前回記事
Databricks File System (DBFS)
Azure DatabricksのClusterには、Databricks File System (DBFS)という分散ファイルシステムがインストールされています。DBFSのファイルはAzure Blob Storageに永続化されるため、Clusterが終了してもデータが保持されるようになっています。
NotebookからDBFSにアクセスする場合には、Databricks Utilities(dbutils)、Spark API、open関数等のFileIOを使用しますが、OSとDBFSでルートディレクトリの扱いが異なるため、ファイルにアクセスする上で注意が必要になります。
Databricks Utilities(dbutils)
dbutilsでは、DBFSのルートディレクトリを基準にパスを参照します。
dbutilsで「/mnt/my_blob_container」を指定した場合は「dbfs:/mnt/my_blob_container」を参照することになります。
dbutilsでClusterのローカルストレージを参照する場合は「file:/home/ubuntu」のように、OSのローカルパスに「file:」を追加したものを使用します。
Spark API
Spark APIでファイルを読み込む場合、DBFSのルートディレクトリを基準にパスを参照します。
ただし、dbutilsとは異なり「file:/home/ubuntu」のような形でClusterのローカルストレージを参照することはできません。
そのため、Sparkでファイルの読み込みを行う場合はファイルをDBFS上に配置する必要があります。
FileIO (上記2つ以外のファイル操作)
