はじめに
今回は初、Databricksに触れていきます。
機械学習の構築で難しいところは、データソースに欠損値が含まれていたり、メモリに収まらない可能性があることです。
さらに、アルゴリズムの知識だけでなく、マシンアーキテクチャと分散システムの知識も必要とされます。
Databricksを使う良さ
Databricks はそんな気難しい機械学習プロセスを、簡略化します。
表形式のデータで、機械学習モデルをトレーニングするエンドツーエンドの例をチュートリアルでやっていきます。
手順について
このチュートリアルでは、次の手順について説明します。
- ローカルマシンから、Databricksファイルシステム(DBFS)にデータをインポートする
- Seabornとmatplotlibを使用して、データを視覚化する
- 並列ハイパーパラメータースイープを実行して、データセットで機械学習モデルをトレーニングする
- MLflowを使用して、ハイパーパラメータースイープの結果を調べる
- MLflowで最もパフォーマンスの高いモデルを登録する
- Spark UDFを使用して、登録済みモデルを別のデータセットに適用する
この例では、ワインの物理化学的特性に基づいて、ポルトガルの 『Vinho Verde』ワインの品質を予測するモデルを作成します。
物理化学的特性からの、データマイニングによるワインの好みのモデリング [Cortez et al。2009] に示されている
『UCI Machine Learning Repository』のデータセットを使用しています。
