はじめに
Delta Live Tables(略: DLT) とは Databricks にてデータのパイプライン処理を構築するときに利用できる便利なフレームワークです。
こちらのフレームワークを使用することでパイプラインのスケジューリングやモニタリング、テーブルの依存関係の可視化、データ品質管理など様々なことが実現できます。
過去に DLT を実装していた際に自分の頭の中で想定していた出力結果(テーブルの中身)と実際に DLT を使用した出力結果がなぜか異なったことがあったので詳細について解決策含めて記事にしてみます。
DLT の実装について
DLT を使用して複雑なパイプラインを構築していく際、通常は以下のようなステップを踏んでいくことが自然です。
- まず DLT なしでノートブック上に処理を書き起こす
- 1 の処理結果を確認する
- 1 をベースに 新たに DLT 用のノートブックに処理を書き起こす
- 3 の処理結果を確認する
DLT もノートブック上に処理実装していくのですが、通常の PySpark や Spark SQL の記述とは異なる「宣言型」と呼ばれる記法が必要となります。
また、セルごとに都度処理がエラーなく実行できるか確認するといった通常のノートブックの使い方ができません。
慣れない方にとって始めは少し特有に感じる部分もあるかとは思います。
よってパイプラインがうまく動作しないといった場合に原因の切り分けをしやすくするためにも、いきなり DLT 実装に取り掛かるのではなく、まずは上記 1,2 の手順のように通常のコーディングでエラーなく処理が実装できるかを先に確かめておくのが無難な進め方かと思います。
実装内容
自分も上記ステップごとに実装を進めていましたが、2 と 4 の出力結果を比較したときに同じ結果であることを期待していましたが実際は異なっていました。
以下、具体的なコード含めて詳細を記述していきます。
グループごとの英語テストのスコアのようなデータを作りました。
今回、コードの内容は本記事の説明用にあくまで例としてシンプルにしております。
過去実際に直面した問題が以下コードでも同様に発生しますが、コード自体は実際の直面したものではございません。
また、本記事では Python で記述しています。
DLT なしのノートブックでの記述
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
group_a = [ ("田中", "55", "80", "80", "70"), ("佐藤", "95", "85", "60", "70"), ("山田", "30", "20", "80", "50"), ] columns= ["name","listening","speaking","writing","reading"] df = spark.createDataFrame(data = group_a, schema = columns) # group_b 出力 display(df) # group_b データ作成 group_b = [ ("鈴木", "100", "90", "80", "80"), ("高橋", "50", "45", "55", "65"), ("伊藤", "80", "50", "80", "90"), ] df = spark.createDataFrame(data = group_b, schema = columns) # group_a 出力 display(df) |
DLT ありのノートブックでの記述
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import dlt # group_a データ作成 group_a = [ ("田中", "55", "80", "80", "70"), ("佐藤", "95", "85", "60", "70"), ("山田", "30", "20", "80", "50"), ] columns= ["name","listening","speaking","writing","reading"] df = spark.createDataFrame(data = group_a, schema = columns) @dlt.table def score_group_a(): return ( df ) # group_b データ作成 group_b = [ ("鈴木", "100", "90", "80", "80"), ("高橋", "50", "45", "55", "65"), ("伊藤", "80", "50", "80", "90"), ] df = spark.createDataFrame(data = group_b, schema = columns) @dlt.table def score_group_b(): return ( df ) |
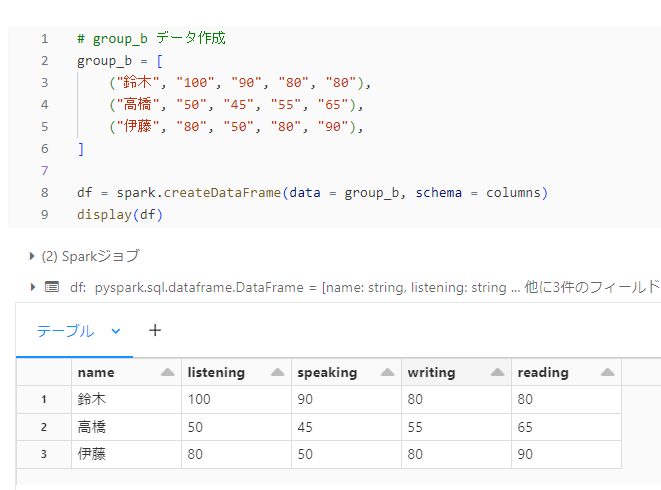
筆者が期待していた結果
group_a
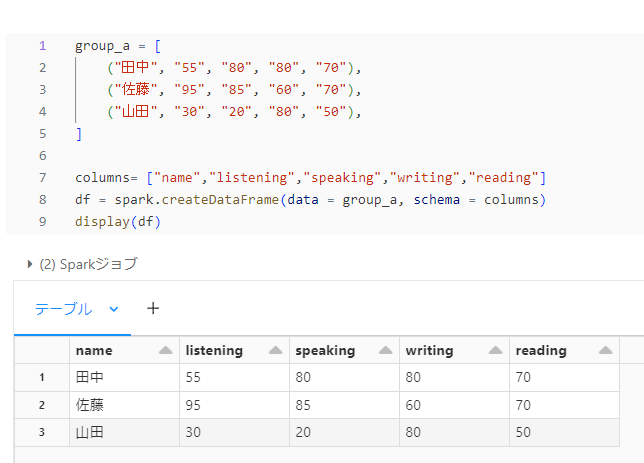
group_b
実際に DLT にて出力された結果
group_a
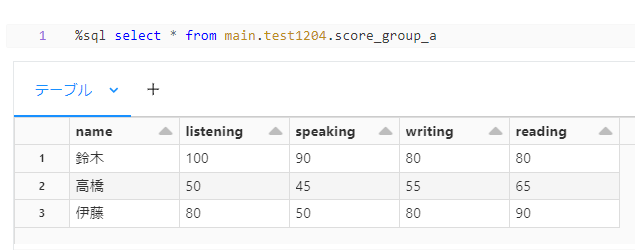
group_b
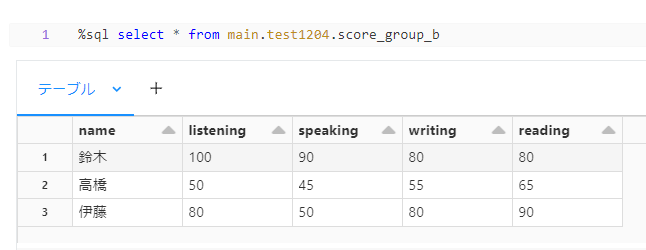
判明したこと
DLT を使用した場合に score_group_a テーブルの出力結果が期待したものでないことがわかります。
さらに、よくみてみると score_group_a テーブルの中身が score_group_b テーブルと同じになっています。
なぜこういったことが起こるのか調べていたところ、コード内で同じ変数名(df)で複数の値を格納し、DLT のテーブル定義の中で使用していることに気が付きました。。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
~ 略 ~ # df の使用 1回目 df = spark.createDataFrame(data = group_a, schema = columns) @dlt.table def score_group_a(): return ( df ) ~ 略 ~ # df の使用 2回目 df = spark.createDataFrame(data = group_b, schema = columns) @dlt.table def score_group_b(): return ( df ) |
通常であれば処理は上から実行されていくので、score_group_a テーブルは 1回目に格納した df の値となっているはずです。
しかし、今回の DLT で定義したテーブルは、上書きされた最終的な df の値(つまり2回目に格納した df)で実行されていくので、score_group_b テーブルでの出力と同じ内容が score_group_a テーブルでも出力されてしまう結果となっていました。。
こちらの問題を回避するには同じ変数の名前に複数の値を格納することを避けて、以下のように別々の変数名を用意してもらえばと思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
~ 略 ~ # 1つ目の変数 df_group_a = spark.createDataFrame(data = group_a, schema = columns) @dlt.table def score_group_a(): return ( df_group_a ) ~ 略 ~ # 2つ目の変数 df_group_b = spark.createDataFrame(data = group_b, schema = columns) @dlt.table def score_group_b(): return ( df_group_b ) |
さいごに
DLT で実装した際に出力結果が期待したものでない場合は同じ変数を使いまわしていないか確認してみることをおすすめします。
上記で紹介した例くらいのものであれば原因はすぐにわかるかと思いますが、実装したパイプラインが複雑であればあるほど、エラー自体はないにも関わらず出力結果が期待していないものとなってしまう原因箇所の特定が大変になるため注意が必要です。
