
前回「Kaggleコンペに10分で挑戦、ChatGPTが変えるデータ分析の未来」でOpenAIのChatGPTと共に、Kaggleコンペの有名な「Titanic」データセットを使ったデータ分析に取り組みました。TitanicのデータはChatGPTが事前に知っているため、深いアドバイスが得られました。今回は、企業内で利用されるような、ChatGPTが事前に知らない実際のデータを対象に、データ分析の力を試してみたいと思います。
具体的には、全国1700を超える市区町村における13年分にわたる小売販売額データと人口データを組み合わせた分析を実施します。このような大規模なデータを扱う際には、データの前処理や分析が難しくなることがありますが、ChatGPTと一緒に作業することでスムーズに進めることができました。
データの前処理において、欠損値や不要な列の削除、データ型の変換などをChatGPTと行いました。その後、1人あたりの小売販売額や人口・世帯数の変化を計算し、データの特徴を理解しやすくするために可視化を行いました。
その結果、市区町村ごとの小売販売額や人口の変化を捉えることができ、特定の条件に基づいてデータを絞り込んで分析することも可能でした。このように、ChatGPTと連携してデータ分析を行うことで、大規模なデータセットでも効率的かつ柔軟に対応することができます。これからも、企業内データ分析やデータサイエンスの領域で、ChatGPTの活用を検討してみてはいかがでしょうか。
なお、企業内のデータを扱うときはOpenAIではなく、データセキュリティを考慮してAzure OpenAI Serviceの利用を推奨します。
はじめに:データについて
オープンデータ2つを使って分析を行います。
1つ目のデータセット: 小売販売額
経済産業省『商業統計』から取得した、市区町村別の小売販売額(小売業年間商品販売額)を時系列で整理したCSVファイル(小売販売額(小売業年間商品販売額):経済産業省『商業統計』(CSV形式:245KB))です。小売販売額は、市区町村に所在する事業所(小売業)における年間の有体商品の販売額の合計で、消費税額を含みます。このデータは1974年から2007年までの期間をカバーしており、市区町村単位は2014年4月時点のものを使用しています。また、市区町村コードは総務省『全国地方公共団体コード』に基づいています。
2つ目のデータセット: 人口・世帯数
e-stat(統計表)から取得した、市区町村の人口・世帯数のデータです。各市区町村の総人口(人)と世帯数(世帯)が含まれています。
データへのリンクを張ることはできないため、e-stat から人口・世帯数データをダウンロードします。
これら2つのデータセットを組み合わせて、市区町村ごとの小売販売額の変化や人口・世帯数の変化を分析し、それらの関連性や特徴を探ることが目的です。
2つのデータセットを結合
2つのファイルを組み合わせてデータ分析を進める方法について説明します。重要なポイントは、両方のファイルに含まれる年度が異なるため、どのようにしてデータをマージするかが問題となります。この問題を解決するために、ChatGPTが提案した方法を利用しました。
年度が異なるため、ChatGPTに提案してもらった「find_nearest_year」という関数を使って、最も近い年度を見つけてデータをマージする方法を採用しました。この関数は、指定された年度と利用可能な年度のリストから、最も近い年度を返すように設計されています。
|
1 2 3 4 5 6 7 8 9 |
def find_nearest_year(year, available_years): nearest_year = min(available_years, key=lambda x: abs(x - year)) return nearest_year # 人口データの年度リスト population_years = [1980, 1985, 1990, 1995, 2000, 2005, 2010, 2015] # 販売データの年度リスト sales_years = [1974, 1976, 1979, 1982, 1985, 1988, 1991, 1994, 1997, 1999, 2002, 2004, 2007] |
