はじめに
前回行ったExcelでの簡易集計と可視化を、Azure Notebooksでやってみます。
Azure Notebooksとは?
概要
データ分析プラットフォームのデファクトスタンダード、Jupyter Notebookをクラウド環境で起動できるAzureサービスです。他にはGoogle Colaboratoryが有名ですね。
ローカルでJupyter Notebookを使う場合、環境構築でつまづくこともしばしば。クラウドであればそのあたりほんと楽です。
・数ステップでAzure上に環境設定可能
・クラウド上で共同作業可能
・メモリ4GB, ストレージ1GBまで無償
Notebookはデータサイエンティストやアナリスト専用のものではありません。
分析に都合のいいプラットフォームがそろってて、メモ書きが残せて、みんなとシェアできる、いい感じに使いやすい “ノート” だと考えて、身構えずに触ってみましょう。
インストール
まずはAzure Notebookをセットアップします。 手順はこちら。Microsoftアカウントがあればすぐに数ステップでできます。
操作のきほん
初めてNotebookに触れる人のために、基本操作とショートカットをご紹介します。
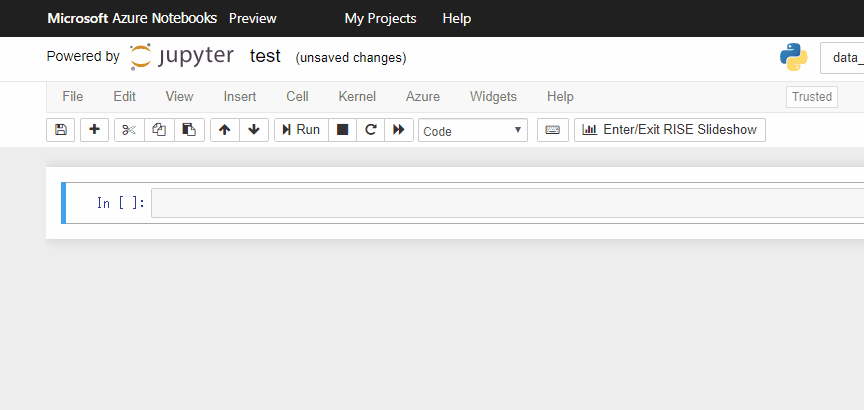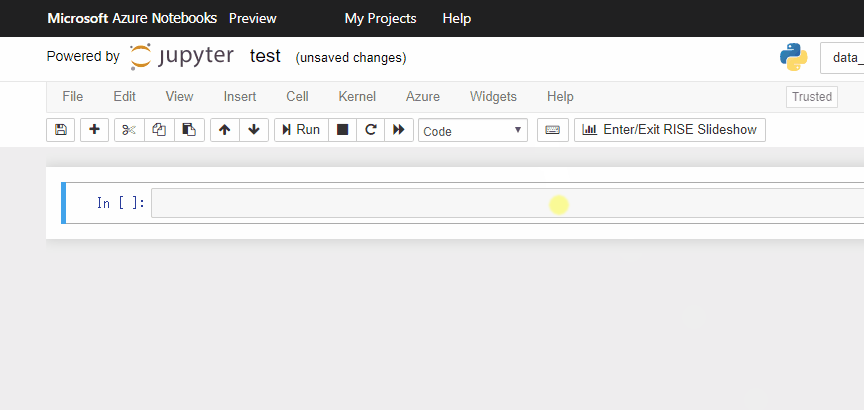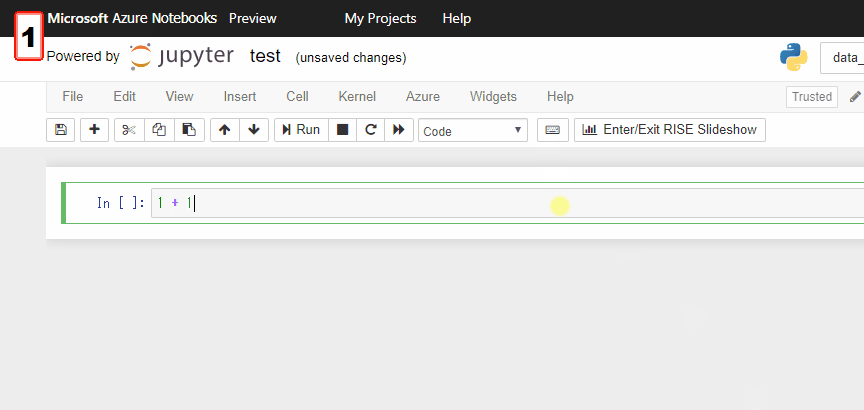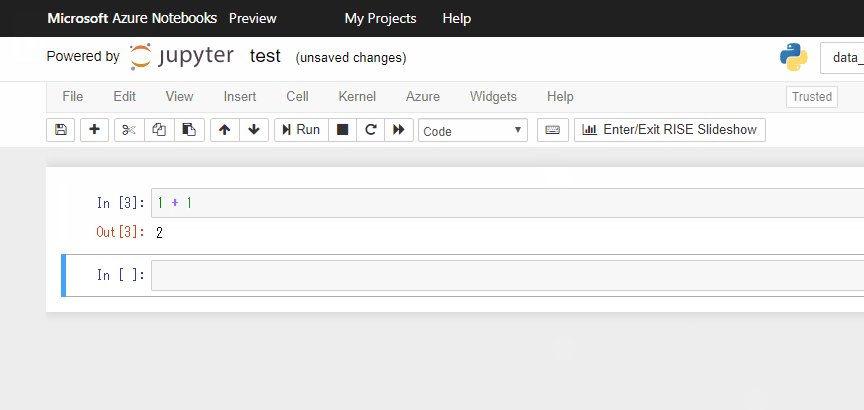
セルを選択、コード入力後、Shift + Enterでそのセルのコードを実行できます。
セルの中を選択すると、枠が緑色になりEdit Modeに、セルの外を選択すると、枠が水色になりCommand Modeになります。
モード切り替えは、escとenterでも可能。
