はじめに
Azure Cognitive Services の Computer Vision APIで利用できる OCR 機能を使って印刷物に描かれた文字の読み取りをさせてみました。
画像からのテキスト抽出をしてみたい方・AI サービスに興味がある方には必見の内容となっています。
本記事の概要
- Computer Vision API の概要・OCR 機能の概要について解説しています。
- 3 種類の言語が書かれた文章の紙を写真に撮り Computer Vision API で性格にテキストデータに変換できるのかを検証しています。
- 自動言語判定を利用して画像を読み取るだけで画像内の言語を正確に判定できているのかを検証しています。
Computer Vision APIについて
Computer Vision API は画像からオブジェクトを認識し、内容を抽出できるサービスで、画像分析、タグ付け、著名人の認識、テキスト抽出、およびサムネイル生成など様々な機能が利用できます。
利用料金は月 5000 トランザクションまで利用出来る無料の「Free」と、従量課金型の「Standard」が設定されており、「Free」で利用検証をして、実運用時に「Standard」に変更するといったような運用ができます。
| レベル | 機能 | 単位 | 料金 |
|---|---|---|---|
| Computer Vision API – Free | トランザクション | 5,000 無料トランザクション / 月 | |
| Computer Vision API – Standard | 最大 10 トランザクション/秒 | トランザクション | ¥153/1,000 トランザクション |
※現在はプレビューのため価格には割引が適応されています。
OCR 機能について
- Optical Character Recognition (光学文字認識)の略
- 画像データ内のテキストを認識し、文字列データとして読み取る機能
- OCR 自体は新しい技術ではなく、1950 年代には商用システムとして利用されるほど歴史が深い
- スキャナーなどのオプション機能としても一般的に提供
- Cognitive Services では、Computer Vision API の1機能としてOCR 用 API が提供
- 写真に撮った文書から文章の傾きや言語情報などを検知、文字列データに変換できる
Computer Vision APIのOCR機能
Computer Vision API のリクエストは Face API とほぼ同じで、Request header に API キー、Request body に画像を取得する URL を設定し、Request parameters に判別する言語の設定をします。
Computer Vision API の OCR 機能は現在 21 の言語に対応しており、言語設定を「’unk’」とすると、言語を自動判別して文字列に変換することができます。
