
はじめに
2026年6月15日~18日サンフランシスコ・バーチャルにて開催されるDatabricks社主催の年間最大規模のカンファレンスイベント、「Databricks Data+AI Summit 2026」(DAIS)が開催中です。
本記事はDAIS2026 AIエージェントは“作る”より“回す”が難しい|開発から運用までの全体像 で発表された、AIエージェントの開発から運用までをどう統合的に管理するか を扱ったセッションのレポートになります。
本記事はDatabricks公式発表を元にした非公式の日本語要約であり、すべての著作権・知的財産権はDatabricksに帰属します。

忙しい方用
- AIエージェント導入で本当に問われるのは、制御できるか・動くか・いくらかかるか の3点
- 現場ではすでに、誰も全体像を把握できない agent sprawl(エージェントの乱立) が起き始めている
- モデル選定以上に重要なのは、データ理解・権限設計・評価・監視・改善の運用ループ を回せる基盤づくり
背景
今年のDAISで強く感じたのは、生成AIの議論が「どう作るか」から「どう運用するか」へ移っている ことです。
2024〜2025年は、LLMやRAG、チャットボットのPoCやプロトタイプ作成が中心でした。
一方で2026年は、単にデモを作るだけでは不十分で、本番で安全に回るか、継続的に改善できるか、コストを抑えられるか が主戦場になっています。
このセッションは、その変化をかなり率直に示していました。
図1: PoCが本番に進まない理由
- まだ多くの企業が GenAI を本番投入することに十分な自信を持てていない
- 課題として強調されていたのは Accuracy / Control / ROI