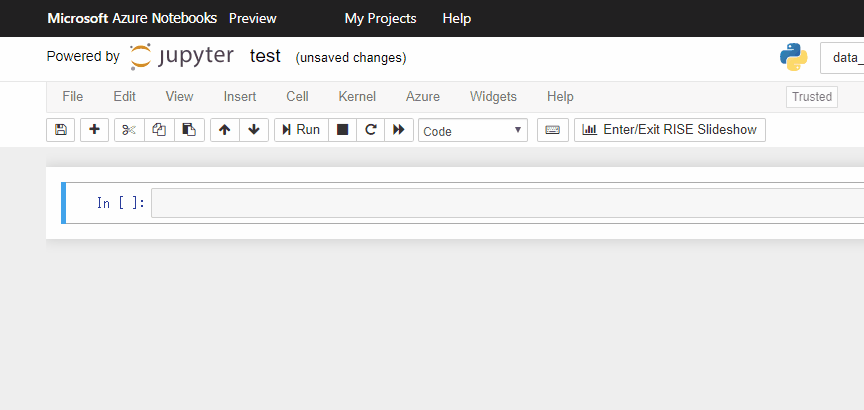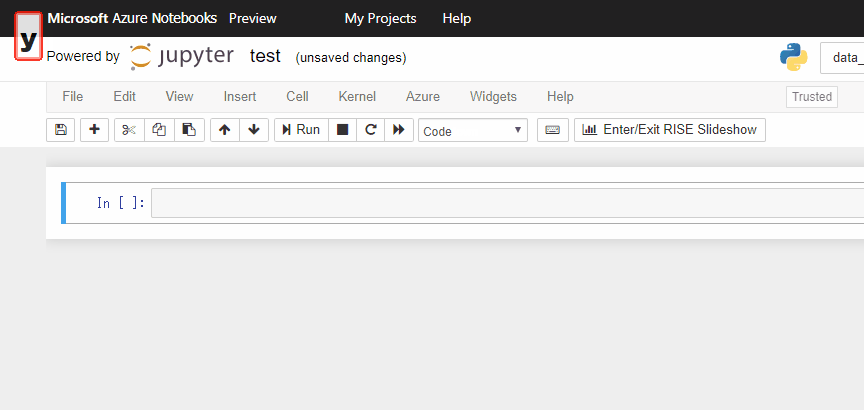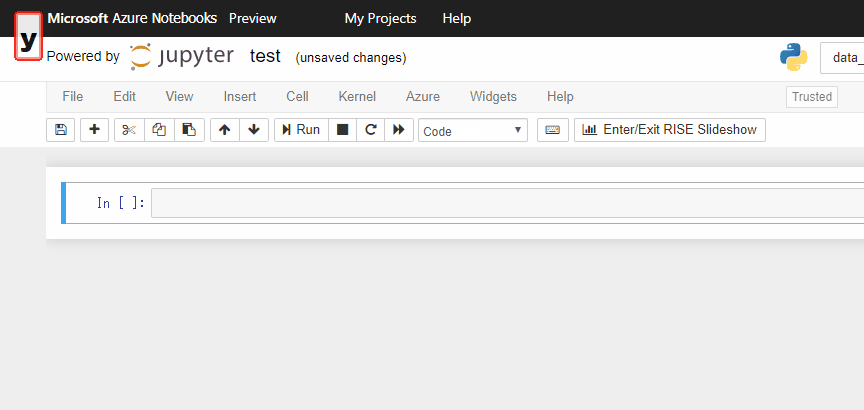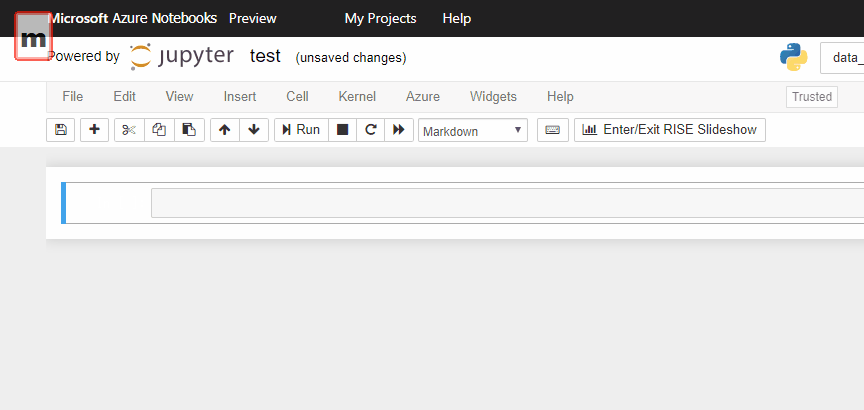
Command Modeで、mを押すとセルをMarkdownモードに、yを押すとcodeモードにできます。
これでMarkdownのメモが残せます。
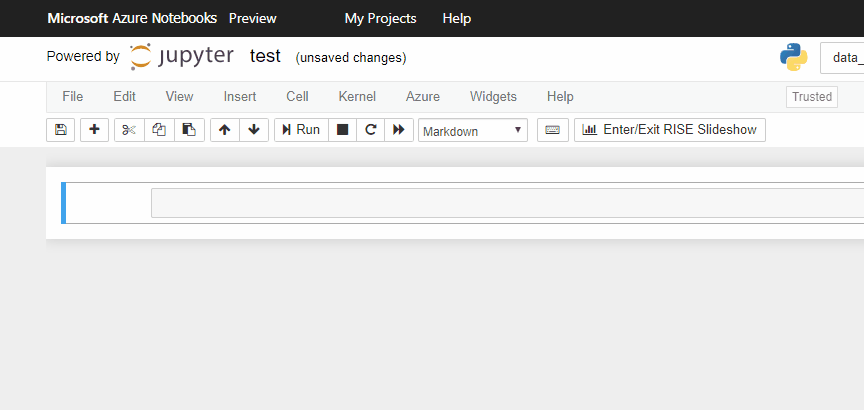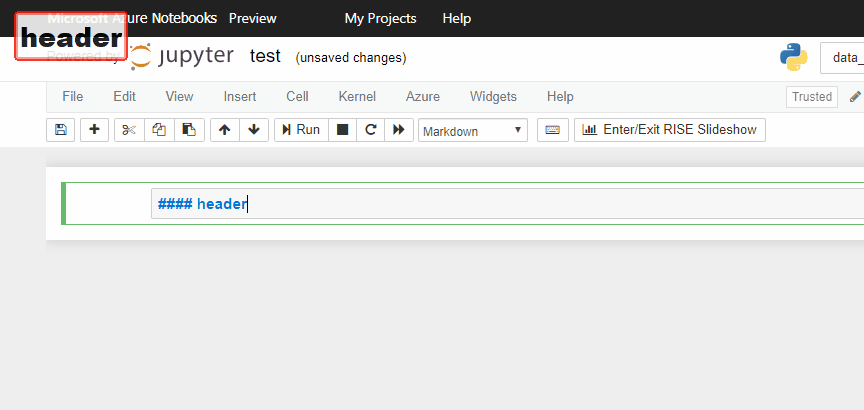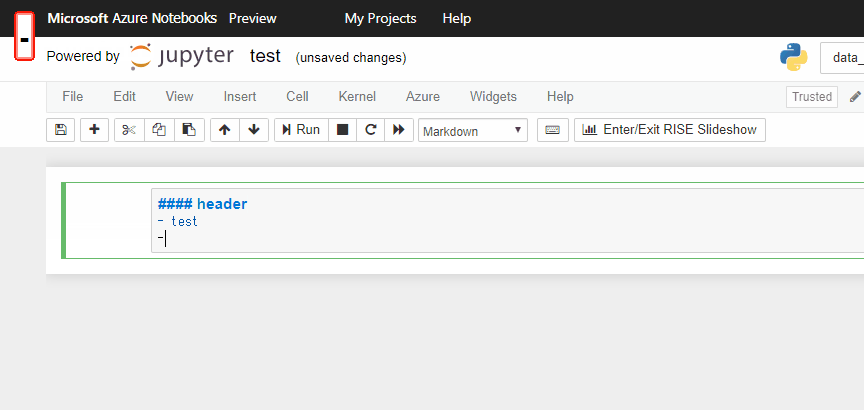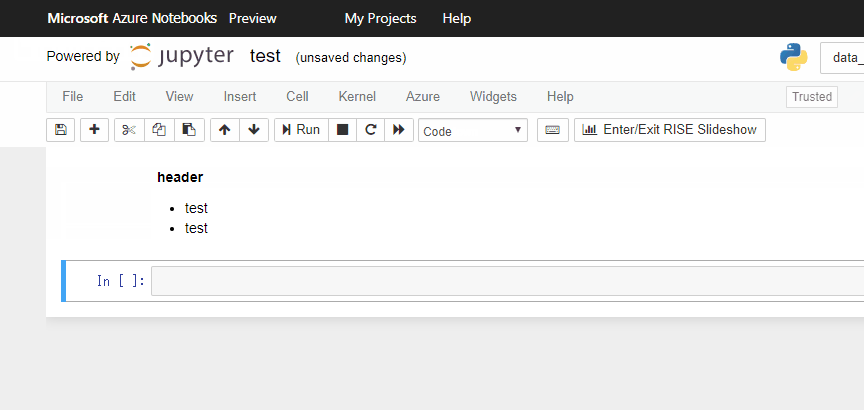
Command Modeでaを押せば上に、bを押せば下にセルを追加可能。xで削除。
Command Mode時に、上下カーソルでセルを移動できます。
編集したいセルでenterを押せば、対象セルのEdit Modeに遷移。
作業をチェックポイントとして保存したいときは、ctrl + sを押します。これでいつでもそのポイントに戻れます。
特定のセルだけ実行されないようにしておきたいな、という時はctrl + / でコメントアウトしておきます。
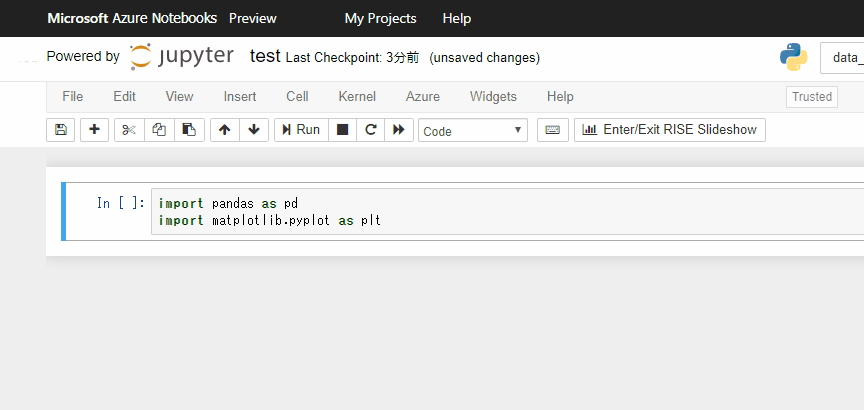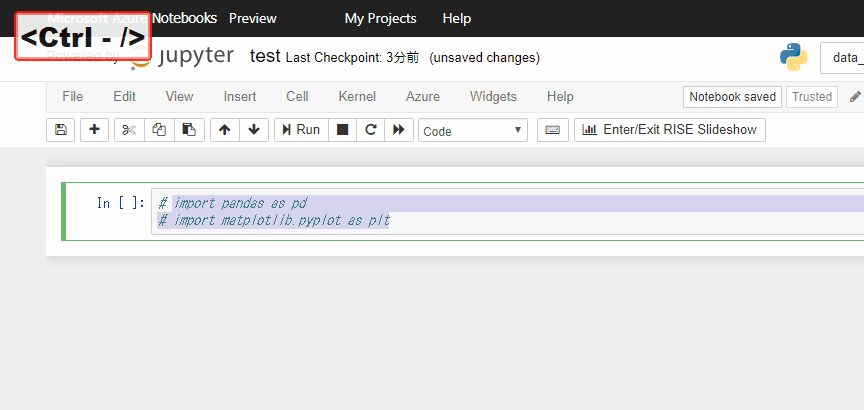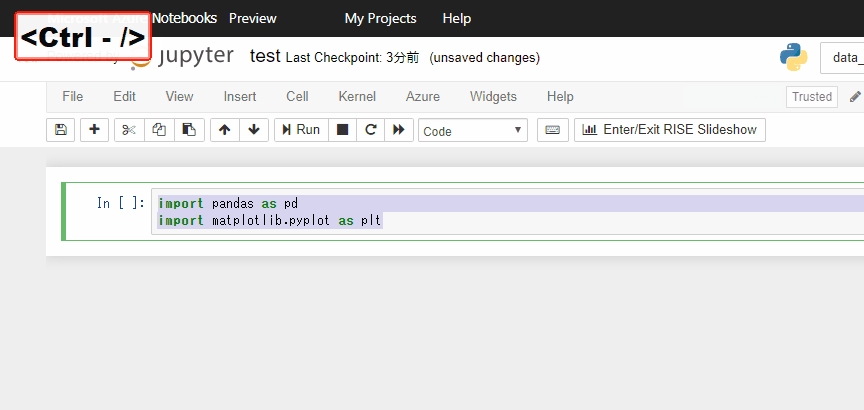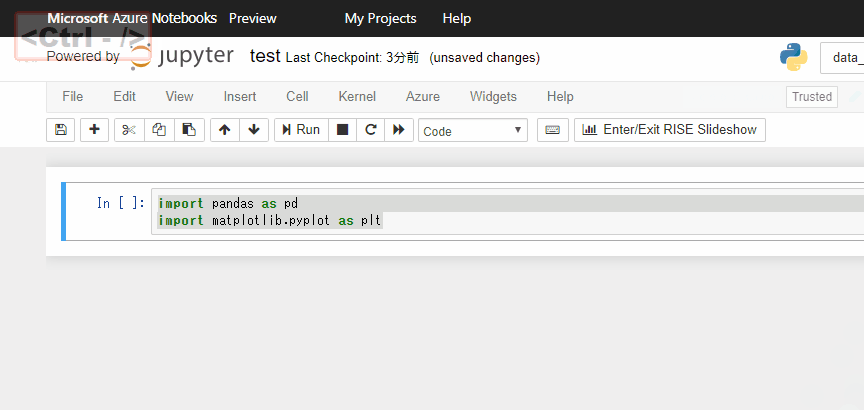
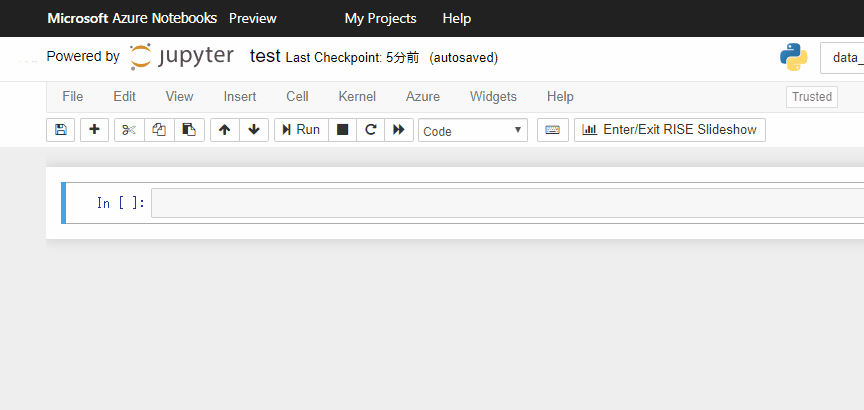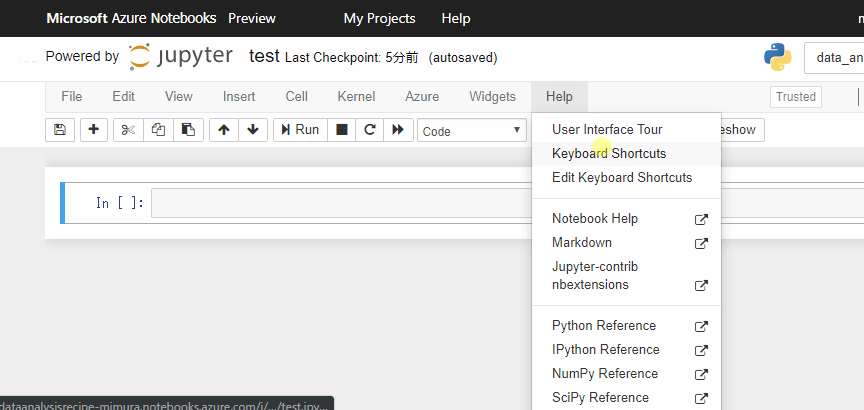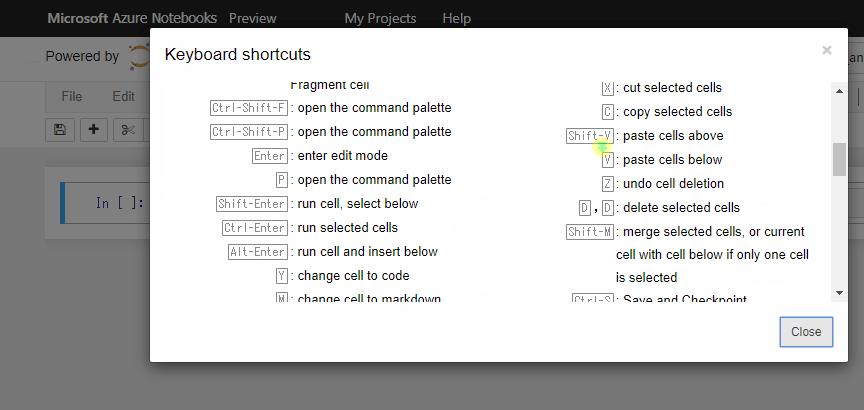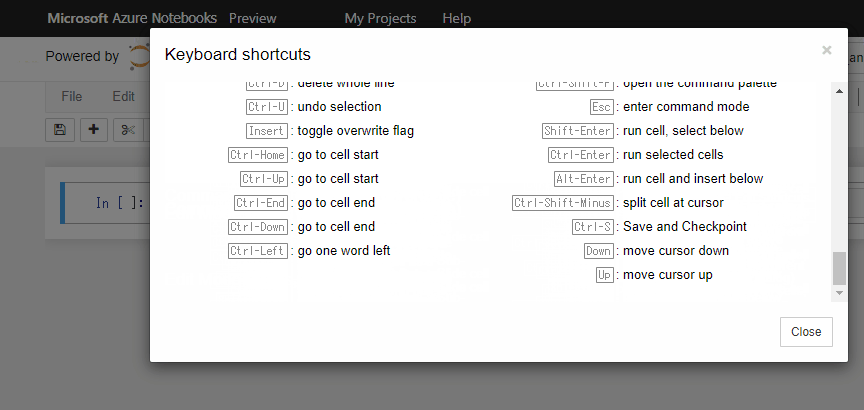
