前回、「OCR機能で印刷物の写真からテキストのデータ化と言語判定をしてみる」というタイトルで
Microsoft Cognitive ServicesのComputer Vision APIで印刷物のテキストデータ化と言語判定を行いました。
Computer Vision APIでは26の言語の自動判定が可能でしたが、対応しない言語の判定は類似性の高い言語として判定されてしまいます。
そこで今回は、Text Analytics APIを併用してより正確な印刷物の言語判定を行ってみます。
Text Analytics APIの言語判定
Text Analytics APIは120の言語に対応した言語判定APIで、入力したテキストが何語かを判定することができます。
26の言語に対応するComputer Vision APIのOCRよりも幅広く判定ができるため、OCRで未対応の言語に対しても正確化な言語判定が期待できます。
Text Analytic APIのリクエストは、Request bodyに判定対象の識別IDとテキスト、Request parametersに判定する言語数の設定をします。
Request bodyでは、「id」および「text」を配列として複数設定することができ、それぞれのidごとに言語判定をすることができます。しています。
・Python 2.7サンプルコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#!/usr/bin/env python #coding:utf-8 import httplib, urllib, base64 import json headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': '*************** {APIキー}', } body = { # Request body 'documents': [ { 'id': '***{識別ID}', 'text': '************{テキスト}' }, { 'id': '***{識別ID}', 'text': '************{テキスト}' } ] } params = urllib.urlencode({ # Request parameters 'numberOfLanguagesToDetect': '1 {判定言語数}', }) try: conn = httplib.HTTPSConnection('westus.api.cognitive.microsoft.com') conn.request("POST", "/text/analytics/v2.0/languages?%s" % params, json.dumps(body), headers) response = conn.getresponse() data = json.loads(response.read()) print(json.dumps(data, indent = 4)) conn.close() except Exception as e: print("[Errno {0}] {1}".format(e.errno, e.strerror)) |
上記のサンプルコードに3つの言語のテキストを設定して分析をすると、idごとに判定された言語とその確度のスコアがJSON形式で返されました。
入力したテキストは「トイレはどこですか?」とドイツ語、バスク語、インドネシア語で質問する短い文章ですが、それぞれ”German”、”Basque”、”Indonesian”と該当する言語で判定することができていました。
バスク語、インドネシア語に関しては、アルファベットで書かれているものの、OCRの言語判定には対応していないため、Computer Vision APIを補完する目的にText Analytics APIを利用することが出来そうです。
・入力テキスト
| id | text |
|---|---|
| WC-1 | Wo ist die Toilette? |
| WC-2 | Non dago komuna? |
| WC-3 | Di mana kamar kecil? |
・レスポンス
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
{ "documents": [ { "id": "WC-1", "detectedLanguages": [ { "score": 1.0, "name": "German", "iso6391Name": "de" } ] }, { "id": "WC-2", "detectedLanguages": [ { "score": 1.0, "name": "Basque", "iso6391Name": "eu" } ] }, { "id": "WC-3", "detectedLanguages": [ { "score": 1.0, "name": "Indonesian", "iso6391Name": "id" } ] } ], "errors": [] } |
印刷物の言語判定
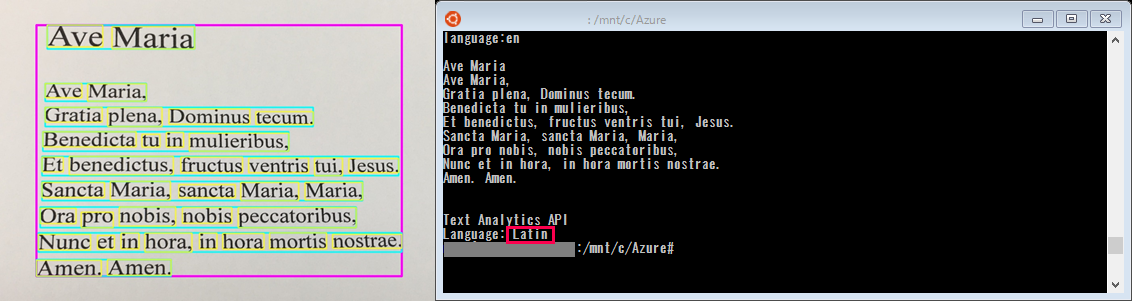
前回の「OCR機能で印刷物の写真からテキストのデータ化と言語判定をしてみる」では、OCRで未対応のラテン語が「英語」と判定されてしまいました。
上述のようにText Analytics APIがOCRの未対応言語にも対応できることが分かったため、Compueter Vision APIとText Analytics APIを連携させて、改めてラテン語の歌詞の印刷物の言語判定を試してみます。

言語判定に関しては下記のコードを使用しました。前回使用したコードにText Analytics APIによる分析を追加したもので、OCRでテキストデータ化した文字列を、そのままText Analytics APIに渡して言語判定を行っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
