
はじめに
この記事は株式会社ナレッジコミュニケーションが運営するチャットボット と AIエージェント Advent Calendar 2025 の16日目にあたる記事になります!
RAG(Retrieval-Augmented Generation)のPoCを始めると、ほぼ確実にぶつかる壁があります。
それは「必要な情報が1か所にない」という現実です。
- 業務マニュアルは SharePoint のファイルサーバーにある
- 最新の仕様書は Box や Blob Storage にある
- 過去のトラブルシューティングは ServiceNow や社内Wikiにある
- 構造化データは OneLake や SQL Database にある
この状態で「社内向けの回答AI」を作ろうとすると、情報源ごとに個別のRAG取り込み・検索・権限制御を実装しがちです。
そしてソースが増えるほど、運用が指数関数的に難しくなります。
本記事では、Foundry IQ(Foundryポータル上の Knowledge Base 体験)と、その背後にある Azure AI Search の Knowledge Source / Knowledge Base(agentic retrieval) の公式説明を手がかりに、マルチソースを“運用できる形”に束ねる設計 について整理します。
注意
本記事は 2025-12-15時点で公開されている Microsoft 公式情報を参照して整理しています。
Knowledge Base / Knowledge Source を含む agentic retrieval は パブリック プレビューとして案内されており、SLAなし・仕様/制限/課金・UI/用語が変わる可能性があります。
導入前に必ず最新ドキュメントを確認してください。
概要
- マルチソースRAGの本番化が止まりがちなのは、精度以前に 取り込みパイプライン増殖・検索ルーティング・権限がアプリ側に溜まって運用破綻するから。
- Foundry IQ / Azure AI Search の Knowledge Base は、複数の Knowledge Source を束ねて「検索(retrieval)責務」を再利用可能に切り出す設計である。
- 設計の勘所は (1) Indexed / Remote の切り分け と (2) Knowledge Base を束ねる/分ける判断(権限境界・ドメイン・SLA・ノイズ) である。
用語ミニ辞典
- Knowledge Source: 「何を検索するか」。検索対象の“入れ物”や接続先(既存インデックス / Blob / OneLake / SharePoint / Web など)。
- Knowledge Base: 「どう検索するか」。クエリ計画、サブクエリ分解、並列検索、ランキング、統合、(必要なら)回答合成までをオーケストレーション。
- Indexed / Remote
- Indexed: Azure AI Search 上のインデックスに対して検索(keyword/vector/hybrid 等)を行う。
- Remote: クエリ時に外部API(例: SharePoint / Bing)を呼び出して取得し、Search側でマージ&再ランク付けを行う。
用語の揺れに注意
ドキュメントやAPIバージョンにより表現が揺れる場合があります。
例: 「knowledge agent ↔ knowledge base」
1. “ソースごとにRAGを作る”が辛い理由
企業の情報が目的に応じて分散しているのは自然なことです。
問題は、RAGを「アプリ都合」で組み始めると、次の負債が増えやすいことです。
1-1. パイプラインが増殖する(しかも重複する)
SharePoint用、Blob用、OneLake用…と、取り込み・チャンク分割・埋め込み・更新のパイプラインが増えます。
- 似た処理(取り込み/チャンク/embedding/再取り込み)なのに、運用は別物になりがち
- 障害対応もソースごと(「SharePointは更新できたがBlobは失敗」など)
- 精度改善のループ(評価→改善)より、基盤維持に時間が吸われる
1-2. ルーティング問題:どこを検索するか決め続ける必要がある
ユーザーの質問に対して、
- 「SharePointだけ検索する」
- 「BlobとOneLakeを両方検索してマージする」
- 「まず社内、足りなければWebで補う」
といった“検索戦略”が発生します。これをアプリに押し込むほど、要件変更で実装が肥大化します。
1-3. 権限が最大の問題になる
特にSharePointのように細かいアクセス制御(ACL)がある場合、検索結果に「見えてはいけない」内容が混ざる事故は致命的です。
データソースが増えるほど、権限同期・監査・例外処理の難易度は上がります。
2. Foundry IQの整理:Knowledge Source と Knowledge Base