他にもショートカットはたくさんあります。一覧表はHelpを参照しましょう。
あとは触りながら覚えていけばOK。
データの準備
Brazilian E-Commerce Public Dataset by Olistから、データをダウンロード、解凍しておきます。
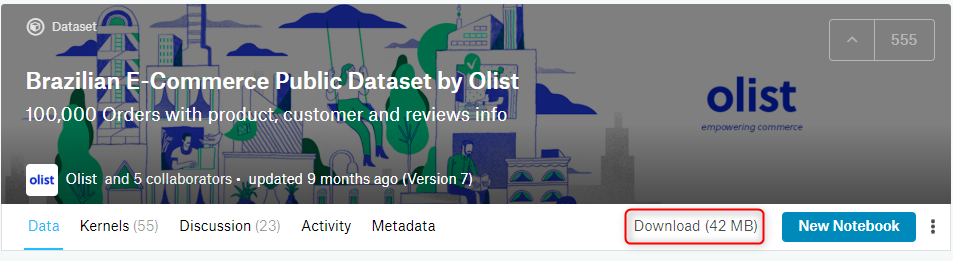
Azure Notebook を立ち上げ、作成した Notebook と同じディレクトリで、UploadタブのFrom Computerを選択
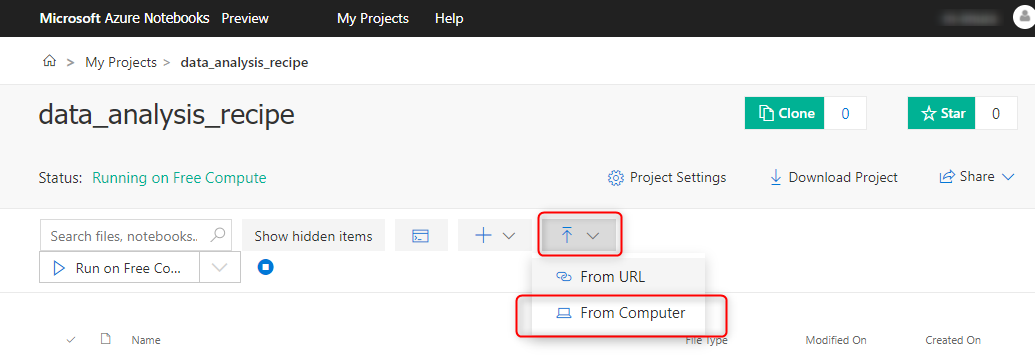
以下の画面に遷移するので、解凍先のフォルダにあるCSVデータを、ドラッグアンドドロップ。
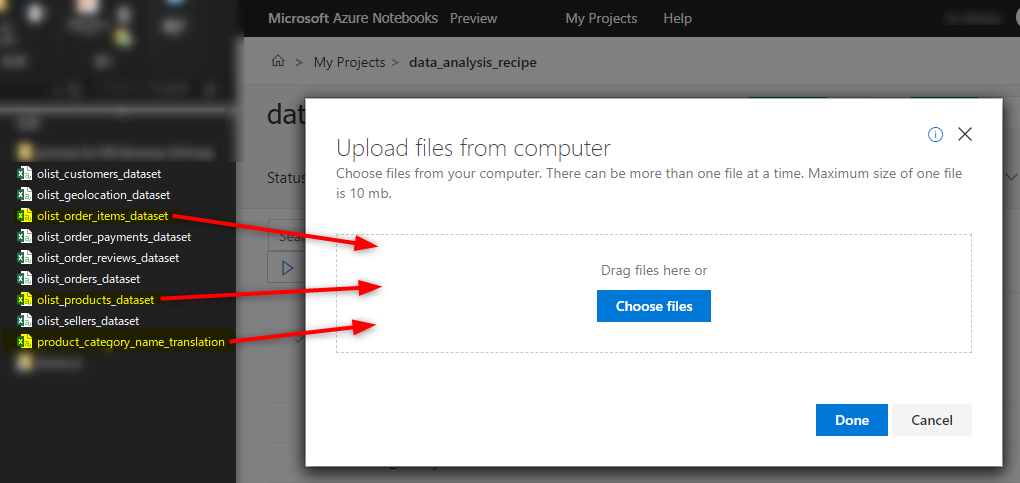
Uploadを押して、しばらく待ちます。Notebookと同じディレクトリにCSVファイルがアップロードされてれば完了です。
流れ
データの操作の定番といえば Pandas ですが、興味本位で Databricksとの比較してみたいので、並列分散処理フレームワークである PySpark を用いて中間テーブルを作成します。
そこからSQLで必要な集計処理を行い、最後に可視化のためのライブラリを使って、グラフを描画します。
手順
以下のスクリプトをNotebookのセルに入れ、実行していきます。
まずはPySpark関連のライブラリをインポート。
|
1 2 3 4 |
from pyspark.sql import SparkSession, SQLContext from pyspark.sql.functions import unix_timestamp, to_timestamp, col, desc, udf from pyspark.sql.types import DoubleType import pyspark |
