本記事は OpenAI活用法 Advent Calendar 2023 by ナレコム の12日目の記事です。
OpenAI活用法 Advent Calendar 2023 by ナレコム ではGPTsを含めた最新のOpenAIの活用法について紹介します。
はじめに
Azure OpenAI Studioは、音声認識と変換技術を活用するための強力なプラットフォームです。2023年12月現在、AzureのWhisperサービスは音声からテキストへの変換を可能にする最先端のツールを提供しています。この記事では、Azure OpenAIのWhisperを使用し、音声ファイルを効果的に文字に変換する方法を紹介します。
Azure AI Speech を介した Whisper モデルは、長時間のファイル(最大1GB)に向いていますが、素早く正確に文字起こしをするときにはOpenAI の Whisper が向いております。
動画ファイルから音声を抽出し、それをテキストに変換するプロセスに焦点を当てます。これは、セミナーやプレゼンテーションなどの長いオーディオコンテンツをテキスト化するのに特に有用です。このプロセスを通じて、Azure OpenAI Studioの強力な機能を最大限に活用し、音声データの潜在的な価値を引き出す方法を学びます。
記事の後半では、具体的な実装手順について説明し、読者が自身のプロジェクトでこの技術を応用できるようにします。Whisperを使用することで、動画やオーディオから得られる情報をよりアクセスしやすく、活用しやすい形式に変換することが可能になります。
Azure OpenAI StudioでWhisperの登録
https://learn.microsoft.com/ja-jp/azure/ai-services/speech-service/whisper-overview
2023年12月現在、Azure上でWhisperを利用できるのは 米国中北部 と 西ヨーロッパ の2箇所となっております。
- Azureポータルで、上記いづれかのリージョンにAzure OpenAIのリソース作成
- 該当リソースの Azure OpenAI Studio に移動
- Azure OpenAI Studioで「デプロイ」でモデルとして「whisper」選択し、任意の「デプロイ名」で作成する(例:whisper)
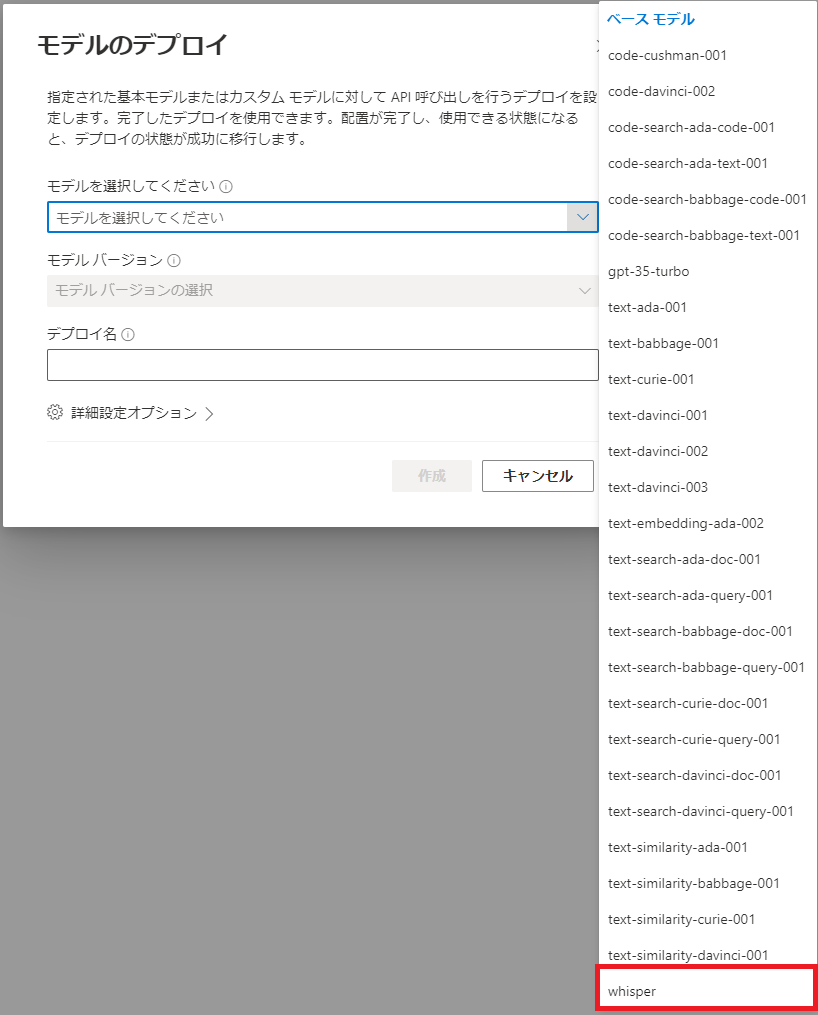
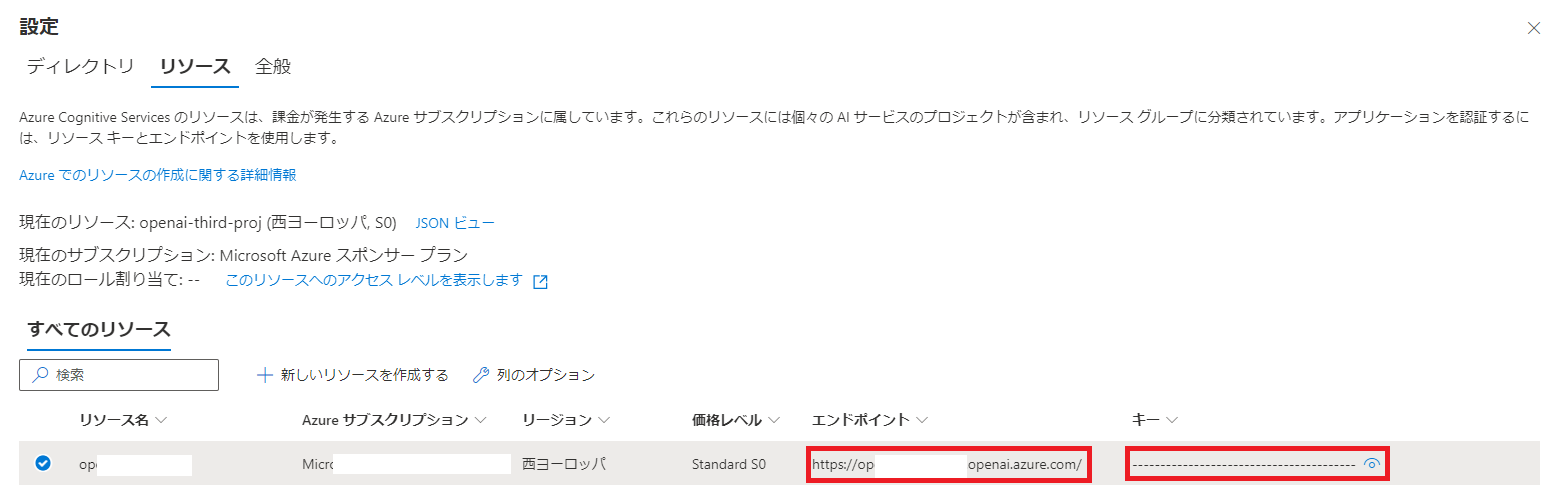
- プログラム用に以下の3つの値を控える
- 上記 「デプロイ名」
- 下図 「エンドポイント」
- 下図 「キー」
プログラム実装
1. mp4(動画)をmp3(音声)に変換
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<span class="kn">import</span> <span class="n">ffmpeg</span> <span class="n">mp4_path</span> <span class="o">=</span> <span class="sh">"</span><span class="s">動画のパス.mp4</span><span class="sh">"</span> <span class="n">mp3_path</span> <span class="o">=</span> <span class="sh">"</span><span class="s">音声のパス.mp4</span><span class="sh">"</span> <span class="c1"># 入力 </span><span class="n">stream</span> <span class="o">=</span> <span class="n">ffmpeg</span><span class="p">.</span><span class="nf">input</span><span class="p">(</span><span class="n">mp4_path</span><span class="p">)</span> <span class="c1"># 出力 </span><span class="n">stream</span> <span class="o">=</span> <span class="n">ffmpeg</span><span class="p">.</span><span class="nf">output</span><span class="p">(</span><span class="n">stream</span><span class="p">,</span> <span class="n">mp3_path</span><span class="p">)</span> <span class="c1"># 実行 </span><span class="n">ffmpeg</span><span class="p">.</span><span class="nf">run</span><span class="p">(</span><span class="n">stream</span><span class="p">)</span> |
2. mp3(音声)に分割
Whisperの仕様として25MB25分以下に分割します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
