今回は、Azure Machine Learning (Azure ML)を使ったクラスタリングをご紹介します。クラスタリングは多項分類と異なり、データの分類に教師データを必要としない点が特徴ですが、実際にどの程度正確に分類が行われるかを検証していきます。
サンプルデータ
サンプルデータには、多項分類で用いた乱数パターンを使用しました。
※サンプルデータの詳細については、Azure Machine Learningで多項分類を試してみた。を参照ください。
・基本パターン

・サンプルデータ

クラスタリングモデルの作成
クラスタリングは教師なし学習のため、教師あり学習の回帰分析や多項分類とは異なるモジュールを使います。
「K-Means Clustering」、「Train Clustering Model」および「Assign Data to Clusters」がそれぞれクラスタリングにおけるアルゴリズム、教師モデル作成、モデルの適用に関するモジュールになります。以下が基本的なクラスタリングのモジュール構成になります。
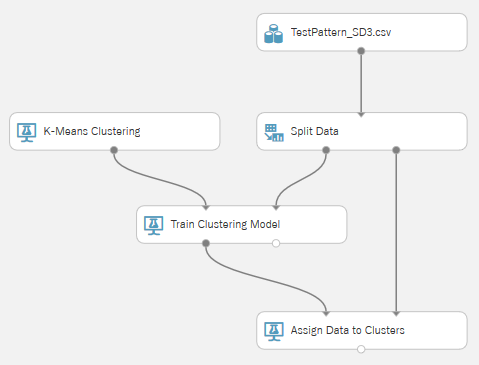
モジュールが組み上がったら、各モジュールの設定を行います。
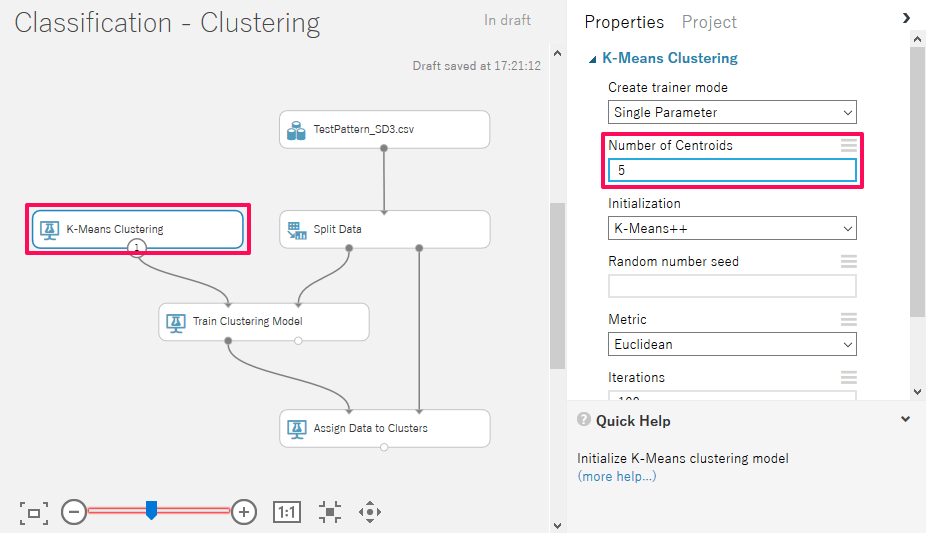
