今回は、Azure Machine Learning (Azure ML)で新たにサポートされたSQL Data Warehouse (SQL DW)との接続についてご紹介します。
操作手順は下記ドキュメントに基づいて行います。
Cortana Intelligence and Machine Learning Blog – How to Use Azure ML with Azure SQL Data Warehouse
https://blogs.technet.microsoft.com/machinelearning/2016/03/08/how-to-use-azure-ml-with-azure-sql-data-warehouse/
※SQL DWの作成については下記の記事を参照してください。
「SQL Data Warehouseを触ってみた」
接続情報の取得
SQL DWとの接続にあたり、あらかじめ接続情報を取得しておきます。
Azureポータルの「SQL Server」から作成したSQL DWのデータベースを選択し、「サーバー名」、「データベース名」、「サーバー管理者」の3項目の情報をメモしておきます。
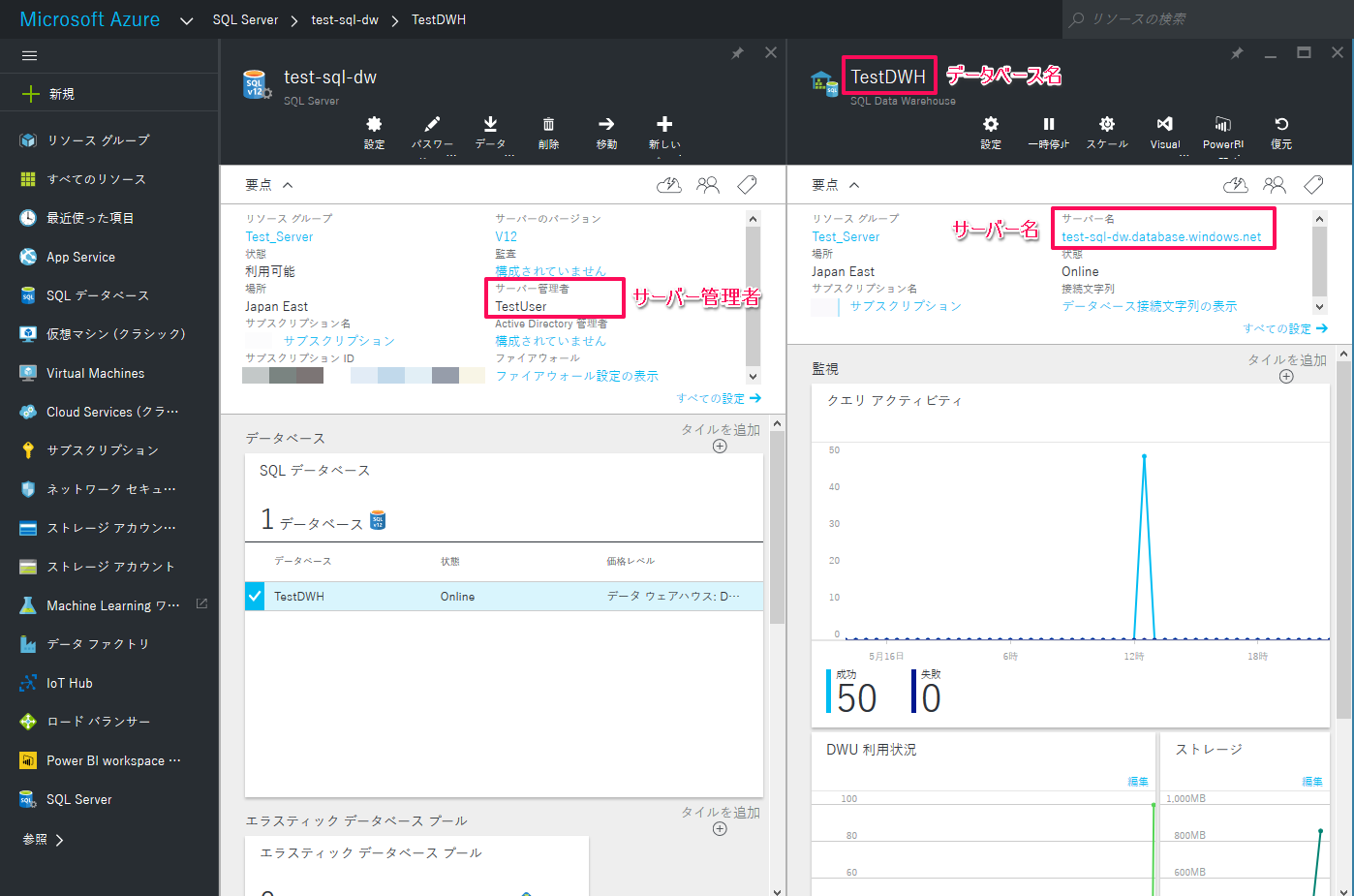
SQL DWとの接続
SQL DWとの接続はBLOBストレージと同じく「Import Data (旧名:Reader)」モジュールを使います。
※BLOBストレージとの接続については下記の記事をご参考ください。
「AZURE MACHINE LEARNING からBLOBストレージに接続してみる。」
