データドリブンな意思決定は、ビジネスにおいてますます重要になっています。最近のAI技術の進歩により、ビジネスアナリストが効率的かつ迅速にデータ分析を行うことが可能になりました。この記事では、OpenAIのChatGPTを活用してデータ分析を進化させる方法を解説します。ChatGPTは、データ分析プロセス全体をサポートし、結果の可視化や洞察を提供することができます。今すぐ、AIと協働してデータ分析を次のレベルへと引き上げましょう!
はじめに: ChatGPTとデータ分析の進化
近年のAI技術の進化は、データサイエンスの世界にも大きな影響を与えています。特に、OpenAIのChatGPTのような高度な自然言語処理技術は、従来のデータ分析手法に革新をもたらす可能性があります。この記事では、Kaggleのタイタニックデータセットを例に、ChatGPTを活用してデータ分析の効率化や精度向上を実現する方法について解説します。
タイタニックデータセットによるデータ分析の基本 タイタニックデータセットは、1912年に起きたタイタニック号の沈没事故で乗船していた乗客の情報をまとめたものです。このデータセットを用いて、機械学習モデルを構築することで、様々な要因から生存率を予測することができます。ここでは、データ分析の基本的なプロセスを説明します。
データの理解
Kaggleのタイタニックコンペティションは、機械学習の基本的なスキルを練習するのに適した入門コンペです。このコンペティションでは、タイタニック号の乗客データを利用して、どの乗客が生存したかを予測するモデルを作成することが目的です。以下に、データ分析からモデル構築、精度向上までの一連のプロセスを詳しく説明します。
データの理解を進めるためには、以下のステップを実行することが効果的です。これらのやり取りをChatGPTと行うことで、より深くデータを理解することができます。
- データの観察:
まず、データをエクセルやPythonのPandasライブラリを使って表示し、生のデータを直接観察しましょう。データの形式や各特徴量の範囲を確認することができます。 - 基本的な統計量の計算:
Pandasを使って、各特徴量の平均、中央値、標準偏差、最小値、最大値などの基本的な統計量を計算します。これにより、データの傾向や分布を把握することができます。 - データの可視化:
各特徴量のヒストグラムや箱ひげ図、散布図などを作成し、データの分布や相関関係を視覚的に理解しましょう。PythonのMatplotlibやSeabornライブラリが可視化に役立ちます。 - ターゲット変数との関係の調査:
ターゲット変数(この場合はSurvived)と各特徴量の関係を調べることで、どの特徴量が重要そうかを把握できます。例えば、性別やチケットクラス別の生存率を計算したり、年齢と生存率の散布図を作成したりします。 - 欠損値と異常値の確認:
各特徴量について欠損値や異常値が存在するか確認します。欠損値が多い特徴量や異常値が存在する場合、データ前処理の段階で適切に処理する必要があります。
ChatGPTと行うデータの理解
ChatGPTと一緒に行うことで以下のようなことが可能です。
カラムの情報からChatGPTが以下のようなヒントをもらうことが出来ます。
タイタニックデータに対して「データの観察」をして、わかりやすく説明してください。
データを観察すると、いくつかの特徴がわかります。
- 生存率は、乗客の階級や性別によって異なる可能性があります。
- 年齢は欠損値が含まれており、データ分析や前処理が必要です。
- 同乗している家族の数(SibSp、Parch)によって、生存率が変わるかもしれません。
- 運賃や客室番号など、乗客の階級に関連する情報が含まれています。
- 乗船した港によって、生存率に違いがあるかもしれません。
データをもう少し詳しく観察すると、以下のような特徴が見られます。
Pclass(乗客のクラス): 1, 2, 3の3つの異なる値があり、それぞれ1等クラス、2等クラス、3等クラスを示しています。クラスが高いほど、より豪華な設備やサービスが提供されていたと考えられます。SibSp(乗船している兄弟・配偶者の数)とParch(乗船している親・子供の数): これらの特徴は、乗客が一緒に旅行している家族の大きさを示しています。これらの値を合計することで、家族全体の大きさを求めることができます。Ticket(チケット番号): チケット番号には、様々な形式の文字列が含まれています。これは、チケットが異なる販売元や方法で発行されたことを示しているかもしれません。Fare(運賃): 運賃は、乗客がチケットに支払った金額を示しており、様々な範囲の値が含まれています。運賃は、Pclassや乗船した場所などの要因によって異なることが考えられます。Cabin(客室番号): 客室番号は、乗客が滞在していた場所を示しています。客室番号の最初の文字は、客室がどのデッキにあるかを示しています(例:Aデッキ、Bデッキなど)。ただし、多くの乗客の客室番号が欠損していることに注意してください。Embarked(乗船した港): 乗客がタイタニック号に乗船した港を示しており、C(シェルブール)、Q(クイーンズタウン)、S(サウサンプトン)の3つの異なる値があります。
これらの特徴を考慮して、生存率との関連性を分析することで、タイタニック号の沈没に関する興味深い洞察を得ることができます。
この中でも家族構成を切り口にするのが面白そうなのでさらに解説してもらいました。
「SibSp(乗船している兄弟・配偶者の数)とParch(乗船している親・子供の数): これらの特徴は、乗客が一緒に旅行している家族の大きさを示しています。これらの値を合計することで、家族全体の大きさを求めることができます。」とありますが、これを見ることでどんな事がわかりますか?
