はじめに
Excel / Azure Notebook / Databricks で同じことをやってみる #1 【はじめに】
Excel / Azure Notebook / Databricks で同じことをやってみる #2 【Excel編】
Excel / Azure Notebooks / Databricks で同じことをやってみる #3 【Azure Notebook編】
に続き、Databricks を用いて簡易集計及び可視化を行います。
Databricksとは?
概要
以前の記事でも取り上げましたが、こんな特徴のデータ分析基盤プラットフォームです。
・Apache Spark環境を数分でセットアップ
-分析環境がすぐに作れる
-スケーラブル
-自動でスケーリング可能
-Sparkを作った人達が、Spark用にカリカリにチューニングしたプラットフォーム
・Notebookをバッチスクリプトとして使える
-例えば、データストリームに対して、Aの処理を一週間に一回かけて、Bのテーブルに追記する、
という処理が必要な場合、Aの処理を記載したNotebookを、バッチジョブとして設定できる
・バージョン管理が楽
-いわゆるタイムマシーン機能が使える
-複数人での作業がしやすい
・マジックコマンドが便利
-デフォルト言語としてPythonを設定しても、セルの頭にマジックコマンド(%sql)でクエリが書ける
・簡単に可視化
-発行したクエリをそのままグラフ化
-別途ライブラリのインポート不要
・オートターミネーションで安心
-クラスタをxx分未使用の場合には停止(=課金されない) といった設定ができる
-高額なクラスタを立ち上げっぱなしで、気が付いたらものすごい課金が…みたいなケースを回避できる
-今回発生した費用のまとめは後述します
設定
こちらのドキュメントを参照いただき、
・Azure Portal へのサインイン
・Spark クラスタの作成
・notebookの作成
まで行ったら準備完了です。
操作のきほん
Notebook自体の操作は、Jupyter Notebookとほとんど同じです。結構直感的に操作できますが、迷ったときは公式ドキュメントを参照しましょう。
データの準備
ストリーミングデータや大規模なテーブルを接続するのであれば、データの保存先は、Blob Storage Gen 2 や Delta Lake が候補になります。
今回は、そこまで大きくないCSVデータx3ですので、Databricksにテーブルを作成します。
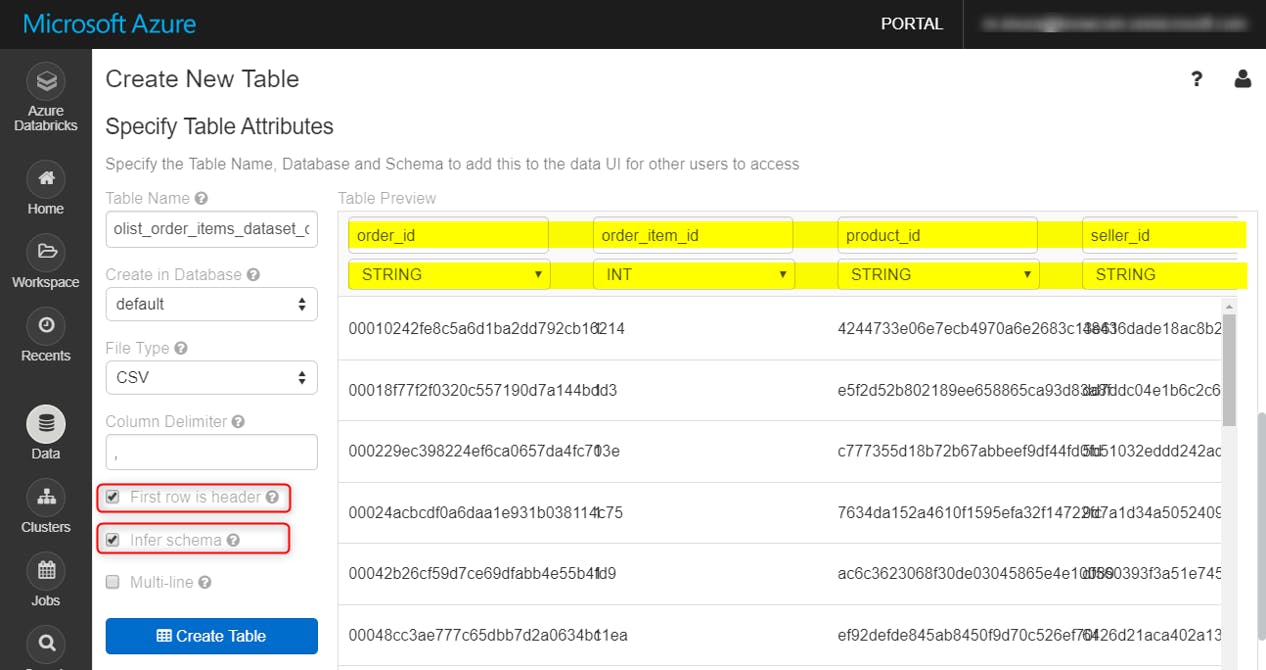
ホーム画面の下記の場所に、CSVデータをドラッグアンドドロップ