http://azure-recipe.kc-cloud.jp/2016/02/azure-mlblob/
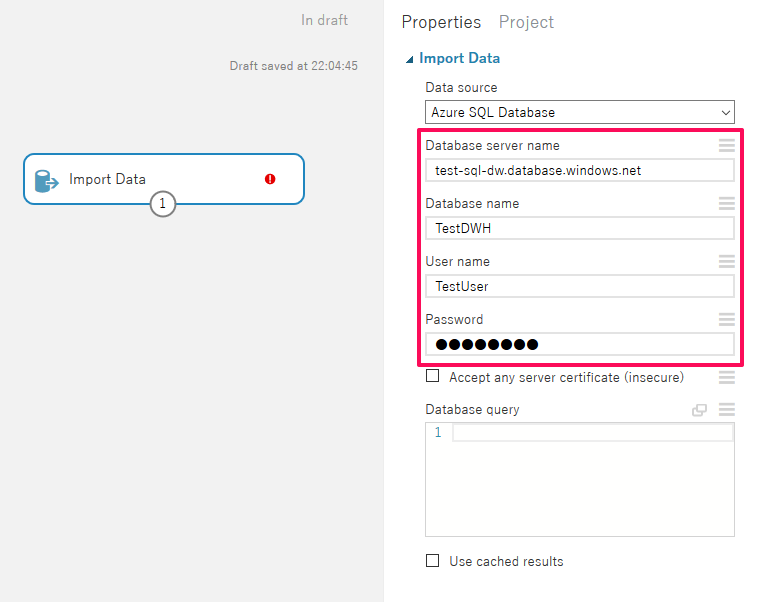
「Import Data」の「Data source」で「Azure SQL Database」を選択すると、データベースとの接続情報およびクエリの入力欄が表示されるため、まず下記4項目についてメモしておいた接続情報を入力します。
| 項目 | 入力内容 |
| Database sever name | サーバー名 |
| Database name | データベース名 |
| User name | サーバー管理者 |
| Password | ※サーバー作成時に設定したパスワード |
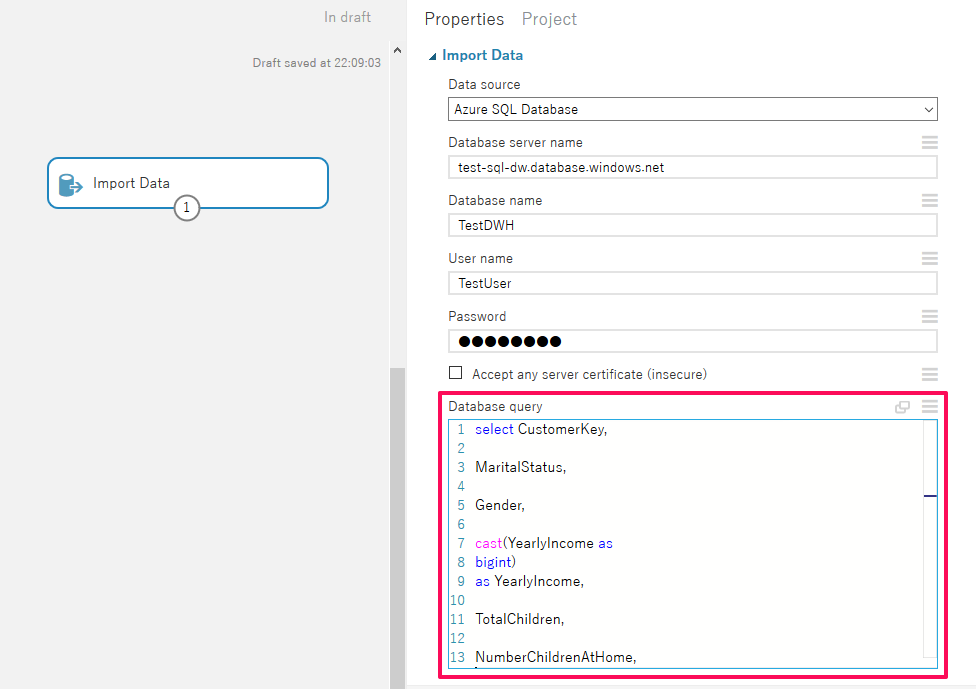
続いてデータベースからデータを取り出すクエリを入力します。
今回はSQL Data Warehouseのサンプル「AdventureWorksDW」を使用しているため、下記のクエリを入力しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
select CustomerKey, MaritalStatus, Gender, cast(YearlyIncome as bigint) as YearlyIncome, TotalChildren, NumberChildrenAtHome EnglishEducation, EnglishOccupation, HouseOwnerFlag, NumberCarsOwned, cast(Year(DateFirstPurchase) as