今回は、Azure Machine Learning (Azure ML)を使った多項分類をご紹介します。
サンプルデータ
今回は乱数パターンをサンプルデータとして検証を行いました。
サンプルの作成にあたっては、まずプログラムにて0~9の10個の整数乱数パラメータ(重複許容)を持つ、5組の基本パターンを用意しました。

さらに基本パターンに対し、パラメータそれぞれに任意の標準偏差となる正規分布の乱数(ノイズ)を付加したものを、3000個生成してサンプルデータとしました。5個のパターンについては均等な確率でランダムにパターンが出現するように調整しています。

注意深く見比べても、ヒトの目での分類は困難であることがわかると思います。
これをAzure MLで分類してみましょう。
多項分類モデル
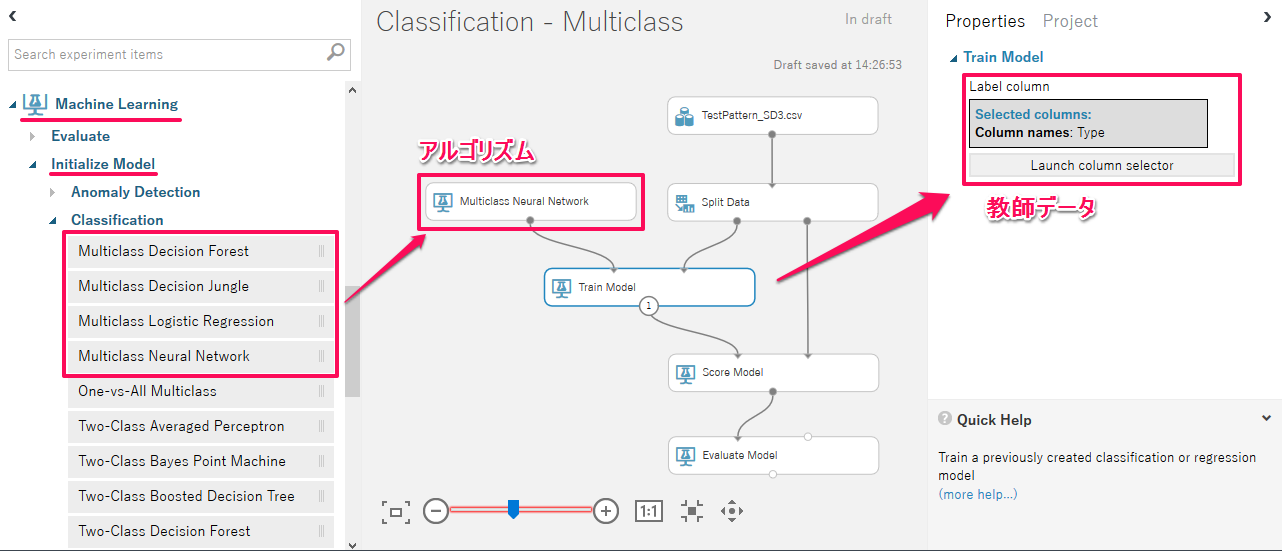
多項分類の基本的なモジュール構成は回帰分析と大きく変わりません。唯一異なる点はモデル作成のアルゴリズムに「Multiclass Neural Network」といった「Multiclass」と付く多項分類用のモジュールを組み込む点です。
