はじめに
ChatGPTをはじめ、生成AIは非常に注目を浴びています。
そして現在では単に生成AIに一般的な回答を生成させるだけでなく、RAG や SQL Agent 等を利用して社内独自のデータに対して生成AIに抽出させるような用途としても非常に需要が高いです。
データを抽出する用途のみで生成AIを利用するのもいいのですが、データを抽出した後にそのデータに対してどのようなことが言えるのか(傾向とか?)といった洞察的な回答の出力はどの程度生成AIで実現できるのか気になったので実験してみました。
さらに今回データ基盤として Databricks を使うので、洞察をする対象のデータフレームは Spark で検証してみました。
前提条件
- 分析環境に databricks を使用する
- 生成AIは Azure OpenAIを使用する
- databricks , Azure OpenAI, Python(PySpark)に関する基礎知識を前提とする
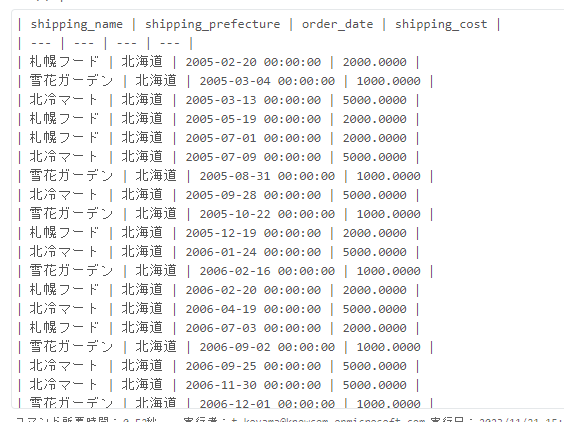
使用したデータフレーム
以下のようなデータを架空で作りました。
北海道の各店舗の注文日と配送コストが書かれています。
このデータをノートブック上で変数「df」に格納しておきます。
| shipping_name | shipping_prefecture | order_date | shipping_cost |
|---|---|---|---|
| 札幌フード | 北海道 | 2005-02-20 00:00:00 | 2000.0000 |
| 雪花ガーデン | 北海道 | 2005-03-04 00:00:00 | 1000.0000 |
| 北冷マート | 北海道 | 2005-03-13 00:00:00 | 5000.0000 |
| 札幌フード | 北海道 | 2005-05-19 00:00:00 | 2000.0000 |
| 札幌フード | 北海道 | 2005-07-01 00:00:00 | 2000.0000 |
| 北冷マート | 北海道 | 2005-07-09 00:00:00 | 5000.0000 |
| 雪花ガーデン | 北海道 | 2005-08-31 00:00:00 | 1000.0000 |
| 北冷マート | 北海道 | 2005-09-28 00:00:00 | 5000.0000 |
| 雪花ガーデン | 北海道 | 2005-10-22 00:00:00 | 1000.0000 |
| 札幌フード | 北海道 | 2005-12-19 00:00:00 | 2000.0000 |
| 北冷マート | 北海道 | 2006-01-24 00:00:00 | 5000.0000 |
| 雪花ガーデン | 北海道 | 2006-02-16 00:00:00 | 1000.0000 |
| 札幌フード | 北海道 | 2006-02-20 00:00:00 | 2000.0000 |
| 北冷マート | 北海道 | 2006-04-19 00:00:00 | 5000.0000 |
| 札幌フード | 北海道 | 2006-07-03 00:00:00 | 2000.0000 |
| 雪花ガーデン | 北海道 | 2006-09-02 00:00:00 | 1000.0000 |
| 北冷マート | 北海道 | 2006-09-25 00:00:00 | 5000.0000 |
| 北冷マート | 北海道 | 2006-11-30 00:00:00 | 5000.0000 |
| 雪花ガーデン | 北海道 | 2006-12-01 00:00:00 | 1000.0000 |
| 雪花ガーデン | 北海道 | 2007-04-29 00:00:00 | 1000.0000 |
| 札幌フード | 北海道 | 2007-05-11 00:00:00 | 2000.0000 |
| 北冷マート | 北海道 | 2007-05-31 00:00:00 | 5000.0000 |
1. データフレームをそのまま変数として生成AIのプロンプトに組み込む
こちらが一番に思いつくシンプルな方法なのかなと思います。
以下のようなプロンプトでAzure OpenAI に投げかけてみました。
|
1 2 3 4 5 6 7 8 9 |
response = openai.ChatCompletion.create( engine="ChatGPT_0301", messages=[ {"role": "system", "content": f"あなたはデータ分析者です。与えられたSparkのデータフレームを解釈し、解釈したことを洞察コメントとして複数回答してください。 なお、比較しているような洞察をしているコメントもください。事実を述べるだけでなく、なぜそうなるのか考えられる要因もつけてください。"}, {"role": "user", "content": f"後述の与えられた Spark データフレームに対して、洞察した結果を出力してください: {df}"} ]) answer = response['choices'][0]['message']['content'] print(answer) |
出力結果は以下です。
- 注文の時期ごとの送料の分布が異なる可能性があります。たとえば、休日シーズンやセール時期など、注文数が増える時期は、送料の合計額も増える可能性があります。一方で、オフシーズンやキャンペーン期間外では、注文数も少なくなり、送料の合計額も減る可能性があります。