次に、Sparkのコンストラクタの作成。
正直言ってこのコードが何をしているのか良くわかっていないのですが、このコンストラクタが後述のスクリプトを良しなに処理してくれるようです。
|
1 2 3 4 5 6 7 8 |
sc = pyspark.SparkContext.getOrCreate() sql = SQLContext(sc) spark = SparkSession \ .builder \ .appName("Python Spark SQL basic example") \ .config("spark.some.config.option", "some-value") \ .getOrCreate() |
アップロードしたCSVファイル名を変数に放り込んでおきます。
|
1 2 3 |
order_item = "olist_order_items_dataset.csv" products = "olist_products_dataset.csv" translation = "product_category_name_translation.csv" |
CSVファイルをSparkに読み込ませます。上から、売上テーブル、製品テーブル、翻訳テーブル。ちょっと時間がかかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
t1 = spark.read\ .format("com.databricks.spark.csv")\ .option("header", "true")\ .load(order_item)\ t2 = spark.read\ .format("com.databricks.spark.csv")\ .option("header", "true")\ .load(products)\ t3 = spark.read\ .format("com.databricks.spark.csv")\ .option("header", "true")\ .load(translation)\ |
テーブル結合のために、製品テーブルの product_id の名称を product_id2 に変更。
|
1 |
t2 = t2.withColumnRenamed('product_id', 'product_id2') |
テーブル結合のために必要な列名を確認しておきます (結果は省略)
|
1 2 3 |
t1.printSchema() t2.printSchema() t3.printSchema() |
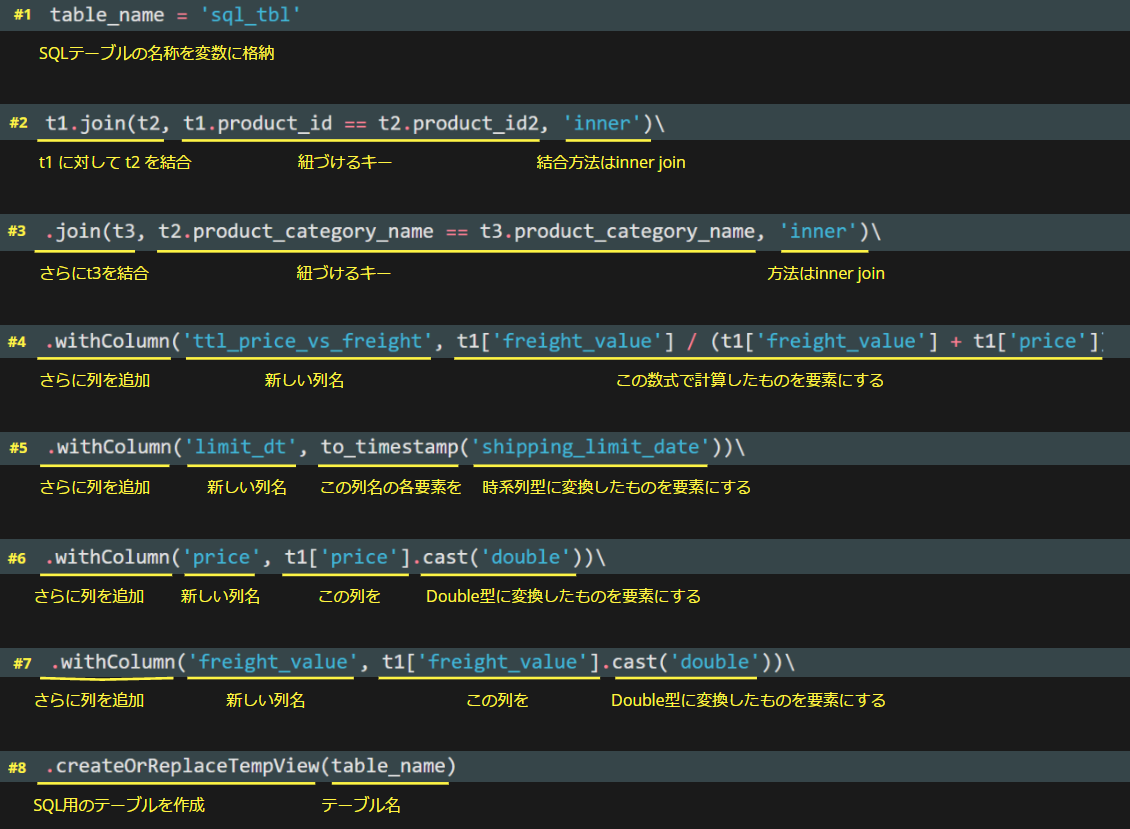
中間テーブルを作成します。※備考参照のこと
|
1 2 3 4 5 6 7 8 9 |
table_name = 'sql_tbl' t1.join(t2, t1.product_id == t2.product_id2, 'inner')\ .join(t3, t2.product_category_name == t3.product_category_name, 'inner')\ .withColumn('ttl_price_vs_freight', t1['freight_value'] / (t1['freight_value'] + t1['price']))\ .withColumn('limit_dt', to_timestamp(t1.shipping_limit_date, 'yyyy/MM/dd HH:mm'))\ .withColumn('price', t1['price'].cast('double'))\ .withColumn('freight_value', t1['freight_value'].cast('double'))\ .createOrReplaceTempView(table_name) |
