はじめに
Delta Lake について、下記のリンク先の記事と動画を参考に、内容を翻訳してまとめてみました。
本記事にはより詳細な内容が記載されているので、そちらも参照してください。
■リンク
Delta Lake について
Delta Lake とは
Delta Lake はデータレイクに信頼性をもたらすオープンソースのストラテジレイヤです。
Delta Lake を利用するメリットとしては、3つ挙げられます。
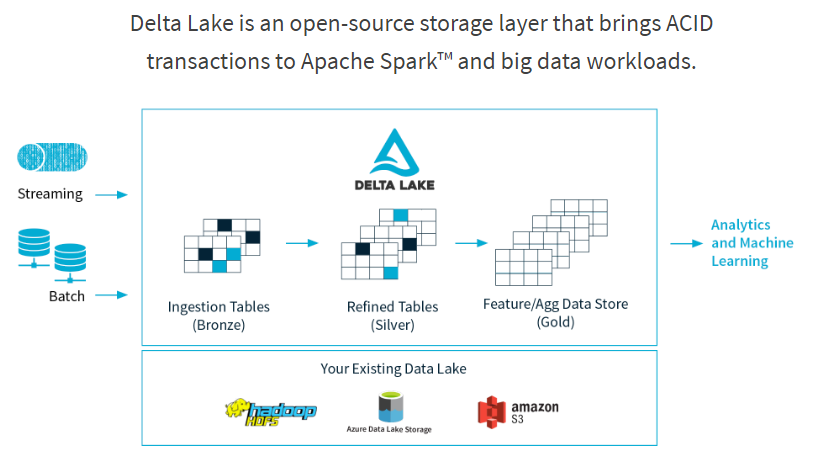
Delta Lake の特徴
Delta Lake には、ユーザが快適に利用できるよう10の機能があります。
■Delta Lake の10の機能
- ACID トランザクション
- ACID トランザクションをデータレイクに提供
- 最強の分離レベルであるシリアライザビリティを提供
- スケーラブルなメタデータのハンドリング
- Spark の分散プロセス力を利用して、数十億のファイルを持つペタバイト規模のテーブルの全てのメタデータを簡単に処理可能
- タイムトラベル(データのバージョニング)
- ロールバックや監査証跡の全履歴、そして再現可能な機械学習実験などがデータのバージョニングで可能
- オープンフォーマット
- Delta Lake の全データを ApacheParquet 形式で保存
- Parquet にとってネイティブな効率的な圧縮とエンコーディングスキームを提供
- 統一されたバッチとストリーミングのソースとシンク
- Delta Lake のテーブルはバッチテーブルでもあると同時に、ストリーミングソースやシンクでもある
- ストリーミングデータの読み込み、バッチ履歴の埋戻し、対話型クエリをそのまま使用可能
- スキーマの実施
- Delta Lake はスキーマを指定して実行する機能を提供
- 不良データによるデータ破損を回避し、正しいデータタイプとカラムの存在を確認することが可能
- スキーマの進化
- Delta Lake デーブルスキーマに変更を加え、自動的に適用される
- DDLといった面倒は不要
- 監査履歴
- Delta Lake のトランザクションログは、データに関するあらゆる変更履歴を記録
- 完全な監査証跡も提供
- アップデートと削除
- データセットのマージ・更新・削除する Scala/Java API のサポート
- GDPR と CCPA に簡単に準拠でき、変更データキャプチャなどのユースケースも簡素化可能
- Apache Spark API との 100% の互換性
- 大規模データ処理エンジンとして利用される Spark と完全互換性
- Delta Lake を最小限の変更で既存のデータパイプラインと利用が可能
Data Lake と Delta Lake の違い
下記は、Data Lake と Delta Lake の違いを図に表したものです。
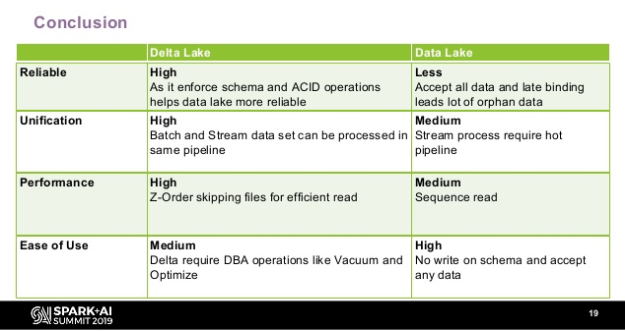
- 信頼性
- Delta Lake:高(スキーマの ACID 操作を強化することでデータの信頼性を高める)
- Data Lake:低(あらゆるデータを許可し、結合も遅いため、大量の孤立したデータが生まれる)
- 統一性
- Delta Lake:高(バッチやストリームデータを同一のパイプラインで生成可能)
- Data Lake:低(ストリーミングプロセスにはホットパイプランが必須)
- パフォーマンス
- Delta Lake:高(Zオーダスキッピングファイルで効率的な読み取り)
- Data Lake:中(シーケンス読み取り)
- 使いやすさ
- Delta Lake:中(DBA オペレーションを求められる)
- Data Lake:高(スキーマへの記述も不要で、どのようなデータも許可)
信頼性、統一性、パフォーマンス、使いやすさ、の4項目でそれぞれ比較した結果、Delta Lake の方がData Lake に比べてより優れているのがわかります。
おわりに
Delta Lake に関する説明は以上となります。
より詳細な内容については、リンク先の記事等を参照ください。
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