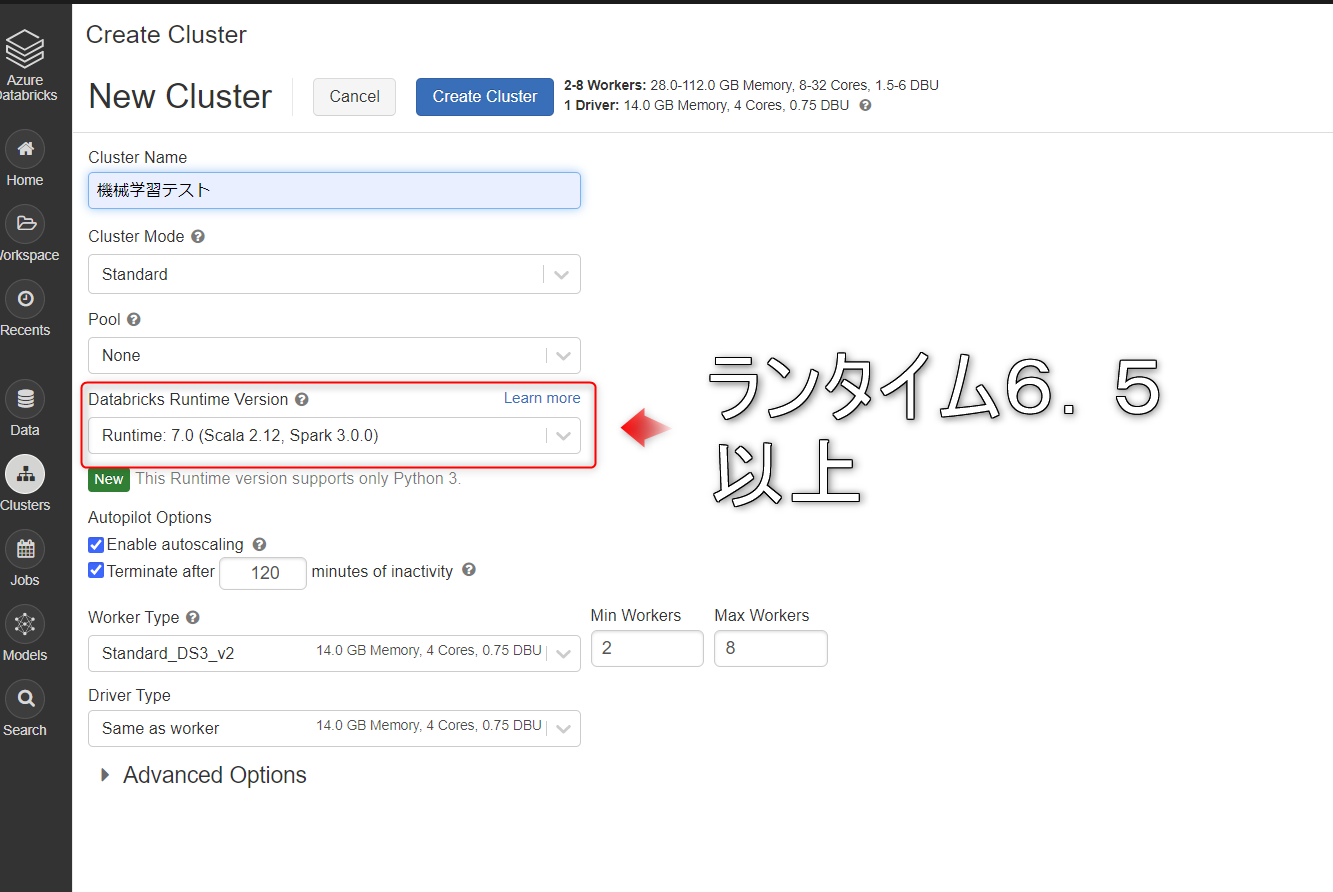
クラスターの起動
Databricksランタイム6.5 ML以上を実行しているPython 3クラスターを起動します。
ファイルのアップ
このセクションでは、Webからデータセットをダウンロードして、Databricksファイルシステム(DBFS)にアップロードします。
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
この両方をダウンロードします。
[winequality-red.csv][winequality-white.csv]
このDatabricksノートブックから、[ ファイル] >>[ データのアップロード]を選択し、このファイルをドラッグアンドドロップターゲットにドラッグして、DBFSにアップロードします。
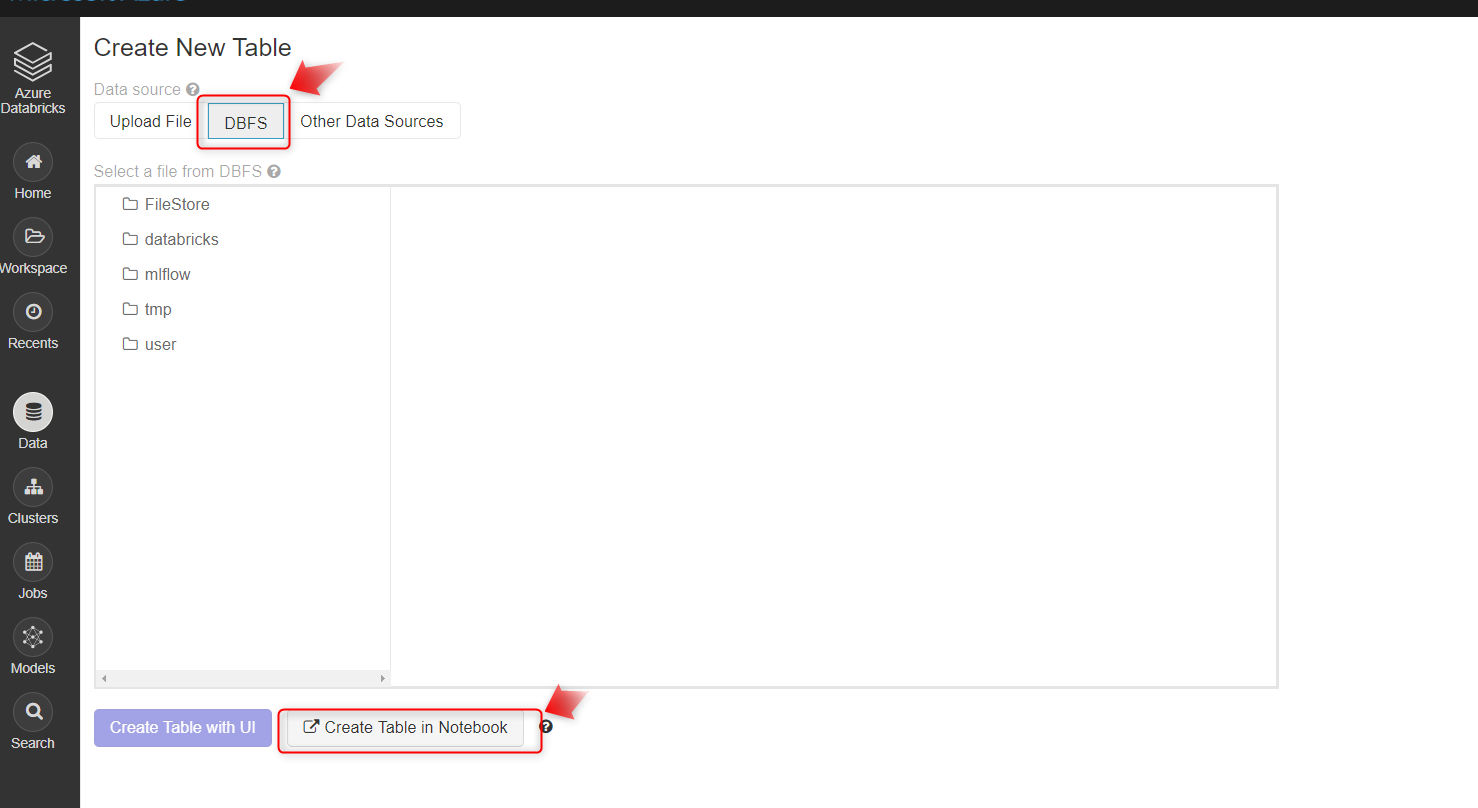
[ファイル] >>[ データのアップロード ]オプションがない場合は、Databricksサンプルデータセットからデータセットをロードできます。
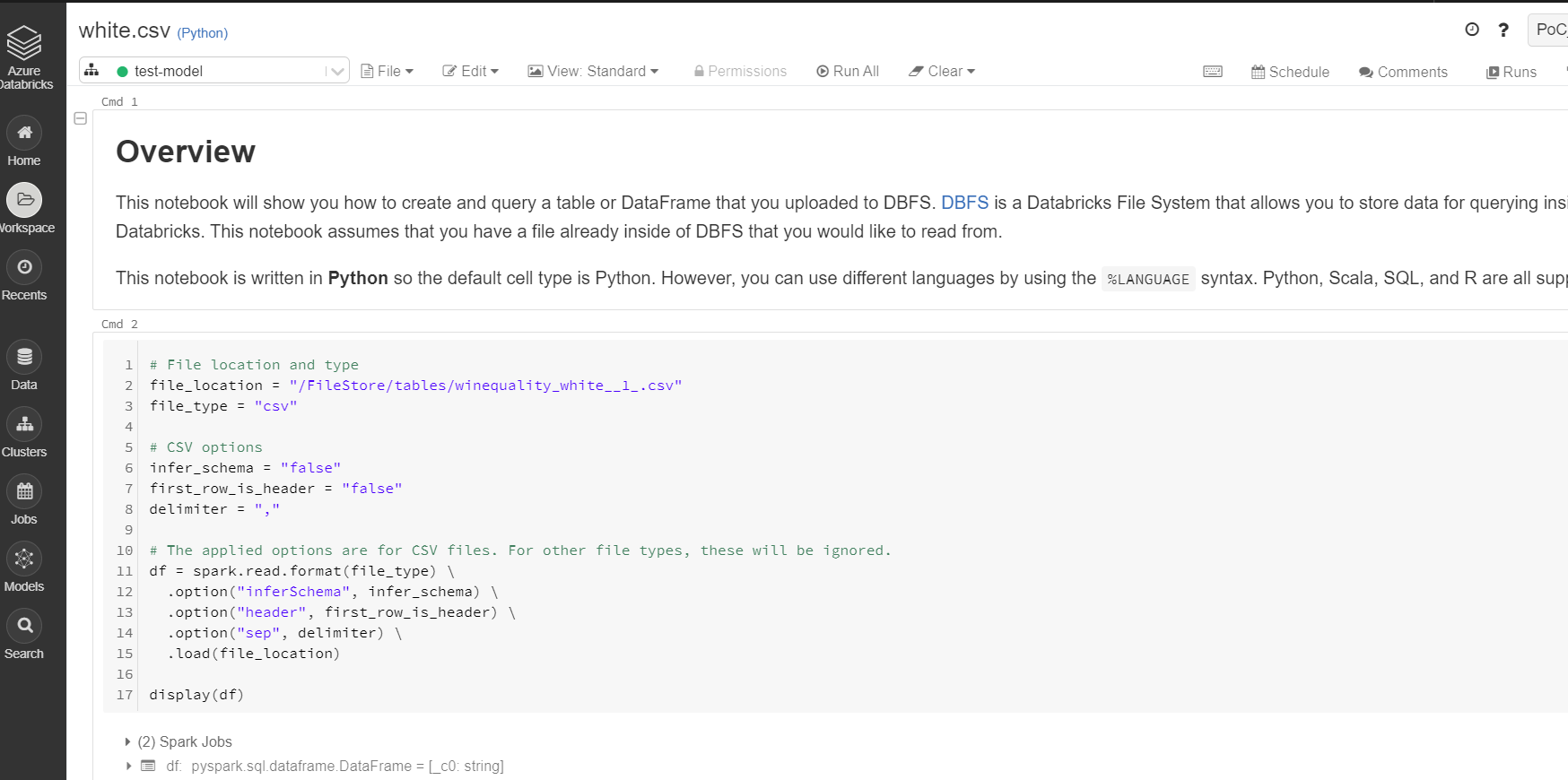
コードの最後の2行をコメント解除して実行します。
データをロードするための自動生成コードが表示されます。
データをマージする
pandasをインポートし、サンプルコードをコピーします。
新しいセルにコードを貼り付けます。
[ファイル]>>[データのアップロード]メニューオプションがある場合は、前のセルの指示に従って、ローカルマシンからデータをアップロードします。
