前回につづいてAzure Machine Learningで提供されているAPIの紹介です。
◯project oxford
http://www.projectoxford.ai/
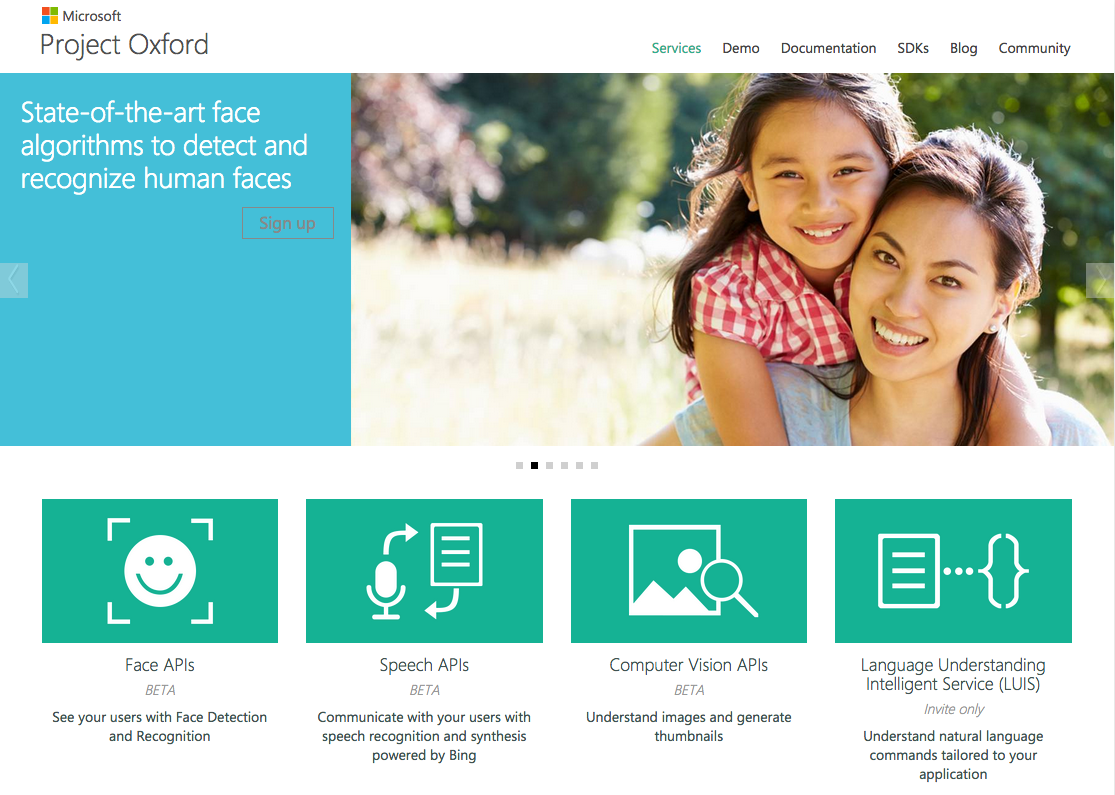
今回紹介するのがSpeech to Text, Text to Speechの2つです。
どちらもAPIから簡単に利用することが出来ます。
機能紹介
大きく以下の機能を提供しております。
● 音声データのテキスト化
・ 英語(米、英)
・ 中国語
・ フランス語
・ ドイツ語
・ イタリア語
・ スペイン語
※2015年7月現在日本語には対応しておりません。
● テキストの音声化
・ 日本語を含む17種類に対応
● 言語意図解釈
※デモは無く、ドキュメントにも記載が無いようです。
それぞれの詳細は以下となります。
1. Speech to Text
※ブラウザによって対応できる機能が異なっているようです。
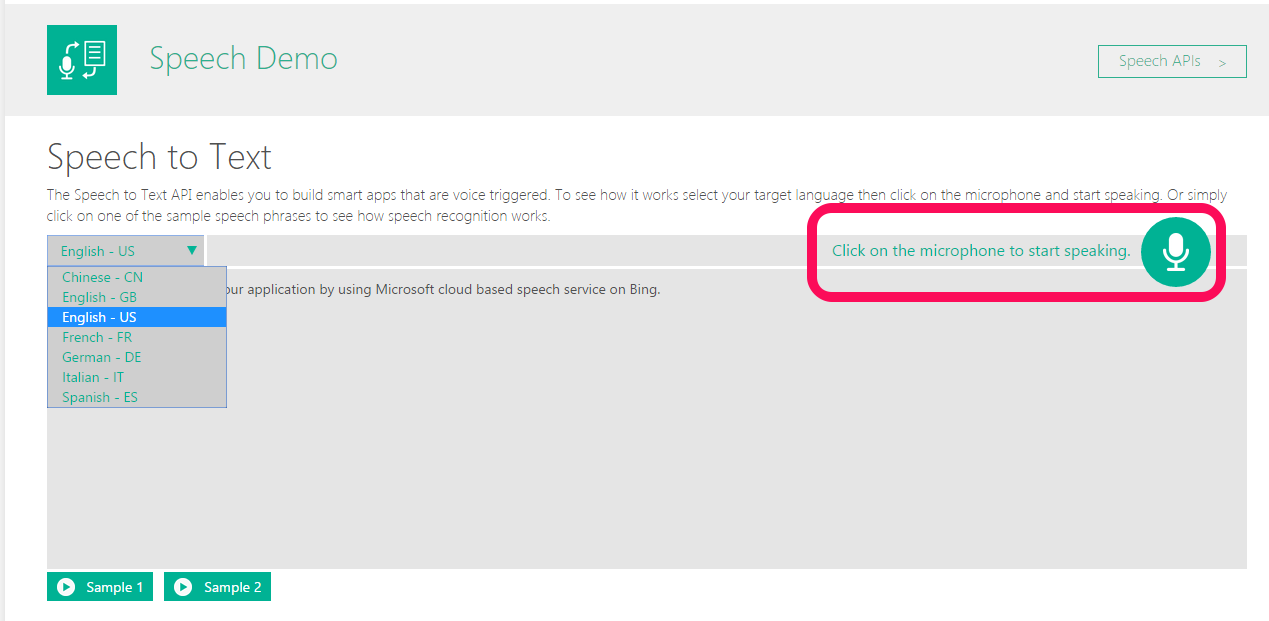
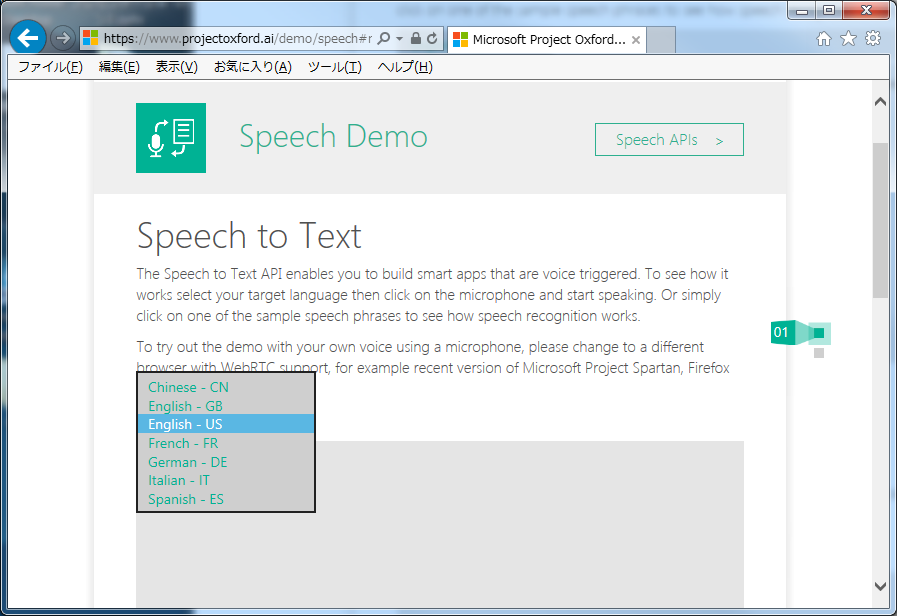
音声データをテキストに変換します。