Foundry IQ は、一言でいうと
「検索(retrieval)の責務を、アプリケーションから切り離して再利用可能にする」
という方向性のものとなっています。
Tech Communityの紹介では、単一のKnowledge Baseを複数のエージェント/アプリから利用でき、背後で indexed / remote の複数ソースを束ねる、という絵が描かれています。
2-1. Knowledge Source(何を検索するか)
Knowledge Source は、agentic retrievalで使う検索対象を定義するトップレベルリソースです。
公式ドキュメント上は、(少なくとも)以下の種類が案内されています(今後増える可能性あり)。
- 既存インデックスを包む(searchIndex)
- Blob から取り込み生成(azureBlob)
- OneLake から取り込み生成(indexedOneLake)
- SharePoint を取り込み生成(indexedSharePoint)
- SharePoint をクエリ時に直接取得(remoteSharePoint)
- Web(Bing)をクエリ時に取得(webParameters)
ポイントは、「ソース追加=アプリ改修」ではなく、「Knowledge Sourceを追加する」方向に寄せられることです。
2-2. Knowledge Base(どう検索するか)
Knowledge Base は、Knowledge Source と LLM を組み合わせて agentic retrieval を実行するオーケストレーターです。
- クエリを計画し、サブクエリに分解
- 複数ソースに並列検索
- セマンティック再ランク等で統合
- 引用(source reference)を付けて返す
- さらに「回答合成(answer synthesis)」までやる/やらないを選べる
Foundry Agent Service とつなぐ場合、公式手順では「Knowledge Base側で回答を作り切る」より、抽出結果(verbatimな根拠)を返して、最終回答はエージェント側で組み立てる設計が推奨されています(=責務境界を明確にしやすい)。
2-3. 概念図(イメージ)
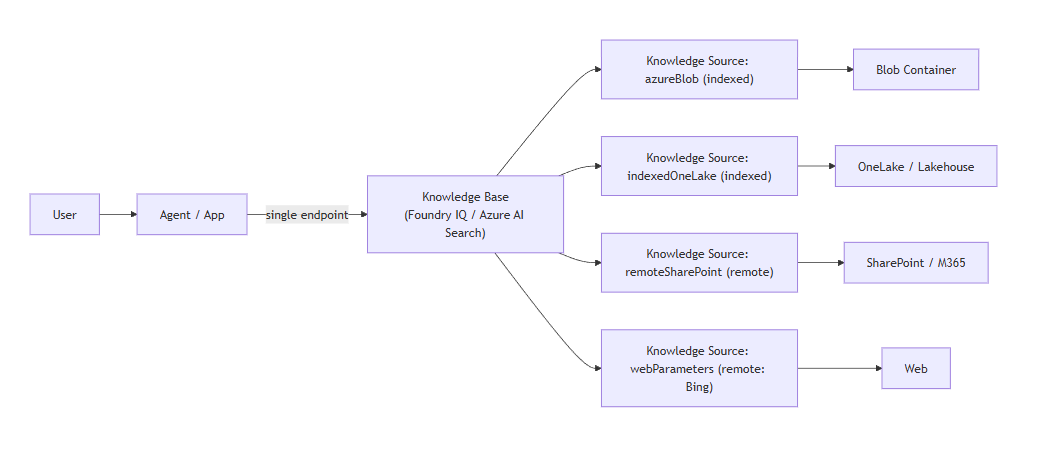
3. Indexed / Remote の違い
Knowledge Source は大きく Indexed と Remote に分かれます。違いは「検索の実行場所」と「運用負債の種類」です。
3-1. Indexed(インデックスを作ってSearchで検索)
- 取得は Azure AI Search の検索機能(keyword / vector / hybrid)を使う
- 一部のKnowledge Sourceでは、インデックス作成パイプライン(取り込み・チャンク・ベクトル化等)を自動生成する流れが用意されている
- 一方で「鮮度」「再取り込み」「削除」「インデックス容量」「スキーマ変更」など、運用が“検索基盤寄り”になる
向いている例:
- 更新頻度が低い/中程度のドキュメント(PDF、規程、手順書)
- レイテンシを安定させたい領域
- 検索ランキングやフィールド設計を作り込みたい領域
3-2. Remote(クエリ時に外部APIで取得)
- クエリ時に外部API(例: SharePoint / Bing)を呼ぶ
- “常に最新”に寄せやすい一方で、外部側の制限・レイテンシ・課金/ライセンスが設計に効く
向いている例:
- 「最新性」が価値の中心(Web grounding、常時更新されるM365コンテンツ)
- 権限モデルを“元システムのアイデンティティ”に寄せたい(後述)
SharePoint(Remote)は便利ですが、設計前に 制限と課金要件を必ず見ておくべきです。
公式ドキュメントでは、たとえば以下のような点が明記されています。
- Copilot Retrieval API を使って テキストを直接取得(検索インデックスは使わない)
- ユーザーIDの代理で呼び出され、SharePoint権限や Purview ラベルが尊重される
- Microsoft 365 側(Copilotライセンス)で課金される
- 取得対象/ファイル種別/回数などの制限(例: 200 req/user/hour、ハイブリッド対象拡張子、非テキスト要素は非対応 など)
つまり「Remoteにしたから全部解決」ではなく、“権限は楽になるが、制限とコストの設計が必要” という判断になります。
4. Knowledge Base を「束ねる?分ける?」
マルチソースRAGの“設計”は、最終的にここに集約されます。
4-1. まず「分ける理由」があるかをチェックする
Knowledge Base を分ける典型理由(よくある順):
- 権限境界が違う(人事/法務/経営など)