まず、「K-Means Clustering」で分類するクラスタの数を設定します。今回は5個のパターンに分類するため、「Number of Centroids」を5に設定しています。
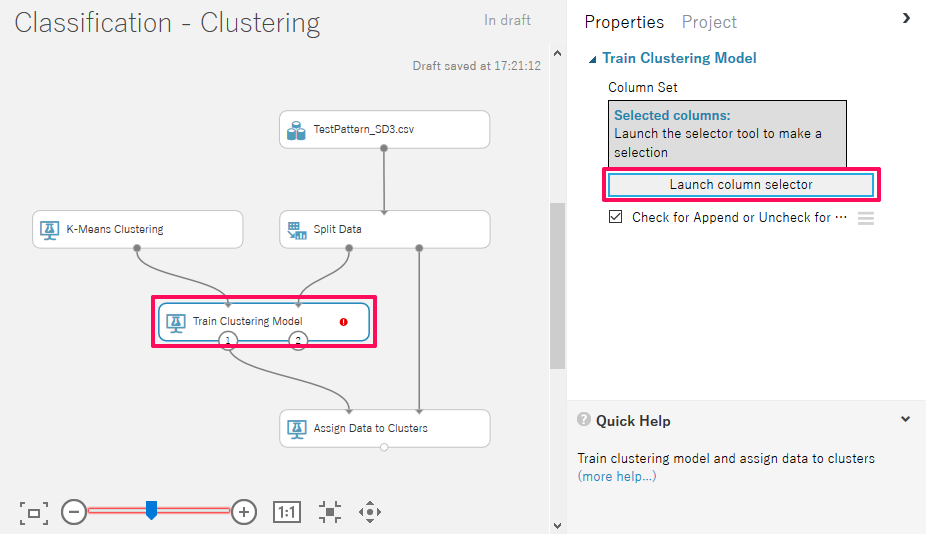
続いて「Train Clustering Model」で、クラスタリングの参考にするパラメータを設定します。
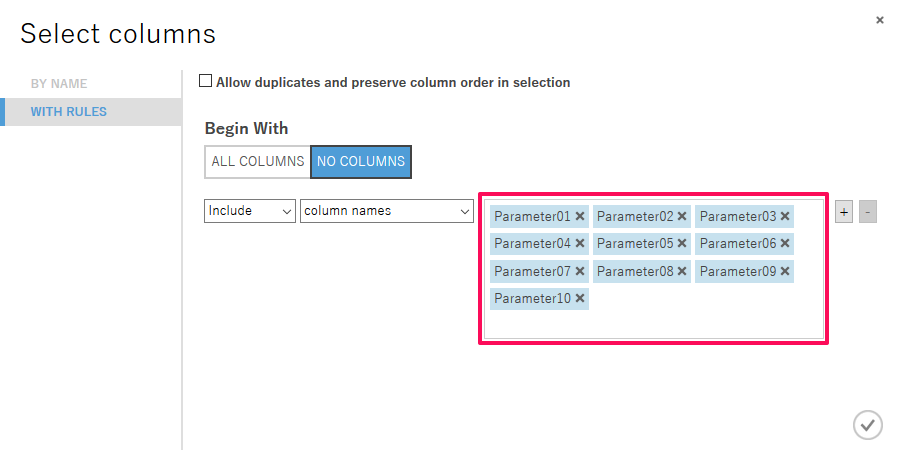
右ペインで「Launch Column Selector」をクリックし、参照パラメータを選択していきます。
乱数パターンは10個のパラメータで構成されるため、10個のパラメータすべてを選択しました。
設定が終わったら、「RUN」をクリックしてモデルを実行します。実行にかかった時間は約20秒でした。
モデル評価
多項分類と異なり、クラスタリングでは教師データを必要としません。
裏を返せば、答えとなるデータがないため、そのクラスタリングの精度を評価する機能が存在しないということになります。
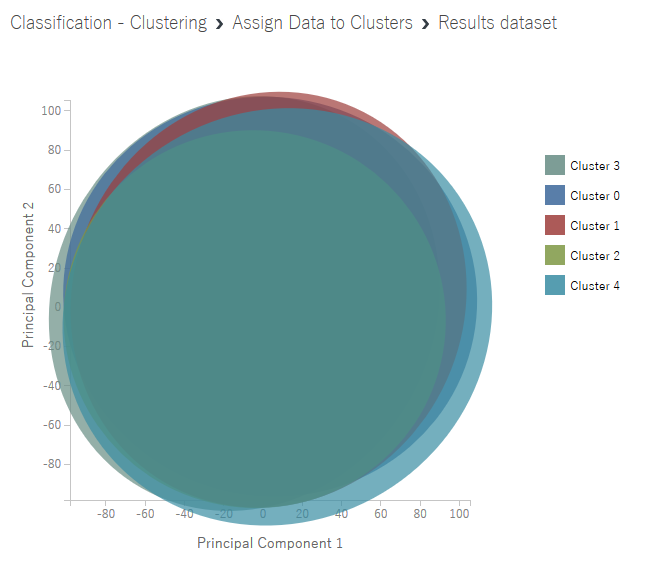
実際に「Assign Data to Clusters」の結果を「Visualize」で表示しても、クラスタのチャートが表示されるだけで、評価に関する項目は表示されません。
