はじめに
本記事では PySpark でデータ加工や分析をされている方向けに、簡易的な縦持ちのテーブルを横持ちで見れる形へと回転するような変換をしていきます。
一般的にデータを見るという点では横持ちのテーブルの方が整っており、行の数も少なく見やすいのではないかと思います。
一方でデータ加工には縦持ちのテーブルの方が行に対してより複雑な情報を加えたりなど柔軟に操作できます。
縦に更新されていくデータを、表の見やすさために横持ちへ変換することが使用用途として考えられます。
使用する関数について
今回は横持ち変換をするために、 pivot という関数を使用します。
pivot は回転軸という意味を持ち、縦に続いていたデータを回転させて横に続くようなテーブルへと変換してくれます。
Pandasでは日本語で解説されている文献が多いものの、PySpark では少ないので記事にしてみました。
本記事のスタートとゴール
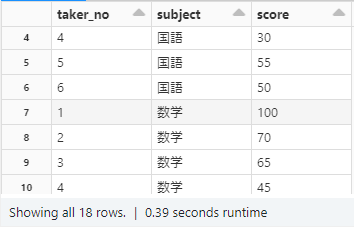
スタートは以下のカラムを持つ、ある試験で受験者がそれぞれ3科目試験を受けた際の点数が縦に記録されたテーブルを用意します。
・taker_no : 受験者の番号(6人)
・subject : 試験科目(3科目)
・score : 試験の点数(100点満点)
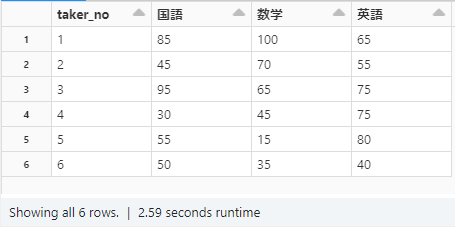
ゴールは上記の試験の点数を横持ちに変換して、受験者の試験の得点が試験科目ごとに横に展開される状態にすることです。
作業環境
・Databricks を使用
・バージョン: Apache Spark 3.2.1
縦持ちテーブルの横持ち変換
まず縦持ちのテーブルを用意しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# データ作成 data = [ (1,"国語",85), (2,"国語",45), (3,"国語",95), (4,"国語",30), (5,"国語",55), (6,"国語",50), (1,"数学",100), (2,"数学",70), (3,"数学",65), (4,"数学",45), (5,"数学",15), (6,"数学",35), (1,"英語",65), (2,"英語",55), (3,"英語",75), (4,"英語",75), (5,"英語",80), (6,"英語",40), ] columns= ["taker_no","subject","score"] df = spark.createDataFrame(data = data, schema = columns) display(df) |
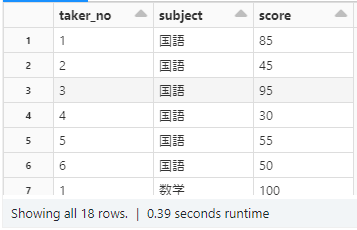
次に作成したデータを横持ちに変換していきます。
縦持ちテーブルだと、現状3科目の試験の点数が縦に記録されているので受験者1人につき3行存在します。
これを1行で横持ちに試験の点数を並べていくので、まず受験者ごとに groupby していきます。
次に、pivot を使用します。引数には横持ちにしていく試験科目である 「subject」 を指定します。
最後に横持ちに展開したカラムに「score」を埋めていくのですが、ここでひとつ注意点があります。
groupby した後には max や avg など集計関数を仕様上使わなければなりません。
今回のデータではグルーピングした際に値は唯一無二になるので、集計関数を使う意味はないのですが、やむを得ず使用した形になります。 max を使用しましたが、他でも問題ありません。(count など値が変化する関数は NG )
※ グルーピングした際に値が複数存在する場合はどのような集計するか用途によって考える必要があります。
|
1 2 3 4 |
# 横持ち変換 df = df.groupby("taker_no").pivot("subject").max("score") display(df.orderBy("taker_no")) |
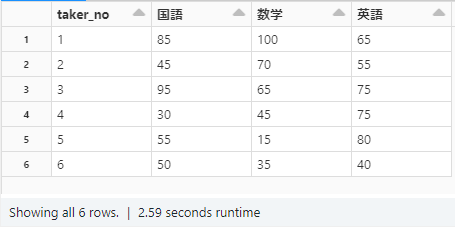
横持ちにテーブルを変換できたことを確認しました。
注意点
PySpark の pivot によって行われる処理は他の一般的な PySpark の変換処理に比べ、重いものとなっております。
本記事で使用したような小さいデータでは問題なく実行されますが、大規模なデータを扱う際にテーブルの列が数百~数千増えるような pivot の処理を実行するとうまく処理が完了されない可能性がありますので注意が必要です。
まとめ
pivot を使用することにより、縦持ちのデータを横持ちへと変換してみました。
これによりテーブルを見やすくできたのではないかと思います。
用途によって利用していただければと思います。