varchar) + cast(Month(DateFirstPurchase) as varchar) as MonthofPurchase, CommuteDistance, Region, Age, BikeBuyer from dbo.vTargetMail; |
入力が終わったら「RUN」をクリックしてExperimentを実行し、接続確認を行います。
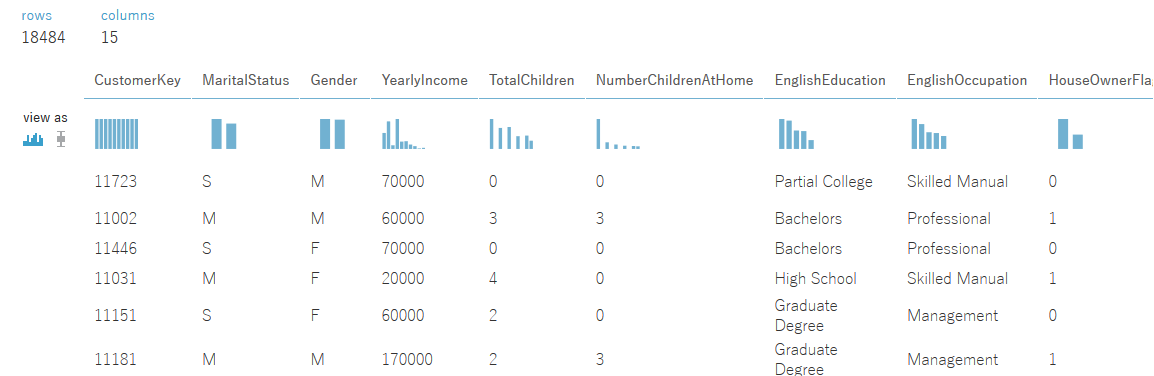
モジュールに緑のチェックが付けば接続成功です。モジュールを右クリックし、「Results Dataset」→「Visualize」を選択すると取得したデータが確認できます。
クラスタリング結果の出力
SQL DWからデータを取得できたので、取得データのクラスタリングをしてSQL DWに結果を出力してみます。
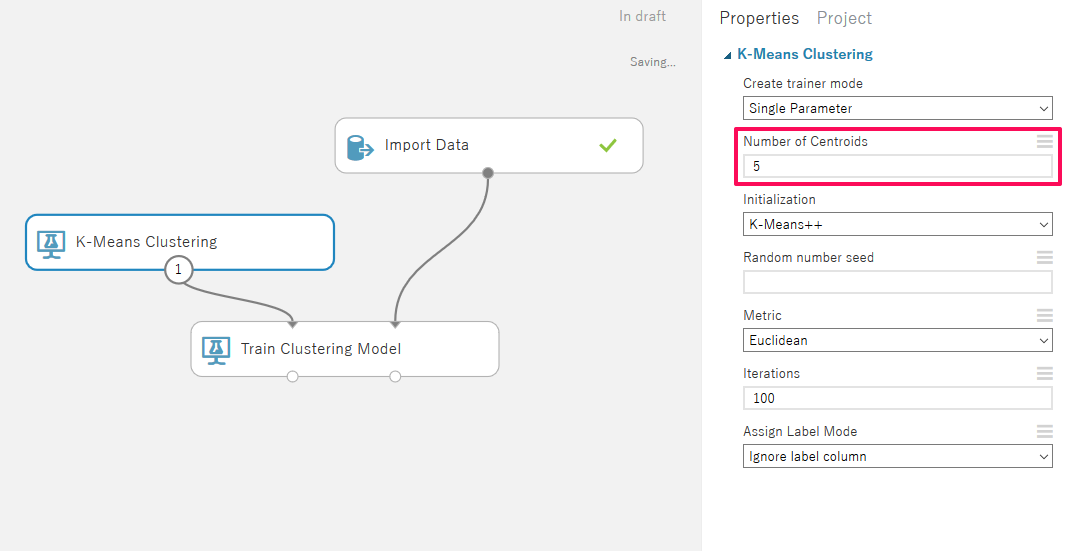
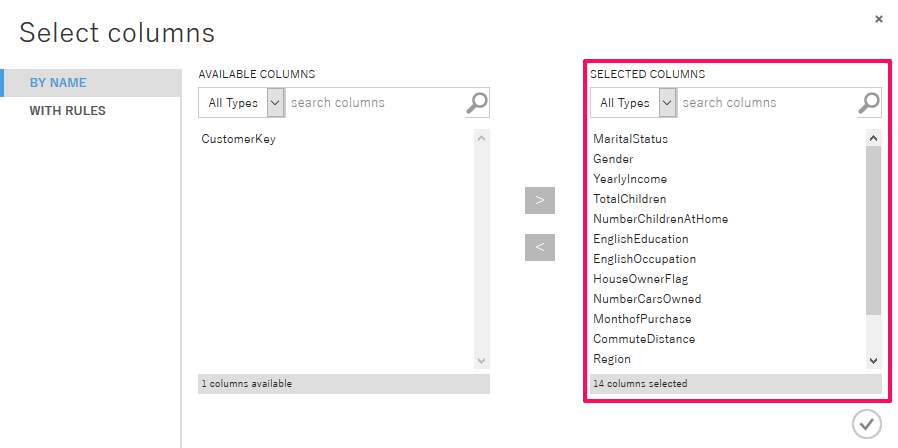
「K-Means Clustering」、「Train Clustering Model」を追加して簡単なクラスタリングモデルを構成し、「K-Means Clustering」の分類数を5、「Train Clustering Model」の参照パラメータを「CustomerKey」以外の全項目として設定します。
設定が終わったら、一度Experimentを実行して正常にクラスタリングができることを確認しておきます。
※Azure MLを使ったクラスタリングについては下記の記事もご参照ください。
「Azure Machine Learningでクラスタリングを試してみた。」