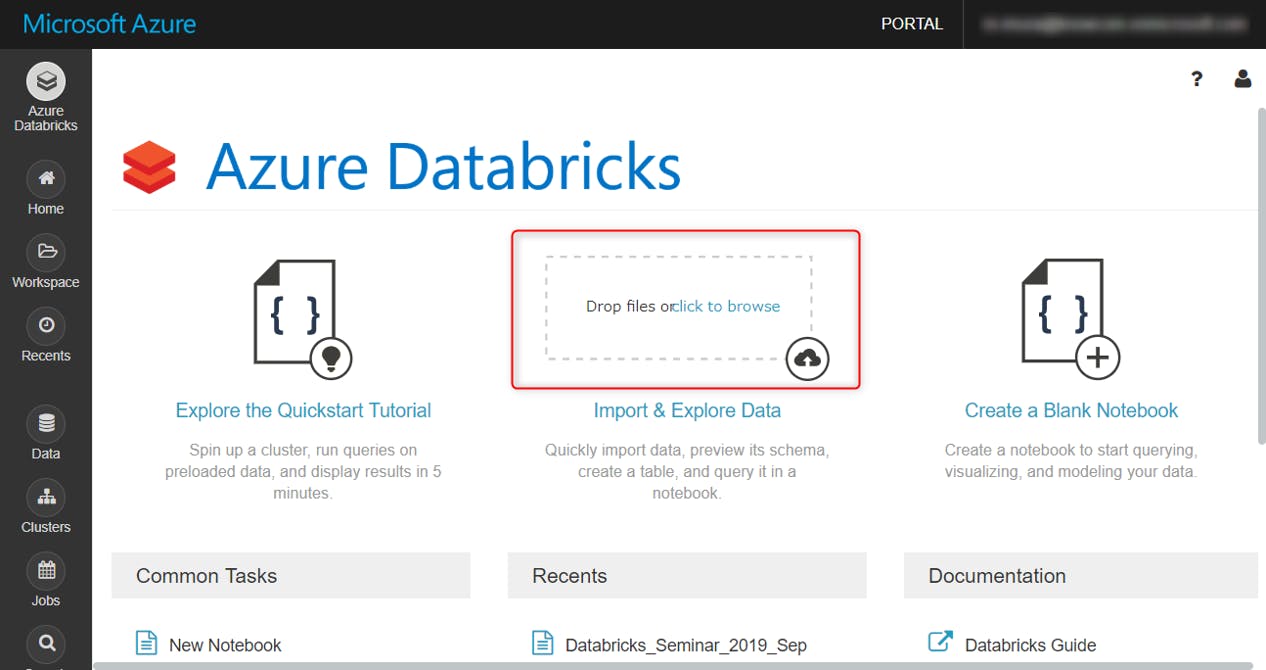
Create Table with UIをクリック
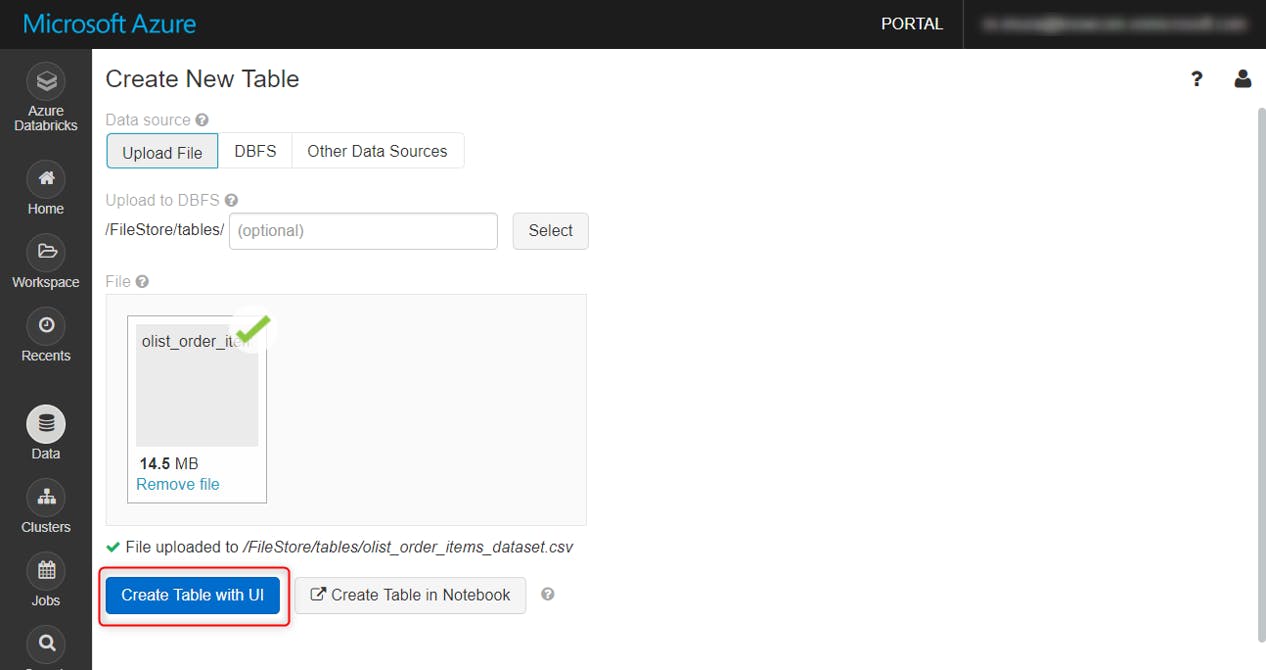
作成したクラスタを選択し、Preview Tableをクリック
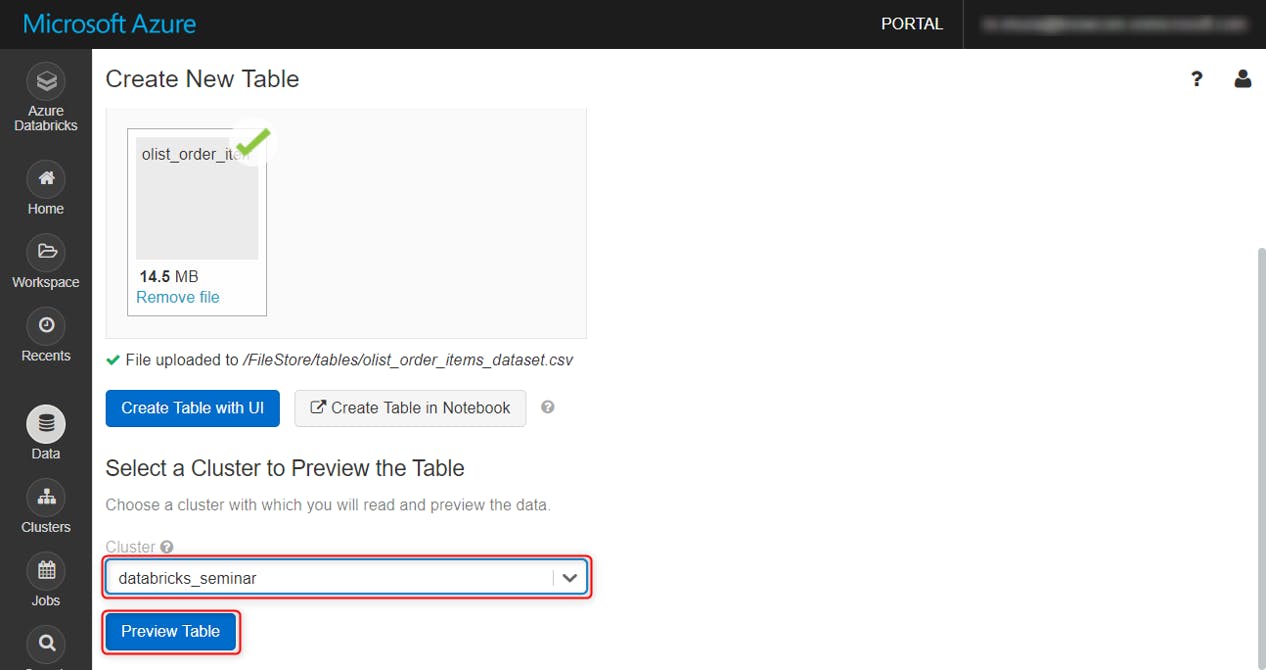
デフォルトだと、列名やスキーマはこのようになっています
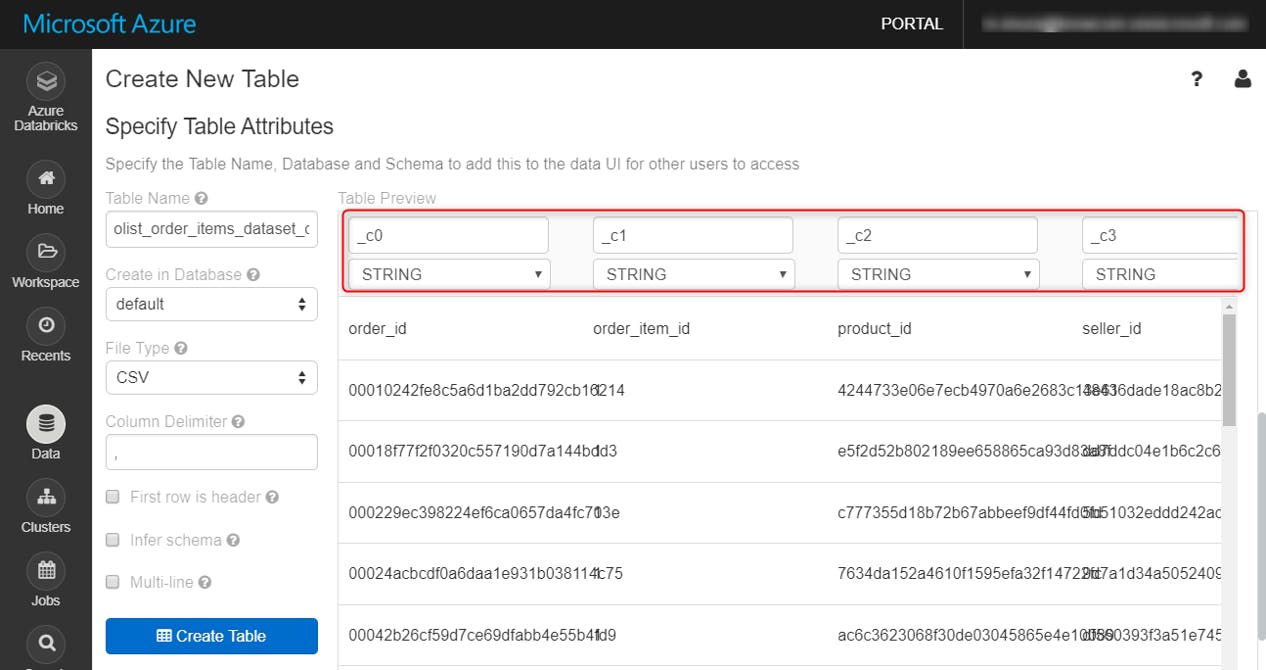
First Row is Header オプションで、一行目を列名として読みこみ、Infer Schema オプションの指定でスキーマを類推してくれます。
Create Tableをクリックし、しばらくするとテーブルの作成が完了します。CSVファイル3つそれぞれでこれらの作業を行います。
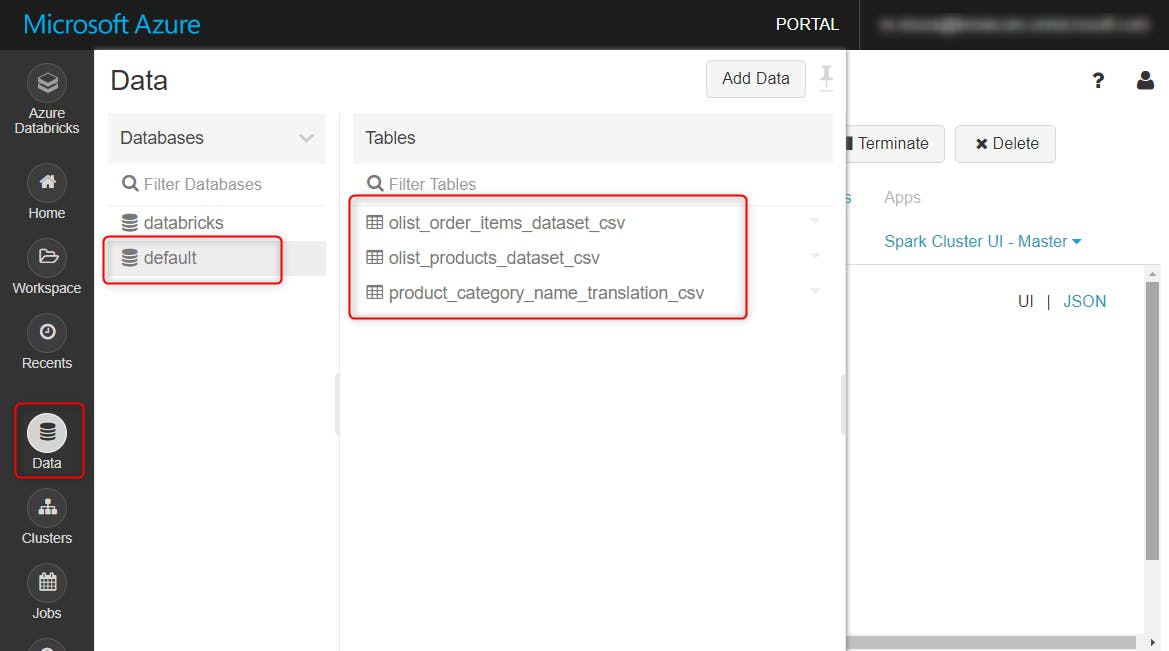
Data タブをクリックすると、テーブルを確認できます。
やってみる
流れ
Azure Notebookの回でやったように、Sparkで中間テーブルを作成します。
そこから先は、SQLオンリーでグラフ化まで行います。
手順
PySparkのライブラリをインポート。今回の用途であればこれだけでOK