この関数を使って、人口データと小売販売額データを最も近い年度でマージし、統合されたデータセットを作成することができました。これにより、異なる年度のデータを効果的に組み合わせて分析を進めることができます。
結合したデータからポイントを絞って抽出
全国の1700を超える市区町村にわたる13年分のデータを分析することになりますが、そのままではデータ量が多すぎて分析が難しいことが予想されます。そこで、データを簡略化するために、1974年と2007年の2つの年度に焦点を当てることにしました。これにより、分析が容易になるだけでなく、長期的な変化の概要も把握することができます。このアプローチは、ChatGPTが提案してくれた方法です。
まず、全国1700超の市区町村における1974年と2007年の小売販売額と人口データを抽出しました。これにより、期間中の人口変化や小売販売額の変化を比較しやすくなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 必要な列を抽出 columns_to_keep = ['市区町村名', '1974年', '1974年_総人口', '2007年', '2007年_総人口'] data_filtered = sales_data_with_population[columns_to_keep] # 数値を整数に変換 data_filtered['1974年'] = data_filtered['1974年'].str.replace(',', '').replace('−', '0').astype(int) data_filtered['2007年'] = data_filtered['2007年'].str.replace(',', '').replace('−', '0').astype(int) data_filtered['1974年_総人口'] = data_filtered['1974年_総人口'].str.replace(',', '').astype(float) data_filtered['2007年_総人口'] = data_filtered['2007年_総人口'].str.replace(',', '').astype(float) # 1人あたりの小売販売額を計算 data_filtered['1974年_1人あたり'] = data_filtered['1974年'] / data_filtered['1974年_総人口'] data_filtered['2007年_1人あたり'] = data_filtered['2007年'] / data_filtered['2007年_総人口'] # 人口や世帯数の変化を計算 data_filtered['人口変化'] = (data_filtered['2007年_総人口'] - data_filtered['1974年_総人口']) / data_filtered['1974年_総人口'] print(data_filtered.head()) |
データを絞り込んだ後、1974年と2007年の人口と小売販売額を基に、人口変化と小売販売額の変化を計算しました。これにより、市区町村ごとの人口変化の影響をより明確に把握できます。
このように、ChatGPTの提案に従って1974年と2007年にフォーカスし、データを抽出・整理することで、期間中の人口と小売販売額の変化を効果的に分析することができました。今後の章では、このデータを用いてさらに詳細な分析を行います。
可視化・分析:小売販売額からの考察
加工されたデータをChatGPTの勧めに合わせて可視化しました。
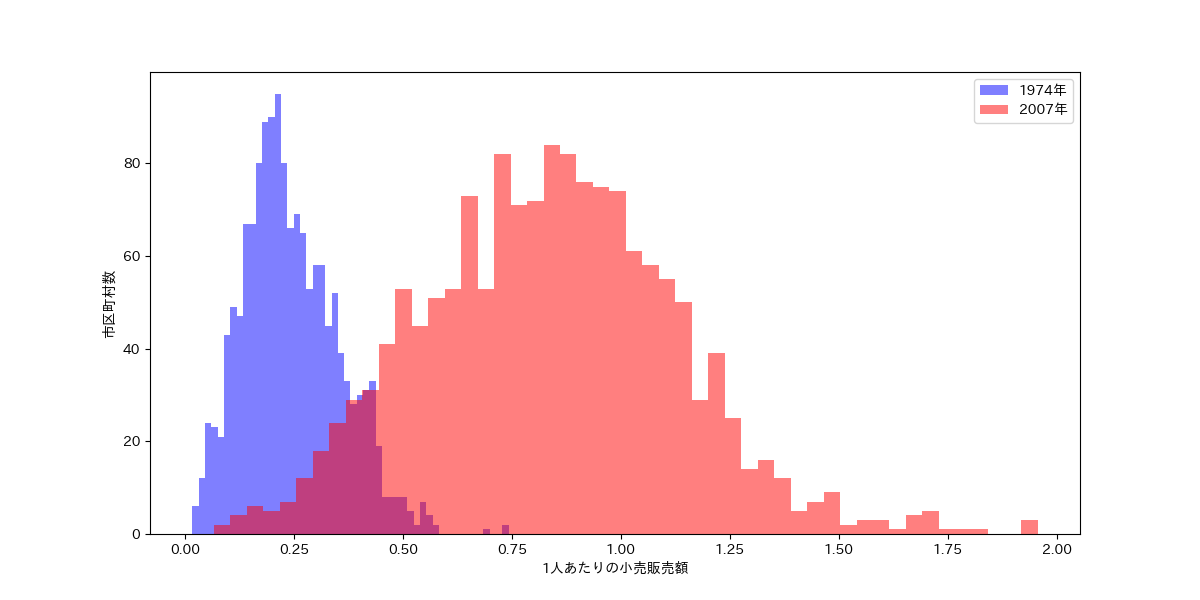
図を見ると、1人あたりの小売販売額は物価の変動に合わせて基本的に 2007年>1974年であることがわかります。
ここから、以下の2つを確認してみました。
- 市区町村で小売販売額が 2007年<1974年になっているところがあるか?