作成した中間テーブルのスキーマを確認します。(これも結果省略)
|
1 2 3 4 |
# 中間テーブルの列名確認 temp_df = spark.sql(''' SHOW COLUMNS FROM sql_tbl ''').show() |
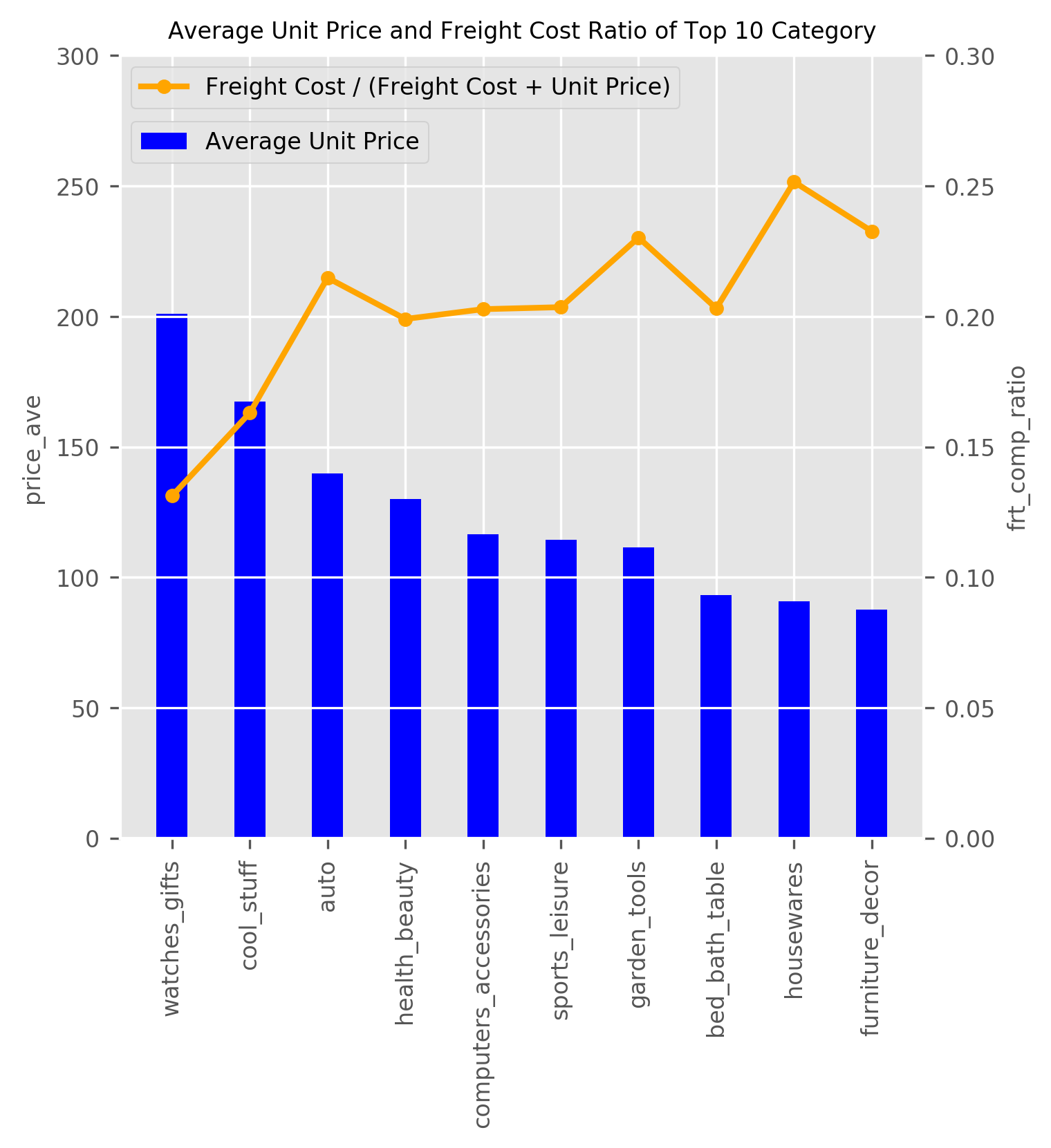
このテーブルに対してSQLを発行し、売上のTop10カテゴリを抽出、pandas_dfに変換後、平均単価で並べ替えします。こんな形でそのままクエリが書けるのは便利ですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
df = spark.sql(''' SELECT product_category_name_english as cat_name , count(order_id) as cnt , sum(price) as price_ttl , avg(ttl_price_vs_freight) as frt_comp_ratio , avg(price) as price_ave FROM sql_tbl GROUP BY product_category_name_english ORDER BY price_ttl DESC LIMIT 10 ''').toPandas().sort_values('price_ave', ascending=False) |
可視化のためのライブラリをインポート。
|
1 2 3 4 |
import matplotlib.pyplot as plt import pandas as pd import numpy as np import seaborn as sns |
グラフを描画。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