pandas を pd としてインポートします。
次の行で、『username』をユーザー名に置き換えます。
|
1 2 3 4 5 6 7 8 9 |
import pandas as pd white_wine = pd.read_csv("/dbfs/FileStore/shared_uploads/<username>/winequality_white.csv", sep=';') red_wine = pd.read_csv("/dbfs/FileStore/shared_uploads/<username>/winequality_red.csv", sep=';') # [ファイル]> [データのアップロード]メニューオプションがない場合は、これらの行のコメントを外して実行し、データセットをロードします。 #white_wine = pd.read_csv ("/ dbfs / databricks-datasets / wine-quality / winequality-white.csv", sep = ";") #red_wine = pd.read_csv ("/ dbfs / databricks-datasets / wine-quality /winequality-red.csv", sep= ";") |
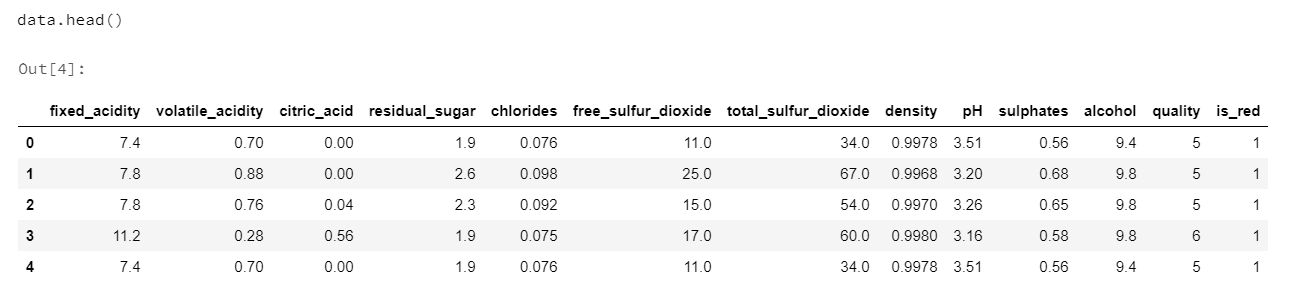
ワインが赤か白かを示す新しいバイナリ機能「is_red」を使用して、2つのデータフレームを1つのデータセットにまとめます。