ChatGPTからは以下のような回答が返ってきました。多くの洞察が一瞬で返ってきました。
SibSp(乗船している兄弟・配偶者の数)とParch(乗船している親・子供の数)を合計して家族全体の大きさを求めることで、以下のような洞察が得られる可能性があります。
- 家族構成と生存率の関連性: 家族の大きさが生存率にどのような影響を与えるのかを調べることができます。例えば、一人旅の乗客と比較して、家族連れの乗客の方が生存率が高いかどうかを分析することができます。
- 家族の大きさと客室クラスの関連性: 家族の大きさが客室クラス(
Pclass)とどのように関連しているかを調べることができます。例えば、大家族はどのクラスに多く乗っていたのか、または家族の大きさがクラスごとにどのように分布しているかを分析できます。 - 家族の大きさと運賃の関連性: 家族の大きさが運賃(
Fare)とどのように関連しているかを調べることができます。大家族の場合、運賃が高いことが予想されますが、実際にどの程度影響があるのかを分析できます。 - 家族の大きさと乗船港の関連性: 家族の大きさが乗船港(
Embarked)とどのように関連しているかを調べることができます。特定の港から乗船した家族の大きさに特徴があるかどうかを分析できます。
これらの洞察は、タイタニック号の沈没に関する様々な要因と生存率の関係を理解するために役立ちます。また、これらの情報を用いて、機械学習モデルの予測性能を向上させる特徴エンジニアリングを行うことができます。
実装
実装もChatGPTがサポート(というか実施)してくれます。
教えてくれたアプローチを使って「データの読み込み、データの前処理、特徴間の関係の可視化、相関分析」までをPythonでやりたいです。手順とスクリプトを教えてください。
コードは割愛しますが、実施すると以下のような図が出力されました。
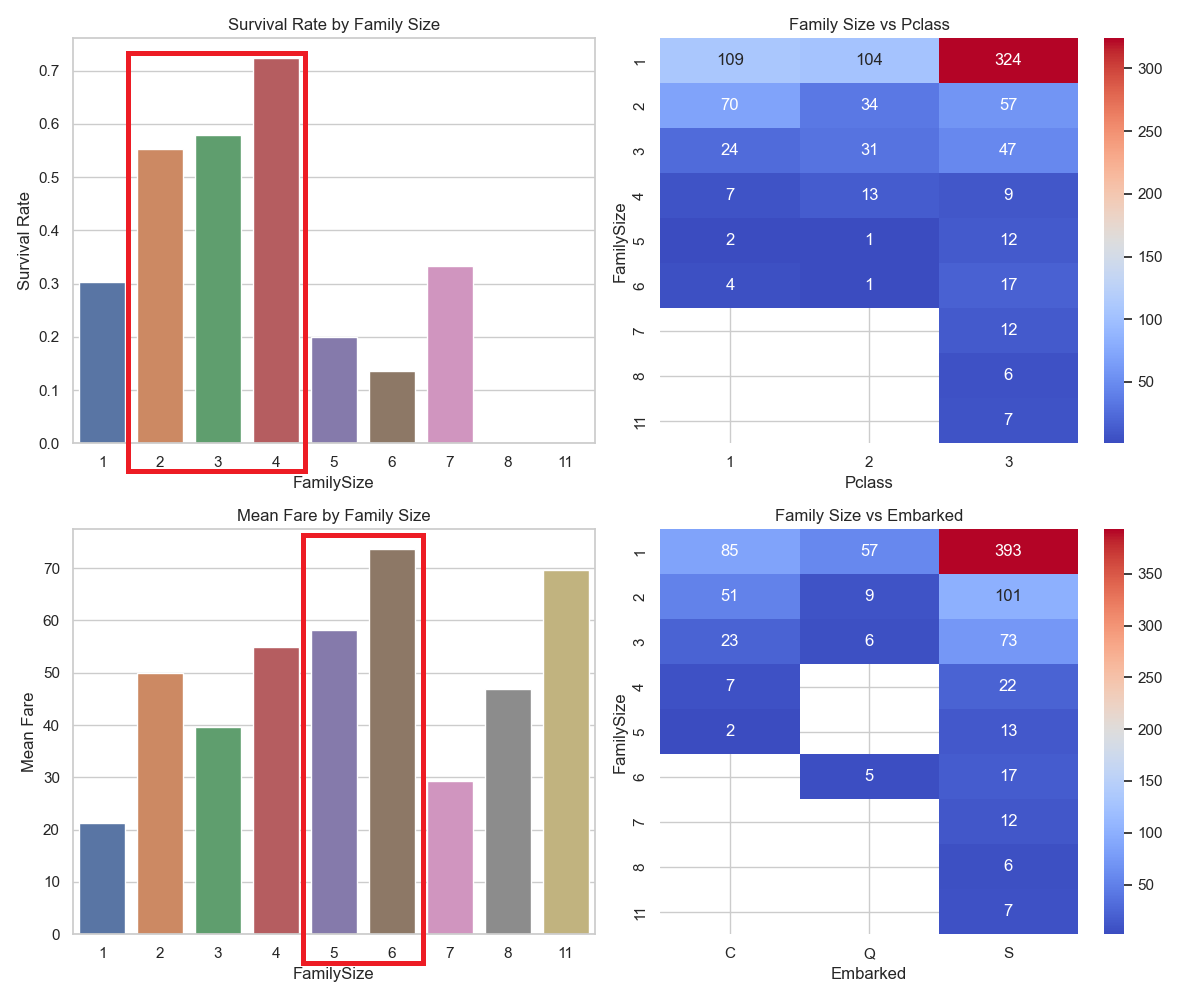
上記の図から家族構成ごとの生存率や等級別の人数構成などを把握することができます。
例えば、2-4人で参加している人は5-6人で参加した人に比べて生存率が高く、逆に運賃は5-6人が高くなっております。このことから運賃が高いほど生存率が下がるかを確認してみました。
以下の通り、1等(高い)ほど生存率が高くなっています。なぜ5-6人の場合、運賃は高いのに生存率が低くなっているのでしょうか?