・Python 2.7 サンプルコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#!/usr/bin/env python #coding:utf-8 import httplib, urllib, base64 import json headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': '*************** {APIキー}', } body = { # Request body 'url': 'http://********** {画像URL}' } params = urllib.urlencode({ # Request parameters 'language': 'unk {言語設定}', 'detectOrientation ': 'true', }) try: conn = httplib.HTTPSConnection('westus.api.cognitive.microsoft.com') conn.request("POST", "/vision/v1.0/ocr?%s" % params, json.dumps(body), headers) response = conn.getresponse() data = json.loads(response.read()) print(json.dumps(data, indent = 4)) conn.close() except Exception as e: print("[Errno {0}] {1}".format(e.errno, e.strerror)) |
上記コードで、文字列を画像として保存したものを Computer Vision API の OCR で分析すると、以下のような JSON が返されます。
分析結果は、文章のブロック、行、単語のレベルごとに、「region」、「lines」、「words」の階層を持った配列として出力されるため、ルールに沿って展開することで容易に文字列に変換することができます。
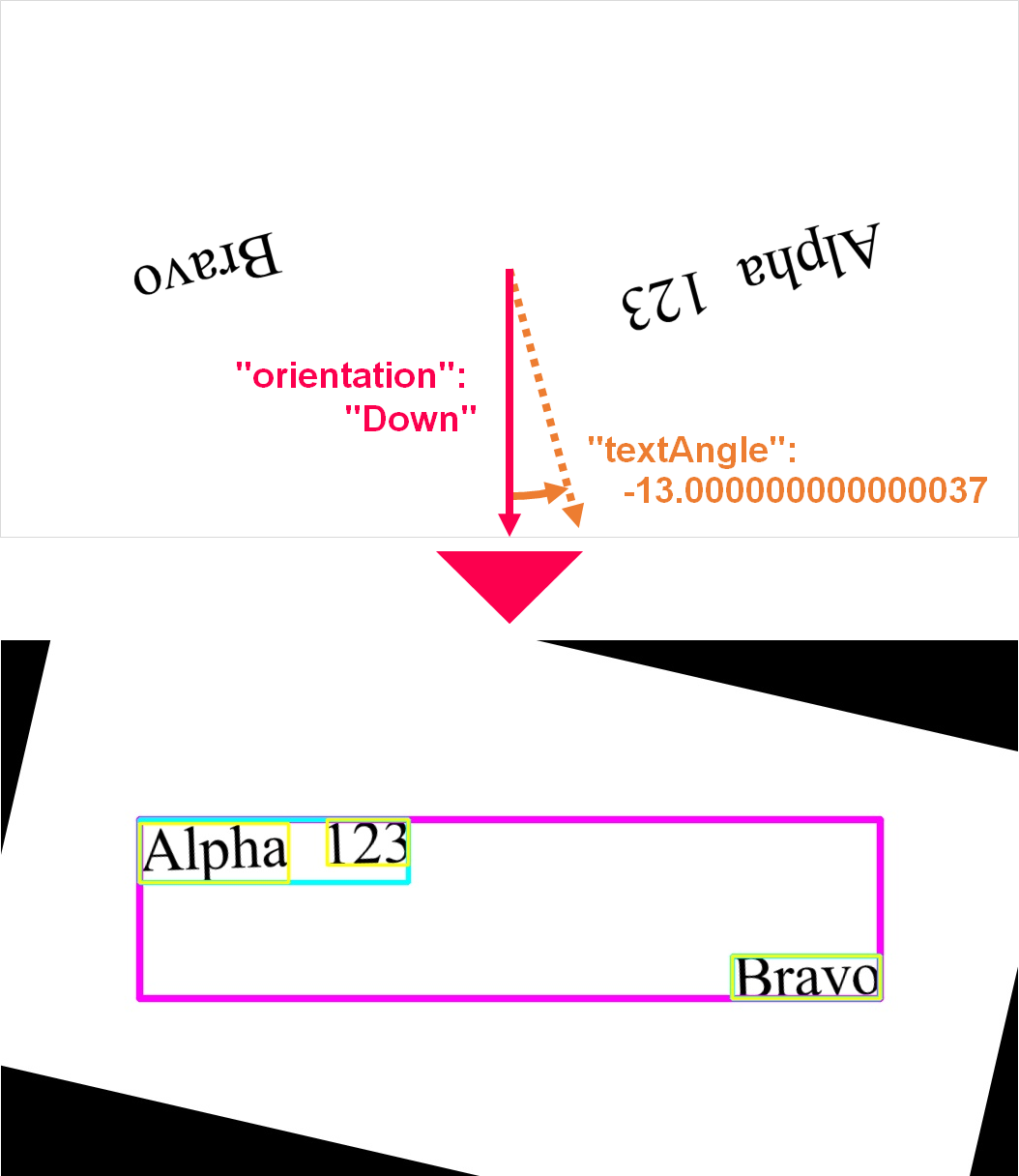
・入力画像

・レスポンス
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
{ "regions": [ { "boundingBox": "143,185,766,185", "lines": [ { "boundingBox": "143,185,278,65", "words": [ { "boundingBox": "143,189,154,61", "text": "Alpha" }, { "boundingBox": "337,185,84,47", "text": "123" } ] }, { "boundingBox": "756,326,153,44", "words": [ { "boundingBox": "756,326,153,44", "text": "Bravo" } ] } ] } ], "textAngle": -13.000000000000037, "orientation": "Down", "language": "es" } |
各階層の「boundingBox」は行や単語の検出範囲(座標)を示しています。「boundingBox」の座標は、元画像の座標ではなく、「orientation」と「textAngle」を基に行が水平になるように回転させた後の座標を示しています。