|
1 2 3 4 5 6 7 |
red_wine ['is_red'] = 1 white_wine ['is_red'] = 0 data = pd. concat ([ red_wine, white_wine ], axis = 0) # Remove spaces from column name data. Rename (column = lambda x: x. Replace ('','_'), In Place = True) |
データを可視化する
モデルをトレーニングする前に、Seaborn と Matplotlib を使用してデータセットを探索します。
従属変数(関数 y =f (x )において、独立変数 x の変化に応じて変わる y をいう語。)である、品質のヒストグラムをプロットします。
|
1 2 |
import seaborn as sns sns.distplot(data.quality, kde=False) |
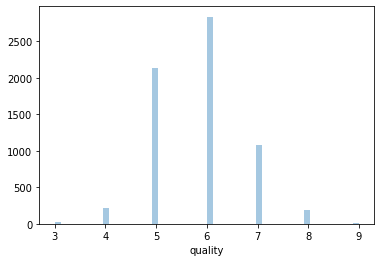
品質スコアは通常3から9の間に分布しているようです。
品質が7以上のワインを高品質と定義します。
|
1 2 |
high_quality = ( data . quality >= 7 ) . astype ( int ) data . Quality = high_quality |
ボックスプロットは、特徴とバイナリラベルの間の相関関係を知るのに役立ちます。