ここで印象的だったのは、本番導入の壁はモデル性能だけではない と明確に示されていた点です。
企業が実際に詰まりやすいのは、むしろ次のような論点です。
- どこまでアクセスさせるか
- 誰の権限で動くか
- 間違えたときにどう気づくか
- どれくらいコストがかかるか
つまり、AIエージェントの本質は「賢さ」だけでなく、運用に耐えられるかどうか にあります。
セッションで特に重要だった3つのポイント
1. エージェント導入の本質は「CFOテスト」
登壇者は、AIエージェントを本番導入する際に、意思決定者が最終的に確認するポイントを 「CFOテスト」 と表現していました。
確認されるのは次の3つです。
- 制御できるか
- 動くか
- いくらかかるか
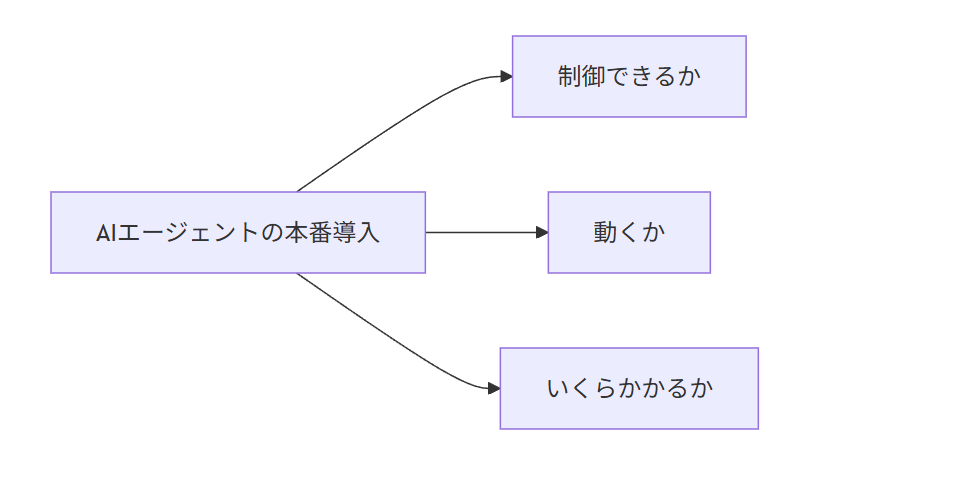
制御できるか
- 何にアクセスできるのか
- 何を実行できるのか
- 権限は適切か
- 最悪どんな事故が起きるのか
動くか
- 実際に期待通り動作するか
- 間違えたときにどう振る舞うか
- 評価と改善の仕組みがあるか
いくらかかるか
- 推論コストはどのくらいか
- 利用増加に耐えられるか
- 無駄な呼び出しを抑えられるか
特にエージェントは、単なるチャットボットよりも 「何をしてしまうか」 の影響が大きいため、制御・評価・コスト管理の重要度がかなり高いと感じました。
2. すでに起きているのは「agent sprawl」
もう一つ印象的だったのが、agent sprawl という表現です。
これは、組織内でエージェントがあちこちに作られ、誰も全体像を把握できなくなる状態 を指します。
たとえば、こんなことが起きます。
- 営業部門が営業支援エージェントを作る
- 人事部門がHRチャットボットを作る
- 分析チームが別の業務エージェントを作る
それ自体は悪いことではありません。
問題は、増えたあとに管理できなくなること です。
- どのエージェントが本番で動いているか分からない
- 何にアクセスしているか追えない
- 評価基準がバラバラ
- コストも見えない
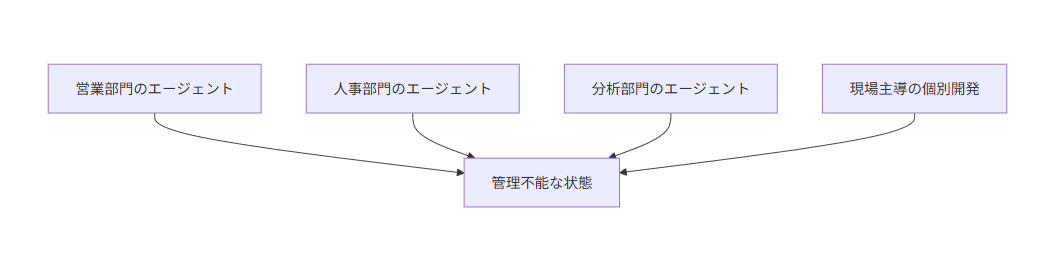
つまり、エージェント開発は簡単になったが、統制は難しくなった ということです。
3. 重要なのはモデルではなく「プラットフォーム」
このセッションでは、エージェントを支える基盤として、次の3要素が強調されていました。
- データを理解するエージェント
- フルスタック開発基盤
- 統合AIガバナンス
この3つがそろって、ようやく企業で使えるエージェント運用になります。
1) データを理解するエージェント
単にLLMに質問を投げるだけでは不十分で、次のようなことが必要になります。
- 企業固有の用語や略語を理解する
- メトリクス定義を追跡できる
- オントロジーやセマンティクスをたどれる
- 構造化データと非構造化データを横断できる
登壇者は、今後のエージェントは「検索問題」に近くなるとも述べていました。
大量の企業データから、次の応答に必要な少量の文脈を正しく見つけること が本質になっていく、という考え方です。
2) フルスタック開発基盤
モデル、フレームワーク、実行環境、トレース、評価、改善サイクル。
これらを一気通貫で扱えることが重要になります。
3) 統合AIガバナンス
このセッションで特に強調されていたのは、データ・モデル・ツール・アプリ・権限・監視を分断せずに管理すること でした。
キーワードとして挙がっていたのは以下です。
- Unity Catalog
- Genie Spaces
- Agent Bricks
- MCP Server
- AI Gateway
要するに、重要なのは「どのモデルを使うか」だけではなく、
誰が、どの権限で、何にアクセスし、どう評価・監視されるか を一体で設計できるか、ということです。
今年の特徴
今年のDAISで特に印象的だったのは、エージェントの個別機能より、運用全体の設計に焦点が移っていたこと です。
セッション全体としては、次の流れが一貫していました。
- まずデータを理解する
- 次に安全に開発する
- 最後に評価・監視・改善する
これは単なる「生成AIの紹介」ではなく、企業システムとしてAIを成立させるための設計思想 だと感じました。
今年の特徴として見えた点
- エージェント数の増加を前提にしている
- 評価が“実験”ではなく“運用機能”として扱われている
- MCPや外部システム連携まで含めて統制する
- AI Gatewayで利用状況・コスト・品質を可視化する
- 人手レビューを含めた改善ループが前提になっている
図2. エージェント評価の考え方
- Trace / judges / human feedback を通じて評価を回す
- 根本原因を見つけて改善する構成