<span class="kn">import</span> <span class="n">os</span> <span class="k">def</span> <span class="nf">split_mp3</span><span class="p">(</span><span class="n">file_path</span><span class="p">,</span> <span class="n">split_length</span><span class="o">=</span><span class="mi">1440</span><span class="p">):</span> <span class="c1"># 元のファイルのディレクトリとファイル名を分ける </span> <span class="n">dir_name</span><span class="p">,</span> <span class="n">file_name</span> <span class="o">=</span> <span class="n">os</span><span class="p">.</span><span class="n">path</span><span class="p">.</span><span class="nf">split</span><span class="p">(</span><span class="n">file_path</span><span class="p">)</span> <span class="n">base_name</span><span class="p">,</span> <span class="n">_</span> <span class="o">=</span> <span class="n">os</span><span class="p">.</span><span class="n">path</span><span class="p">.</span><span class="nf">splitext</span><span class="p">(</span><span class="n">file_name</span><span class="p">)</span> <span class="c1"># 分割されたファイルの数をカウントする </span> <span class="n">index</span> <span class="o">=</span> <span class="mi">0</span> <span class="c1"># 分割するファイルの長さを取得 </span> <span class="n">file_info</span> <span class="o">=</span> <span class="n">ffmpeg</span><span class="p">.</span><span class="nf">probe</span><span class="p">(</span><span class="n">file_path</span><span class="p">)</span> <span class="n">duration</span> <span class="o">=</span> <span class="nf">float</span><span class="p">(</span><span class="n">file_info</span><span class="p">[</span><span class="sh">'</span><span class="s">format</span><span class="sh">'</span><span class="p">][</span><span class="sh">'</span><span class="s">duration</span><span class="sh">'</span><span class="p">])</span> <span class="c1"># 分割処理 </span> <span class="k">while</span> <span class="n">index</span> <span class="o">*</span> <span class="n">split_length</span> <span class="o"><</span> <span class="n">duration</span><span class="p">:</span> <span class="n">start_time</span> <span class="o">=</span> <span class="n">index</span> <span class="o">*</span> <span class="n">split_length</span> <span class="c1"># 出力ファイル名の生成 </span> <span class="n">output_file</span> <span class="o">=</span> <span class="n">os</span><span class="p">.</span><span class="n">path</span><span class="p">.