
はじめに
2026年6月15日~18日サンフランシスコ・バーチャルにて開催されるDatabricks社主催の年間最大規模のカンファレンスイベント、「Databricks Data+AI Summit 2026」(DAIS)が開催中です。
本記事はDAIS2026 An Intro to Building and Scaling Agentic Apps で発表された、独自の解釈・図解・考察を加えた再構成のものになります。
本記事はDatabricks公式発表を元にした非公式の記事であり、すべての著作権・知的財産権はDatabricksに帰属します。


忙しい方用
- エージェント開発の現状だけ把握したい → エージェント開発の”今”
- 本番化で何が問題になるか知りたい → PoCと本番の間にある gap
- Databricksの基本を手早く知りたい → Databricksとは何か
- アーキテクチャの全体像を把握したい → Reference Architecture で設計を整理する
- Genieとカスタムエージェント、どちらを使うか知りたい → Genieとカスタムエージェントの使い分け
- エージェントがどんな失敗をするか知りたい → 失敗する3つの典型パターン
- 品質を継続的に担保する方法を知りたい → Agent Opsループ
- セッションで印象に残った点だけ知りたい → このセッションで印象に残った点
- まず何から手をつければいいか知りたい → 自分で試す導線
0. はじめに
この記事について
Tim & Robert(Databricks Field Engineering)のセッション 「An Intro to Building and Scaling Agentic Apps」 を、本番化の観点で並べ替えたメモです。Databricks 固有の話と、他環境でも使える話は、できるだけ分けて書いています。


この記事で扱うこと
- PoC で動いたエージェントを、誰かに渡すとき何が足りないか(gap)
- Reference Architecture(5層)の各層が何を担うか
- Agent Ops ループを TechMart デモでどう回したか
想定読者
この記事は、おおよそ次のような方を想定しています。
- LangGraphやLangChainなどで、簡単なエージェントは動かしたことがある
- でも「これを本番に出すとなると何が必要なんだ…?」と漠然とした不安がある
- Databricksはこれから使い始めようとしている、もしくは興味がある
- ツールの使い方そのものより、“ちゃんと運用できる設計”の考え方を知りたい
💡 完全なエージェント未経験者向けではありませんが、「最近エージェントに触り始めた」くらいの方なら十分読み進められるよう、要所で補足を入れています。
1. エージェント開発の”今”
なぜ急に「作れる」ようになったのか
ここ1〜2年で、エージェント開発のハードルは劇的に下がりました。![]()
少し前まで、「LLMに外部ツールを使わせて、複数ステップの処理を自律的にこなさせる」のは、それなりに腰を据えて取り組む必要のあるテーマでした。ところが今は、
- モデル自体の進化(ツール呼び出しや推論が安定してきた)



- フレームワークの整備(LangGraphなどで、状態管理やツール連携が宣言的に書ける)
- エコシステムの成熟(MCPのような”ツールを繋ぐ標準”が広がりつつある)
これらが重なり、「とりあえず動くエージェント」なら数時間で作れてしまうのが当たり前になってきました。
実際、このセッションでも「エージェントを構築すること自体は、もはや難しい部分ではない」という前提に立って話が進んでいきます。


