はじめに
今回は、Michael Armbrust 氏による「Data Reliability for Data Lakes」の動画を翻訳し、まとめてみました。
本動画については、下記リンク先参照でお願いします。
■リンク
・ Delta Lake – Open Source Reliability for Data Lakes
Data Lake について
Data Lake の現状
現在、様々な企業が Apache Spark を用いて、Data Lake にデータを置き、データサイエンスや機械学習のプロジェクトなどに利用してきました。
■Data Lake を利用する3つの理由
- とても安価に利用可能
- スケーラブル
- 置いたデータを様々な用途で利用可能
しかし、Data Lake を利用するにあたって、ある問題が発生しております。それは、Data Lake に置いてあるデータが整理されていない為、プロジェクトの進行が阻まれるという事態です。信頼性の低いデータの存在により、様々なプロジェクトが生まれては失敗で終わるという事態が実際に起きてます。

Data Lake を用いたプロジェクトの進め方
図は一般的な Data Lake を用いたプロジェクトの進め方です。
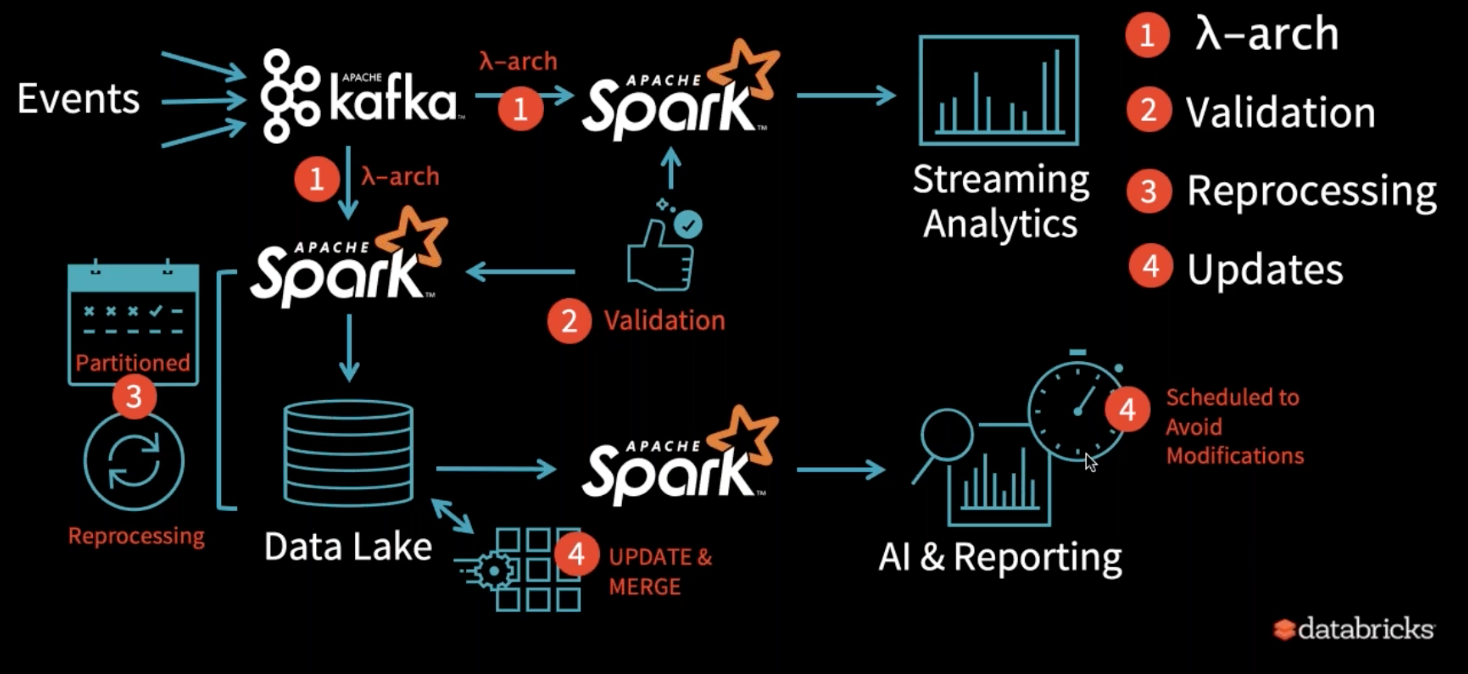
■プロジェクトのポイント
①λ-arch を構築