graph_name = 'Average Unit Price and Freight Cost Ratio of Top 10 Category' # グラフの軸指定 x = df['cat_name'] y2 = df['frt_comp_ratio'] y1 = df['price_ave'] # グラフの見た目スタイル plt.style.use('ggplot') # グラフ形式 fig, ax2 = plt.subplots(figsize=(5, 5)) plt.xticks(rotation='90', fontsize=8) plt.yticks(fontsize=8) ax1 = ax2.twinx() plt.yticks(fontsize=8) ax1.plot(x, y2, linewidth=2, color="orange", linestyle="solid", marker="o", markersize=4, label='Freight Cost / (Freight Cost + Unit Price)') ax2.bar(x, y1, label='Average Unit Price', color='blue', width=0.4) #y軸範囲 ax1.set_ylim([0,0.3]) ax2.set_ylim([0,300]) #凡例 ax1.legend(bbox_to_anchor=(0, 1.00), loc='upper left', borderaxespad=0.5, fontsize=8) ax2.legend(bbox_to_anchor=(0, 0.93), loc='upper left', borderaxespad=0.5, fontsize=8) #グリッド ax2.grid(True) #軸ラベルを表示 plt.xlabel('X-Axis') ax1.set_ylabel('frt_comp_ratio', fontsize=8) ax2.set_ylabel('price_ave', fontsize=8) plt.title(graph_name, fontsize=8) plt.savefig(graph_name, bbox_inches='tight', dpi=300) |
