はじめに
2020年8月26日に Spark + AI Summit 2020 のダイジェストセミナーが実施されました。
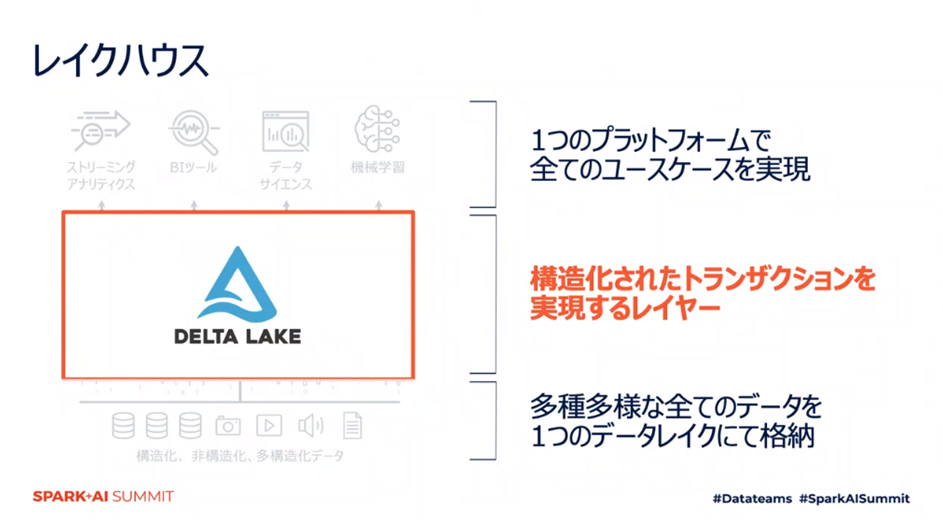
この記事ではデータウェアハウスとデータレイクの考え方を統合したレイクハウスという概念を実現するための Delta Lake についてご紹介します。
Delta Lake とは
構造/非構造化データを蓄積するデータレイク上に構成するストレージレイヤーです。

Delta Lakeによって、構造化されたトランズアクションを実現するストレージレイヤーを構成することができ、レイクハウスの概念を実現することができます。
データレイクにおける9つの課題と解決策
Delta Lakeはデータサイエンス・機械学習にデータレイクを活用するうえで生じる9つの課題に対応するために開発されました。
- データを追加することが難しい
- 既存データの変更が難しい
- ジョブが途中でエラーとなった時の対応が難しい
- リアルタイムデータの取り扱いが難しい
- データの履歴をバージョンで保有するとコスト的に厳しい
- 大量のメタデータを扱うことが難しい
- “沢山のファイル”を適切に扱うことが難しい
- 最高の処理性能を享受することが難しい
- データ品質を担保することが難しい
ACID トランズアクション
Delta Lakeではデルタログという変更履歴データによってバージョンが管理されます。これにより全オペレーションをトランズアクションとして実行可能なものとなり、履歴データを参照することで過去のトランズアクションをレビューすることも可能となります。(課題1~5の解決策)
Spark の特性
sparkは大量データ処理用のフレームワークとして開発されました。Delta Lakeではparquet形式で格納されており、Spark で処理するデータはその一部がキャッシュ化され、高速なアクセスが可能となるよう最適化されています。また、データとメタデータが常に一緒に格納されているため、カタログとデータを同期する必要がないことも大量データの取り扱いを容易にしています。(課題6の解決策)
インデックス
- パーティショニング
典型的クエリのためのレイアウト - データスキッピング
数値統計に基づいて整頓されたファイル群 - Zオーダー
複数カラムの最適化レイアウト
というレイアウトが自動で最適化されるため、高速なアクセスを可能とします。(課題7,8の解決策)
スキーマ妥当性の検証
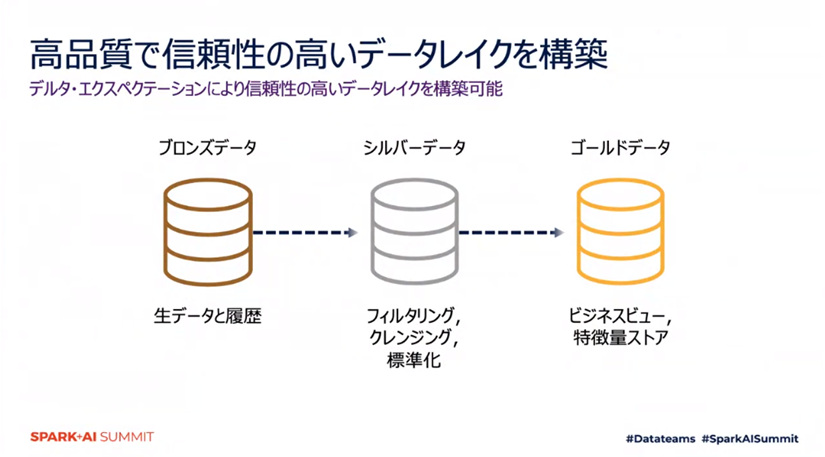
SQLによってデータ品質保証のためのプロファイルを定義し、すべてのテーブルはすべてのエクスペクテーションを満たすデルタ・エクスペクテーションによってデータの品質を担保しています。(課題9の解決策)
Delta Lakeの活用方法
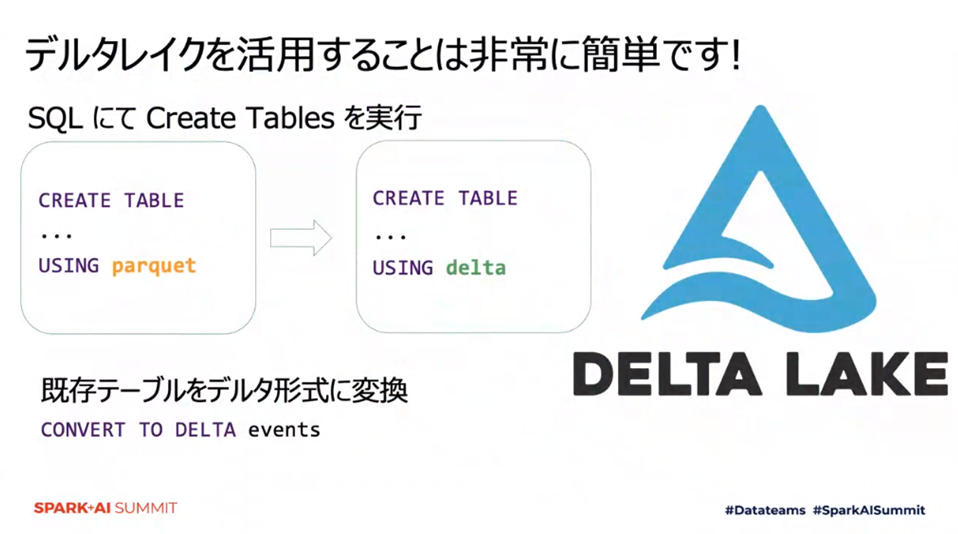
フォーマットを “parquet” から “delta” にすることでデルタ形式のテーブルを扱うことができます。既存のテーブルを変換して使うことも可能です。また、Delta Lake ビッグデータ・ストレージをオープンな形式で標準化しているため、多種多様なツールからのアクセスが可能となっています。
まとめ
今回はデータレイクとデータウェアハウスのいいとこどりであるレイクハウスを実現するためのDelta Lakeについてご紹介しました。
次回はDelta Lakeを高速に扱うためのクエリエンジンであるデルタエンジンについてご紹介します。