多項分類モジュールは左ペインのモジュール一覧の「Machine Learning」→「Initialize Model」→「Classification」に格納されています。
今回の構成は、入力データを「Split Data」で50%ずつに分割し、50%分で教師モデルを作成、もう50%分を「Score Model」でモデルによる分類を実行して「Evaluate Model」で評価を行います。「Train Model」には教師データとなるパターンの識別「Type」を設定しました。
分類の実行と結果
それでは作成した多項分類モデルでサンプルデータの分類を行ってみましょう。
モデルを実行する場合には「RUN」をクリックします。
モデルの作成から1500個の分類、評価を行うのにかかった時間は約30秒でした。
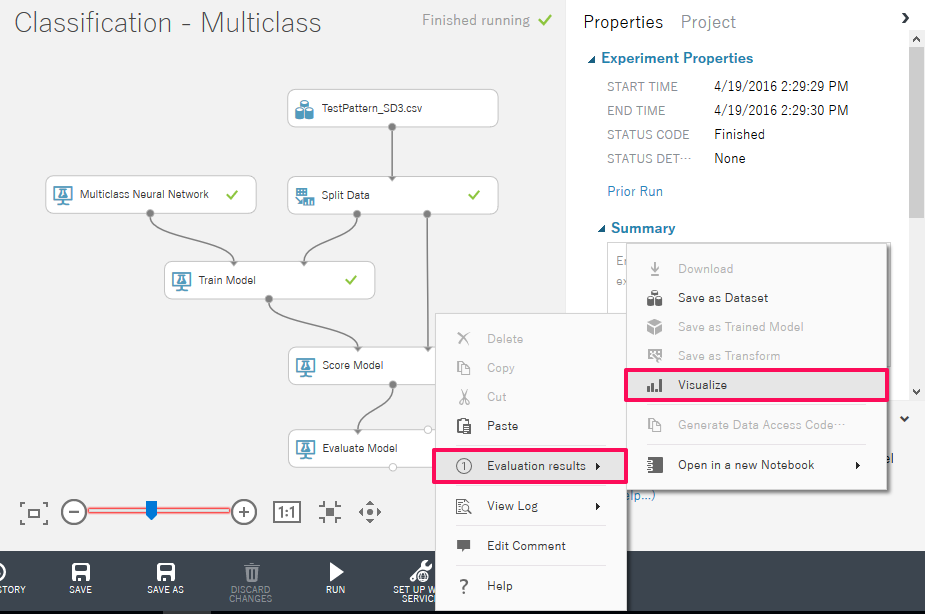
分類結果の精度を確認する場合には、「Evaluate Model」を右クリックして「Evaluation Results」→「Visualize」を選択します。
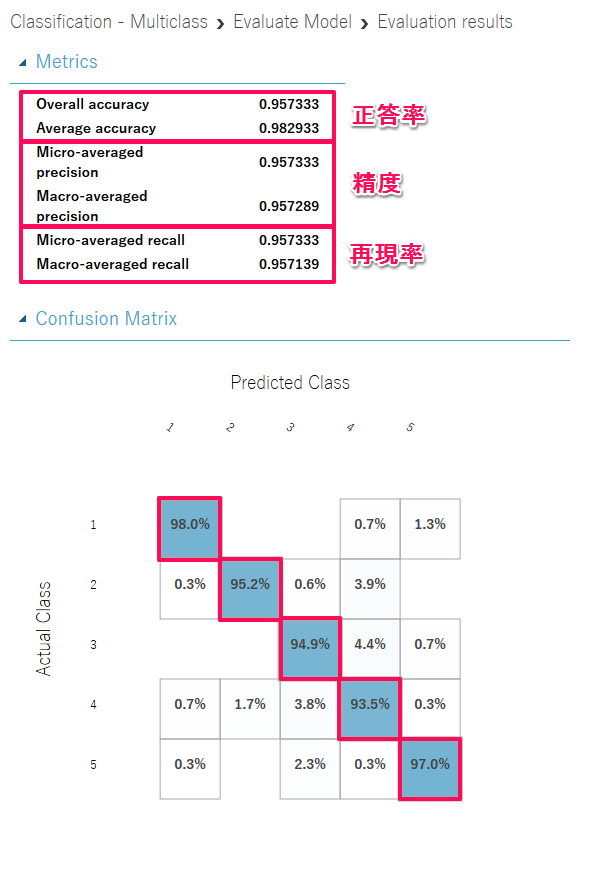