出力されるグラフデータはこちら
pros
・ビジネスロジックが埋もれにくい
・どの処理をどんな順番で行うのか明確になる
・Markdownでメモ書きも残せて第三者にもフレンドリー
・意外と習得コストが低い
・今回はPySparkを使ったので参考資料は少ないものの、pandasであれば、たくさんの参考資料あり
・SQLも然り
・環境構築が簡単
・クラウドのNotebookの最大の利点
・違うPCでもアカウントにログインさえできれば同じように動作する
cons
・バージョン管理が大変
・チェックポイントを設けることはできますが、コードを書きたいときにわざわざこれをやるか、というと私はやりません。ちょっと面倒ですがコメントアウトで対応することが多いです。
・可視化に要する工数が大きい
・グラフの成型には結構な手間がかかります。今回はカテゴリの選定なので本来はそこまで凝ったグラフは必要ないのですが、ついいろいろ手を出してしまい、時間を費やしてしまいました(自戒)
まとめ
Azure Notebooksはすごく便利ですが、Jupyter Notebookをそのままクラウドに持ってきたというコンセプトなので、運用という意味では課題がいくつかあるように感じられます。次回はDatabricksでやってみます。お楽しみに!
参考サイト
Kaggle.com
Brazilian E-Commerce Public Dataset by Olist
Class SparkContext
備考: 中間テーブル作成時のPySparkコード
備忘録がてらまとめました
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
