最近話題の機械学習、数あるアルゴリズムの中でも今回はサンプルデータを用いてレコメンドモデルの作成を紹介していきます。
準備
早速Azure MLstudioを起動
新しいExperimentを作成します!
左下の「+」をクリックし、「Blank Experiment」を選択します。
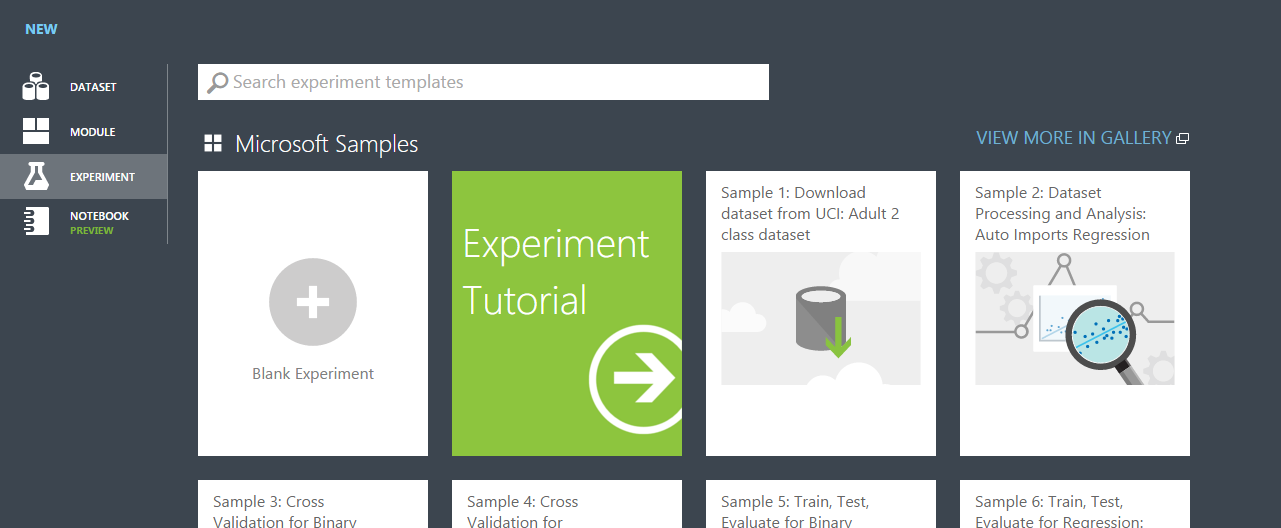
ここからサンプルを選択して構成を確認することもできます。
空っぽの実験場(Experiment)
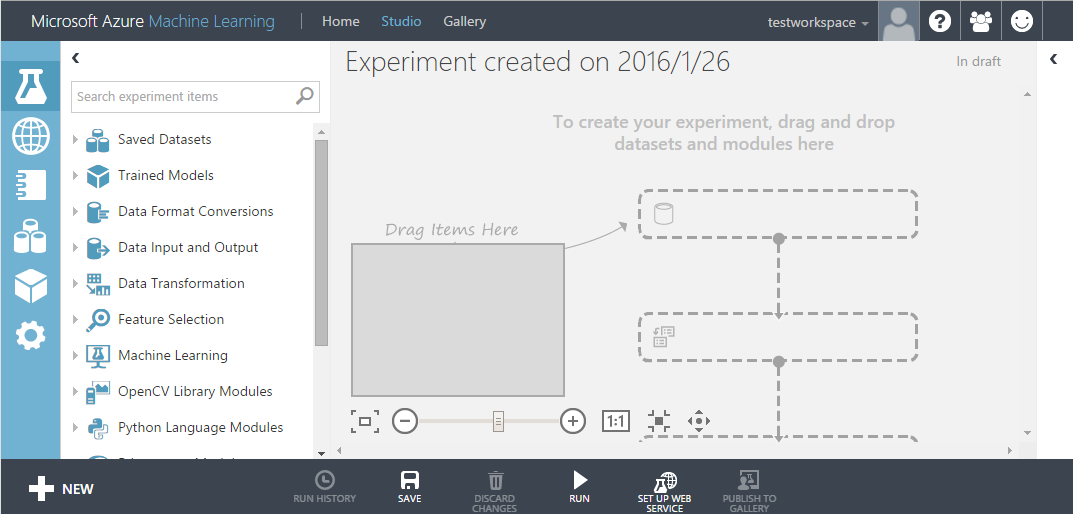
データの種類と制約
まずはデータを用意します。
レコメンドを行うためには3種類のデータが必要です。
サンプルで用意されている飲食店データを例に取って説明します。
サンプルデータセットは「Saved Datasets」の「Samples」内にあります。
後で使うのでドラッグアンドドロップして置いておきます。
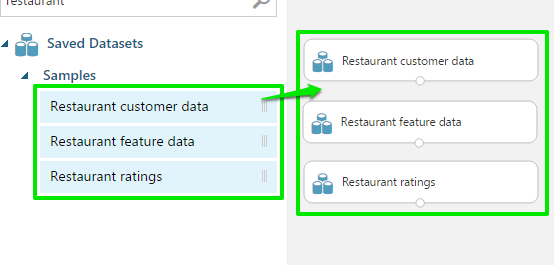
それぞれのデータは上から
1. 個人の特徴を表したデータ
内容:ユーザID、緯度経度での位置情報、喫煙の有無、生まれ年など
2. お店の特徴を表したデータ
内容:レストランID、緯度経度での位置情報、喫煙所の有無、価格、ドレスコードなど
3. 個人のお店への評価データ
内容:ユーザID、店舗ID、評価値
です。
両者の特徴を表したデータとその間を繋ぐ評価データが必要なことが分かります。
※評価データで注意しなくてはならない点として
評価する側、評価される側、評価値という形式にしておく必要があります。
今回のレストランの場合はユーザID、レストランID、ユーザのレストランへの評価という順番です。
また評価する側、評価される側の組み合わせがユニークである必要があります。