#!/usr/bin/env python #coding:utf-8 import httplib, urllib, base64, sys import json # OCR機能 (Computer Vision API) def ocr(img_url, key, lang): body = { 'url':img_url } headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': key } params = urllib.urlencode({ # Request parameters 'language': lang, 'detectOrientation ': 'true' }) conn = httplib.HTTPSConnection('westus.api.cognitive.microsoft.com') conn.request("POST", "/vision/v1.0/ocr?%s" % params, json.dumps(body), headers) response = conn.getresponse() data = json.loads(response.read()) conn.close() return data # 言語判定 (Txet Analytics API) def ta_detect_lang(text, key, num): body = { "documents": [ { "id": "1", "text": text } ] } headers = { # Request headers 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': key } params = urllib.urlencode({ # Request parameters 'numberOfLanguagesToDetect': num }) conn = httplib.HTTPSConnection('westus.api.cognitive.microsoft.com') conn.request("POST", "/text/analytics/v2.0/languages?%s" % params, json.dumps(body), headers) response = conn.getresponse() data = json.loads(response.read()) conn.close() return data # 処理設定 setting = { 'rectangle': 'true' } # 入力設定 input_params = { 'computer_vision': { 'img_url':'http://********** {画像URL}', 'language': 'unk' }, 'text_analytics': { 'num_of_detect': 1 } } # APIキー cognitive_keys = { 'computer_vision': '********** {Computer Vision APIキー}', 'text_analytics': '********** {Text Analytics APIキー}' } # OCRの使用 ocr_data = ocr(input_params['computer_vision']['img_url'], cognitive_keys['computer_vision'], input_params['computer_vision']['language']) # テキストデータ化 output = '' for txt_lines in ocr_data['regions']: for text_words in txt_lines['lines']: for text_word in text_words['words']: if ocr_data['language'] == 'ja': # 日本語(スペースなし) output += text_word['text'] else: # 欧米言語(スペース区切り) output += text_word['text'] + ' ' output += '\n' output += '\n' print('language:' + ocr_data['language'] + '\n') print(output) # Text Analytics APIの言語判定 ta_lang = ta_detect_lang(output, cognitive_keys['text_analytics'], input_params['text_analytics']['num_of_detect']) print('Text Analytics API\nLanguage: ' + ta_lang['documents'][0]['detectedLanguages'][0]['name']) |
上記コードにてラテン語の歌詞を認識させると、「Language: Latin」と正しく言語判定させることができました。
他、日本語、ドイツ語でも試しましたが、いずれもText Analytics APIで正しく言語判定ができており、APIを連携させることで正確に言語判定を行えることがわかりました。
今回はText Analytics APIとComputer Vision APIを使って印刷物の言語判定を行いましたが、Computer Vision APIでは対応しきれない言語判定も、言語判定に特化したText Analytics APIで補うことで精度を高められることがわかりました。
このケースはニッチな用途にしか適応できませんが、Cognitive ServicesではBing Speech APIなど20以上のAPIが用意されているため、APIの連携により汎用的、実用的な機能の開発ができるのではないでしょうか。
次回は、Bing Speech APIのText to Speech機能を併用して印刷物の読み上げ機能を検証していきます。
お楽しみに!