- 都道府県ごとの送料の差異があるかもしれません。地理的な要素や物流インフラの差異により、一部の都道府県では送料が高くなる可能性があります。また、一部の都道府県では送料が無料になるプロモーションが実施されることも考えられます。
- 注文額に応じて送料が変動する場合もあります。たとえば、高額の商品を購入した顧客には送料無料サービスが提供されるかもしれません。これは、顧客の購買力を考慮しており、大口の注文を促進するための戦略として採用されることがあります。
- 注文額と送料の関係を調査することで、最適な送料設定を行うことができます。特に、送料が注文額の一部であり、利益を確保するために最適化する必要があります。データフレームを使用して、注文額と送料の関連性を分析し、収益を最大化するための最適な送料設定を特定することができます。
出力結果を見るとデータフレームの中身の内容を全然参照してくれていないように感じます。
これでは洞察とは言えないので別の方法を模索した方がよっそうです。
2. Spark Dataframe Agent を使ってみる
生成AIを利用して、Spark のデータフレームと対話のできる「Spark Dataframe Agent」というエージェントを見かけたので試しに使ってみます。
【参考】
https://docs.databricks.com/ja/large-language-models/langchain.html#spark-dataframe-agent
上記ドキュメント通りに準備していましたが、ライブラリをインポートしようとした際にエラーとなりました。

執筆時点では使えなくなっているので、以下のようにDatabricksのノートブック上にて別のライブラリをpipでインストールすると使用できるようになります。
その他の手順はドキュメント通りです。
|
1 2 3 |
%pip install langchain_experimental |
|
1 2 |
from langchain_experimental.agents.agent_toolkits.spark.base import create_spark_dataframe_agent |
以下のようなプロンプトでエージェントに問いかけてみました。
|
1 2 |
agent.run("あなたはデータ分析者です。データを解釈し、解釈したことを洞察コメントとして複数回答してください。 なお、比較しているような洞察をしているコメントもください。事実を述べるだけでなく、なぜそうなるのか考えられる要因もつけてください。必ず日本語で回答してください。") |
結果は以下になります。
Insight 1: このデータによれば、札幌フードは北海道にあるようです。北海道は日本の最北部に位置しており、食品業界が盛んな地域です。そのため、札幌フードが北海道に拠点を置いているのは、地域の資源や需要に合わせた戦略的な選択と言えます。
Insight 2: 注文日は2005年2月20日です。この日は冬の時期であり、北海道は寒冷な地域です。冬は食品の需要が高まる季節であり、札幌フードがこの時期に注文を受けたことは、需要の増加に対応した戦略的な動きと言えます。
Insight 3: 配送料は2000円です。配送料は商品の重さやサイズ、配送先の距離などによって決まることが一般的です。この場合、札幌フードの商品は比較的大きく重い可能性があります。また、北海道から他の地域への配送は距離が長いため、高い配送料が設定されていると考えられます。
Thought: I have provided multiple insights based on the data.
Final Answer: このデータによれば、札幌フードは北海道に拠点を置き、冬の時期に注文を受け、配送料は2000円となっています。これらの要素は、地域の特性や需要に合わせた戦略的な選択によるものと考えられます。
少し詳細な数値も交えて回答をしてくれていそうですね。
まだまだ一般的な回答には変わりはないですが、先ほどよりは改善がされていそうです。
3. データフレームをマークダウン形式の表に変換してプロンプトに組み込む
こちらを試すため、まずSpark のデータフレーム「df」をマークダウンに変える必要があります。
ChatGPTに以下のコードを生成してもらいました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# データフレームのスキーマとデータをマークダウン形式に変換 schema_markdown = "| " + " | ".join([f"{col}" for col in df.columns]) + " |" data_markdown = df.collect() # マークダウン形式の文字列を作成 markdown_table = f"{schema_markdown}\n" + "| " + " | ".join(["---"] * len(df.columns)) + " |\n" for row in data_markdown: markdown_table += "| " + " | ".join(map(str, row)) + " |\n" # マークダウン形式の文字列を変数に格納 markdown_variable = markdown_table # 結果を表示 print(markdown_variable) |
きちんとマークダウン形式に変換できていそうですね。すごい!