</span><span class="nf">join</span><span class="p">(</span><span class="n">dir_name</span><span class="p">,</span> <span class="sa">f</span><span class="sh">"</span><span class="si">{</span><span class="n">base_name</span><span class="si">}</span><span class="s">_part</span><span class="si">{</span><span class="n">index</span> <span class="o">+</span> <span class="mi">1</span><span class="si">}</span><span class="s">.mp3</span><span class="sh">"</span><span class="p">)</span> <span class="c1"># ffmpegを使ってファイルを分割 </span> <span class="p">(</span> <span class="n">ffmpeg</span> <span class="p">.</span><span class="nf">input</span><span class="p">(</span><span class="n">file_path</span><span class="p">,</span> <span class="n">ss</span><span class="o">=</span><span class="n">start_time</span><span class="p">,</span> <span class="n">t</span><span class="o">=</span><span class="n">split_length</span><span class="p">)</span> <span class="p">.</span><span class="nf">output</span><span class="p">(</span><span class="n">output_file</span><span class="p">)</span> <span class="p">.</span><span class="nf">run</span><span class="p">(</span><span class="n">overwrite_output</span><span class="o">=</span><span class="bp">True</span><span class="p">)</span> <span class="p">)</span> <span class="n">index</span> <span class="o">+=</span> <span class="mi">1</span> <span class="nf">split_mp3</span><span class="p">(</span><span class="n">mp3_path</span><span class="p">)</span> |
3. 分割した音声を文字に変換する
先程取得した3つの値を入力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
<span class="kn">import</span> <span class="n">json</span> <span class="kn">import</span> <span class="n">requests</span> <span class="n">deployment</span> <span class="o">=</span> <span class="o"><</span><span class="n">デプロイ名</span><span class="o">></span> <span class="n">endpoint</span> <span class="o">=</span> <span class="o"><</span><span class="n">エンドポイント</span><span class="o">></span> <span class="n">api_key</span> <span class="o">=</span> <span class="o"><</span><span class="n">キー</span><span class="o">></span> <span class="n">url</span> <span class="o">=</span> <span class="sa">f</span><span class="sh">"</span><span class="si">{</span><span class="n">endpoint</span><span class="si">}</span><span class="s">/openai/deployments/</span><span class="si">{</span><span class="n">deployment</span><span class="si">}</span><span class="s">/audio/transcriptions?api-version=2023-09-01-preview</span><span class="sh">"</span> <span class="n">headers</span> <span