OpenCV で検出位置を可視化する場合などの処理を行う場合は、元画像の回転処理を行う必要があります。
OCR 機能は日本語にも対応しており、試しに日本語の画像データを入力してみると書かれている、かな、漢字をテキストデータに変換することができました。
ただし、西欧言語とは異なり、1 文字を単語として認識するため、欧米言語とは異なる方法でテキストデータ化する必要があるようです。

OCR による自動言語判定
Computer Vision API の OCR 機能がどの程度まで正確にデータ化と言語判定できるか試してみます。
今回は、滝廉太郎の「荒城の月」(日本語)、ベートーヴェンの「交響曲第9番」(ドイツ語)および「Ave Maria」(ラテン語)の歌詞を印刷した紙を写真に撮って OCR でテキストデータへの変換と言語判定をしてみました。

テキストデータへの変換には下記のコードを使用しました。
上述のように欧米言語と日本語では単語の認識が異なるため、日本語の判定の場合には単語のスペース区切り処理を行わないように処理を分けています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
#!/usr/bin/env python #coding:utf-8 import httplib, urllib, base64 import json # OCR機能 def ocr(key, img_url, lang): body = { 'url':img_url } headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': key } params = urllib.urlencode({ # Request parameters 'language': lang, 'detectOrientation ': 'true' }) conn = httplib.HTTPSConnection('westus.api.cognitive.microsoft.com') conn.request("POST", "/vision/v1.0/ocr?%s" % params, json.dumps(body), headers) response = conn.getresponse() data = json.loads(response.read()) conn.close() return data # 処理設定 setting = { 'rectangle': 'true' } # 入力設定 input_params = { 'computer_vision': { 'img_url':'http://**********{画像URL}', 'language': 'unk' } } # APIキー cognitive_keys = { 'computer_vision': '**********{APIキー}' } # OCR機能の使用 ocr_data = ocr(cognitive_keys['computer_vision'], input_params['computer_vision']['img_url'], input_params['computer_vision']['language']) output = '' # テキストデータ化 for txt_lines in ocr_data['regions']: for txt_words in txt_lines['lines']: for txt_word in txt_words['words']: if cv_data['language'] == 'ja': # 日本語 (スペースなし) output += txt_word['text'] else: # 欧米言語 (スペース区切り) output += txt_word['text'] + ' ' output += '\n' output += '\n' print('language:' + ocr_data['language'] + '\n') print(output) |
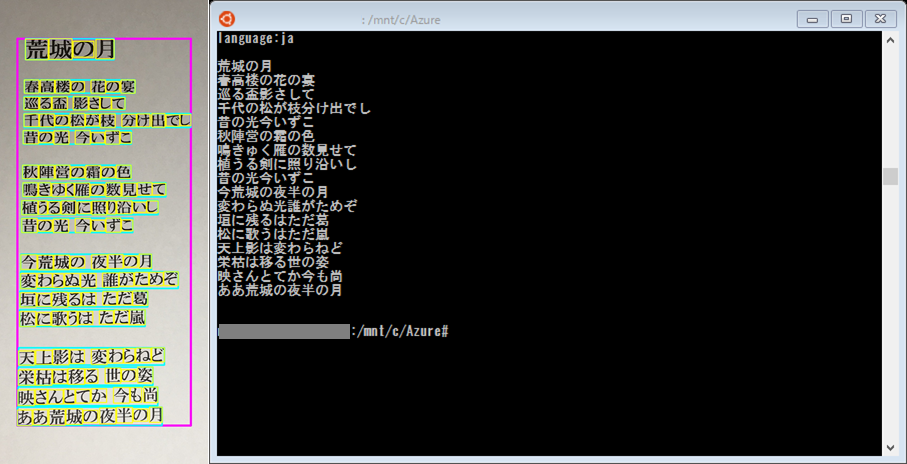
まず、日本語の「荒城の月」を認識させてみると、「language:ja」(日本語)と判定され、「荒城の月」の歌詞を表示することができました。
比較的難しい漢字の多い歌詞ですが、認識の誤りは「鳴きゆく雁の数見せて」の「ゆ」が小書きになっているのみで、漢字含めほぼ正確に認識できていることがわかりました。
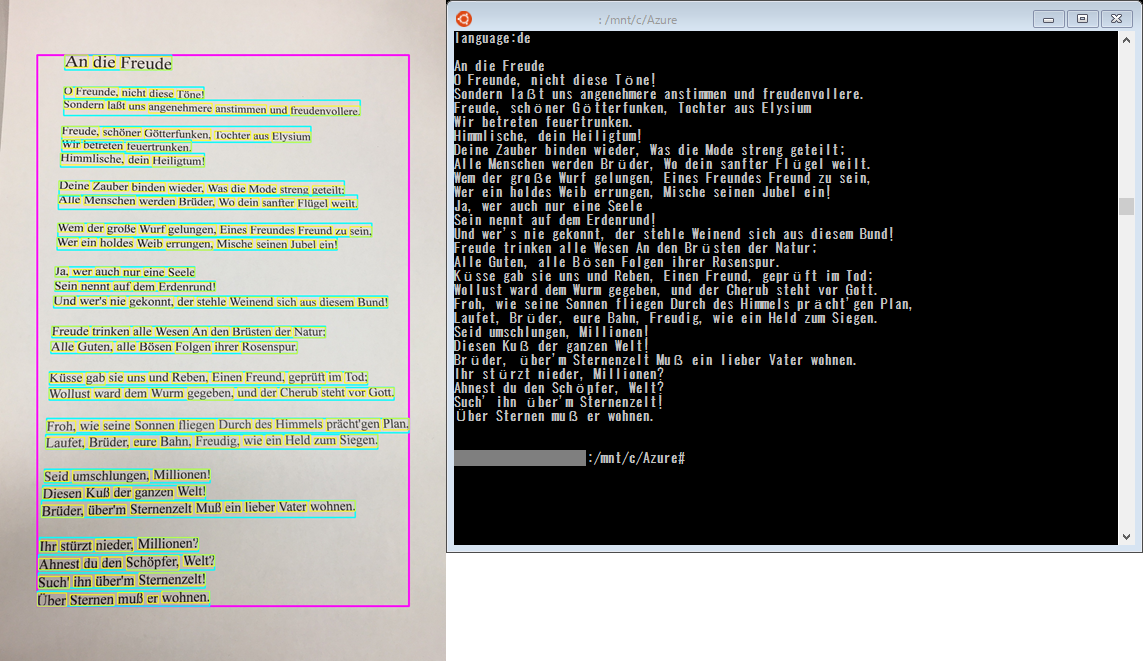
続いて、ドイツ語の「交響曲第9番」を認識させてみました。
26 行にわたる長い歌詞ですが、ウムラウトやエスツェットなど特殊な文字を含めても誤認識は 0で、正確にテキストデータに変換できていました。
言語も「language:de」(ドイツ語)と判定されており、言語の自動判定も正確にできていることがわかりました。
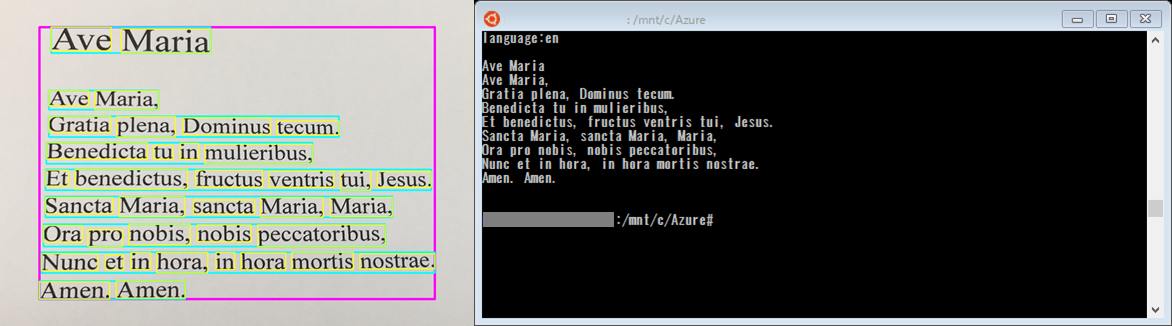
最後にラテン語の「Ave Maria」を認識させてみました。
歌詞自体はそれほど長くなく、文字もアルファベット 26 文字のみのため、文字認識はドイツ語同様に誤認識 0で、正確にテキストデータ化できていました。
しかし、OCR の言語判定機能はラテン語に対応していないため、言語判定に関しては最も近いと思われる「language: en」(英語)と判定されてしまいました。
最後に
今回は、Computer Vision API の OCR 機能を使用して印刷物のテキストデータ化と言語判定を試してみましたが、
スマートフォンで撮った文書の写真でも精度良くテキストデータに変換することができており、実用性の高さを感じました。
また、言語判定に関しても対応言語であれば正確に判定できるようで、何語かわからない文書もスマートフォンで撮るだけで言語判定できるといった利用ができるのではないでしょうか。
一方、対応していない言語に関しては単語の傾向か類似の言語を判定してしまうようなので、正確な判定を行う場合には別の手段をとる必要があります。
そこで次回は、OCR に加え言語判定に特化した Text Analytics API を併用して、より正確な言語判定を行う検証をしていきます。
お楽しみに!