- ドメインが違う(開発ナレッジ vs 営業ナレッジ)
- 更新頻度・SLAが違う(静的マニュアル vs 日次更新データ)
- 検索ノイズが許容できない(1つに束ねると精度が落ちる)
4-2. 束ねるのが効く条件
一方で束ねると強い条件もあります。
- 1つの業務フローで複数ソースを“跨ぐ”質問が多い
- 「どこにあるか」をユーザーに意識させたくない
- 取り込み・ルーティングを各チームで作りたくない
- 1つのKnowledge Baseを複数アプリ/エージェントで再利用したい(横展開したい)
4-3. 判断チェックリスト
例えば、以下のようなチェックリストで「束ねるか、分けるか」を決めることができます。
- 権限境界が明確に違う(人事/法務/経営)→ 分ける
- 同じ業務フローで複数ソースを跨ぐ → 束ねる
- 更新頻度/SLAが極端に違う → 分ける(運用を単純化)
- 束ねるとノイズ増で精度が落ちそう → 分ける or 絞り込み設計
- 複数アプリからretrievalを共通利用したい → 束ねる
5. “運用できるマルチソース”にするための設計メモ
最後に、Foundry IQ / Knowledge Base を前提にしても、設計する際に押さえるべき論点をまとめます。
5-1. 権限(最優先)
- Remote(SharePoint等)を使うなら
- 「ユーザーIDで呼ばれる」「元の権限やラベルが尊重される」設計は取りやすい
- 代わりにライセンス/制限、テナント条件などを満たす必要がある
- Indexed を使うなら
- “インデックス側で見せてよい結果だけ返す”ための設計(ACL/メタデータ/フィルタ)を要検討
- 監査ログ・例外運用(退職者、異動、外部共有等)の設計が後から効く
5-2. 鮮度(更新頻度と期待値のすり合わせ)
- Indexed は「速い・安定」になりやすい一方、鮮度は取り込み設計に依存
- Remote は鮮度は良いが、レイテンシとクォータの影響を受ける
5-3. コストとレイテンシ(“束ねれば束ねるほど”増えやすい)
- Knowledge Base は複数ソースへファンアウトするため、ソース数や難問が増えるほどコスト/時間が増えやすい
- agentic retrieval には(少なくとも)検索側とLLM側の課金軸があるため、**「どの質問を、どの努力量で解くか」**の設計が必要
5-4. 検索品質(命名・説明が効く)
Foundry IQの評価記事では、難問ほど「複数ソース横断」「クエリ計画」「反射的再検索」といった要素で改善が出る旨が示されています。
やりがちな失敗として、「ソース名や説明が長すぎて、逆に選択がブレる」問題もあるため、 Knowledge Sourceの命名と説明は“設計パラメータ” として扱うのが安全です。
まとめ:RAGは「作る」から「設計して繋ぐ」フェーズへ
マルチソースRAGは、手組みでやろうとすると「インフラ構築とパイプライン維持」に時間を割くことになり、肝心の「回答精度の向上」に時間を使えなくなりがちです。
Foundry IQ の登場により、検索(retrieval)を再利用可能な部品として切り出しやすくなったことで、エンジニアの主戦場は
- どのデータを
- どの方式(Indexed/Remote)で接続し
- どの権限境界で束ね/分け
- どの品質・コスト・鮮度のトレードオフで運用するか
という アーキテクチャ設計 へとシフトしていくと考えられます。
参考文献
- Foundry IQ: Unlock knowledge retrieval for agents, by Azure AI Search(Microsoft Tech Community)
- Foundry IQ: boost response relevance by 36% with agentic retrieval(Microsoft Tech Community)
- Foundry IQ ナレッジ ベースを Foundry Agent Service に接続する(Microsoft Learn)
- What is a knowledge source?(Azure AI Search / Microsoft Learn)
- Create a Knowledge Base(Azure AI Search / Microsoft Learn)
- Create a remote SharePoint knowledge source(Azure AI Search / Microsoft Learn)
- (補足)Quickstart: Use Agentic Retrieval in the Azure portal(Azure AI Search / Microsoft Learn)
- (補足)Create an index for agentic retrieval(Azure AI Search / Microsoft Learn)
