
はじめに
2026年6月15日〜18日、サンフランシスコ・バーチャルにて Databricks 社主催の年次カンファレンス「Databricks Data + AI Summit 2026(DAIS2026)」が開催されています。Databricks 公式サイトでは、Data + AI Summit 2026 は 6月15日〜18日に開催され、Virtual Experience は 6月16日〜17日に提供される形で案内されています。
本記事は、DAIS2026 のセッション
Building Better Apps: Architecture Best Practices and Common Patterns on Databricks Apps
で発表された内容をもとに、Databricks Apps で本番品質のアプリを作るときに押さえたい設計の考え方を整理したものです。
Databricks Apps は、Databricks 上でデータや AI を活用したアプリケーションを構築・公開できる機能です。
データ基盤とアプリを近い場所でつなげられるため、分析や AI の成果をそのまま業務アプリに組み込みやすいのが特長です。
セッション概要でも、「アプリを作ること自体は簡単だが、セキュアで高性能、かつスケーラブルにすることが難しい」と問題提起されており、単なる機能紹介ではなく、“運用できるアプリ” をどう設計するかが主題になっていました。
本記事はDatabricks公式発表を元にした非公式の日本語要約であり、すべての著作権・知的財産権はDatabricksに帰属します。

忙しい方用
最初に結論だけまとめると、このセッションの主題は「Databricks Apps を使ってアプリを作ること」そのものではなく、Databricks Apps 上で“ちゃんと運用できるアプリ”をどう設計するかでした。Databricks Apps は、Databricks 上でデータ/AI アプリを直接ホスティングする仕組みで、Unity Catalog、Databricks SQL、OAuth ベースの認可と統合されています。
このセッションから持ち帰るべきポイントは、次の5つです。セッション概要でも、共通テーマとして接続性と状態管理、Identity/Auth、Agentic design、Performance が示されています。
- 状態管理や単票検索のような低レイテンシ処理は Lakebase
- 集計や分析表示は Databricks SQL
- ユーザーごとに見えるデータが違うなら OBO(On-Behalf-Of User Authorization)を使う
- Agent はアプリ全体ではなく、アプリの一部として設計する
- 遅いときは、まずボトルネックを測ってからスケールする
個人的には、このセッションは Databricks Apps の紹介というより、Databricks 上で業務アプリや Agentic App を本番化するための設計原則として読むと非常にしっくりきました。

このセッションが扱っていたテーマ
セッションでは、アプリの種類が違っても共通する設計原則がある、という整理がされていました。セッション概要では対象カテゴリとして Internal Tools / AI Copilots / Agentic Workflows / Customer-Facing Products が挙げられています。
発表の中身を実務寄りに言い換えると、対象はおおむね次の3タイプに整理できます。
- エージェント系アプリ
- 分析系アプリ
- 取引処理系アプリ
そして、これらに共通する重要テーマとして次の4つが示されていました。
- 接続性と状態管理
- アイデンティティと認証
- エージェント設計
- パフォーマンスとスケーリング

この整理が良いのは、アプリの見た目や用途ではなく、下支えする設計原則に焦点を当てていることです。社内ツールでも、分析アプリでも、Agentic App でも、結局問われるのは「どの処理をどの基盤に載せるか」「誰の権限で動かすか」「どこが遅いのかをどう切り分けるか」という点です。
Databricks Apps をどう捉えるべきか
Databricks Apps は、単に「Databricks 上で Web アプリを動かせる機能」ではありません。公式ドキュメントでは、Apps はサーバレス基盤上で動作し、Unity Catalog、Databricks SQL、OAuth ベースの認証認可、各種 app resources と統合するアプリ実行基盤として位置付けられています。
このセッションを踏まえると、Databricks Apps は次のように捉えるのが自然です。
- UI/UX を提供する層: Databricks Apps
- 短い read/write と状態管理: Lakebase
- 集計・分析・可視化: Databricks SQL
- ガバナンスと権限制御: Unity Catalog
- 自然言語体験やエージェント: Genie / Custom Agent / Foundation Models / AI Gateway

