最近話題の機械学習、数あるアルゴリズムの中でも今回はサンプルデータを用いてレコメンドモデルの作成を紹介していきます。
前回はレコメンドモデルを作成するために必要なデータの種類と分割を説明しました。
今回はそのデータを元に実際にレコメンドモデルを作成します。
モデル作成
今回はレコメンドを行うので検索欄に「recommend」と入力してみます。
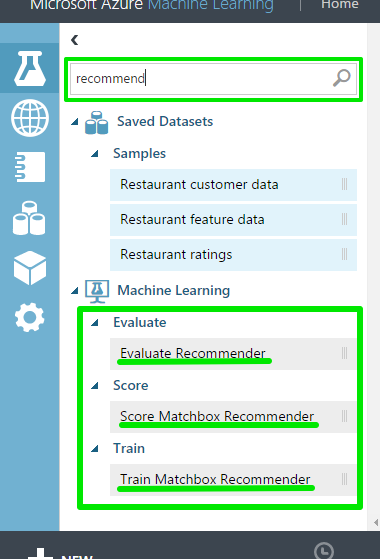
レコメンドで使用するモジュールが表示されました!
ここでそれぞれのモジュールについて簡単に説明します。
他の機械学習でも共通ですが
Training、Score、Evaluateの3つのモジュールに分かれています。
Trainingでモデルを作成、Scoreでモデルに実データを適応、Evaluateでモデルの評価を行っています。
– 1.モデルの作成(Training)
Train Matchbox Recommenderモジュールにデータを流し込みます。
左の入力端子からから評価データ、評価する側(ユーザー)、評価される側(アイテム)の順番です。
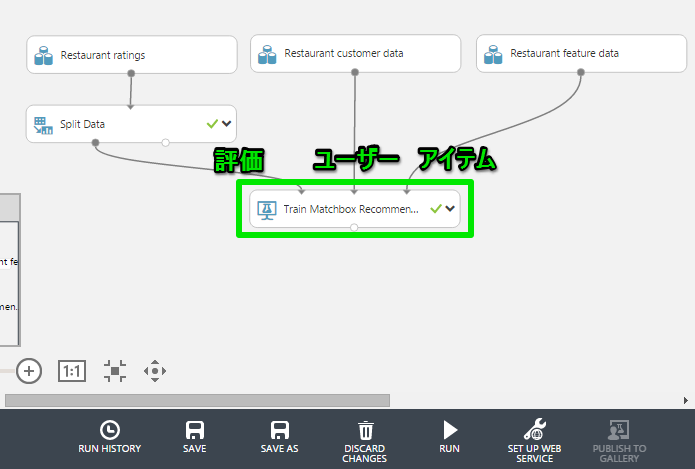
この状態でRUNを行うとモデル自体は完成です。
– 2.データの適応(Score)
出来たモデルでモデル作成では使わなかったユーザーに対して実際にレコメンドを行います。
Score Matchbox Recommenderモジュールの入力は左から、「作成したモデル」、「分割した残りの評価データ」、「評価する側(ユーザー)」、「評価される側(アイテム)」の順番です。
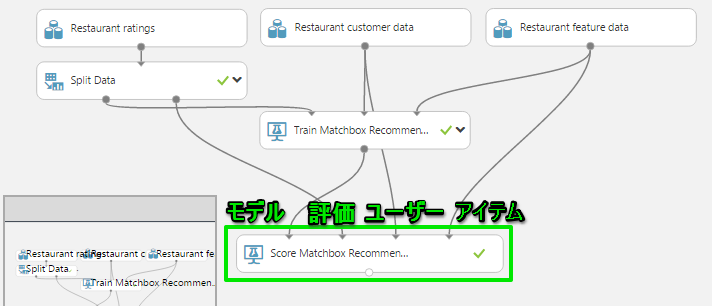
ここで一度RUNを行って結果を見てみると・・
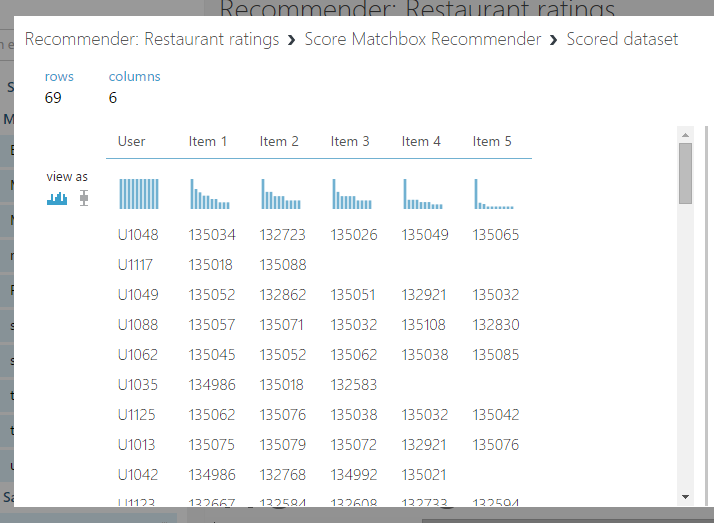
レコメンドの結果を見ることが出来ます!
おさらいになりますが、結果の見方は見たい出力端子をクリックして「Visualize」ですよ!
– 3.モデルの評価(Evaluate)
最後にこのレコメンドモデルがどうだったか実データに照らし合わせて評価を行います。
Evaluate Recommenderモジュールは左が「残りの評価データ」、右が「レコメンドの結果データ」です。
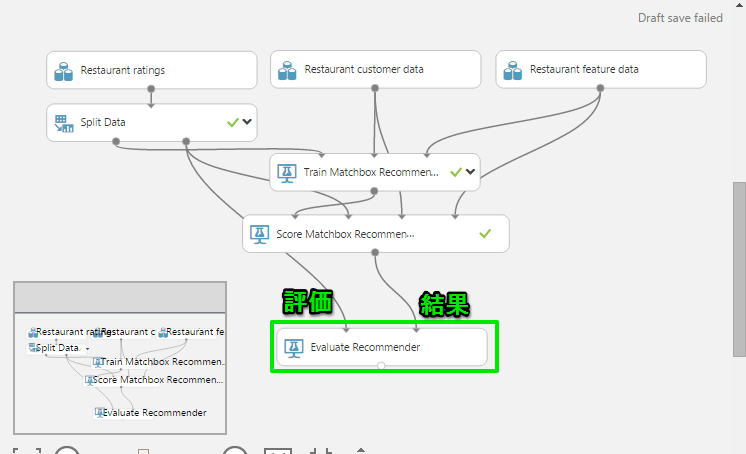
RUNを行い、結果を見てみます。

NDCGというのが評価です!
順番を付けた時の正確性を評価する指標、
つまりレコメンドがどれだけ妥当であったかを示しています。
1に近づくほど評価が高くなるので0.919はかなり高い精度で当たっていることが分かります。
お疲れさまでした!
モデルの作成と評価は以上になります。
うまく行きましたでしょうか?
評価値をどう決めていくかがレコメンドモデルを作る上での肝になります。
とは言っても評価データは取得が難しくログデータだけという場合も少なくないと思います。
そこからいかに評価データを作り出すことができるかが腕の見せ所ですね!
今が勝負と言える機械学習、是非取り入れてみてはいかがでしょうか!
最後まで読んでいただき、ありがとうございました!
またお会いしましょう!
