
はじめに
この記事は Azure OpenAI Service と Azure AI Search を使った社内文書チャットボットを設計する前に、押さえておきたい用語と全体像を整理する入門記事です。
実装手順や料金比較ではなく、サービスの役割と RAG 構成の理解に焦点を当てます。
この記事でわかること
- 取り込み時と問い合わせ時を分けた RAG の全体像
- Azure OpenAI Service、Azure AI Search、Microsoft Entra ID の役割分担
- 設計前に押さえたい基本用語
- 認証と文書権限制御の違い
この記事で扱わないこと
- 実装手順の詳細
- 料金・リージョン比較
- chunking 設計や評価設計の詳細
- 権限制御の実装詳細
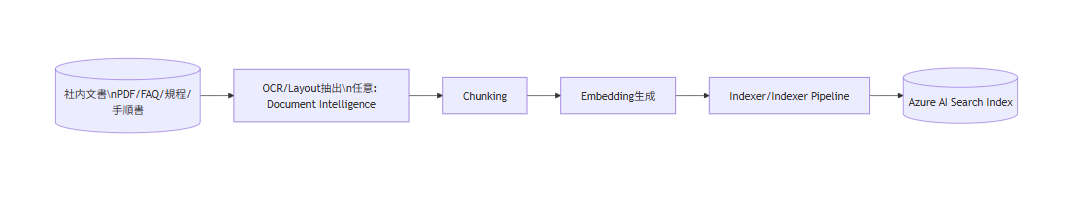
想定アーキテクチャ(取り込みフロー / 問い合わせフロー)
RAG 構成を理解するコツは「取り込み」と「問い合わせ」を分けることです。
Azure AI Search は問い合わせ時に原文書を直接読むのではなく、あらかじめ作られたインデックスを検索します。
取り込みフロー
問い合わせフロー

補足:
- Azure AI Search は問い合わせ時に index を検索します
- 原文書の取り込み・分割・埋め込みは取り込み側の処理です
参考: Azure AI Search ドキュメント(index, indexer, integrated vectorization)
主要サービスの役割
| サービス | 何ができる? | 位置づけ |
|---|---|---|
| Azure OpenAI Service | 文章生成、要約、質問応答、分類、埋め込み生成 | 生成AIの中核。答えを作る頭脳 |
| Azure AI Search | キーワード検索、ベクトル検索、ハイブリッド検索、RAG検索基盤 | 必要な情報を探す検索基盤。資料棚から本を探す司書 |
| Microsoft Entra ID | サインイン、トークン発行、ID管理 | 認証の基盤(誰が使うかを確認) |
| Azure AI Document Intelligence | OCR、レイアウト抽出、帳票項目抽出 | 文書を検索しやすいデータに変換 |
| Azure AI Speech / Translator | 音声認識、音声合成、翻訳 | 音声・多言語対応を担う拡張機能 |
| Microsoft Foundry(旧称: Azure AI Foundry) | AI開発のポータル/管理体験 | モデル評価・実験・運用を整理しやすくする基盤 |
※ 2026-05-08 時点の Microsoft Learn では Microsoft Foundry 表記が中心です。
本記事では検索しやすさのため旧称 Azure AI Foundry も文脈に応じて併記します。
用語整理① Azure/OpenAI の利用単位
| 用語 | 意味 |
|---|---|
| Resource | Azure 上で作成するサービスの管理単位 |
| Deployment | モデルをアプリから呼び出せるようにした配置単位 |
| Endpoint | Resource にひも付く API 呼び出し先 |
| API Key | API アクセス用の資格情報 |
| Microsoft Entra ID 認証 | トークンベース認証。実運用で推奨されることが多い |
Deployment について
Azure OpenAI Service はモデル名を直接指定して使うというより、Deployment 名を指定して呼ぶ形になります。
同じモデルでも用途別に Deployment を分けられます。
例:
- chat-prod
- chat-test
- embedding-v1
用語整理② 生成AI API とパラメータ
| 用語 | 意味 |
|---|---|
| Prompt | モデルに与える入力文・指示文 |
| System message | モデルの振る舞いを定義する前提指示 |
| User message | ユーザー入力 |
| Assistant message | モデルの応答 |
| Token | モデルが文章を扱う単位 |
| Completion | 単一 prompt を入力として生成する方式 |
| Chat completion | 複数メッセージを入力して会話形式で生成する方式 |
| Responses API | チャット補完系とアシスタント系機能を統合的に扱う新しい API |
| Temperature | 出力のランダム性。高いほど多様、低いほど安定 |
| top_p | nucleus sampling の設定。通常は temperature か top_p のどちらか一方を主に調整 |
| Content filter | 不適切な入出力を抑制する仕組み |
参考: Azure OpenAI ドキュメント(Responses API, parameters)
用語整理③ RAG / 検索の基本用語
| 用語 | 意味 |
|---|---|
| RAG | 検索で取得した情報を根拠に生成する構成 |
| Index | 検索用に最適化されたデータ構造 |
| Indexer | データソースから index を更新する仕組み |
| Data source | 取り込み元データ |
| Chunk | 長文を分割した検索単位 |
| Embedding | テキストの意味を数値ベクトル化した表現 |
| Vector search | ベクトル類似度で検索する方式 |
| Hybrid search | キーワード検索とベクトル検索を組み合わせる方式 |
| Retrieval | 質問に関連する情報を取り出す処理 |
| Grounding | 回答を取得情報に結びつけること |
| Security filter | 検索結果を権限条件で絞り込む仕組み |