- 1人あたりの小売販売額が 2007年<1974年になっているところがあるか?
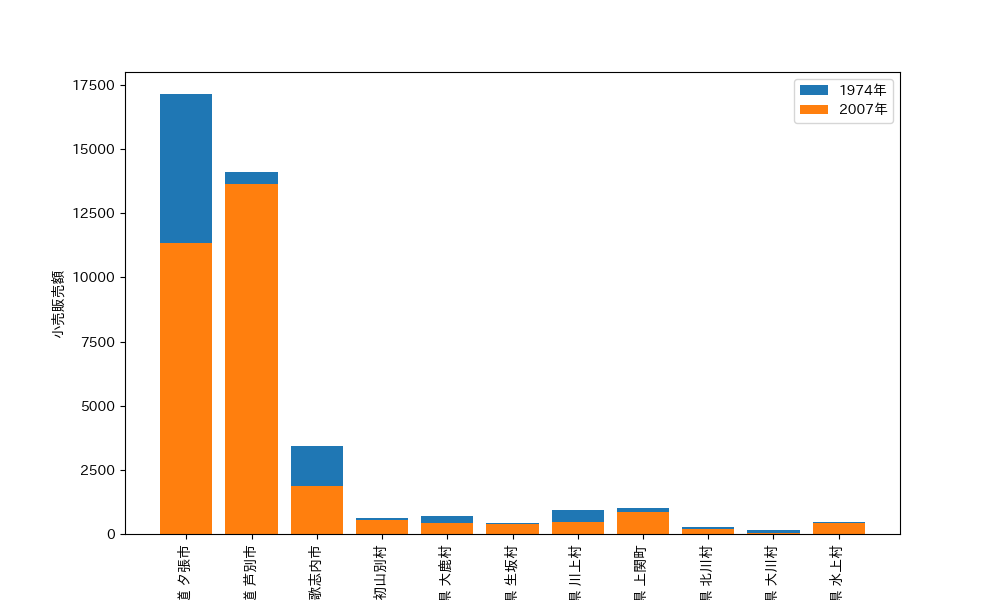
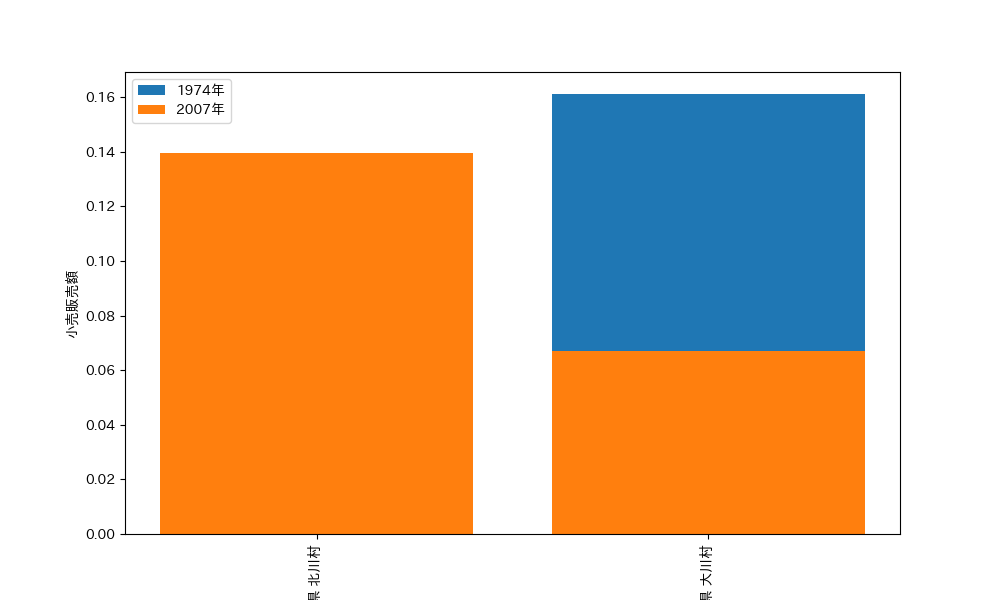
それぞれの結果についてもChatGPTに考察してもらいました。
1つ目の考察:これらの市区町村を見ると、いくつかの共通点が見られます。
- 地域性:これらの市区町村は、北海道、長野県、奈良県、山口県、高知県、熊本県といった地域に位置しています。これらはいずれも日本の農村や山間部に位置することが多く、都市部と比べて人口密度が低いことが特徴です。
- 人口減少:これらの地域は、過去数十年間で人口が減少している傾向があります。これは、若者が都市部への移住を選択し、地域の高齢化が進んでいることが一因とされています。
- 地域産業:これらの地域では、農業、林業、漁業などの第一次産業が主な産業となっており、小売業の規模が都市部に比べて小さいことが一般的です。また、これらの地域は観光資源も限定的であるため、観光客による小売販売額の増加も見込めない場合があります。
このような共通点から、2007年より1974年の方が小売販売額が少ない市区町村は、地域性や人口減少、地域産業の特徴が影響していると考えられます。これらの要因を考慮することで、地域の小売販売額の変化をより深く理解することができます。
2つ目の考察:高知県北川村と高知県大川村で、1人あたりの小売販売額が2007年より1974年の方が少ない理由については、いくつかの要因が考えられます。
