はじめに
MMLSpark を Databricks (on AWS EC2) のクラスタで使用できるようにする手順を示します。
対象者
- Databricks on EC2(AWS) で分析環境を立ち上げている
- init_script をいじったけどなんだかうまく行かない
pipでもうまくいかない- MMLSpark は Azure 以外のプラットフォームで使えないの?
- 現在使用しているアルゴリズムをSparkによる分散処理に最適化できないか方法を探している
mmlspark とは?
正式名称は、Microsoft Machine Learning for Apache Spark。
Microsoft Azure のマネージド機械学習サービスである Cogninive Services や、機械学習の現場でよく使われる LightGBM などを Spark で効率的に活用できるように最適化したパッケージが揃っているライブラリです。
画像処理ライブラリの雄である OpenCV のパッケージもあります。2020年5月現在では実装されている関数は限定的ですが、大量の画像に対してシンプルな前処理を並列かつ高速に行いたい場合には選択肢に入ってきそうです。
MMLSpark OpenCV Package
そしてこのパッケージ、Microsoft Azure 以外のプラットフォームでも使えます。
インストール方法
Databricks のワークスペースで、
ClustersからLibrariesに飛び、Install Newをクリック
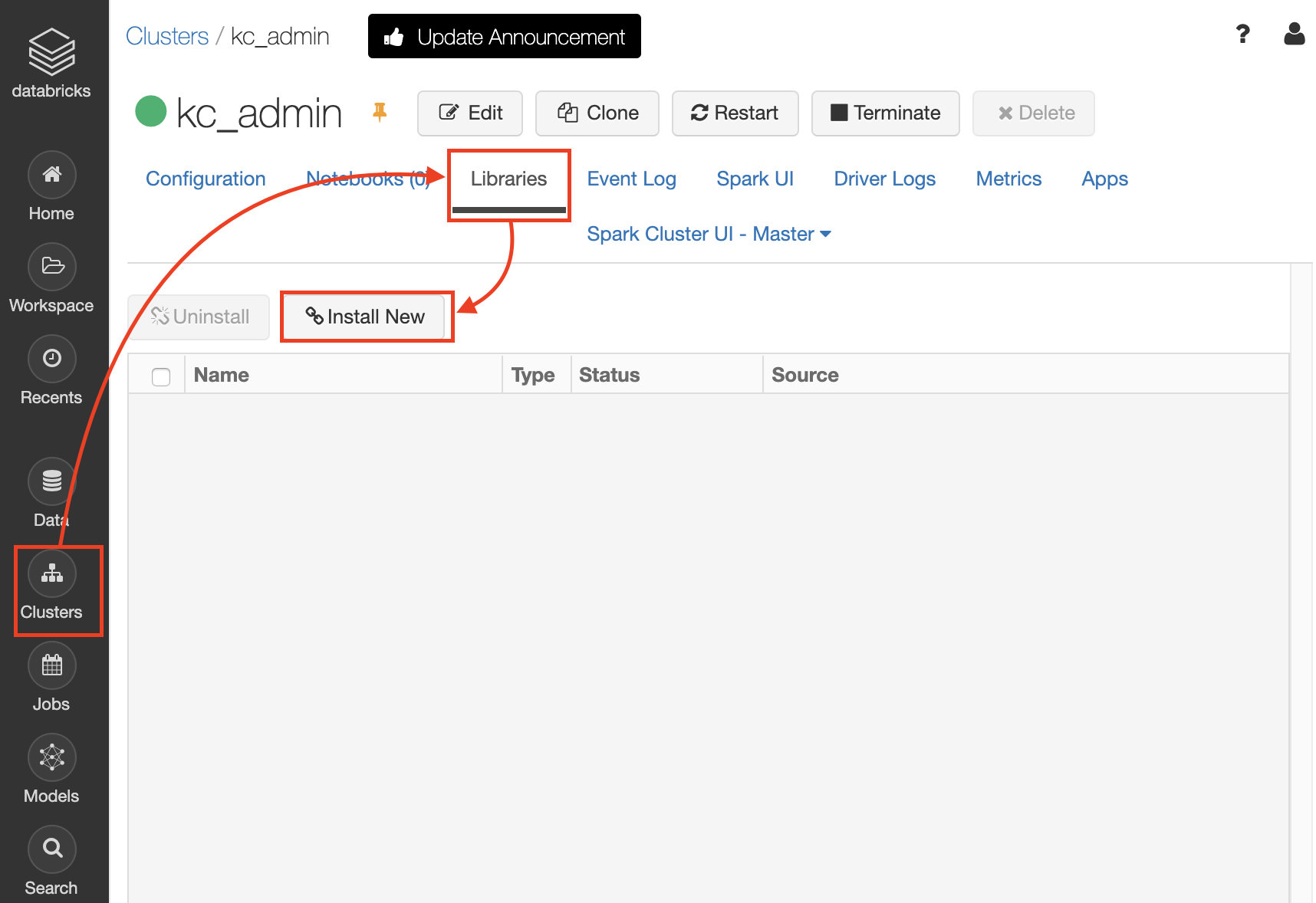
Library Source に Mavenを選択し、Repository に以下を入力、Installをクリック
com.microsoft.ml.spark:mmlspark_2.11:1.0.0-rc1