これが進むと議事録等の文字起こしの自動化なんかが出来ますね。
Internet Explorerでは使えませんでしたが、Chromeではブラウザ上にもマイク画像が表示されており、クリックすると話しかけた内容が表示される事が確認できます。
この機能は先日リリースされたWindows 10に実装されているCortanaに実装されている会話機能に活かされているものだと思われます。
英語の中でも、アメリカとイギリスの英語についてはユーザー側でどちらかを選択する必要があるようです。
iOSやAndroid用のSDKが提供されており、スマートフォンアプリケーションの中に組み込むことが出来るので、Siriの様に話しかけられた内容をアプリケーション側に文字情報として引き渡すことが出来ます。
2. Text to Speech
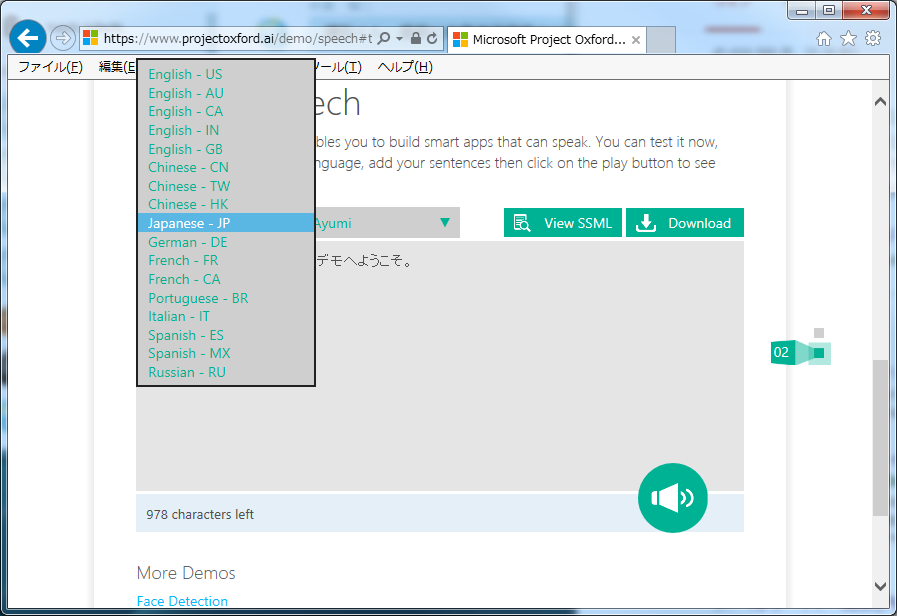
文字情報を発声してくれます。
文脈を理解して、発声してくれます。
英語だけでも、アメリカ・オーストラリア・カナダ・インド・イギリスの発音に対応しており、スペイン語もスペイン・メキシコと地域ごとの発音の特徴にあった発声が出来ます。