このチャート自体も何を示しているかよくわかりません。
そこで、どの程度正しくクラスタリングができているのかを評価するため、出力されたデータを処理して、マトリクス図として出力してみます。
最初のモデルでは出力されたデータをダウンロードすることができないため、「Assign Data to Clusters」の後段に「Convert to CSV」を追加して改めてモデルを実行します。
「Convert to CSV」を右クリックし「Results Dataset」→「Download」を選択すると、出力された結果をCSV形式でダウンロードすることができます。
※今回は簡易的な方法でダウンロードしていますが、「Writer」モジュールを使ってストレージ経由で取得することもできます。
参照: 「Azure Machine Learning からBLOBストレージに接続してみる。」
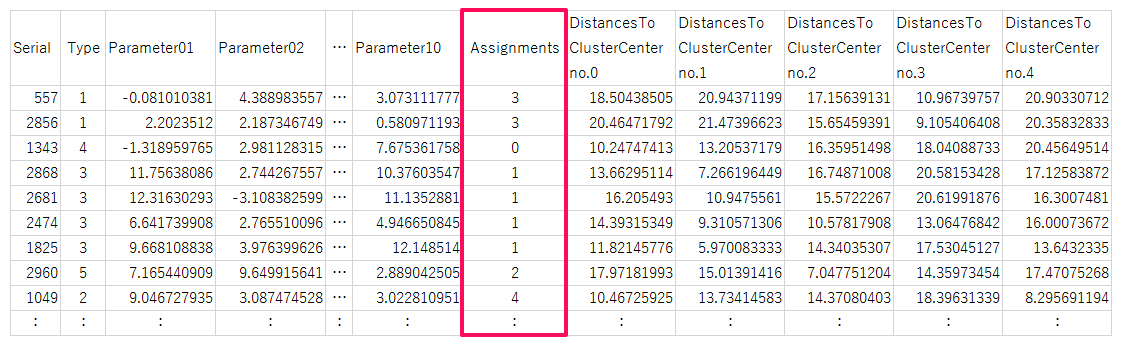
出力データの「Assignment」が分類されたクラスタになります。
教師データはないため、番号についてはAzure MLで自動的に採番されます
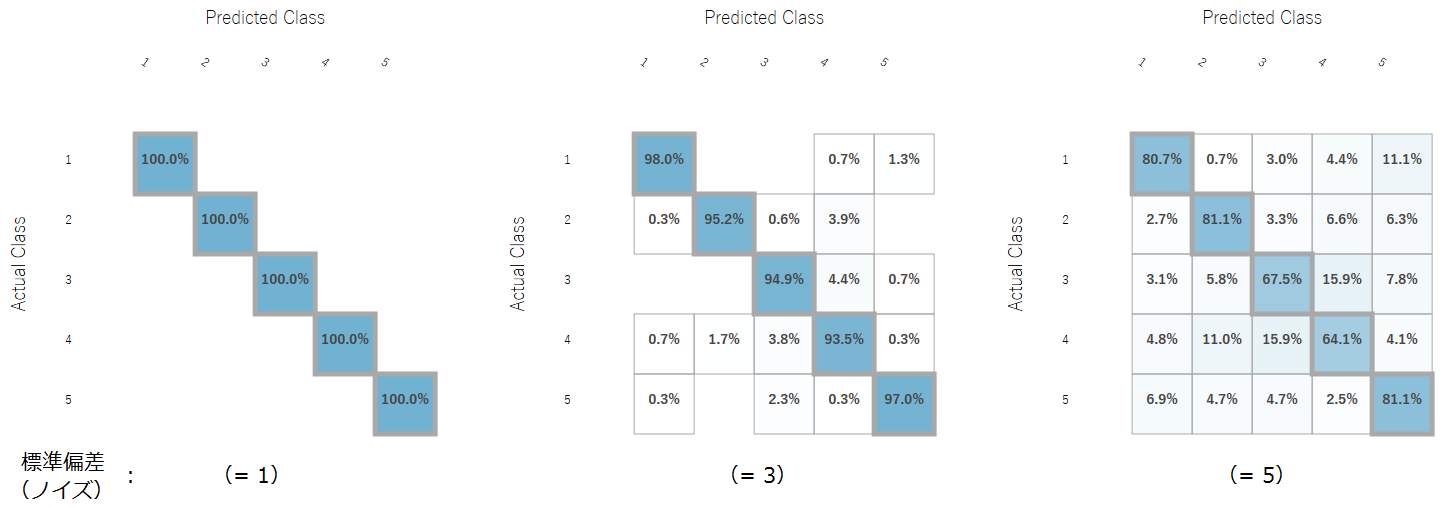
出力結果を基にデータ処理を行い、多項分類と同じような形式で分類の正答率を算出してみました。