つまり、Apps 単体で何でもやるのではなく、Databricks の各サービスを適材適所で組み合わせる“ハブ”として使うのが本筋です。

1. 接続性と状態管理:OLTP と OLAP を分けて考える
このセッションで最初に強調されていたのが、クエリの形に応じてエンジンを選ぶことです。
Lakebase は Databricks に統合されたフルマネージド Postgres で、公式には real-time transactional applications 向けの OLTP データベースとして案内されています。Databricks Apps と組み合わせると、アプリに専用の service principal と Postgres role が割り当てられ、接続情報も環境変数として注入されます。
一方、Databricks SQL は Databricks 上のデータに対してクエリ・集計・分析を行うための SQL warehouse です。Databricks も、分析クエリには SQL warehouse を使うことを推奨しています。

使い分けの基本
-
Lakebase が向くもの
- アプリ状態
- セッション情報
- 単票検索
- フォーム入力や小さな更新
- 低レイテンシな read/write
-
Databricks SQL が向くもの
- ダッシュボード
- 集計
- レポート
- 大規模テーブルのスキャン
- 分析用の可視化
要するに、これは OLTP と OLAP の分離です。
アプリを作っていると、つい「慣れている SQL に全部載せる」「とりあえず DB に全部入れる」となりがちですが、このセッションではそこを明確に戒めていました。

実務での読み替え
この考え方は、アプリ設計としてはかなり CQRS 的です。
- Command / 状態変更 → Lakebase
- Query / 分析表示 → Databricks SQL
ここが共通設計パターン
このセッションの共通パターンの1つは、Query-Shape-Driven Compute Selection、つまり「アプリ種別ではなくクエリ形状で基盤を選ぶ」ことだと思います。
分析系アプリでも、実際には UI の状態保持や選択肢一覧のような OLTP 的処理があります。逆に業務アプリでも、履歴分析や集計が必要です。
だからこそ、アプリ単位ではなく処理単位でエンジンを分ける設計が効いてきます。


2. アイデンティティと認証:OBO を前提に考える
次に重要なのが、誰の権限でクエリを実行しているのかです。
Databricks Apps の認可モデルは OAuth 2.0 ベースで、公式には大きく app authorization と user authorization の2つがあります。user authorization は、いわゆる on-behalf-of-user authorization(OBO) で、Databricks がユーザーの access token をアプリに forward し、そのユーザー本人としてリソースにアクセスできます。
Unity Catalog は、権限管理に加えて、行フィルタや列マスクなどの細粒度アクセス制御を提供します。つまり、アプリでもユーザーごとの見え方を正しく再現したいなら、OBO でユーザー本人の権限をそのまま使うのが自然です。

App SP と OBO の使い分け
-
App service principal が向くもの
- 共有状態の更新
- バックグラウンド処理
- ユーザーに依存しないメンテナンス処理
-
OBO が向くもの
- ユーザーごとに見えるデータが違うクエリ
- Unity Catalog のポリシーをそのまま尊重したい処理
- 監査証跡をユーザー単位で残したいケース

なぜここが重要か
プロトタイプでは shared identity でも動きます。
でも本番では、次の問いに答えられないと困ります。
- 誰がこのデータを見たのか
- どの権限でこのクエリが動いたのか
- 行フィルタや列マスクは本当に効いているのか

ここが共通設計パターン
ここでの共通パターンは OBO-First Governed Access です。
ユーザーごとにデータの見え方が変わるなら、まず OBO を第一候補にする。
そして、ユーザーに依存しない処理だけを app service principal に寄せる。
この Hybrid Identity Pattern を取ると、セキュリティ、監査、責務分離が一気に整理しやすくなります。
3. Agent 設計:Agent はアプリ全体ではなく“1コンポーネント”
このセッションで個人的に最も印象的だったのは、Agent はアプリ全体ではなく、アプリの一部として設計するべきというメッセージでした。
Databricks は、Apps に Genie Space を app resource として追加する方法を公式に提供しています。また、AppKit には Genie plugin や GenieChat コンポーネントがあり、自然言語でのデータ問い合わせ UI を比較的簡単に組み込めます。
さらに、Databricks は Apps 上で custom AI agent をデプロイする方法も公式に提供しています。Custom Agent の実装では、Databricks Apps を agent のホスティング先として使えます。