面白いのが、ただ発声するだけでなく、喋る人を選ぶことが出来ます。言語ごとに異なるキャラクターがいて、日本語だと「Ayumi」「Ichiro」の二人から選ぶことが出来ます。
より人間ぽく喋る事や、文脈によって読み方が変わる単語など、様々な技術的に難しい要因がありますが、その部分に機械学習を利用することで精度をあげています。
ちなみに弊社にいるロボット(Pepper/NAO)と比較してみましたが、精度はAzure Machine Learningの方が高いと感じました。
例えば「三菱東京UFJ銀行」の様なローマ字入りの文字はロボットでは読めないため「三菱東京ユーエフジェイ銀行」と入力する必要があったり、「僕はロボット」と入力すると「しもべはロボット」と発声するといった感じです。
ただし、単語によっては「神の僕」と入れても「かみのぼく」という風に間違えて発音するものもあるようですが、ここはクラウド型の利点で、どんどん精度が上がっていくものと思われます。
是非日本語対応した際には社内でも様々な用途で使ってみたいですね。
特に電話や会議といった音声が簡単に文字で残せるように出来たらいいですね。
ナレコムクラウドでは機械学習を含めたAIやロボットといった事に興味があるエンジニアを募集しております。未経験の方でも興味がある方はお気軽にお問い合せ下さい。