今回使用したデータでは、多項分類と遜色なく分類ができていることが分かりました。
・クラスタリング
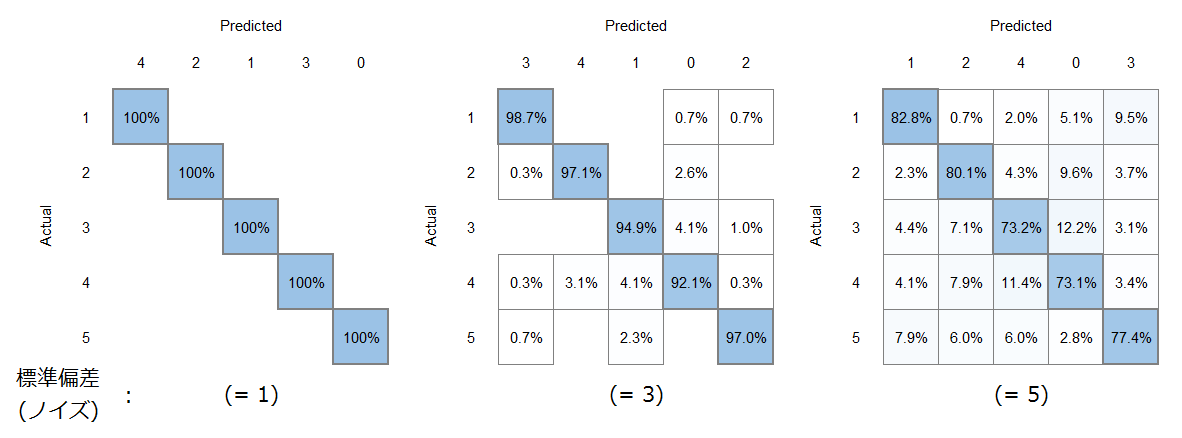
・多項分類
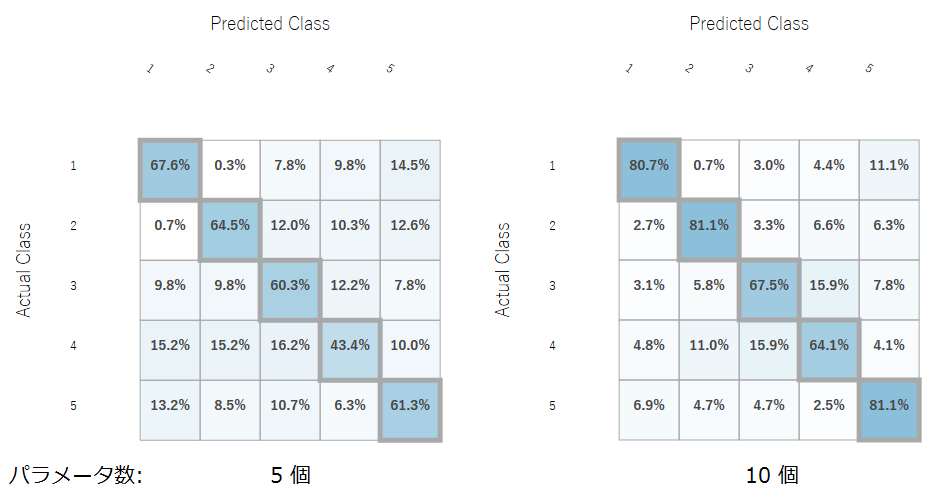
多項分類と同様に参照するパラメータを半分の5個にした場合も検証してみました。
こちらも多項分類と同等の分類ができており、やはり有意なパラメータが多いほど分類精度が上がることが分かりました。
・クラスタリング
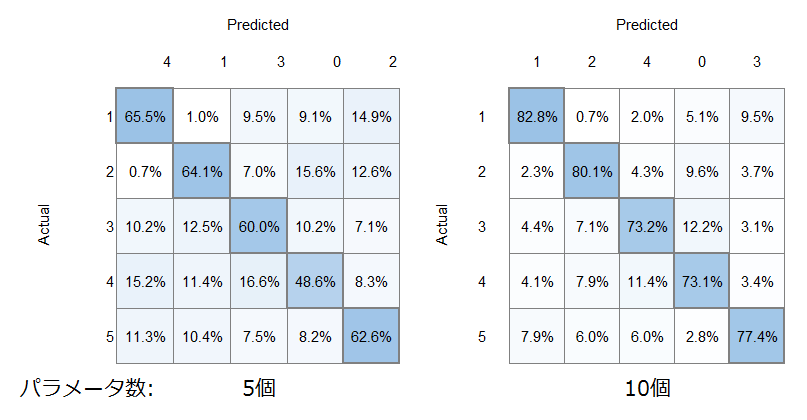
・多項分類
いかがでしたでしょうか。
クラスタリングでは教師データがなくてもデータの傾向から自動で分類を行えるため、関係性が分からないデータを一先ず流し込んでみるだけでも有用な情報が得られるのではないでしょうか。
注意点としては、分類の判断は機械学習によって行われるため、ヒトの感覚とは異なる分類が行われることがあるということで、クラスタ数や分類条件といったモジュールのパラメータ調整を行わなければならない場合もあります。
ですので、教師データを作れるなら「多項分類」、作らず簡単に分類するなら「クラスタリング」というように用途を分けて使ってみてください。
次回もお楽しみに!!