class="o">=</span> <span class="p">{</span> <span class="sh">'</span><span class="s">api-key</span><span class="sh">'</span> <span class="p">:</span> <span class="n">api_key</span> <span class="p">}</span> <span class="n">mp3_path</span> <span class="o">=</span> <span class="n">mp3_path_part</span> <span class="k">with</span> <span class="nf">open</span><span class="p">(</span><span class="n">mp3_path</span><span class="p">,</span> <span class="sh">'</span><span class="s">rb</span><span class="sh">'</span><span class="p">)</span> <span class="k">as</span> <span class="n">f</span><span class="p">:</span> <span class="n">file_data</span> <span class="o">=</span> <span class="n">f</span><span class="p">.</span><span class="nf">read</span><span class="p">()</span> <span class="n">files</span> <span class="o">=</span> <span class="p">{</span><span class="sh">'</span><span class="s">file</span><span class="sh">'</span><span class="p">:</span> <span class="p">(</span><span class="n">music_filepath</span><span class="p">,</span> <span class="n">file_data</span><span class="p">)}</span> <span class="n">response</span> <span class="o">=</span> <span class="n">requests</span><span class="p">.</span><span class="nf">post</span><span class="p">(</span><span class="n">url</span><span class="p">,</span> <span class="n">headers</span><span class="o">=</span><span class="n">headers</span><span class="p">,</span> <span class="n">files</span><span class="o">=</span><span class="n">files</span><span class="p">)</span> <span class="nf">print</span><span class="p">(</span><span class="n">response</span><span class="p">.</span><span class="nf">json</span><span class="p">())</span> |
プレゼン動画だと、概ね24分で1万文字程度となります。
まとめ
本記事では、Azure OpenAI Studioを利用してWhisperモデルを使用し、音声ファイルをテキストに変換する一連のプロセスを詳しく説明しました。主要なステップは以下の通りです:
-
Azure OpenAI StudioでWhisperの登録:
- 米国中北部または西ヨーロッパのリージョンでAzure OpenAIリソースを作成。
- Azure OpenAI Studioで「Whisper」モデルをデプロイし、必要な「デプロイ名」、「エンドポイント」、「キー」を取得。
-
プログラム実装:
- mp4形式の動画ファイルをmp3形式の音声ファイルに変換。
- Whisperの仕様に従って、mp3ファイルを25MBまたは25分以下に分割。
- 分割した音声ファイルを文字に変換。
このプロセスにより、セミナーやプレゼンテーションなどの長いオーディオコンテンツを効率的にテキスト化し、さまざまな用途で活用することができます。Whisperの利用により、動画やオーディオから得られる情報をアクセスしやすく、扱いやすい形式に変換することが可能になります。
この技術は、ビジネス会議の記録、教育コンテンツの作成、メディア分析など、多岐にわたる分野で応用可能です。Azure OpenAIとWhisperを活用することで、音声データの潜在的な価値を最大限に引き出すことができます。
また、ナレッジコミュニケーションでは 「Musubite」 というエンジニア同士のカジュアルトークサービスを利用しています!この記事にあるような生成AI 技術を使ったプロジェクトに携わるメンバーと直接話せるサービスですので興味がある方は是非利用を検討してください!