何が大事か
Agent を入れると、つい「全部 AI にやらせたくなる」のですが、実際の業務アプリではそう単純ではありません。
多くの場合、より堅牢なのは次のような構成です。
- 定型入力はフォームやフィルタ UI
- データ探索は Genie
- 自由対話が必要な部分だけ Agent
- 外部ツール呼び出しやモデル統制は AI Gateway

Unity AI Gateway は、Databricks における agents や LLMs のガバナンス層として案内されており、権限、usage tracking、monitoring などを提供します。外部モデルを使う場合も、この統制レイヤーを意識するのがよさそうです。
AppKit と Genie が効く理由
AppKit は、Databricks Engineer が提供する React ベースの開発体験で、plugin による resource 統合や OBO 実行パターンも持っています。FAQ でも .asUser(req) による OBO 実行が説明されています。
これはつまり、Agent をゼロから全部組むのではなく、Databricks 側の resource / plugin / auth パターンに乗せる方が、安全で保守しやすいということです。

MLflow Agent Server も重要
もし custom agent を実装するなら、MLflow Agent Server も重要です。MLflow 公式では、Agent Server は FastAPI ベースで、request validation、streaming support、tracing を備えた本番向けの agent serving 基盤として説明されています。Databricks の migration ガイドでも、Apps 上の agent 実装に MLflow Agent Server のパターンが使われています。


ここが共通設計パターン
ここでの共通パターンは Agent-as-a-Component Pattern です。
Agent を万能化するのではなく、必要な場所にだけ埋め込む。
この発想の方が、ガードレール、権限制御、UX の予測可能性を維持しやすいはずです。
4. パフォーマンスとスケーリング:増やす前に、どこが遅いかを見る
最後のテーマはパフォーマンスです。ここでもセッションのメッセージは明快で、いきなり Apps compute を増やすな、まずボトルネックを見極めろでした。
Databricks Apps の best practices でも、アプリ compute は UI レンダリング向けであり、重いデータ処理や推論は Databricks SQL、Lakeflow Jobs、Model Serving へオフロードすべきとされています。

スケーリングの選択肢
Databricks Apps には compute size の設定があり、公式 docs では instance size を調整できます。また、Horizontal scaling for Databricks apps が提供されており、複数インスタンスを単一 URL の背後で動かし、高可用性・並行性・session affinity を実現できます。これは 2026年5月に Beta として公開されています。

でも、本当に詰まっているのはどこか
アプリが遅いとき、原因候補は Apps compute だけではありません。
- ブラウザ描画
- アプリサーバ
- SQL Warehouse
- Lakebase
- LLM / 外部 API
たとえば、巨大リストの描画が遅いならブラウザ側の問題かもしれません。クエリが遅いなら warehouse のサイズやクエリ設計の問題かもしれません。Agent の返答が遅いならモデル推論待ちかもしれません。
つまり、レスポンスの遅さをレイヤーごとに分解する triage が先です。

すぐ効く実践テクニック
発表で挙がっていたテクニックは、実務でも効きそうなものばかりでした。
- volume 上の静的ファイルを app disk にキャッシュ
- Lakebase 接続に connection pooling を使う
- 複数クエリは逐次でなく並列で投げる
- cache はユーザーに近い層へ置く
- browser storage
- app memory
- app disk
- database
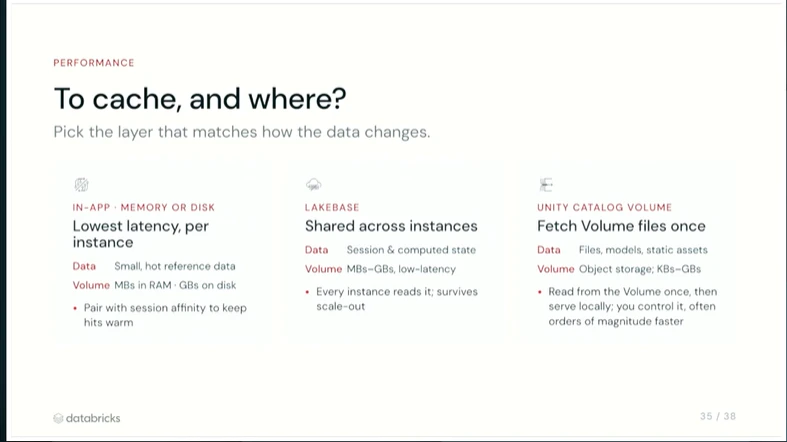
session affinity があると、同一ユーザーを同じインスタンスへ best-effort で寄せられるので、短命な per-user cache を扱う設計とも相性が良いです。
ここが共通設計パターン
ここでの共通パターンは Profile-Before-Scale Pattern です。
先に測る。
詰まっているレイヤーを切る。
そのうえで vertical / horizontal のどちらを使うか考える。
これは Apps に限らず良い設計原則ですが、このセッションはそこをかなり実践的に言語化してくれていました。
このセッションから見える、Databricks Apps の共通設計パターン
ここまでをまとめると、このセッションで示されていた共通パターンは次のように整理できます。
1. 処理の形で基盤を選ぶ
処理の形で基盤を分ける。
OLTP は Lakebase、OLAP は Databricks SQL。
2. ユーザー権限が必要な処理は OBO を優先する
ユーザーごとに見えるデータが違うなら、まず OBO を選ぶ。
Unity Catalog の権限制御をそのまま活かしやすくなる。
3. App SP と OBO の使い分け
共有処理は app SP、ユーザー依存処理は OBO。
責務分離と監査性が高い。
4. Agent はアプリの一部として扱う
Agent をアプリの1部品として置く。
Genie、フォーム、定型 UI、LLM を混在させる方が堅牢。
5. スケール前に計測する
スケールの前にプロファイリングする。
Apps compute だけを疑わない。