matplotlibをインポートします。
pyplot として PLT と記します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import matplotlib.pyplot as plt dims = (3, 4) f, axes = plt.subplots(dims[0], dims[1], figsize=(25, 15)) axis_i, axis_j = 0, 0 for col in data.columns: if col == 'is_red' or col == 'quality': continue # Box plots cannot be used on indicator variables sns.boxplot(x=high_quality, y=data[col], ax=axes[axis_i, axis_j]) axis_j += 1 if axis_j == dims[1]: axis_i += 1 axis_j = 0 |
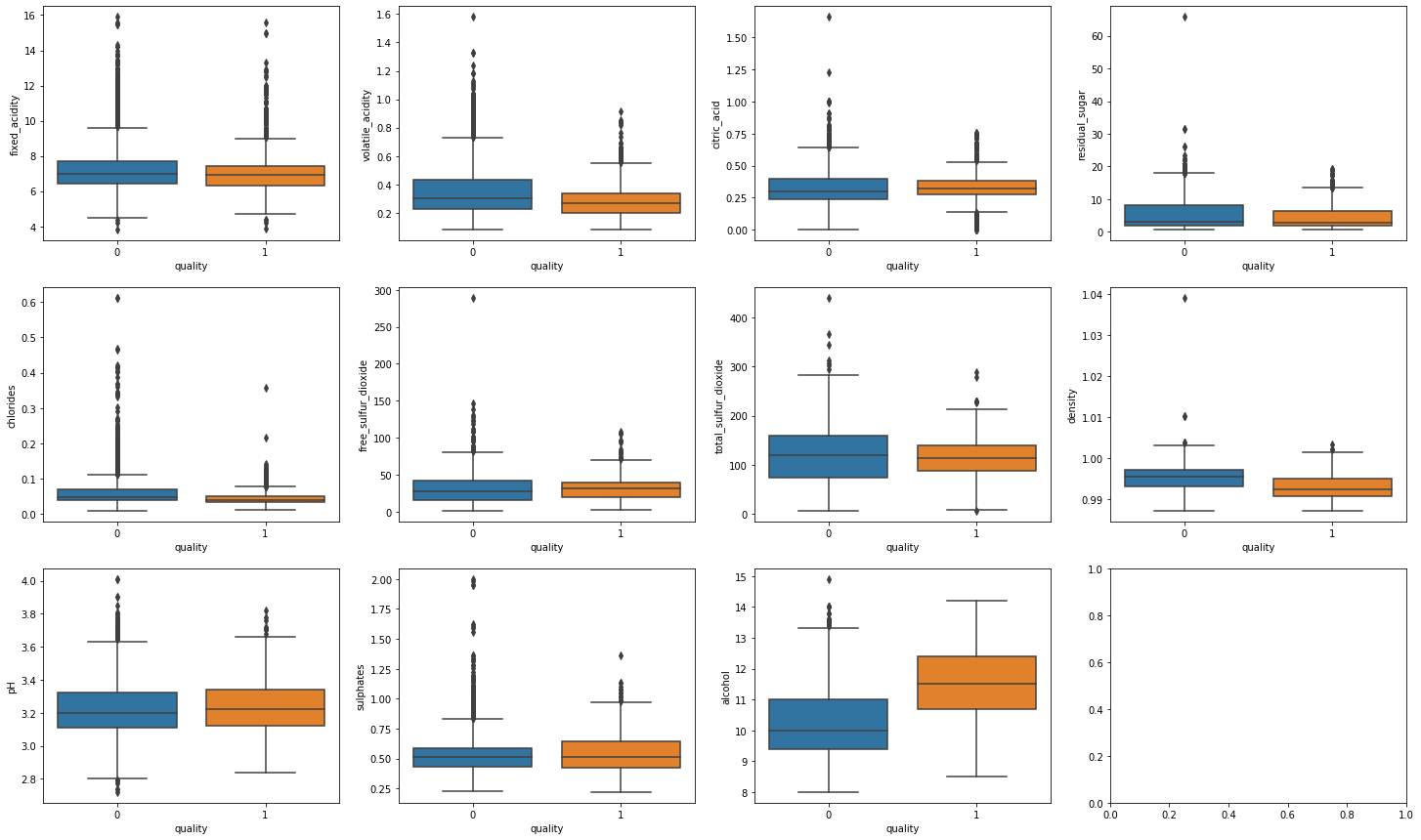
上記の箱ひげ図では、いくつかの変数が品質の一変量予測子として際立っています。
アルコールボックスプロット
- 高品質ワインのアルコール度数の中央値は、低品質ワインの75分位よりも高くなっています。 高アルコール含有量は品質と相関しています。
密度ボックスプロット
- 低品質のワインは高品質のワインよりも密度が高くなっています。 密度は品質と反比例します。
では2に続きます。
