はじめに
これからAzureを利用してデータ分析をはじめる方向けに
Azure Synapse Analyticsの概要や機能などをまとめて紹介したいと思います。
Azure Synapse Analytics とは
Azure Synapse Analyticsは、マイクロソフトが提供する統合型分析サービスです。
大規模なデータウェアハウス(DWH)機能とビッグデータ分析を一つのプラットフォームで組み合わせています。
データの収集、処理、分析を容易にし、機械学習やBIツールとの連携も可能です。
データ分析初学者にとって、Azure Synapse Analyticsはデータの探索から洞察の獲得までのプロセスをシンプルにする強力なツールです。
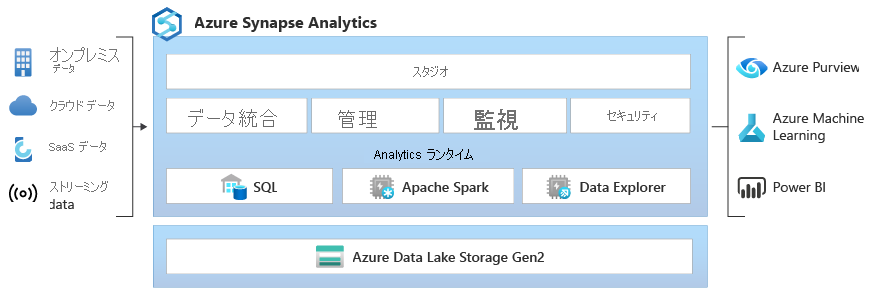
Azure Synapse Analytics の特徴
- 統合分析サービス: 大量のデータを迅速に分析・処理するための統合プラットフォーム。
- 多様なデータソースのサポート: 様々なデータソースとの接続と統合が可能。
- リアルタイム分析: ストリーミングデータのリアルタイム分析機能。
- セキュリティとプライバシー: 高度なセキュリティとプライバシー機能。
- 柔軟な分析オプション: SQL、Apache Sparkを活用した分析オプション。
- スケーラビリティとパフォーマンス: 高いスケーラビリティとパフォーマンス。
Synapse ワークスペース
Synapse ワークスペースは、Azureでデータの分析をするための場所です。
これを使うと、データを安全に共有して分析できます。
ワークスペースは特定のリージョンにデプロイされ、データを一時的に保存するためのストレージも備えています。
SQLとApache Sparkという2つのツールを使って、データを分析することができます。
Synapse SQL
Synapse SQLは、Azure Synapse ワークスペース内でT-SQLを使ってデータ分析を行う機能です。
Synapse SQLには、「専用モデル」と「サーバーレスモデル」の2種類があります。専用モデルでは、専用の「SQLプール」と呼ばれるリソースを使います。
サーバーレスモデルでは、別のタイプの「サーバーレス SQLプール」を使います。
これらのプールを使って、Synapse Studioという場所でSQLスクリプトを実行し、データを操作します。
※ただし、Synapseの専用SQLプールと以前のSQL DW(データウェアハウス)は異なるので注意が必要です。
Synapse 用の Apache Spark
Spark分析は、SynapseワークスペースでサーバーレスのApache Sparkプールを作って使います。
Sparkプールを使い始めると、ワークスペースがSparkセッションを作り、そのセッションに必要なリソースを扱います。
Sparkを使う方法は2つあります。
- Spark Notebooksで、データサイエンスやエンジニアリングに使い、ScalaやPySparkなどの言語を使用。
- Sparkジョブ定義で、バッチSparkジョブをjarファイルで実行します。
SynapseML
SynapseMLは、大規模な機械学習(ML)パイプラインを作るのを簡単にするオープンソース ライブラリです。
これはApache Sparkというフレームワークを拡張するために使われます。
SynapseMLは、既存の機械学習ツールやMicrosoftの新しいアルゴリズムを組み合わせ、Python、R、Scala、.NET、Javaといった言語で使えるようにします。
パイプライン
Azure Synapseでは、「パイプライン」という機能を使ってデータを統合します。
これは、異なるサービス間でデータを移動したり、特定の作業を調整したりすることを可能にします。
パイプラインは、1 つのタスクを連携して実行するアクティビティの論理的なグループです。
アクティビティは、データのコピー、ノートブックの実行、SQLスクリプトの実行などを定義します。
データフローは、データを変換するための特別なアクティビティで、ノーコードで使えます。
トリガーはパイプラインを開始し、手動または自動で動かせます。
(スケジュール、タンブリング ウィンドウ、またはイベントベース)
まとめ
学んだことの備忘録として記載しておりますので、参考程度にご覧頂ければ幸いです。
次回はSynapseの具体的な使い方などをまとめていきたいと思います。