準備ができたので以下のプロンプトで結果を確認してみます。
|
1 2 3 4 5 6 7 8 9 |
response = openai.ChatCompletion.create( engine="ChatGPT_0301", messages=[ {"role": "system", "content": f"あなたはデータ分析者です。与えられたマークダウン形式の表を解釈し、解釈したことを洞察コメントとして複数回答してください。 なお、比較しているような洞察をしているコメントもください。事実を述べるだけでなく、なぜそうなるのか考えられる要因もつけてください。"}, {"role": "user", "content": f"後述の与えられたマークダウン形式の表に対して、洞察した結果を出力してください: {markdown_variable}"} ]) answer = response['choices'][0]['message']['content'] print(answer) |
洞察コメント1: 札幌フード、雪花ガーデン、北冷マートの3つの企業が北海道で商品を出荷していることがわかります。これは、北海道に本社または拠点を構える企業が顧客に対してサービスを提供しているためかもしれません。
洞察コメント2: 雪花ガーデンと札幌フードは、発注日間隔が約2週間から1ヶ月であるのに対し、北冷マートはより短い間隔での発注が見られます。これは、北冷マートがより頻繁に顧客からの注文を受けるか、またはより速いサプライチェーンを持っている可能性があります。
洞察コメント3: 雪花ガーデンの出荷費用は常に1000円である一方で、札幌フードと北冷マートの出荷費用は一定ではありません。これは、雪花ガーデンが出荷費用を固定している可能性がありますが、札幌フードと北冷マートは顧客や注文の量に応じて変動させている可能性があります。
洞察コメント4: 北冷マートは2005年と2006年に出荷費用を5000円に上げていますが、その後は変更を加えていません。これは、2005年から2006年にかけて物価上昇や運送コストの増加があり、その後は変化がなかった可能性があります。
洞察コメント5: 札幌フードと雪花ガーデンは2005年から2007年にかけても出荷費用を変更していません。これは、顧客に対して一定の出荷費用を提供することで、予測可能性と安定性を提供している可能性があります。
洞察コメント6: 2006年9月から2006年11月にかけて北冷マートは連続して5000円の出荷費用を請求しています。これは、期間中に何らかの特別なサービスや費用関連の変更がある可能性があることを示唆しています。たとえば、特別な受注プロモーション、貨物輸送の固定コストの増加、在庫不足などが考えられます。この期間のデータを詳しく見ることで、その要因を特定することができます。
こちらは具体的なデータの中身も参照して、出力結果を出してくれていますね。
よく読んでみると事実と異なる内容は一部あるのですが、それっぽい回答ができているのではないでしょうか。
4. データフレームを二次元リストに変換してプロンプトに組み込む
最後の検証になります。
まず Spark のデータフレームを一旦 pandas のデータフレームにしてリスト化をしています。
そして今までと同じようにプロンプトを書き、出力結果を確認してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 2次元リストに変換 pdf = df.toPandas() list_df = pdf.values.tolist() response = openai.ChatCompletion.create( engine="ChatGPT_0301", messages=[ {"role": "system", "content": f"あなたはデータ分析者です。二次元リストのデータを解釈し、解釈したことを洞察コメントとして複数回答してください。 なお、比較しているような洞察をしているコメントもください。事実を述べるだけでなく、なぜそうなるのか考えられる要因もつけてください。"}, {"role": "user", "content": f"後述の与えられた二次元リストのデータに対して、洞察した結果を出力してください: {list_df}"} ]) answer = response['choices'][0]['message']['content'] print(answer) |
洞察コメント1: 札幌フード、雪花ガーデン、北冷マートの3つの店舗があります。
洞察コメント2: 札幌フードと雪花ガーデンは販売価格が同じで、北冷マートはその2倍の価格です。価格の差異はブランド価値や品質の違いによる可能性があります。
洞察コメント3: 札幌フードと北冷マートは月ごとに販売を行っていますが、雪花ガーデンは一定の期間が空いていることがわかります。この差異は需要の変動や季節性による可能性があります。
洞察コメント4: 札幌フードと雪花ガーデンは特定の月に販売を集中しており、北冷マートは比較的均等に販売を行っているようです。これは各店舗の販売戦略の違いによる可能性があります。
洞察コメント5: 販売量から言えば、北冷マートの売り上げが最も高いことがわかります。これは店舗の規模や顧客の優先順位付けによる可能性があります。
一応データの中身を参照して、結果を出力してくれてそうに見えます。(矛盾している洞察も多いですが…)
マークダウンにした場合の方がより具体的に回答が得られたようにも感じますね。
まとめ
Databricks など Spark 中心のデータ処理基盤を使っていて、保有しているテーブルに対して Azure OpenAI で洞察してみたいという場合はデータフレームをマークダウン形式に変換してプロンプトを書くことをおすすめします。
それでも出力結果は矛盾していることともあるので出力結果をそのまま信じず、プロンプトを工夫するであったり、最終ジャッジは人間にておこなったほうが良いかと思います。
※ プロンプトの制限を超えないようにデータは十分に絞ってください。
Spark の分析基盤を使ってない場合でも、データに対して何かしら洞察が欲しければマークダウン形式の表にしてプロンプトに組み込むことはひとつの方法としてありかなと思います。