「Visualize」ではAccuracy (正答率)、Precision (精度)、Recall (再現率)の情報が取得できます。これらの値は1に近いほど良好な分類結果となることを示します。
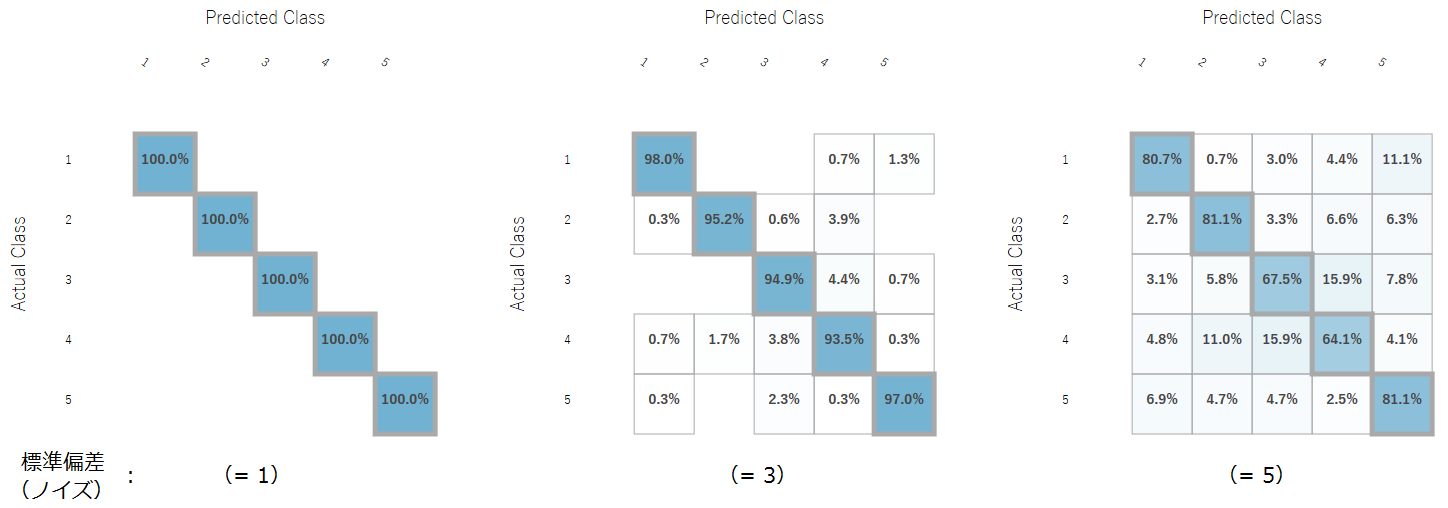
また、マトリクス図では、実際のパターンに対して予測がどのパターンに分類したかを割合で示しており、右下がりの対角線方向がパターンごとの正答率になります。
以下は、初めに示したサンプルの結果になりますが、たった30秒で95%を正しく分類できていました。
サンプルに付加するノイズの標準偏差を1、3、5と変化させた場合の分類の精度を確かめてみました。標準偏差が大きいほどにノイズが大きくなるため、分類の精度は低下していきますが、パラメータの期待値4.5に対して100%以上の標準偏差のノイズを付加しても、65~80%の正答率と良好な分類ができていることが分かります。
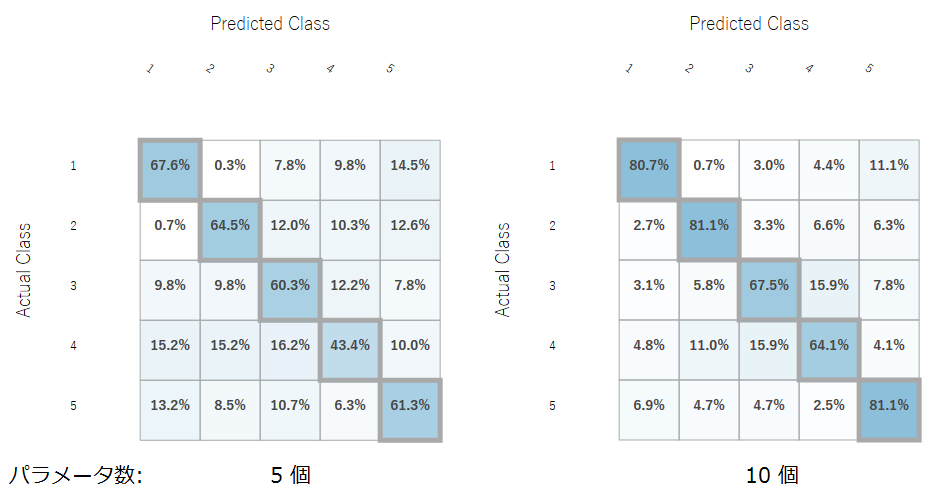
また、同サンプルデータでパラメータ数を半分の5個にして同様の分類を行いました。パラメータ数を減少したものでは、正答率が40~60%程度と低くなっており、有意なパラメータが多いほど分類精度が上がることが分かりました。