| Document-level access control | 文書単位で可視制御する考え方 |
参考: Azure AI Search ドキュメント(hybrid search, security filters, document-level access control)
認証と認可を分けて考える
Microsoft Entra ID は主に「誰が使うか」を確認する認証の基盤です。
一方で「その人がどの文書を見てよいか」は別の話です。
見えてよい文書だけを検索結果に含めるには、Azure AI Search 側で security filter や document-level access control を設計する必要があります。
一部の ACL / RBAC 連携機能は preview を含むため、採用時は最新ドキュメントで状態確認が必要です。
1つの具体例(質問1件の流れ)
例: 利用者が「在宅勤務手当の申請期限は?」と質問する場合
- バックエンドが質問を受け取る
- Azure AI Search が index を検索する
- 就業規程の該当チャンクを上位候補として取得する
- Azure OpenAI Service が取得チャンクを根拠に回答文を生成する
- 回答と参照元文書名を返す
この流れにより、モデルの一般知識だけではなく社内文書に基づく回答を返しやすくなります。
RAG が必要な理由
- Azure OpenAI Service は自然な文章を作るのが得意ですが、社内の最新ルールや独自マニュアルの内容をそのまま持っているわけではありません
- そのため生成AIに単独で回答させるのではなく社内文書を検索して、その結果をもとに回答を作る RAG 構成がよく使われます
- RAG を使うことでAIが一般的な知識だけで答えるのではなく、実際の社内情報に基づいた回答を返しやすくなります
- 特に規程集・申請手順書・FAQ・マニュアルのように「正しい内容が決まっている情報」を扱う場合はこの構成と相性が良いです
検索から回答までの流れ
利用者がチャット画面に質問を入力すると、まずアプリケーションがその内容を受け取ります。次に Azure AI Search を使って関連する社内文書を検索します。ここでは質問文と意味が近い内容や、回答に必要そうな記述を探します。検索で見つかった情報はそのまま表示するだけではなく Azure OpenAI Service に渡します。Azure OpenAI Service はその検索結果を踏まえて利用者にわかりやすい自然文の回答を生成します。つまりこの構成では「検索が先、生成が後」という流れになります。
AI がゼロから自由に答えるのではなく、根拠となる文書をもとに回答を作ることで実務で使いやすい仕組みにできます。
利用者・運用者のメリット
利用者は検索キーワードを考えなくても自然文で質問できるため、必要な情報にたどり着きやすくなります。
たとえば「この申請はどこから行うのか」「この制度の対象条件は何か」「この手続きに必要な書類は何か」といった内容を、そのまま会話のように入力するだけでよくなります。
運用側はよくある問い合わせをAIが一次対応することで、担当者の負担を減らしやすくなります。
参照元の文書を表示できるようにしておけば、なぜその回答になったのかを確認しやすくなり利用者も安心して使いやすくなります。
文書の内容が更新された場合でも検索対象の文書を差し替えることで、回答の元になる情報を更新しやすいという利点があります。
このように RAG 構成は「使いやすさ」と「運用しやすさ」の両方を意識しやすい仕組みです。
設計時の注意点(認証・認可・根拠表示・運用)
- 生成AIの回答は自然でも常に正しいとは限らないため、人の確認プロセスを残す
- 認証(Entra ID)と認可(文書可視制御)を分離して設計する
- 参照元文書名や根拠チャンクを表示して説明可能性を確保する
- 取り込み範囲や chunking 粒度を調整して回答品質を安定させる
- 認証方式は API Key より Entra ID / Managed Identity を優先的に検討する
まとめ
- RAG は「取り込み」と「問い合わせ」を分けて考えると理解しやすい
- 問い合わせ時の Azure AI Search は原文書ではなく index を検索する
- Microsoft Entra ID は認証の基盤であり、文書可視制御は別設計が必要
- 用語をレイヤーごとに整理すると AI-102 学習や実務設計が進めやすい
参考文献
※ 本記事の製品名・API名・機能状態は 2026-05-08 時点の Microsoft Learn を基準に記載しています。
- Microsoft Learn: Azure OpenAI Service documentation
- Microsoft Learn: Azure OpenAI concepts
- Microsoft Learn: Azure AI Search documentation
- Microsoft Learn: Vector search in Azure AI Search
- Microsoft Learn: Hybrid search in Azure AI Search
- Microsoft Learn: Integrated vectorization
- Microsoft Learn: Security filters and access control in Azure AI Search
- Microsoft Learn: Microsoft Entra documentation
- Microsoft Learn: Azure AI Document Intelligence documentation
- Microsoft Learn: Azure Monitor / Application Insights documentation
