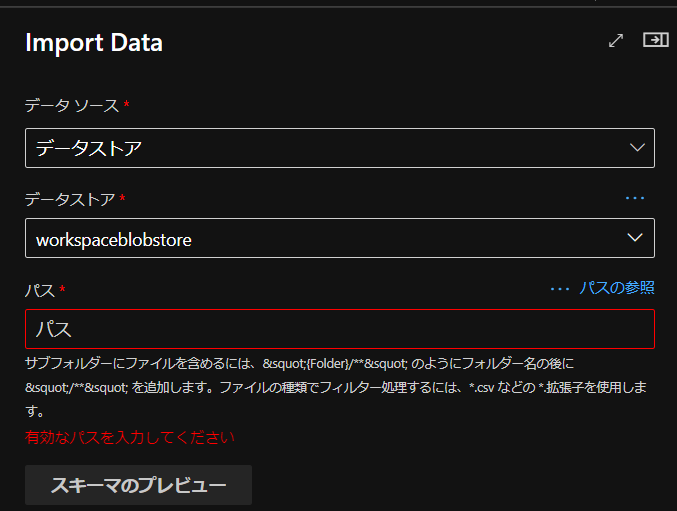
このようにパス設定を求められます。
ここで使用するのが「パイプラインパラメータ」。
これを用いることで実行ごとに学習データセットの選択と出力先を決めることが可能になります。
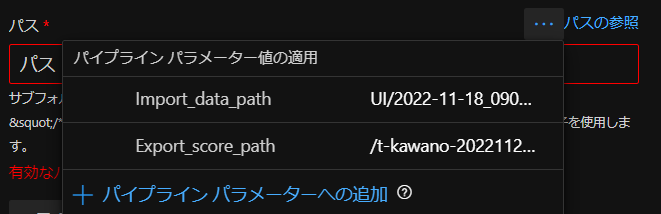
右上の「・・・」をクリックし、「+パイプラインパラメータへの追加」を選択。
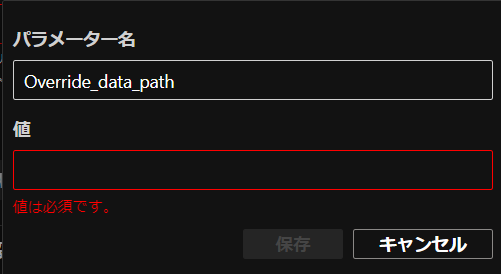
「パラメーター名」と「値」を入力すれば作成できます。
今回の学習データには前回同様にKaggleのTabular Playground Series – Aug 2022を使っていきます。
データセットは前回追加したので、trainデータセットの保存先のパス名を「値」に入力します。
また「パラメーター名」は「Import_data_path」としました。
同様に、Export Dataのパイプラインパラメータも設定します。
「パラメーター名」を「Export_score_path」に、
「値」には出力したい場所のパスと出力時の名前を入力します。
これでパイプラインパラメータの追加は完了です。
パイプラインパラメータの更新・削除
パイプラインパラメータの名前の変更や削除は右上の「設定」から「・・・(三点リーダー)」から可能です。
ジョブで実行できているか確認
ブロックの変更が完了したので、いったんこのパイプラインを実行できるか確認します。
問題なく実行できました!
パイプラインエンドポイントの作成
Pythonoから実行できるようにパイプラインを公開していきます。
まずは実行完了したジョブから「公開」ボタンを押して、パイプラインのエンドポイントを作成します。
そして作成後、「パイプラインID」ができるのでこれを使えばPythonからの実行ができます。
IDはどこに書いてあるのかというと、作成したパイプラインエンドポイントを開き
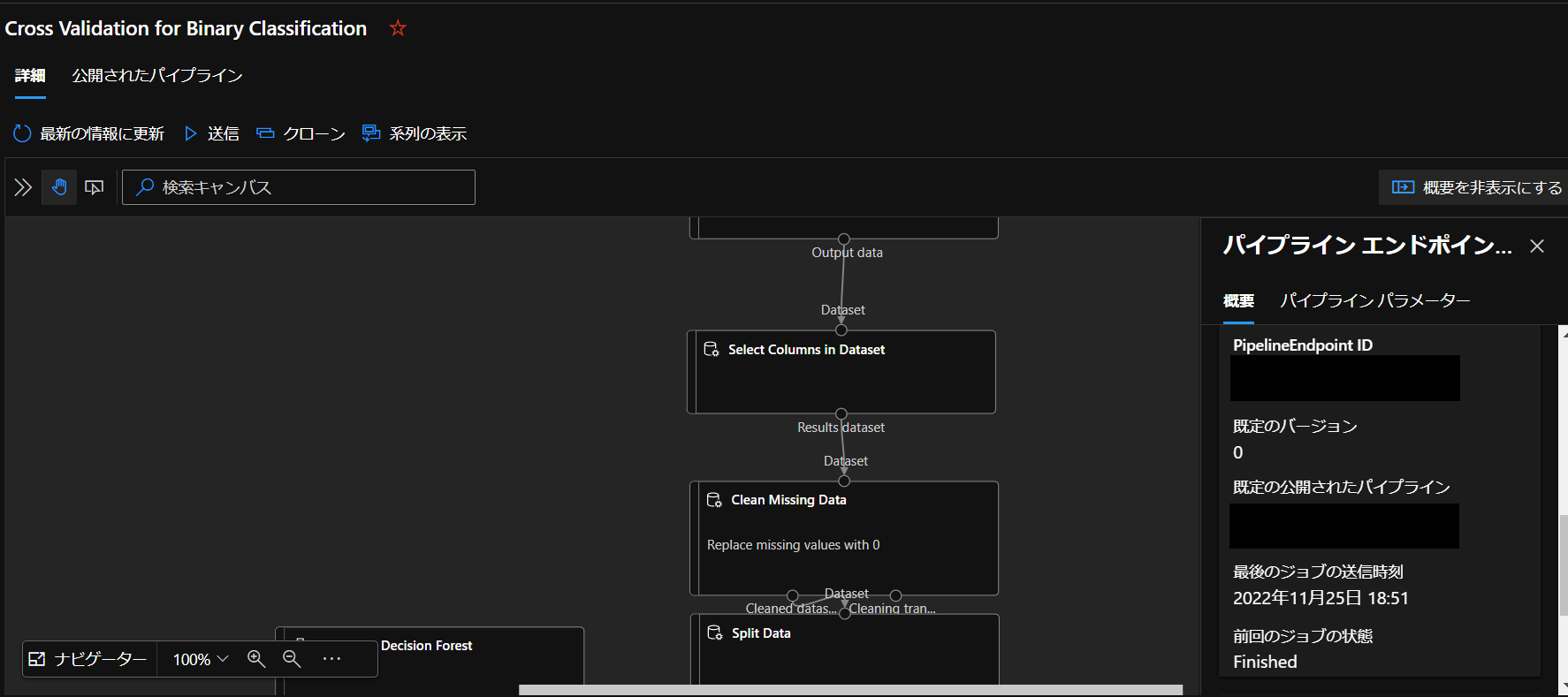
概要の下の方にスクロールしたときに現れる「既定の公開されたパイプライン」に書かれてあります。
これがパイプラインIDです。
Pythonから実行
こちらのコードを動かして、パイプラインをPythonから実行していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