②検証アーキテクチャの構築
③Data Lake の再処理(不純なデータが無いか確認)
④アップデートの実施
実際にプロジェクトを進めていくにあたり重要なポイントは4つですが、図のような構成を組む必要がある為、プロジェクトを順調に進めるのは簡単ではありません。Data Lake において、データの信頼性を維持するのはとても難しく、その理由は3つあります。

■複雑な構成になる3つの理由
- ジョブの失敗
- 破損したままのデータの放置は復旧に多くの時間が必要
- 品質の低下
- 矛盾した不整合データの生成
- トランザクション不足
- アペンドや読み込み、バッチやストリーミングの実行がほぼ不可能
Delta Lake について
Delta Lake を用いたプロジェクトの進め方
それでは、Delta Lake を用いた場合はどうなるでしょうか。
Delta Lake を用いた場合は、Data Lake の時の構成とはだいぶ異なり、プロジェクトの進め方は図の様になります。
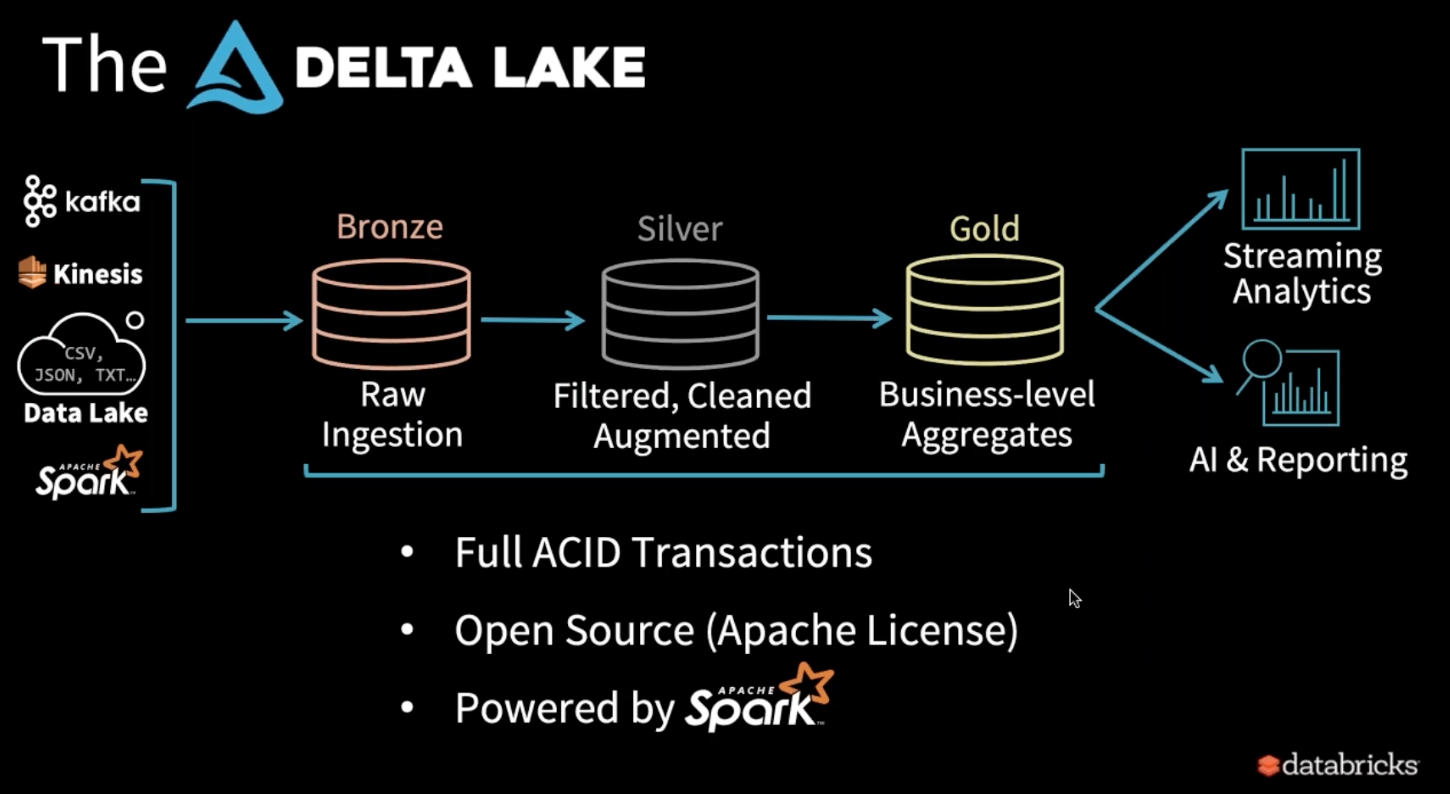
Delta Lake の一番の特徴は、データを利用するまでデータの品質を向上させることが可能という点です。
それを可能にしているのが、Delta Lake の下記の3つの特徴です。
- フル ACID トランザクション
- オープンソース
- Apache Spark を利用