続いてSQL DWにクラスタリング結果を出力しますが、その前にSQL DWに出力用のテーブルを作成しておく必要があります。この操作はAzure ML上ではできないため、Visual Studioを使って行います。
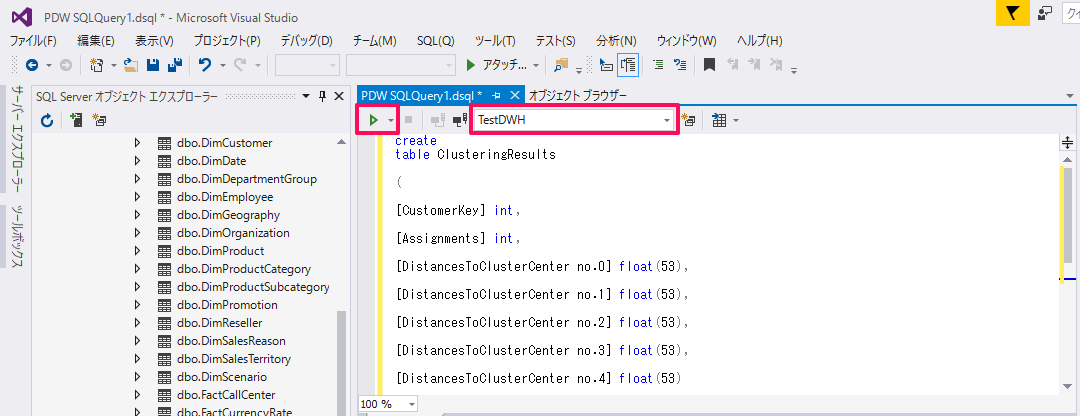
Visual StudioでSQL DWに接続したら、「SQL Serverオブジェクトエクスプローラー」上で該当のサーバーを右クリックし「新しいクエリ」を選択します。

クラスタリング結果はクラスタの割り当ておよびクラスタ重心までの距離が出力されるため、出力内容に合わせて下記のクエリを実行し、「ClusteringResults」というテーブル作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
create table ClusteringResults ( [CustomerKey] int, [Assignments] int, [DistancesToClusterCenter no.0] float(53), [DistancesToClusterCenter no.1] float(53), [DistancesToClusterCenter no.2] float(53), [DistancesToClusterCenter no.3] float(53), [DistancesToClusterCenter no.4] float(53) ) with (distribution=round_robin) |
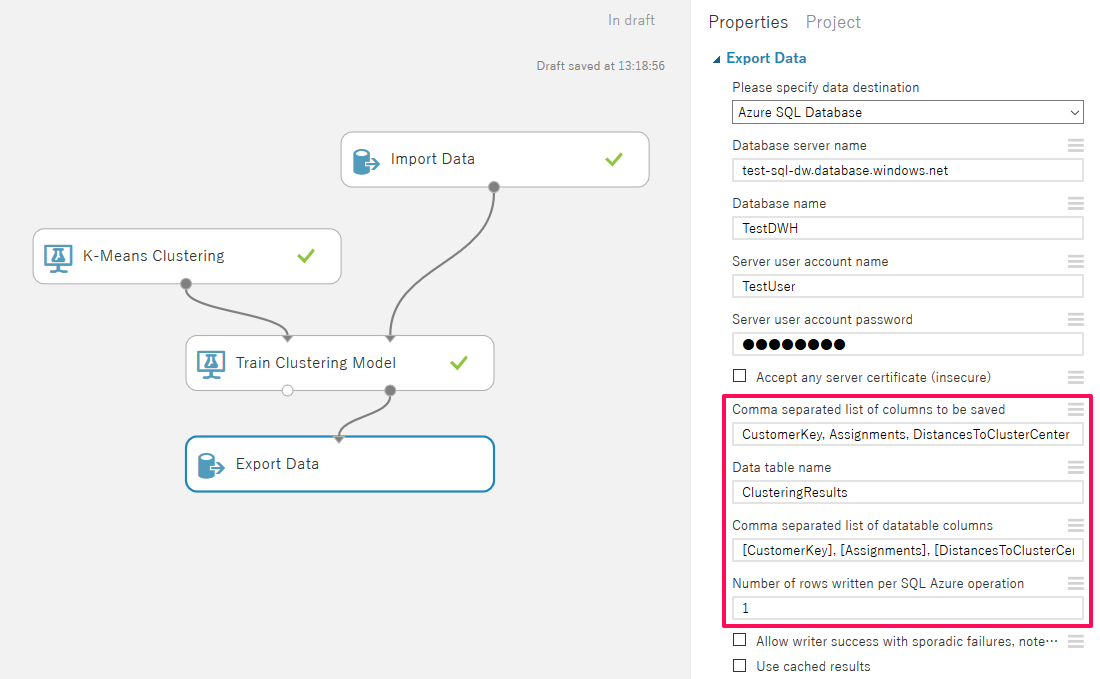