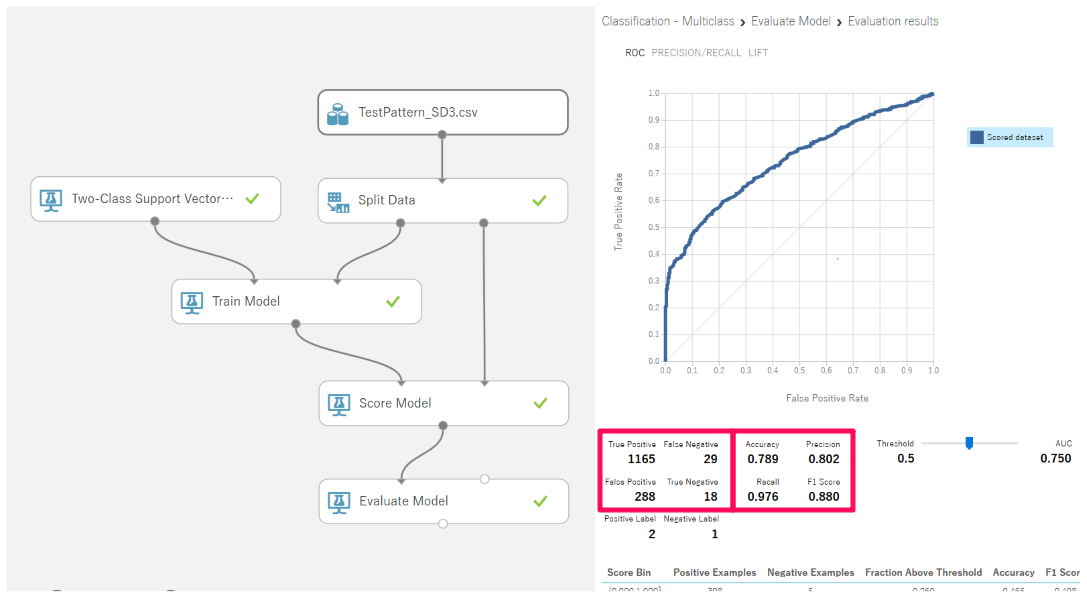
「One-vs-All Multiclass」モジュール
「One-vs-All Multiclass」モジュールを使うと、二項分類モジュールを多項分類に適用することができます。
二項分類モジュールを「Train Model」に接続すると多項分類のサンプルであっても、二項分類として結果が出力されます。
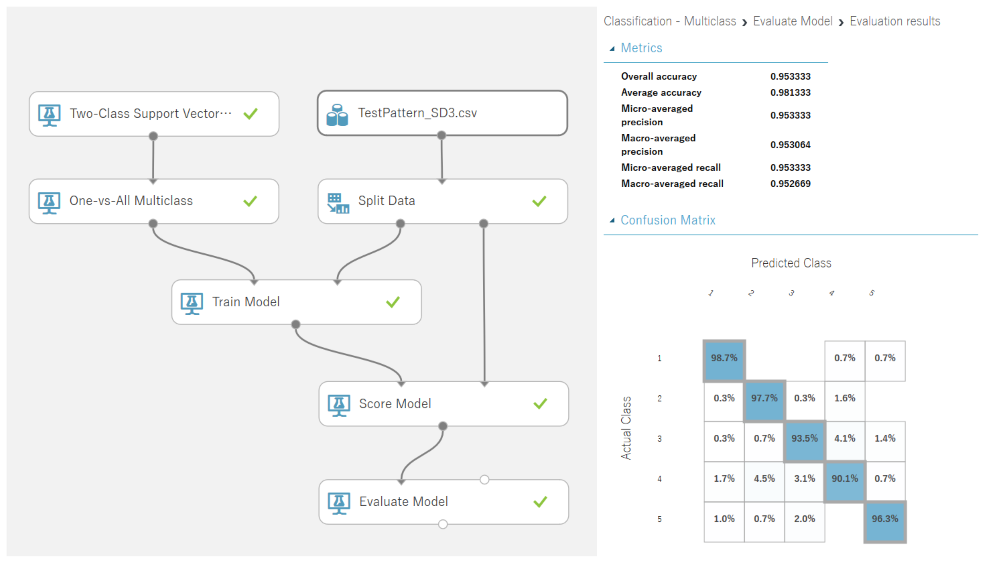
「One-vs-All Multiclass」モジュールを介して「Train Model」に接続すると二項分類モジュールでありながら、多項分類の結果が出力できます。
現状では多項分類アルゴリズムは4種類しかありませんが、「One-vs-All Multiclass」を使うことで、事実上、二項分類アルゴリズムを含めた13種類のアルゴリズムが使用可能となります。
いかがでしたでしょうか。
一見して関係性のわからないような数値の羅列でも、機械学習であれば教師データとパターンの対応を識別して分類してくれるため、情報の分類に苦心されている方は一度試してみてはいかがでしょうか。
次回もお楽しみに!!