このスライドで印象的だったのは、評価は単発ではなく、原因特定と改善に繋がるべき という点です。
単に点数を付けるのではなく、どこが壊れているかを見つけ、どう直すかまで見えることが重要だと示されていました。
デモで見えた実装イメージ
後半では、架空のタピオカチェーン企業 BobaBricks を題材にしたデモが行われました。
登場した主な要素は次の通りです。
- Supervisor Agent
- Ops Bot
- Sales Analyst
- Genie Spaces
- Knowledge Assistant
- Agent Bricks
- MCP Server
- AI Gateway
用途としては、レシピ管理、在庫管理、売上分析、問い合わせ対応などです。
図3. BobaBricksデモの全体像
- 1つのアプリから複数のAI機能を束ねる
- データ、エージェント、評価、ガバナンスがつながっている

デモから見えた構成のポイント
Genie Spaces
構造化データに対する自然言語での質問応答を担当
Knowledge Assistant
レシピや安全手順など、非構造化情報を扱う
Agent Bricks
用途別にエージェントを作成・構成する
MCP Server
外部システムや追加情報ソースと連携する
AI Gateway
利用状況、コスト、品質、アクセスを可視化する
このデモを一言で整理すると、
Supervisor Agent が入口となり、構造化データは Genie、文書ベース情報は Knowledge Assistant、外部連携は MCP、全体の統制と観測は AI Gateway が担う という構成でした。
さらに、評価ランの画面 では、MLflow でテストデータを流し込み、出力を自動採点し、比較や原因特定をしやすくする仕組みが紹介されていました。
図4. MLflowによる評価ラン
- テストデータを投入
- アプリを実行
- 自動採点
- 比較・改善へつなげる

この画面は、「評価が開発者の感覚ではなく、再現可能な運用プロセスになっている」 ことをよく表していました。
セキュリティとガードレールの考え方
セッションでは、Fine-grained safety and security controls も重要なテーマでした。
ポイントは、単にLLMに対してポリシーをかけるだけでは不十分で、
エージェント、MCP、各種接続先まで含めて制御する必要がある ということです。
たとえば、PIIを外部に送ってはいけない場合でも、制御ポイントは1つではありません。
- LLMとハーネスの間
- ハーネスとMCPの間
- エージェントの出力経路
- 外部システムへの接続部分
図5. 細粒度のセキュリティ制御
- LLMだけではなく、エージェントやMCPにもポリシーを適用
- 入口と出口の両方を制御する

この考え方は、企業導入ではかなり重要です。
なぜなら、事故は「モデルが暴走したから」ではなく、接続先や権限制御が穴になって起きる ことが多いからです。
昨年との比較
ここからは、セッション内容を踏まえた筆者の整理です。
昨年のDAISでも、GenAIの本番化についてはかなり語られていました。
ただ、今年と比べると焦点が少し変わっています。
昨年の中心テーマ
- Accuracy
- Control
- ROI
つまり、PoCをどう本番に持っていくか が中心でした。
今年の中心テーマ
- 何個エージェントがあるのか把握できるか
- 誰が何を触れるのか制御できるか
- 評価と監視を継続できるか
- 全体を統合的に管理できるか
つまり、「1つのエージェントをどう本番化するか」から、
「エージェント群をどう運用するか」へシフトしているように見えます。
これは、企業利用が進んだことの裏返しでもあります。
1個のデモを動かすだけなら比較的簡単でも、複数部門で同時に使い始めると、権限・品質・コストの管理が一気に難しくなるからです。
他社・一般的なアプローチとの比較
ここは「他社を批判する」という意味ではなく、一般的なAI導入アプローチとの差分 として整理すると分かりやすいです。
一般的なアプローチ
- モデルを選ぶ
- プロンプトを書く
- RAGをつなぐ
- まずはデモを作る
これはもちろん重要です。
ただし、このやり方だけだと、次の問いに答えづらくなります。
- そのエージェントは何にアクセスしたのか
- 失敗したら誰が気づくのか
- 誰の権限で実行されるのか
- コストは可視化されているか
- 変更したときに比較できるか
このセッションで示されていた考え方
- データからガバナンスまで一体化する
- 評価を開発後の確認ではなく、運用プロセスに組み込む
- エージェントを単独ではなく「群」として管理する
- ユーザーの代理実行まで含めて統制する
つまり、「どのモデルが良いか」よりも、
「どの運用基盤で回すか」が主題になっていました。
比較表で整理すると
| 観点 | 一般的なアプローチ | このセッションの考え方 |
|---|---|---|
| 入口 | モデル選定 | データ・権限・運用設計 |
| 開発 | PoC中心 | 本番運用前提 |
| 評価 | 単発の精度確認 | Trace + Judge + Human feedback |
| 運用 | 個別管理 | 統合ガバナンス |
| 監視 | 後から追加 | 最初から組み込む |
運用の最後に効いてくるのは「可視化」
AIエージェントは、導入して終わりではありません。
むしろ、導入後に何が起きているかを見える化できるか が勝負です。
AI Gatewayのダッシュボードでは、次のような観点を確認できる構成でした。
- Overview
- Performance
- Usage
- Coding Agents
- External MCP Server
- Cost Analysis
- README
図6. AI Gateway Usage Analytics
- 利用状況
- パフォーマンス
- コスト
- 外部接続先
を一画面で可視化する