|
1 |
from pyspark.sql.functions import udf, to_timestamp, col, desc, udf |
先ほど作成したテーブルの名称を変数に格納
|
1 2 3 |
orders = 'olist_order_items_dataset_csv' items = 'olist_products_dataset_csv' translation = 'product_category_name_translation_csv' |
それぞれのテーブルをSparkで読み込み
|
1 2 3 4 5 6 |
t1 = spark.read.table(orders) t2 = spark.read.table(items) t3 = spark.read.table(translation) t2 = t2.withColumnRenamed('product_id', 'product_id2') t3 = t3.withColumnRenamed('product_category_name', 'product_category_name2') |
テーブル結合のために、必要な列名を確認しておきます (結果は省略)
|
1 2 3 |
t1.printSchema() t2.printSchema() t3.printSchema() |
中間テーブル (name: sql_tbl) を作成します。コードは#3 Azure Notebookの回で説明したものと同じです。
|
1 2 3 4 5 6 7 8 |
table_name = 'sql_tbl' t1.join(t2, t1.product_id == t2.product_id2, 'inner')\ .join(t3, t2.product_category_name == t3.product_category_name2, 'inner')\ .withColumn('ttl_price_vs_freight', t1['freight_value'] / (t1['freight_value'] + t1['price']))\ .withColumn('limit_dt', to_timestamp(t1.shipping_limit_date, 'yyyy/MM/dd HH:mm'))\ .withColumn('freight_value', t1['freight_value'].cast('double'))\ .createOrReplaceTempView(table_name) |