テーブルを作成したら、「Train Clustering Model」の「Results Dataset」コネクタから「Export Data (旧:Writer)」に接続します。
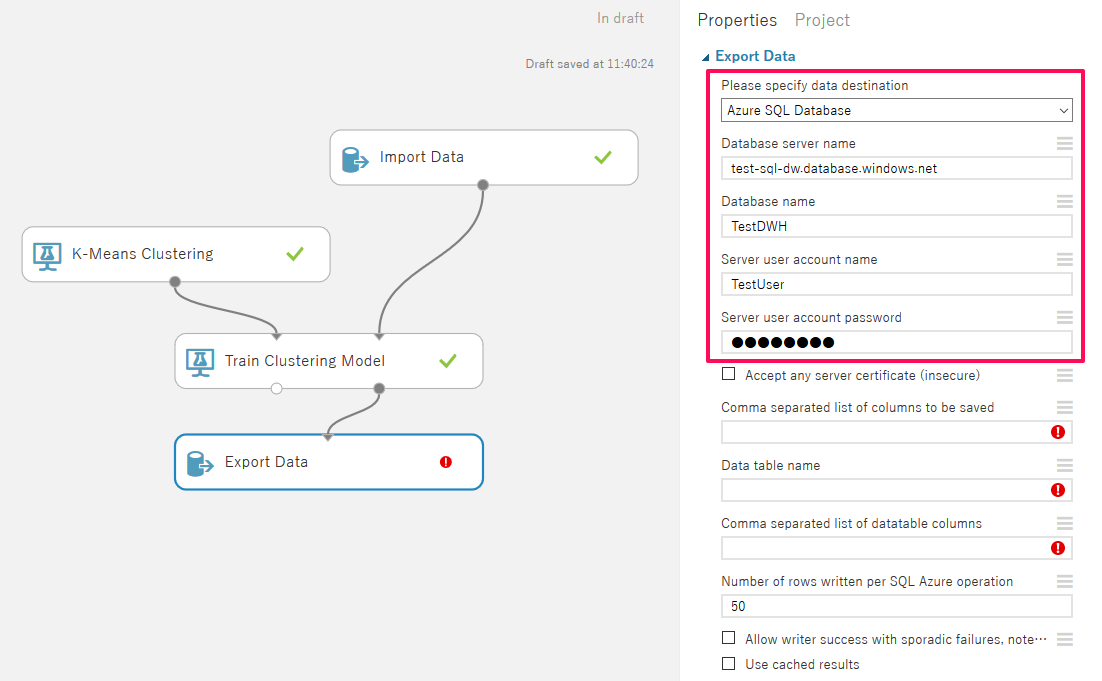
「Export Data」の「Please specify data destination」で「Azure SQL Database」を選択すると接続情報の入力欄が表示されるため、下記4項目について「Import Data」と同様に入力をします。
| 項目 | 入力内容 |
| Database sever name | サーバー名 |
| Database name | データベース名 |
| Server user account name | サーバー管理者 |
| Server user account password | ※サーバー作成時に設定したパスワード |
続いてその下の出力データとテーブルの情報を入力します。下記の4項目について出力したいデータと先ほど作成したテーブルの情報を入力します
| 項目 | 入力内容 |
| Comma separated list of columns to be saved | CustomerKey, Assignments, DistancesToClusterCenter no.0, DistancesToClusterCenter no.1, DistancesToClusterCenter no.2, DistancesToClusterCenter no.3, DistancesToClusterCenter no.4 |