azureml-test.py from azureml.core import Workspace from azureml.core.experiment import Experiment from azureml.pipeline.core import PublishedPipeline ws = Workspace.from_config() experiment = Experiment(workspace=ws, name='XXX') published_pipeline = PublishedPipeline.get(workspace=ws, id="YYY") pipeline_run = experiment.submit( published_pipeline, pipeline_parameters={ "Import_data_path": "UI/2022-11-18_090809_UTC/train.csv", "Export_score_path": "/t-kawano-test-20221125.csv", } ) #XXX:実験名 #YYY:パイプラインID |
実験名は任意で、パイプラインIDは先ほどのものを貼り付けます。
Import_data_pathとExport_score_pathにはそれぞれ学習データがあるパスと、出力先のパスを設定します。
しかし、これで実行してみたらazureml-coreとazureml-pipeline-coreがないと言われたので、
|
1 2 3 |
pip install azureml-core pip install azureml-pipeline-core |
これでpipインストールします。
インストール後、もう1回実行したら今度は
「The workspace configuration file config.json, could not be found」
というエラーが出てきました。
このエラーの対処としては、ワークスペースに戻り、右上のアカウント名をクリックします。
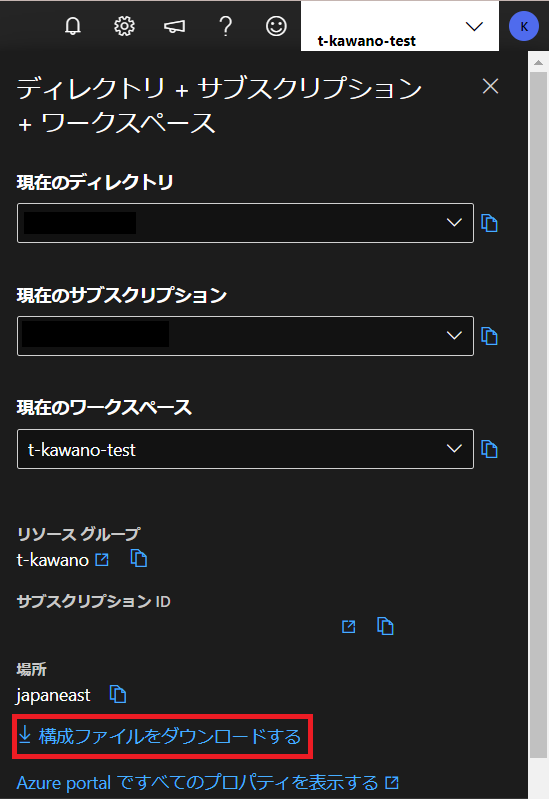
そして「構成ファイルをダウンロードする」をし、config.jsonをプロジェクト直下に置きます。
これでもう1度実行!
|
1 2 3 |
Submitted PipelineRun XXX #実行ID Link to Azure Machine Learning Portal:https://YYY #ジョブへのURL |
このような結果が返ってきました。
2行目のURLに飛んでみたら、ちゃんと実行できていました^^
実行が終わったらジョブタグで状態ステータスが「完了」となります。

結果データファイルがExportされているか確認してみると

指定した場所にきちんと出力されていました。
一応中身も確認。
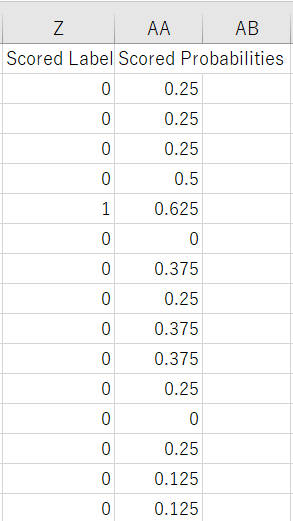
スコアデータも見れるようになってます!
まとめ
- Azure MLで作成したパイプラインをPythonから実行してみた。
- Import DataやExport Dataを追加し、パイプラインパラメータを使えば実行のたびに学習データや出力先を設定できる。