ここからは全部SQLで記載していきます。%sqlとセルの頭に入れれば、SQL文として処理してくれます。結合処理を再度行うのは面倒なので、このテーブルは永続化しておきましょう。一時テーブルで良いときは、CREATE TABLE を CREATE OR REPLACE TEMPORARY VIEW AS にすればOK
|
1 2 3 |
%sql CREATE TABLE sql_tbl SELECT * from sql_tbl |
以下で中間テーブルのスキーマが確認できます
|
1 2 |
%sql DESCRIBE sql_tbl |
結果
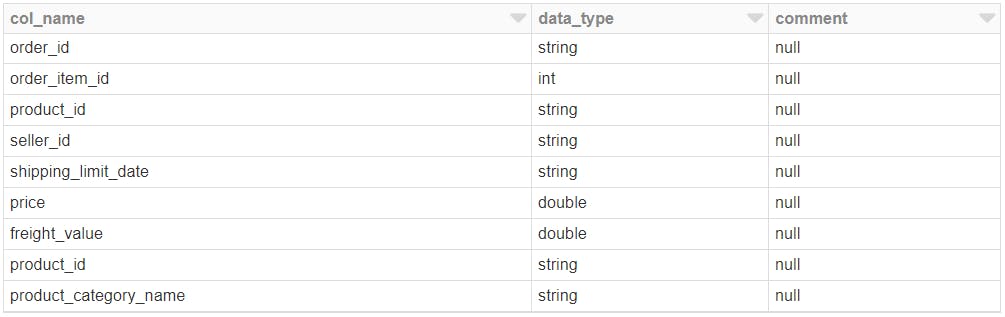
集計後テーブル (name: sql_tbl2) を作り、永続化させます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
%sql %sql CREATE TABLE sql_tbl2 SELECT product_category_name_english as cat_name , count(order_id) as cnt , sum(price) as price_ttl , avg(ttl_price_vs_freight) as frt_comp_ratio , avg(price) as price_ave FROM sql_tbl GROUP BY product_category_name_english ORDER BY price_ttl DESC LIMIT 10 |
集計後テーブルに対してクエリを発行します。可視化した時に同じくらいのスケールに収まるように、送料の割合を1000倍しておきます。
|
1 2 3 4 5 6 7 8 |
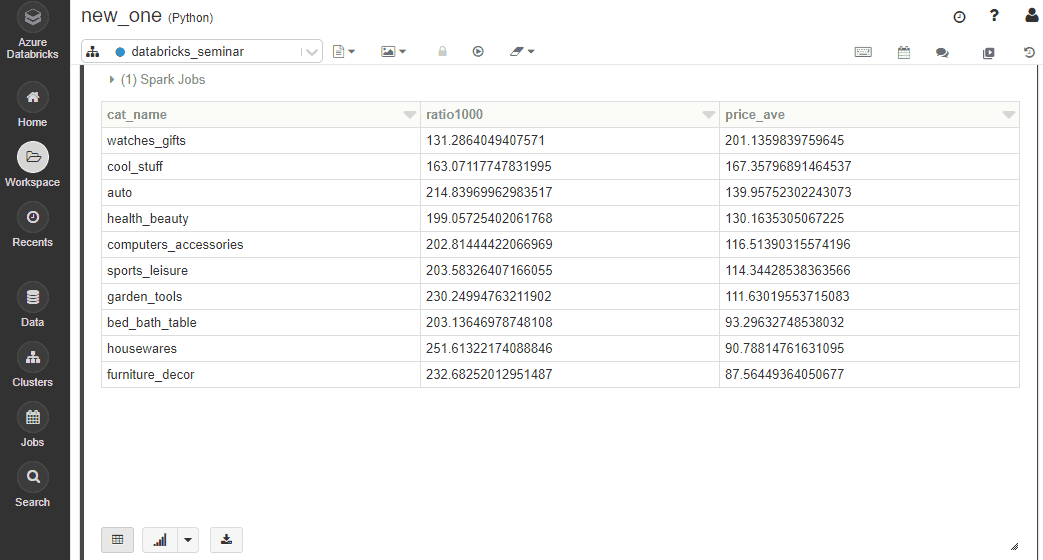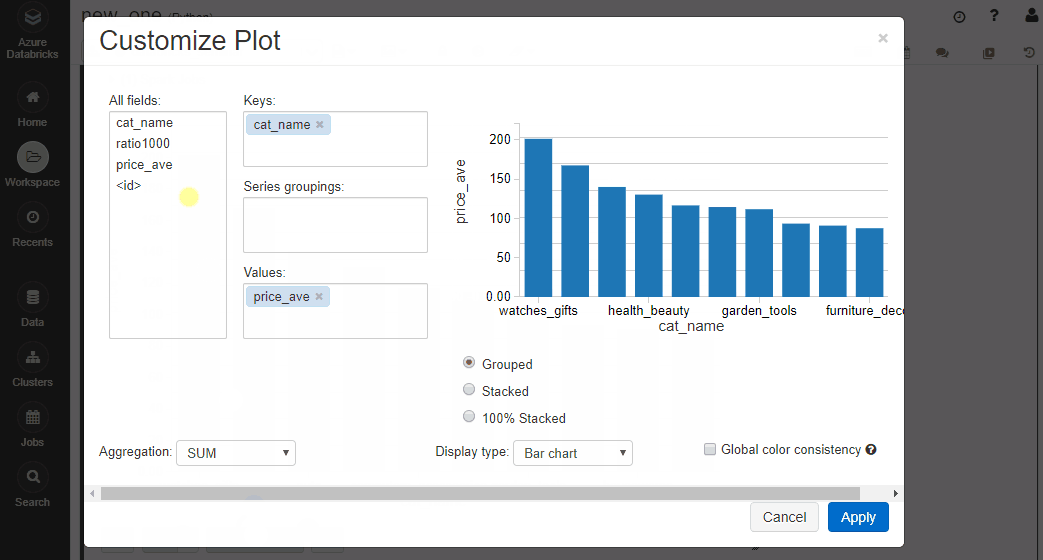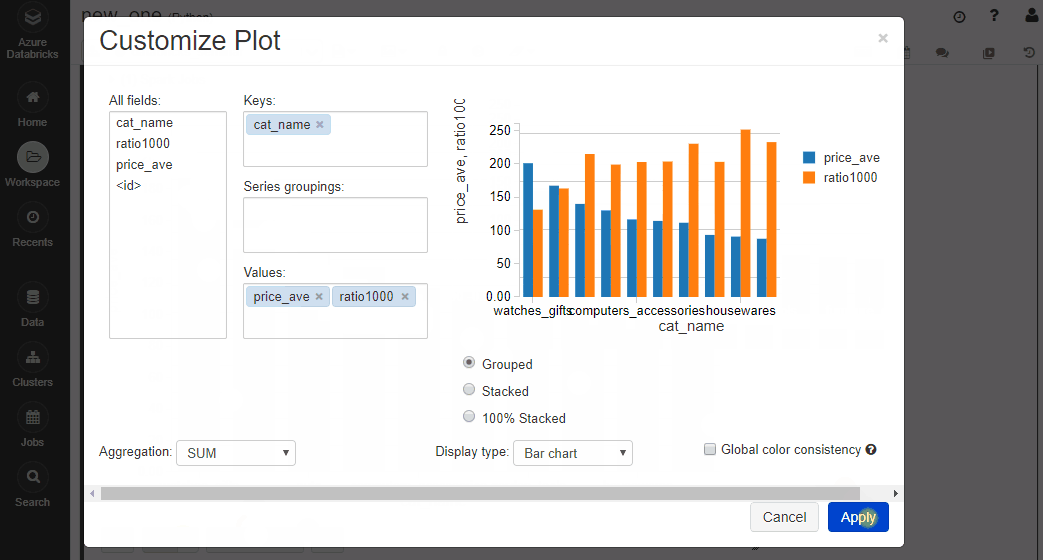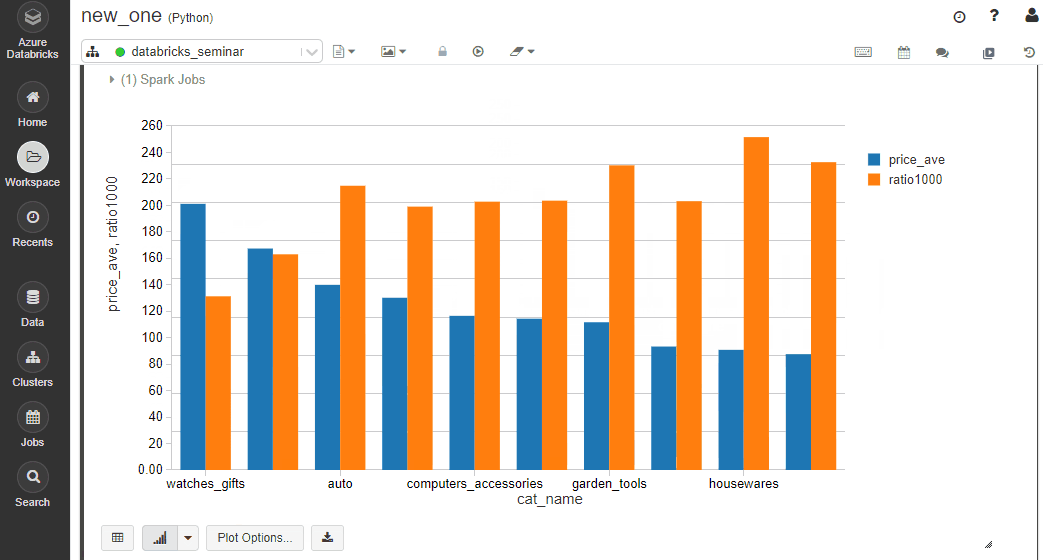
%sql SELECT cat_name , frt_comp_ratio * 1000 as ratio1000 , price_ave FROM sql_tbl2 ORDER BY price_ave DESC |
結果はこちら。デフォルトだと表が出力されます。下のボタンでクエリの結果をそのまま可視化可能。
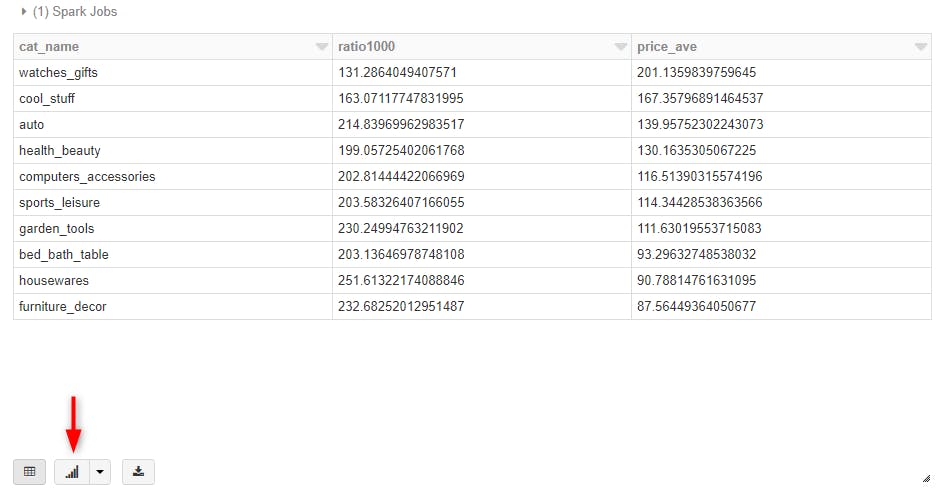
こんな感じです。アドホックな分析にとても便利!