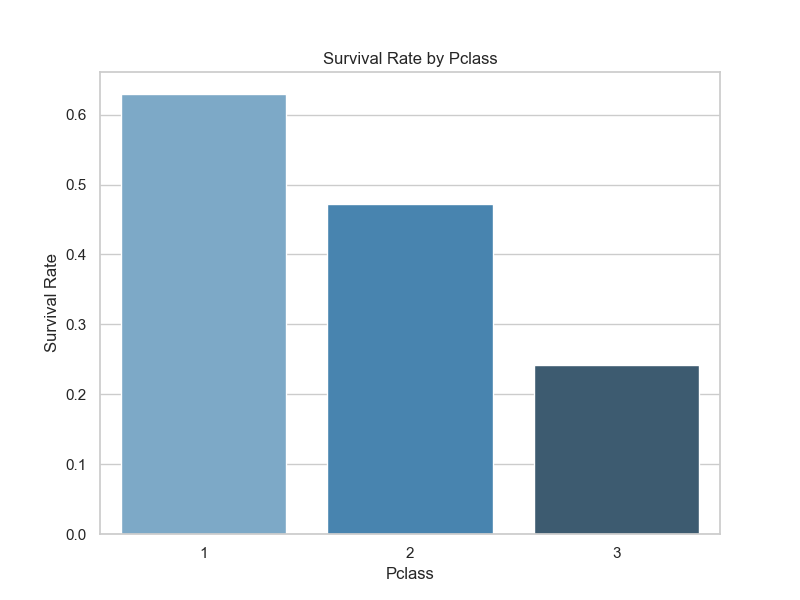
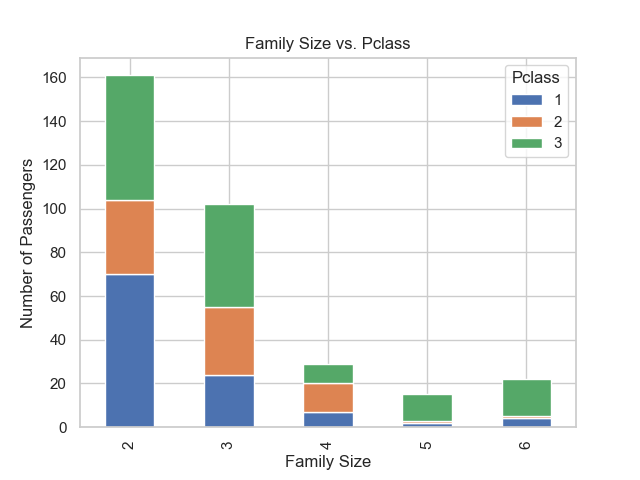
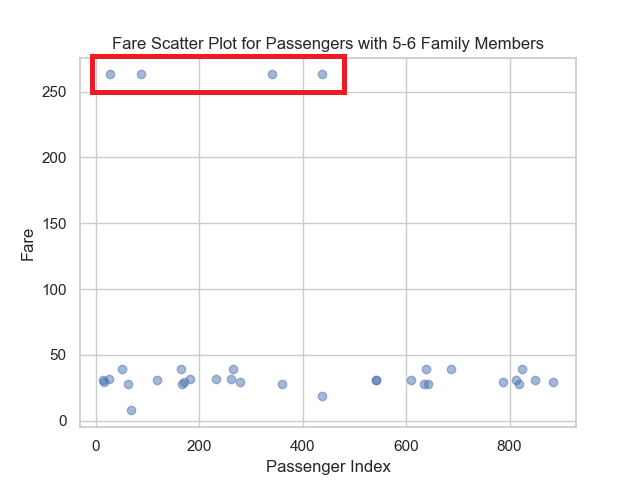
下図から、5-6人は生存率が低い3等に乗船している比率が高い(=生存率が低い)ものの運賃の平均値が高くなっております。もう1つの図をみることで一部の乗客が非常に高額な運賃で乗船しているために運賃の平均値が上がっていることがわかります。
ここまでのアプローチをわずか10分程度で行うことができます。通常であれば、データサイエンティストが何時間もかけてExcelやPythonを使って試行錯誤することが、ChatGPTと行うことでスキルが無くても一瞬で行うこともできました。Pythonで実行した結果も、図でなく数値で取得するとChatGPTに投げて結果を解説してくれることもできます。
また、アプローチで見つけた洞察込みの機械学習モデルを作ることも可能です。
今までの特徴を捉えた機械学習モデルを作りたい。
と唱えるだけで、ChatGPTがPythonのスクリプトが出力され実装完了です。
まとめ
この記事では、OpenAIのChatGPTを活用してデータ分析を効率化し、洞察を得る方法を解説しました。Kaggleのタイタニックデータセットを例に、データの理解や可視化、相関分析などの一連のプロセスをChatGPTと協働して行うことで、効率的かつ迅速にデータ分析が可能となります。また、洞察を元にした機械学習モデルの構築も容易になります。これにより、データサイエンティストだけでなく、Pythonや機械学習に精通していない方も、AIの力を利用してデータ分析を行えるようになります。今後もChatGPTを活用し、データ分析の進化に取り組んでいきましょう!