Pythonのopen関数等のFileIOで読み込みを行う場合、OSのルートディレクトリを基準にパスを参照します。
DBFSルートディレクトリはOS「/dbfs」にマウントされているため、DBFSの「/mnt/my_blob_container」にアクセスする場合は、「/dbfs/mnt/my_blob_container」のように「/dbfs」を追加したパスを使用します。
マジックコマンド
Databricksでは、セルにマジックコマンドを指定することで、各種スクリプトの実行ができます。
マジックコマンドは1セルにつき1つだけ指定できます。
Markdown形式でのコメント挿入: %md
セルにMarkdownを記載してコメントとして挿入します。
|
1 2 3 4 5 6 |
%md ## Blob Storageのマウント | 項目 | 設定値 | | :-- | :-- | | ストレージアカウント | ●●●●●●●● | | Blobコンテナ | ●●●●●●●●●● | |

Databricks File System(DBFS)のファイル操作: %fs
Databricksの分散ファイルシステムであるDBFSのリスト、コピーといったファイル操作をシェルコマンドライクに記述して実行します。
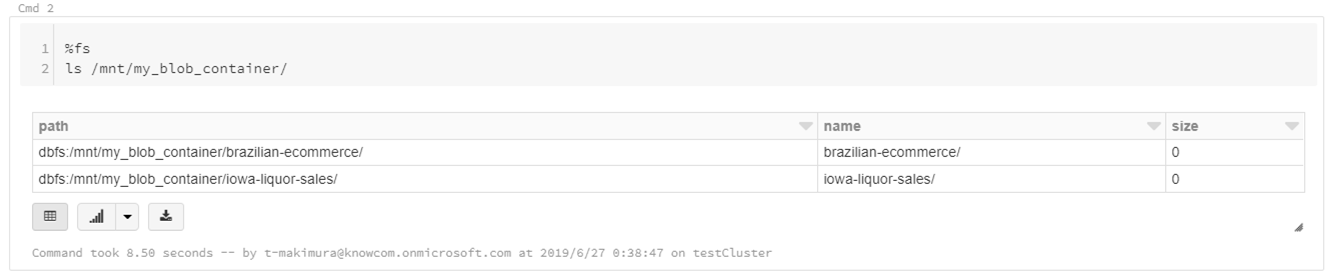
ディレクトリにあるファイルのリストを表示する場合は、下記コマンドを使用します。
|
1 2 |
%fs ls /mnt/blob_container/ |
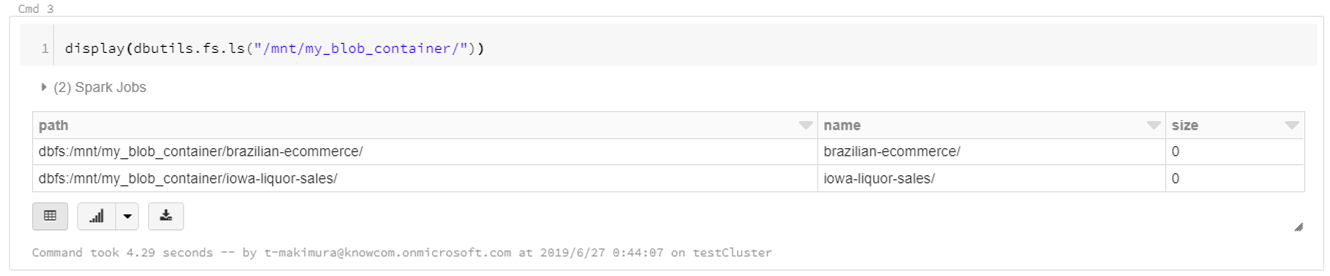
上記コマンドはPythonの下記スクリプト実行結果と同等となります。
|
1 |
