
はじめに
2026年6月15日~18日サンフランシスコ・バーチャルにて開催されるDatabricks社主催の年間最大規模のカンファレンスイベント、「Databricks Data+AI Summit 2026」(DAIS)が開催されました。
本記事はDAIS2026 Lakebase 101: core workflows and the Lakebase experience で発表された、DatabricksのLakebase入門:サーバーレスPostgresの特徴とデモで見えた実用性についての記事になります。
本記事はDatabricks公式発表を元にした非公式の日本語要約であり、すべての著作権・知的財産権はDatabricksに帰属します。

忙しい方用
この発表で言いたかったことを、3行でまとめると次の通りです。
- Lakebase は、Databricks 上で使えるサーバーレスな Postgres
- compute と storage を分離しているので、起動・スケール・復旧がかなり速い
- Unity Catalog や Lakehouse とつながるため、OLTP と OLAP を同じプラットフォームで扱いやすい
特に印象的だったのは、branch / snapshot / scale to zero の3点です。
これによって、従来の「DB を丸ごとコピーする」「ピークに合わせて常時 provision する」といった運用をかなり軽くできそうだと感じました。
この記事で分かること
この記事では、発表をもとに次の点を整理します。
- Lakebase とは何か
- なぜ今こうした仕組みが必要なのか
- どんな機能があるのか
- 従来の Postgres 運用と何が違うのか
- 他社製品や去年までの考え方とどう違うのか
- どんな人に向いているのか
- 実際のデモから何が読み取れるのか
単なる説明の要約ではなく、「自分たちのシステムに当てはめるとどう見えるか」 という観点でも整理します。
どんな人に向いているか
この内容は、特に次のような人に向いています。
- アプリケーション開発者
- データエンジニア
- プラットフォーム / インフラ担当
- Postgres を日常的に使っている人
- Databricks を使っている、または導入を検討している人
- OLTP と OLAP をつなぎたい人
- AI アプリや業務アプリのバックエンドを考えている人
「DB をなるべくシンプルに運用したい」「開発環境の複製や復旧を速くしたい」「データ基盤とアプリ基盤を分けすぎたくない」 という人にはかなり刺さる内容です。
背景
今日のアプリケーションは、以前よりずっと高度になっています。
生成AIの普及、サーバーレス化、アプリの多機能化によって、ただデータを保存するだけではなく、低遅延で、柔軟に、そして安全に使えるDB が求められるようになりました。
しかし、既存のデータベースの多くは、現在のアプリ要件に十分最適化されているとは言いにくいのが実情です。
発表では、主に次のような課題が挙げられていました。
1. compute と storage が密結合している
少しメモリを増やしたいだけでも、ストレージまで含めて全体を拡張する必要があります。そのため、必要以上に大きな構成を持ちがちです。
2. ピーク前提でコストがかかる
たとえばブラックフライデーのように一時的に負荷が上がるサービスでは、 ピークに合わせて常時高い構成を維持しなければならず、無駄が出やすいです。
3. 開発用環境の作成が重い
staging や dev を作るたびに、DB をコピーしたり、一部のデータだけを複製したりする必要があります。 これが時間もコストもかかります。
4. 復旧や監査対応が重い
保持期間、ポイントインタイムリカバリ、監査ログなどの要件に対応するのが大変です。
5. OLTP と OLAP の連携に手間がかかる