- 地域の経済状況の変化:これらの村では、1974年から2007年の間に地域の経済状況が変化した可能性があります。例えば、地域産業が拡大し、雇用機会や所得が増加したことで、1人あたりの小売販売額が上昇したと考えられます。
- 消費パターンの変化:時代の変化とともに、消費者の購買行動や消費パターンが変化したことが影響しているかもしれません。例えば、インターネットの普及や交通インフラの発展により、住民が都市部や他地域での購入が容易になり、地域内での小売販売額が増加した可能性があります。
- 観光客の増加:これらの村が観光資源を活用し、観光客が増加したことが1人あたりの小売販売額の上昇に寄与している可能性があります。観光客が増加することで、地域の小売業者にとって新たなビジネスチャンスが生まれ、小売販売額が増加することが考えられます。
- 人口減少の影響:これらの村では人口が減少している傾向があるかもしれません。人口が減少する一方で、地域内での小売販売額がある程度維持された場合、1人あたりの小売販売額は自然と上昇します。
これらの要因が複合的に影響し、高知県北川村と高知県大川村で1人あたりの小売販売額が2007年より1974年の方が少なくなっていると考えられます。ただし、具体的な理由を特定するには、これらの村の地域状況や経済データを詳細に調査する必要があります。
このように小売販売額データ 約2万6千個、人口データ 約9万個というデータの中からChatGPTと協力することで特徴的なデータを見つけることが出来ました。
可視化・分析:人口変化からの考察
加工されたデータをChatGPTの勧めに合わせて可視化しました。
1人あたりの小売販売額と人口変化を散布図にしてみました。この中で人口変化が大きい・小さい/1人当りの販売額変化が大きい・小さいで比較してみました。