しばらくするとこちらの画面に遷移します。
Status が InstalledになっていればOK。これで完了です。

参考スクリプト
以下のような感じで、Collaborative Notebook 上でモジュールが使えるようになります。
|
1 2 3 4 5 6 |
triazines = spark.read.format("libsvm")\ .load("wasbs://publicwasb@mmlspark.blob.core.windows.net/triazines.scale.svmlight") # print some basic info print("records read: " + str(triazines.count())) print("Schema: ") |
result

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
triazines.printSchema() triazines.limit(10).toPandas() train, test = triazines.randomSplit([0.85, 0.15], seed=1) from mmlspark.lightgbm import LightGBMRegressor model = LightGBMRegressor(objective='quantile', alpha=0.2, learningRate=0.3, numLeaves=31).fit(train) from mmlspark.lightgbm import LightGBMRegressionModel model.saveNativeModel("mymodel") model = LightGBMRegressionModel.loadNativeModelFromFile("mymodel") print(model.getFeatureImportances()) |
result

|
1 2 |
scoredData = model.transform(test) scoredData.limit(10).toPandas() |
result
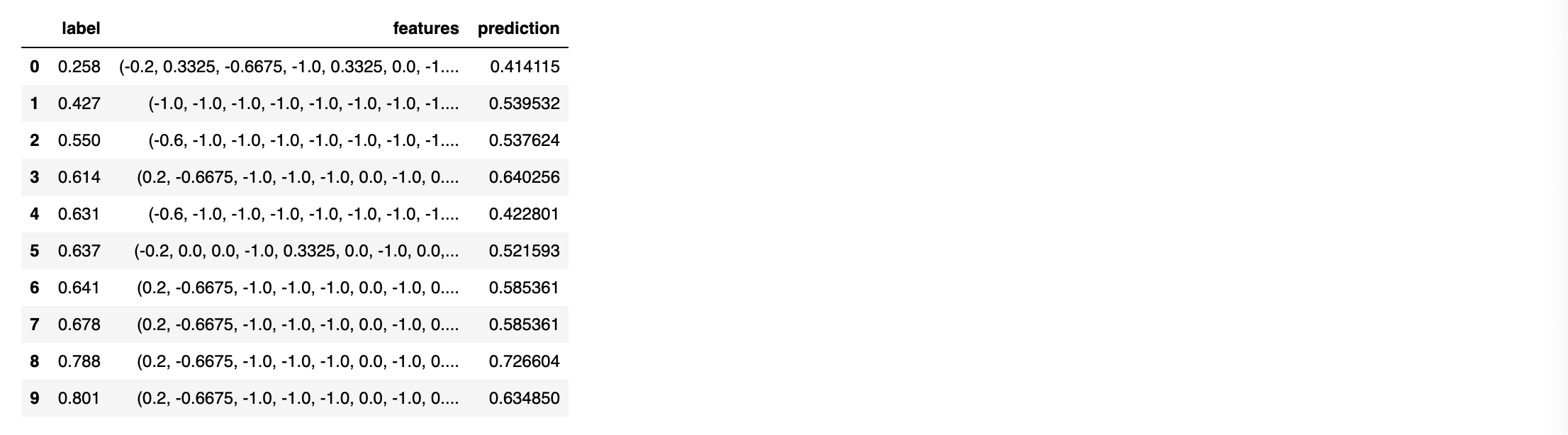
|
1 2 3 4 5 6 |
from mmlspark.train import ComputeModelStatistics metrics = ComputeModelStatistics(evaluationMetric='regression', labelCol='label', scoresCol='prediction') \ .transform(scoredData) metrics.toPandas() |
result

おわりに
モジュールのインストール方法にもいろいろあるんですね。
依存関係が出やすいので pip 乱発はやめたいところです(自戒)