このタイプの画面が重要なのは、単なるメトリクス表示ではなく、
「運用しているAI資産の棚卸し」 になるからです。
- どの機能が使われているか
- どこで負荷が高いか
- どこでコストが膨らんでいるか
- どのエージェントが増えているか
これが見えると、初めて改善が回せるようになります。
実務への示唆
このセッションを、実務の観点でどう持ち帰るかを整理します。
1. まず「何個あるか分からない」を解消する
最初にやるべきは、エージェントの棚卸しです。
- どの部署が作っているか
- 何に接続しているか
- どの環境で動いているか
- 誰がオーナーか
- 本番か検証か
- 廃止基準はあるか
ここが不明だと、評価も統制も始まりません。
2. PoCではなく、評価ループを作る
「使えるかどうか」ではなく、どう改善するか まで設計します。
- トレースを取る
- judgeで評価する
- 人手レビューを挟む
- データやルールを直す
- 再評価する
重要なのは、評価を開発の最後にやるものではなく、運用の中で回すこと です。
3. 権限と代理実行を最初から設計する
ユーザーの代理として動くエージェントは、利用者ごとに違う結果を返す 必要があります。
そのため、次を最初から決めておく必要があります。
- 誰の権限で実行するのか
- app権限か user権限か
- 外部ツール接続時の認可はどうするか
- 監査ログをどう残すか
これは後付けだとかなり難しくなります。
4. コストは最後ではなく最初に見る
エージェントは便利になるほど呼び出しが増えます。
そのため、コストの可視化は「後でやる」ではなく、導入時点から必要です。
- どのエージェントが高いのか
- どの機能が無駄に呼ばれているのか
- 外部接続で余計なトークンを消費していないか
- 利用増に耐える構成か
5. 持ち帰り用チェックリスト
- エージェント台帳がある
- オーナーが明確
- 接続先が可視化されている
- 実行主体が整理されている
- trace / judge / human feedback の仕組みがある
- usage / cost / alert を見られる
- 本番・検証・廃止の区別がある
まとめ
このセッションを通じて、AIエージェントの本番運用で大事なのは、派手なデモそのものではなく、次の3点だと整理できました。
- 制御できること
- ちゃんと動くこと
- 適切なコストで継続できること
特に企業利用では、エージェントの数が増えるほど、評価・監視・権限制御・ガバナンス の重要性が増します。
「作るのは簡単、回すのが難しい」というメッセージは、かなり現場感のある内容でした。
そして今年の大きな変化は、AIエージェントを単体機能ではなく、運用される“資産”として扱い始めていること です。
この視点は、来年以降さらに重要になっていくはずです。
図7: AI資産全体に対する統合ガバナンス
- エージェント運用の全体像を再確認する締めのスライド
- 「作る」から「回す」への発想転換を象徴する箇所

お知らせ
ナレッジコミュニケーションでは、Databricks Data + AI Summit 2026 開催に伴い、日本語でのウェビナーや現地レポートを公開しております!
DAIS2026 Recap イベント
現地参加が難しかった方や、主要トピックスを短時間で振り返りたい方向けに、Recapイベントを開催します。
セッションの要点整理や、日本企業での実装観点も交えてご紹介予定です。
▼ 開催概要・お申し込みはこちら

ナレッジコミュニケーション DAIS2026 特設サイト
DAIS2026で発表された注目テーマ、関連セッション、実務での活用ポイントを継続的に発信する特設ページです。
イベント情報の整理・社内共有にもご活用いただけます。
Databricks 導入支援サービスサイト
Databricksの導入検討から活用定着まで、課題に応じた支援メニューをご紹介しています。
「何から着手すべきか相談したい」という段階でも、お気軽にご覧ください。
 databricks.kc-cloud.jp
databricks.kc-cloud.jp