Delta Lake の場合、図のように「Bronze」、「Silver」、「Gold」といった3つの段階を踏んでおります。
それぞれの段階における内容についてまとめました。
- Bronze
- 生データの摂取と、最小限の構文解析
- 数年にわたる長期保存が可能
- Silver
- データのフィルタリングやクレンジング、強化などを適用した中間データ
- 簡単にデバッギングできるようクエリが可能
- Gold
- 実行可能な綺麗なデータ(BI や ML での利用も可能な状態)
- Spark や Presto で利用可能な状態のデータ
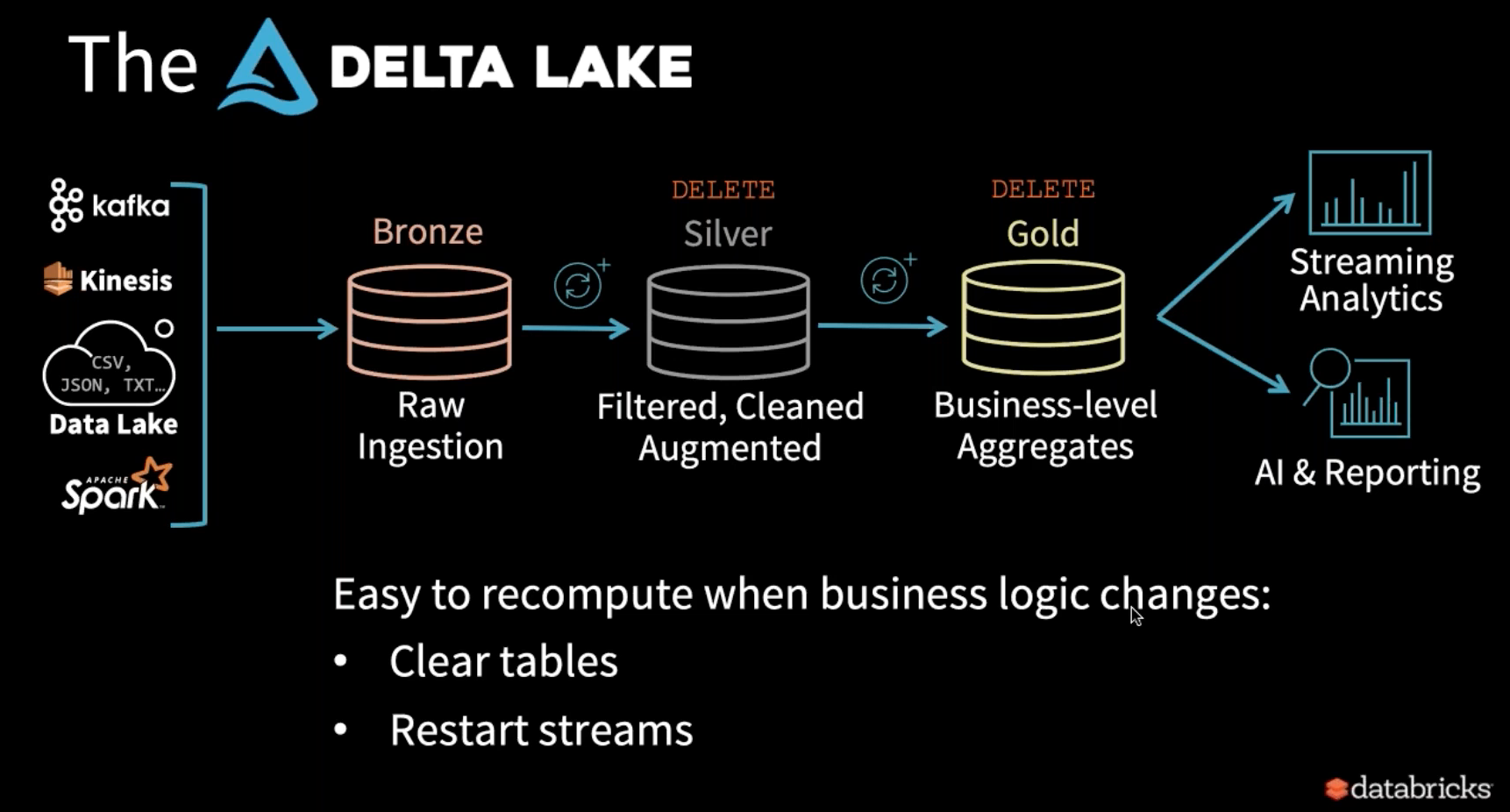
また、Delta Lake は Bronze に生データを置いている為、ビジネスロジックの変更などで計算し直す必要が出た場合は Silver と Gold を削除し、再び Bronze から始めるだけなので、とても簡単に実行できます。
おわりに
「Data Reliability for Data Lakes」の翻訳は以上です。
Delta Lake の流れや仕組みについて詳しく記載されており、とても役立つ動画です。本編では、より詳細な内容について話されているので、ぜひ御覧ください。
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