トランザクション系DBと分析基盤をつなぐために、ETL を書いて、ガバナンスも二重管理して…という運用になりがちです。
こうした背景に対して、Lakebase は 「Postgres をベースにしながら、現代的なクラウド運用に合わせて作り直した」 ものとして紹介されていました。
Lakebase とは何か
Lakebase は、Databricks が提供するフルマネージド・サーバーレスの Postgres です。
発表では、単に「Postgres が使える」だけではなく、
compute と storage を分離した新しいアーキテクチャ が強調されていました。
つまり、Postgres の互換性を保ちながら、次のような機能を実現しています。
- 迅速な起動
- 自動スケーリング
- scale to zero
- branch
- snapshot
- PITR
- read replica
- Databricks 製品群との統合
重要なのは、これらが「あとから足した機能」ではなく、
最初からクラウドネイティブな前提で設計されている という点です。
印象的だったポイント
1. 500ms未満で起動できるという発想
発表では、compute を非常に短時間で起動できることが強く押し出されていました。 従来のDB運用だと、起動や再開にはある程度の待ち時間があるのが普通です。
それに対して Lakebase は、
「必要なときにすぐ立ち上がるDB」 を目指しているのが印象的でした。
2. scale to zero ができる
使っていないときは compute を止められるので、
アイドル時間の課金を避けられる のが大きな魅力です。
特に開発環境や検証環境では、常時稼働前提のDBはコストが無駄になりやすいので、 この仕組みはかなり実用的だと感じました。
3. branch が Git のように扱える
発表の中でも特に分かりやすかったのが branch 機能です。
既存の DB をコピーするのではなく、コピーオンライト的に新しい branch を作れる ため、データを丸ごと複製しなくて済みます。
これは開発・検証でかなり便利です。
- 本番データを元に検証したい
- 一時的な分岐を作りたい
- 終わったら branch を消したい
という用途に向いています。
4. snapshot と restore が即時
スナップショットは即座に取得でき、復元もすぐ行えます。
しかも、内部で重いコピー処理を伴わないのが特徴です。
DB運用では「バックアップはあるけど復元が重い」というケースが少なくないので、 この即時性はかなり魅力的です。
5. OLTP と OLAP を同じプラットフォームでつなげる
Lakebase の面白さは、単体のDB機能ではなく、
Databricks の Lakehouse / Unity Catalog と一体で使える ところにあります。
これによって、分析データと業務データの連携がかなり自然になります。
従来との違い
1. 従来の managed Postgres との違い
従来の managed Postgres では、以下のような前提がありました。
- 一定の容量を確保しておく必要がある
- ピークに合わせて常時 provision しがち
- 使っていない時間にもコストがかかる
- 復旧や拡張に時間がかかる
- 開発用環境はコピーで作ることが多い
Lakebase では、これらがかなり変わります。
- scale to zero で idle コストを抑えられる
- branch で DB を気軽に分岐できる
- snapshot / restore が即時に近い
- compute と storage が分かれているので、運用の自由度が高い
つまり、「DBは常に大きく持つもの」ではなく、「必要なときだけ伸び縮みするもの」 という考え方に変わります。
2. 昨年までの発想との違い
昨年までの運用では、DB を使うたびに次のような作業が発生しがちでした。