display(dbutils.fs.ls("/mnt/my_blob_container/")) |
OS (Linux)のシェルコマンド実行: %sh
OSのシェルコマンドを実行する場合には「%sh」を使用します。
DBFSを%shで参照する場合は下記のとおりです。
|
1 2 |
%sh ls /dbfs/mnt/my_blob_container/ |

各言語のスクリプト実行: %python, %scala, %sql, %r
Notebookで指定した言語以外の言語を使用する場合は、対応言語のマジックコマンドを使用します。
|
1 2 3 |
%scala var x = 100 x |
|
1 2 3 |
%r y <- 100 y |
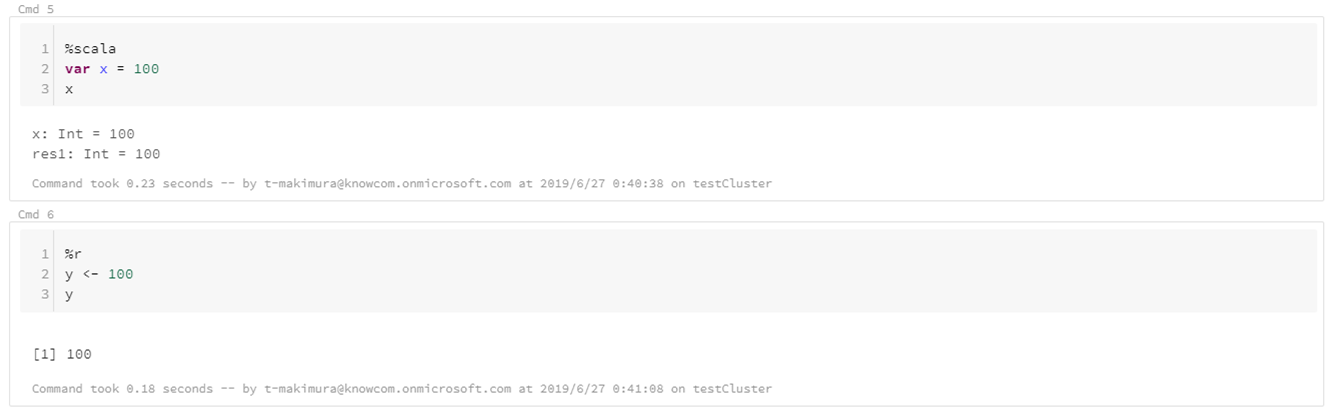
言語間で変数は共有されないため、マジックコマンドの変数に値を引き渡す場合は一旦DBFSにファイル出力をする等で渡す必要があります。

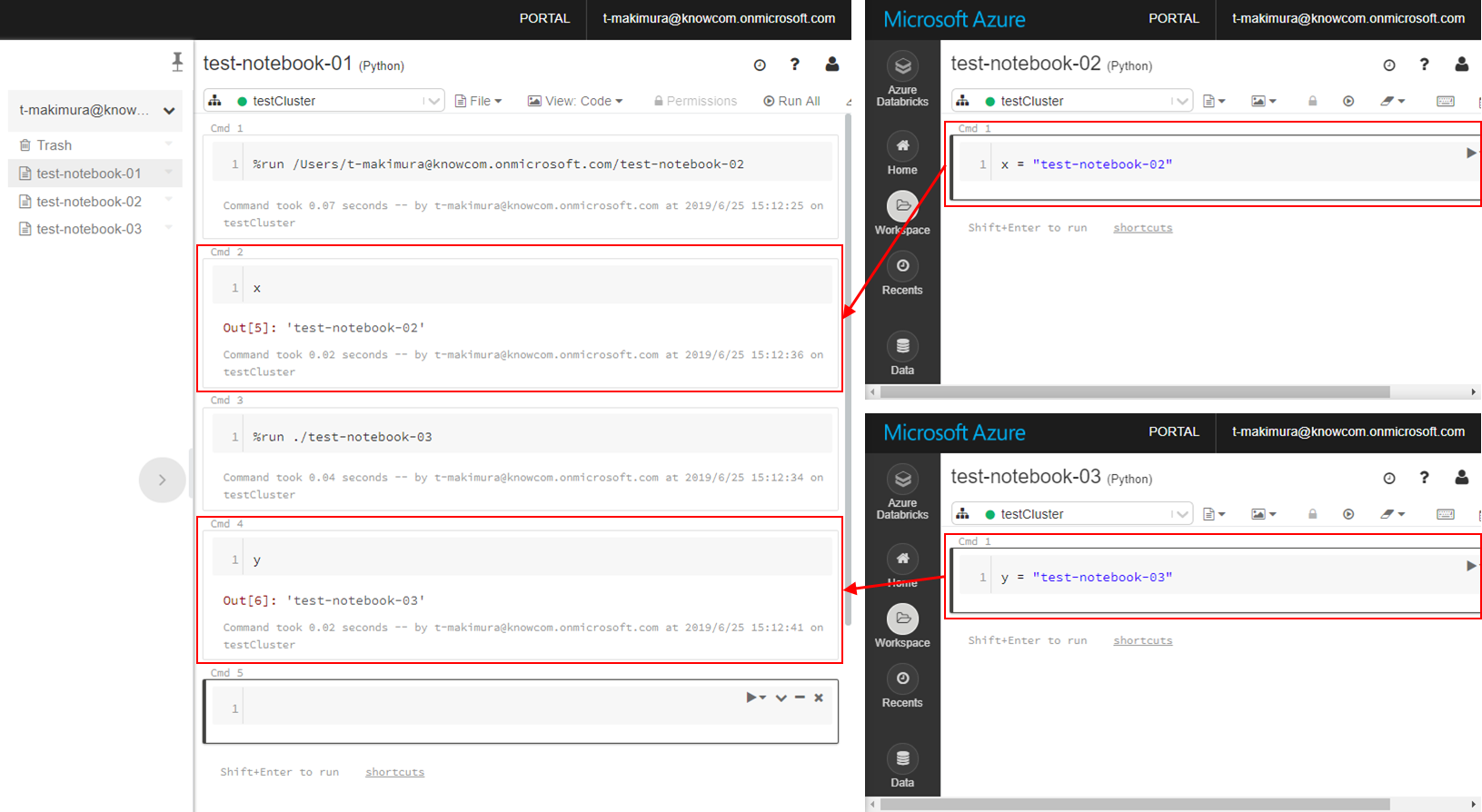
他のNotebookの実行と読み込み: %run
他のNotebookを実行する場合は「%run」で対象Notebookを指定して実行します。
%runで実行すると、同じ言語であれば他のNotebookで定義された変数をそのままの変数名で参照することができます。
メンテナンス性を高めるために、スキーマ定義を別Notebookで記述しておくといったような使い方ができます。
|
1 |
%run /Users/{ユーザー名}/{Notebook名} |
参考
Azure Databricksの導入ならナレコムにおまかせください。
導入から活用方法までサポートします。お気軽にご相談ください。
Azure Databricksソリューションページはこちら