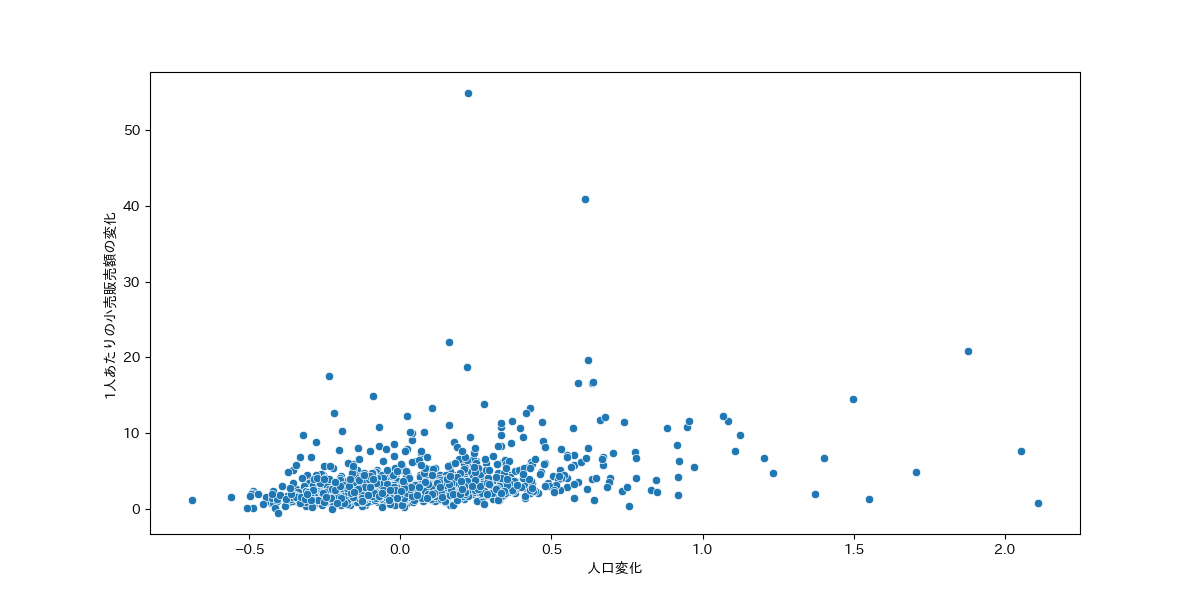
人口変化にフォーカスすると、人口が大きく増えているところも逆に減っているところも概ね1人あたりの小売販売額は伸びています。ただし、人口が増えているところには3か所1.0(百万円)を超すところがあるのがわかります。
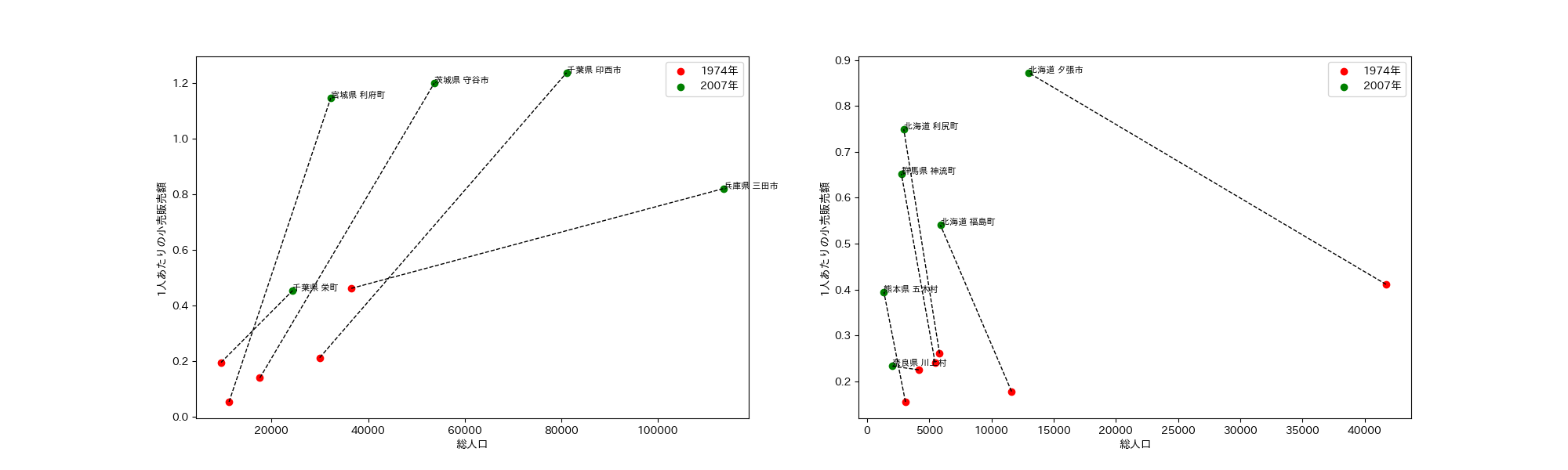
1人あたりの小売販売額にフォーカスすると販売額が増えている上位市区町村は人口も増えており、販売額が増えていないところは人口が減っていることがわかります。

再び強調しますが、ChatGPTと協力することで時間をかけずに企業内のデータも分析することが出来ます。
まとめ
本記事では、ChatGPTを活用して企業内のデータ分析を行う方法を紹介しました。具体的には、全国1700以上の市区町村の小売販売額と人口データを組み合わせた実例を通じて、ChatGPTが未知のデータに対しても、データの組み合わせや分析手法の提案をChatGPTから受けることで、効率的に深い洞察を得ることができることを示しました。
将来的には、このようなデータ分析の取り組みが企業内でより一層進化し、より複雑で大規模なデータセットや分析手法に対応できるようになるでしょう。その際には、企業内のデータを扱う場合は、Azure OpenAI Serviceを利用することで、より安全で効率的にデータ分析を行うことができます。
この記事を読んだ皆さんにとって、ChatGPTを使ったデータ分析が新たな視点やアイデアを提供し、ビジネス上の課題解決や戦略立案に役立てることができることをお伝えできたら幸いです。今後もAI技術の進化を活用し、データ分析の可能性を広げていきましょう。