- 本番DBのコピー
- staging 環境の再作成
- ETL の整備
- データ同期の運用
- 監査や権限管理の二重管理
Lakebase は、こうした「周辺作業」を減らす方向です。
特に、branch と snapshot があることで、開発や検証のやり方自体を変えられる のが大きいです。
3. 他社との違い
他社製品にも、優れた managed Postgres やクラウドDBはあります。
ただし発表の文脈では、「サーバーレス」「Postgres 互換」「Databricks 統合」「branch」「scale to zero」を一体で提供している点 が差別化要素として説明されていました。
単機能では優秀でも、以下を同時に満たすのは簡単ではありません。
- アプリケーションから見て使いやすい
- 運用負荷が低い
- データ基盤と自然につながる
- 開発用コピーを軽くできる
- コスト最適化できる
Lakebase は、そこをまとめて取りに行っている印象です。
この記事での視点
この記事では、Lakebase を単なる新製品紹介としてではなく、
「アプリケーションのDB運用を、どこまで再設計できるか」 という視点で捉えています。
その意味で、今回の発表は次のように読めます。
- DB を「保存先」ではなく「動的な実行基盤」として扱う
- 開発環境や検証環境を、コピーではなく branch で扱う
- 分析基盤と業務基盤を、ETL ではなく統合基盤でつなぐ
- idle 時間のコストを前提にしない
- DB の運用を、より Git ライクにする
この発想は、今後のアプリ運用にかなり影響しそうです。
今年の特徴
今回の発表で特に強かったのは、「まだ構想段階ではなく、すでに使える」 というメッセージです。
GA として提供されており、Free Edition や workspace から触れる点が示されていました。
デモでも、次のような実用性が見えていました。
- DB の作成が非常に速い
- 実データの lookup が高速
- アプリからの更新が即座に反映される
- UI から sync table を作ると、ETL を自前で書かずに連携できる
- branch を作って検証し、終わったら消す、という流れが自然
つまり、「いつか使える未来の話」ではなく、「今の開発に持ち込める機能」 として見せていたのが印象的でした。
デモで印象的だったポイント
発表の後半では、Lakebase が実際のアプリや管理画面でどう使えるのかがデモで示されていました。
1. Databricks Apps 上での全体像

この画面では、Databricks Apps 上の Order Ops Console を使って、Lakehouse のデータを Lakebase に同期する流れが示されていました。
画面上部では、Lakehouse → Reverse ETL → Lakebase の流れが見え、下部では検索、顧客参照、注文追加まで一通り確認できます。
Lakebase が単なる Postgres ではなく、Databricks のアプリ基盤の中で実際に使えることが分かるデモでした。
2. Lakebase と SQL Warehouse の検索速度比較
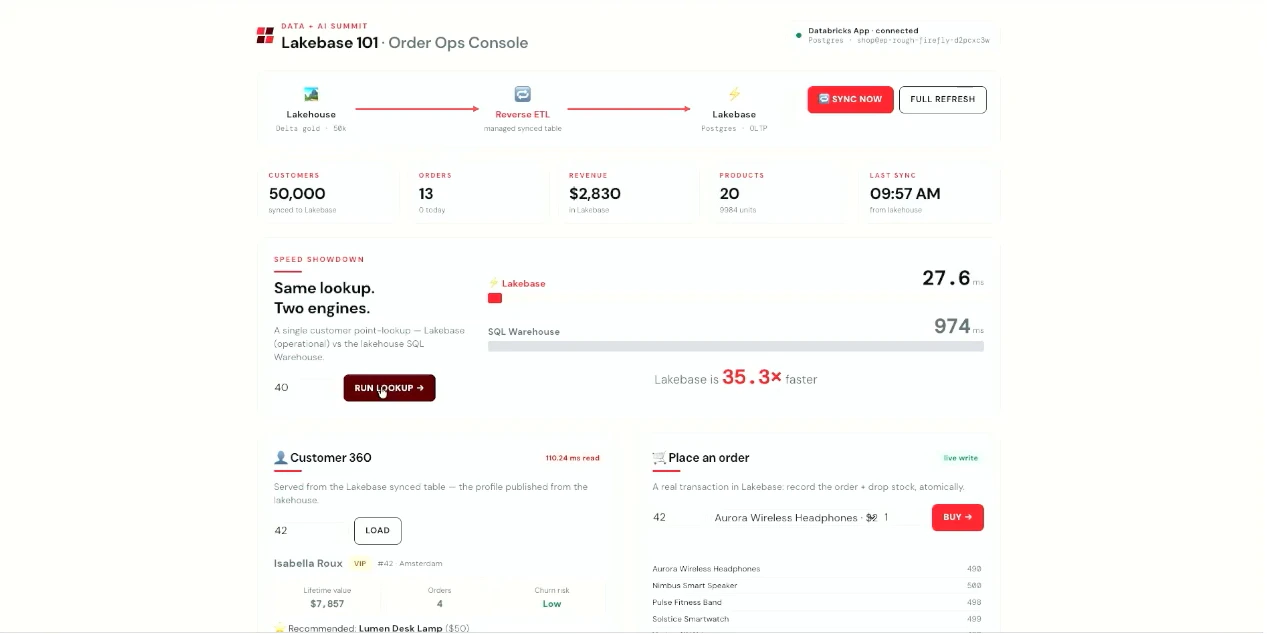
同じ customer lookup を Lakebase と SQL Warehouse で比較している画面です。
Lakebase は 27.6ms、SQL Warehouse は 974ms と表示されており、アプリの参照系では低遅延性が重要であることが分かります。
ここで伝えたかったのは、用途によって最適なエンジンが違うということです。 Lakebase はアプリの参照系のような低遅延が重要な場面に向いていて、SQL Warehouse は分析用途に強い、という住み分けが見えました。