今回の場合を例に出すと1ユーザは1レストランに対して1評価までということです。

複数評価値があると以下のエラーが出ます。
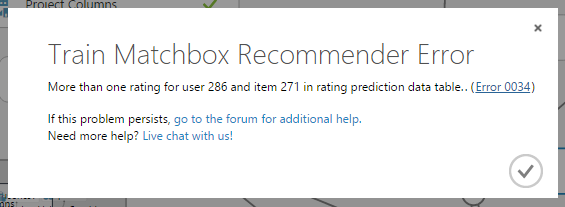
https://msdn.microsoft.com/library/azure/60822377-DA7A-40B8-0034-D185D1509344
データの分割
全データを用いて学習してしまうと評価にも同じデータを使うことになってしまうため分割してモデル作成、評価を行います。
データの分割は「Split Data」モジュールで行います。
「Restaurant ratings」データの出力端子からSplit Dataにドラッグアンドドロップで繋ぎ、
Splitting modeはレコメンド用の「Recommender Split」を選択します。
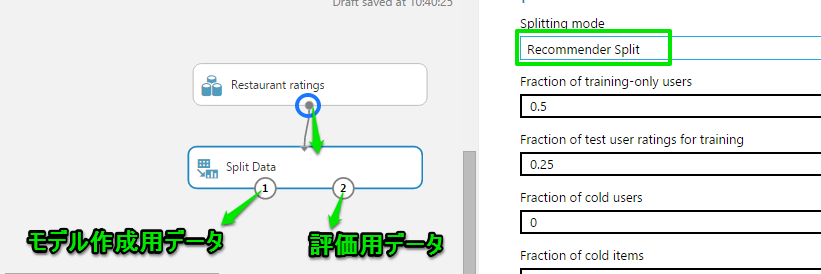
この状態で一度実行してみましょう。
画面下の「RUN」をクリックします。
右上のメッセージが「Queued」から「Finished running」に変わると終了です。
「Split Data」を右クリックして「result」、「Visualize」から内容を確認することが出来ます。
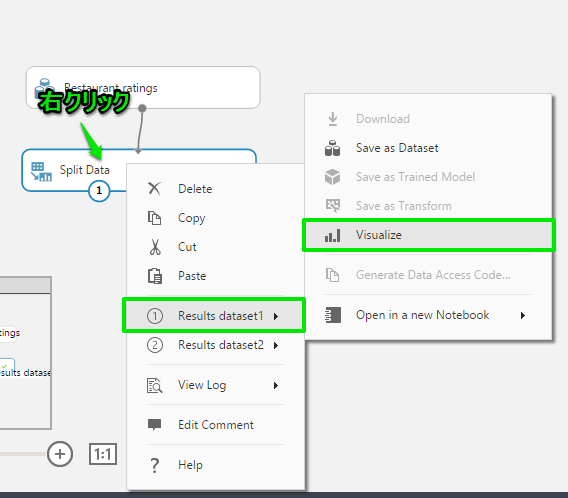
それぞれ確認してみると分割されていることが分かります。
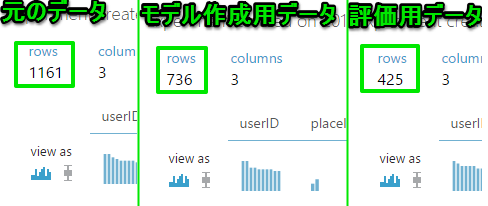
レコメンド用のデータ分割「Recommender Split」の場合他のアルゴリズムで使われるデータ分割とは違いユーザ単位で分割が行われます。
今回はデータの種類、制約と分割について説明しました。
予め必要なものが分かっているとデータも集めやすいのではないでしょうか。
次回はレコメンドモデルの作成を行います。
またお会いしましょう!