費用
料金体系
クラスターの起動時間に応じて、分単位で、以下のマシンリソースに対して課金されます。 (詳細はこちら)
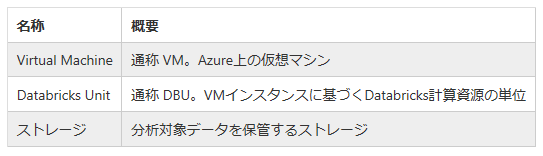
料金表だけを見ていると意識に上がりずらいのですが、Databricks Unit には Driver とWorkerの2タイプがあり、クラスタを立ち上げると両方が起動され、課金されます。それぞれにインスタンスを割り当てて処理をしてもらうわけですが、当然、性能の高いインスタンス(= 高いDBU値) ほど、高コストになります。
今回使用したのはもっとも安価な 0.5 DBU のインスタンス。

今回の費用概算
今回の簡易分析・可視化で、どのくらいの費用が発生したか概算してみましょう。以下は今回使用したクラスタの設定画面。費用に大きく響いてくるところなので、本格的に分析基盤を立ち上げる際には、分析対象と内容に応じて、必要十分な計算資源を割り当てるように留意する必要があります。
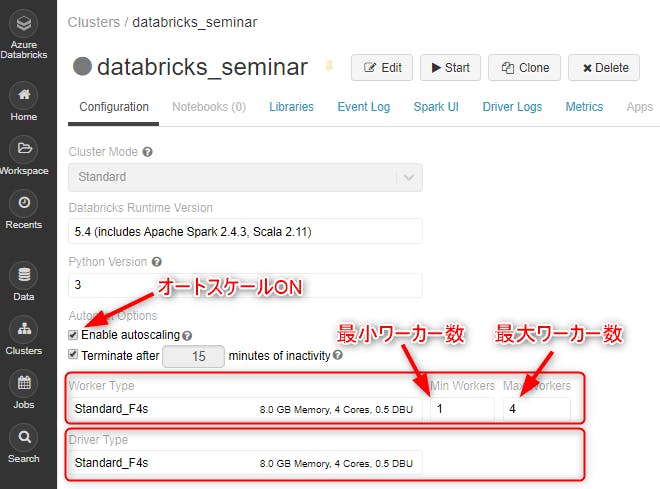
設定は以下の通り。
クラスタのJob履歴を見てみたところ、Workerのスケーリングはしなかったようなので、クラスタの起動中は、0.5 DBU + 0.5 DBU で合計 1 DBU 使ってる計算になります。
・リージョン: 米国西部 2
・ワークロード:データ分析
・レベル:Standard
・Driverタイプ:F4s (0.5 DBU)
・Workerタイプ:F4s (0.5 DBU)
・最小ワーカー数: 1
・最大ワーカー数: 4
・自動停止
・15分操作がなかったらクラスタを停止
分単位の課金なので、Cluster の Event Log から、ここ2日間で何分間クラスタを起動したかざっくり見てみます。3回起動/停止しているようです。合計約70分。
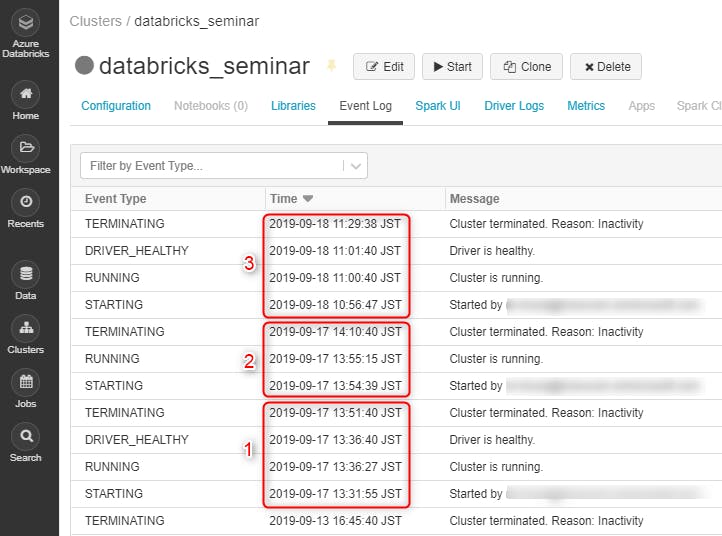
Databricks の料金表を参照し、70分間インスタンスを起動した今回の費用概算と、仮に48時間インスタンスを立てたままにした場合の料金を比較してみました。
当たり前ですが、オートターミネーションした場合と継続利用では、かなりの金額差がありますね。

分析プラットフォームサービスは、どうしてもマシンスペックでの比較がされやすい傾向にあります。
しかし、実運用に則して考えると、Databricks の費用対効果の高さはピカイチじゃないかと思います。
まとめ
さいごにDatabricksの長所をおさらい。
・すぐApache Spark環境を作れる
・Notebookをバッチスクリプトとして使える
・バージョン管理が楽
・マジックコマンドが便利
・簡単に可視化
・オートターミネーション
アドホックな分析をするなら、SQLをそのままかけて、すぐに可視化できて、クラスタのオートターミネーションが利用できる Databricks が最高に便利。
おわりに
Databricks、簡易的な可視化ならできるけど、ちょっと凝ったグラフは?BIとの接続は?
ということで、次回は Databricks を Power BI につなげてみようと思います。お楽しみに!
参考サイト
クイック スタート: Azure portal を使用して Azure Databricks 上で Spark ジョブを実行する
Databricksで分析業務がはかどっている話
平成最後の1月ですし、Databricksでもやってみましょうか
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