まとめ
このセッションは、Databricks Apps の機能紹介というより、Databricks 上で本番運用に耐えるアプリをどう設計するかを整理した発表でした。
特に重要だったのは、次の4点です。
- 状態管理と分析クエリを同じエンジンに押し込まない
- ユーザー権限を尊重すべきデータアクセスは OBO を基本にする
- Agent はアプリ全体ではなく、アプリの一部として設計する
- 性能問題は、まずプロファイリングしてからスケールする
Databricks Apps の価値は、単に Web アプリを動かせることではなく、Lakebase・Databricks SQL・Unity Catalog・Genie・Custom Agent・AI Gateway を、Databricks 上で一体的に組み合わせられることにあります。
「まず動くアプリ」から「運用できるアプリ」へ進むうえで、かなり参考になるセッションでした。
参考資料
-
DAIS2026 セッションページ
https://www.databricks.com/dataaisummit/session/building-better-apps-architecture-best-practices-and-common-patterns -
Databricks Data + AI Summit 2026
https://www.databricks.com/dataaisummit -
Virtual Experience — Data + AI Summit 2026
https://www.databricks.com/dataaisummit/virtual-experience -
Databricks Apps 公式ドキュメント
https://docs.databricks.com/aws/en/dev-tools/databricks-apps/ -
Databricks Apps の認可設定
https://docs.databricks.com/aws/en/dev-tools/databricks-apps/auth -
Databricks Apps のベストプラクティス
https://docs.databricks.com/aws/en/dev-tools/databricks-apps/best-practices -
Lakebase と Databricks Apps の連携
https://docs.databricks.com/aws/en/oltp/projects/databricks-apps -
Lakebase Postgres 概要
https://docs.databricks.com/aws/en/oltp/projects/ -
Databricks SQL / SQL Warehouse
https://docs.databricks.com/aws/en/compute/sql-warehouse/
お知らせ
ナレッジコミュニケーションでは、Databricks Data + AI Summit 2026 開催に伴い、日本語でのウェビナーや現地レポートを公開しております。
DAIS2026 Recap イベント
現地参加が難しかった方や、主要トピックスを短時間で振り返りたい方向けに、Recapイベントを開催します。
セッションの要点整理や、日本企業での実装観点も交えてご紹介予定です。
▼ 開催概要・お申し込みはこちら

ナレッジコミュニケーション DAIS2026 特設サイト
DAIS2026で発表された注目テーマ、関連セッション、実務での活用ポイントを継続的に発信する特設ページです。
イベント情報の整理・社内共有にもご活用いただけます。
Databricks 導入支援サービスサイト
Databricksの導入検討から活用定着まで、課題に応じた支援メニューをご紹介しています。
「何から着手すべきか相談したい」という段階でも、お気軽にご覧ください。
 databricks.kc-cloud.jp
databricks.kc-cloud.jp