| Data table name | ClusteringResults |
| Comma separated list of datatable columns | [CustomerKey], [Assignments], [DistancesToClusterCenter no.0], [DistancesToClusterCenter no.1], [DistancesToClusterCenter no.2], [DistancesToClusterCenter no.3], [DistancesToClusterCenter no.4] |
| Number of rows written per SQL Azure operation | 1 |
※ 「Export Data」を使ってSQL DWに出力を行う場合は「Number of rows written per SQL Azure operation」の値を必ず1に設定してください
すべて設定したら、「RUN」でExperimentを実行して結果の出力を行います。
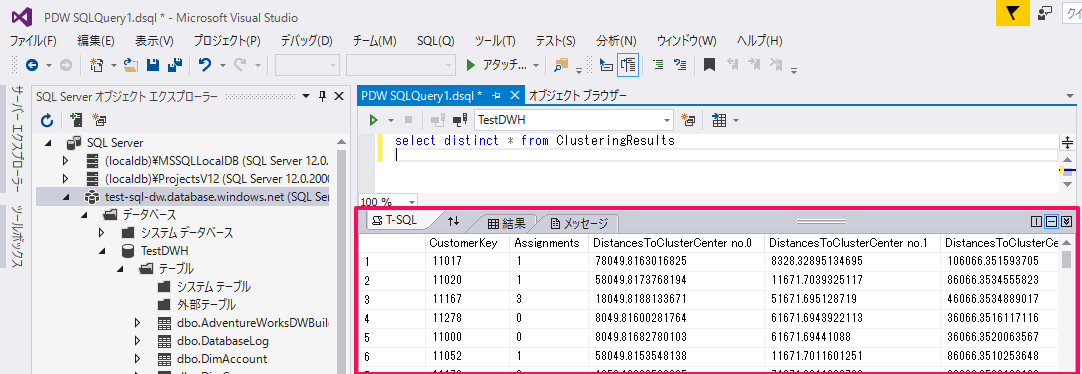
出力内容については、Visual Studioで下記のクエリを実行することで確認できます。
|
1 |
select distinct * from ClusteringResults |
いかがでしたでしょうか。
Azure MLでは様々なストレージと連携してデータ分析を行うことができるので、データが溜まっているけど分析ができていないという場合には是非お試し下さい。
次回もお楽しみに!!