「どちらが良いか」ではなく、
「どちらをどの用途で使うべきか」 が分かりやすいデモでした。
3. Customer 360 と注文追加の即時反映

この画面では、Customer 360 で顧客のLTV、注文数、チャーンリスクをすぐに表示でき、右側では注文を追加すると、その結果がアプリ上で即時に反映される様子が示されていました。
参照と更新の両方が低遅延で動くことで、Lakebase が業務アプリのバックエンドとして使えることが分かります。
4. Lakebase UI での管理機能
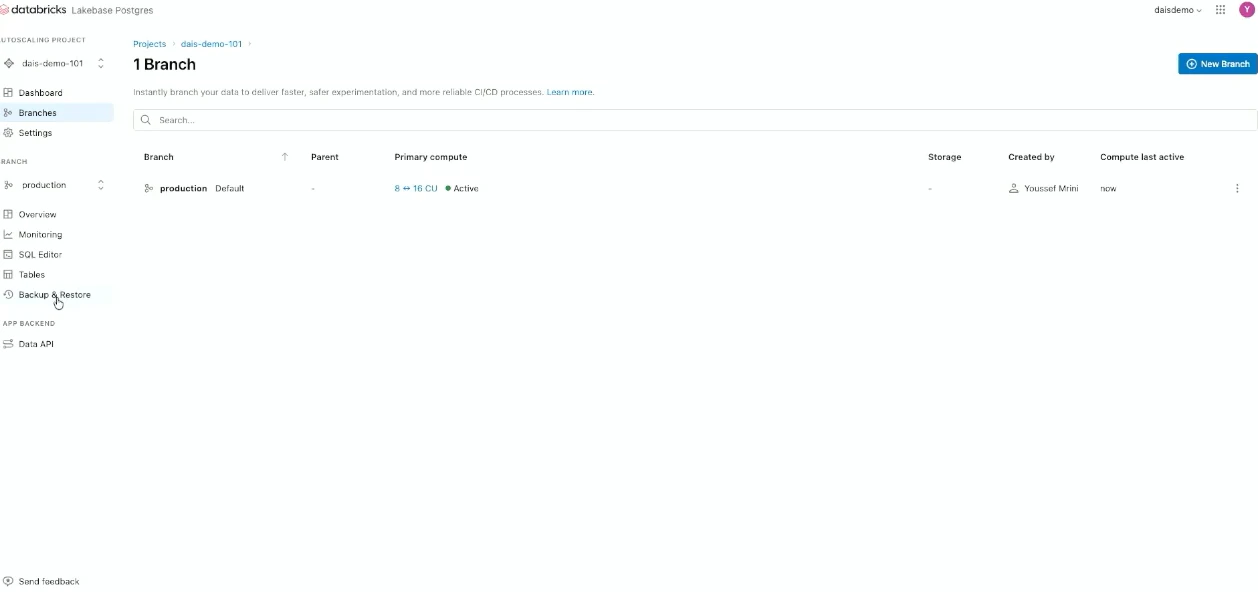
最後は、Lakebase の UI での管理画面です。
ここでは、project 作成、compute 設定、branch 作成、snapshot / restore まで扱えます。
Lakebase の UI では、project 作成だけでなく、branch の管理もできます。
この画面では、production branch や primary compute の状態を確認でき、開発用の branch を追加する流れが見えます。
branch を使うことで、DB をコピーせずに検証環境を切り出せるのが印象的でした。
このデモ全体を通して、Lakebase は
「理屈として面白い」だけでなく、
実際のアプリ運用に持ち込める実用性 がかなり強いと感じました。
読者が持ち帰れる示唆
Lakebase の発表から持ち帰れる示唆は、次の3つです。
1. DB は “常時稼働前提” で考えなくてよい
scale to zero があることで、
「DBは止めないもの」から「必要なときに起動するもの」へ 発想を変えられます。
2. 開発用環境はコピーではなく branch で考えられる
dev / staging を毎回コピーで作る運用は、
branch に置き換えるとずっと軽くなります。
3. OLTP と OLAP のつなぎ方を見直せる
ETL を前提にするよりも、
同一プラットフォーム上で同期・参照する ほうが運用しやすいケースがあります。
まとめ
Lakebase は、単なる Postgres ホスティングではなく、
Databricks のデータ基盤とアプリ基盤をつなぐ、サーバーレスな Postgres レイヤー です。
要点をあらためて整理すると、
- Postgres の互換性を保ちながら、現代的な運用に寄せている
- branch / snapshot / scale to zero によって開発運用を軽くできる
- Unity Catalog や Lakehouse と自然につながる
という3点が大きな魅力です。
「アプリのDBをどうするか」と「データ基盤をどうつなぐか」を同時に考えるなら、 かなり面白い選択肢だと感じました。
お知らせ
ナレッジコミュニケーションでは、Databricks Data + AI Summit 2026 開催に伴い、日本語でのウェビナーや現地レポートを公開しております!
DAIS2026 Recap イベント
現地参加が難しかった方や、主要トピックスを短時間で振り返りたい方向けに、Recapイベントを開催します。
セッションの要点整理や、日本企業での実装観点も交えてご紹介予定です。
▼ 開催概要・お申し込みはこちら

ナレッジコミュニケーション DAIS2026 特設サイト
DAIS2026で発表された注目テーマ、関連セッション、実務での活用ポイントを継続的に発信する特設ページです。
イベント情報の整理・社内共有にもご活用いただけます。
Databricks 導入支援サービスサイト
Databricksの導入検討から活用定着まで、課題に応じた支援メニューをご紹介しています。
「何から着手すべきか相談したい」という段階でも、お気軽にご覧ください。
 databricks.kc-cloud.jp
databricks.kc-cloud.jp