でも「作れる」と「使える」は、まったく別の話
ここで多くの人がぶつかるのが、次のギャップです。
デモでは動く。でも、お客さんや社内の他部署に渡せるかというと…手が止まる。
たとえば、自分用のPoC(概念実証)として作ったエージェントなら、こんなことは気にしなくても済みます。
- たまに変な回答をしても、自分が気づいて直せばいい
- 誰がどんな質問をしたか、ログを残していなくても困らない
- アクセスできるデータの権限管理なんて考えなくていい
- 同時に1人しか使わないので、スケールも関係ない
ところが、これを 本番で自分以外の誰かに使ってもらう 瞬間、話が一変します。
- 間違った回答が、そのままお客さんへの誤案内になる
- 「なぜそう答えたのか」を後から説明・監査できないといけない
- ユーザーごとに触れていいデータ/いけないデータが分かれる
- 何百人が同時に使っても落ちない・遅くならない必要がある
エージェント開発の難しさは、もはや「どう作るか」より「どう信頼できる状態にして人に渡すか」に移ってきています。![]()
この記事のスタンス
セッションでは、この「作れる」と「使える」の間にある溝を gap(the gap)と呼んでいます。上のスライドでも “THE GAP” として提示されています。
次のセクションでは、この gap を6つの要件に分解します。
2. PoCと本番の間にある gap
セッションのデモから見えてくる「本番化の難しさ」
このセッションでは冒頭、家電量販店のカスタマーサポートエージェントのデモが登場します。
「在庫確認」「保証ポリシーの案内」「返品対応」といった業務を自動化するエージェントで、一見するとしっかり動いているように見えます。ところが、このデモで意図的に3つの失敗が演じられます。
失敗① 廃番商品を「在庫あり」と答える
ユーザーが特定の商品を問い合わせると、エージェントは「在庫があります」と回答します。しかし実際にはその商品はすでに廃番になっています。
エージェントが参照していたデータが古く、廃番ステータスの更新が反映されていなかったのです。
失敗② メーカー保証と自社保証を混同する
「この商品の保証期間はどのくらいですか?」という質問に対して、エージェントはメーカー保証(1年)と自社の延長保証(2年)を混同して回答しました。
どちらも「保証」に関する情報として取得してしまい、どちらの文脈で答えるべきかを正しく判断できなかったことが原因です。
失敗③ 長年顧客だからとポリシー違反の対応をする
「10年来のお客様なので、返品期限を過ぎていますが何とかなりませんか」という問いに対して、エージェントは「特別に対応します」と答えてしまいます。
これは会社のポリシーに反する回答です。エージェントがユーザーの感情的な文脈を汲み取りすぎた結果、ルールの逸脱が起きました。
3つの失敗が示すもの
これらの失敗は、技術的なバグではありません。「それなりに動く」エージェントが本番で起こしやすい、構造的な問題です。
| 失敗 | 本質的な原因 |
|---|---|
| 廃番商品を在庫ありと回答 | データの鮮度・正確性の担保がない |
| 保証情報の混同 | どのコンテキストで答えるかの制御不足 |
| ポリシー違反の対応 | エージェントの行動に対するガードレールの欠如 |
そして重要なのは、自分だけが使うPoCならこれらはすべて許容できるという点です。自分が気づいて直せばいい。でも、顧客に触れさせた瞬間にこれらはビジネスリスクになります。
セッションの登壇者はここで、こう言っています。
「エージェントを構築することは難しくない。難しいのは、エージェントを信頼できる状態にして、人に渡すことだ。」
本番化に必要な6つの要件
このデモを踏まえて、セッションでは gap を埋めるために必要な要件が整理されます。以下の6つです。

① 権限管理(Authorization)
エージェントはユーザーに代わってデータにアクセスします。このとき、ユーザーが本来アクセスできないデータに触れてしまわないか、が問題になります。
たとえば、社内エージェントであれば「営業部門のAさんは顧客データにアクセスできるが、経理データは見られない」というポリシーが存在するはずです。エージェントが複数ユーザーに対応するとき、このアクセス制御をエージェント側でも正しく引き継ぐ必要があります。
② 会話履歴・記憶(Memory / History)
ユーザーが複数回にわたって会話するとき、「前回何を話したか」を正しく引き継げるかが重要になります。
単一セッションで完結するPoCと違い、本番では会話が日をまたいだり、複数のチャンネルから来たりすることがあります。履歴をどこに、どんな形で保持するかを設計に組み込む必要があります。
③ 監査(Audit)
「なぜそう答えたのか」を後から説明できる仕組みが必要です。
顧客対応エージェントであれば、クレームが来たときにどのデータを参照して、どういうロジックでその回答を導いたかを追跡できることが求められます。これは法的・コンプライアンス上の要件になることもあります。
④ 可観測性(Observability)
本番で動かし続けるには、エージェントの挙動をリアルタイムで把握できる状態にしておく必要があります。
「どのツールが何回呼ばれたか」「どこでレイテンシが発生しているか」「エラーはどんなパターンで起きているか」といった情報を可視化する仕組みなしには、問題が起きても原因を追えません。
⑤ 信頼性・品質(Reliability / Quality)
エージェントの回答が一定水準以上の品質を保ち続けているかを担保する仕組みです。
LLMは非決定的です。同じ質問をしても、毎回まったく同じ回答が返るとは限りません。モデルのバージョンが変わるだけで挙動が変わることもあります。デモで見せた3つの失敗を継続的に検出・修正し続けるための評価の仕組みが不可欠です。
⑥ スケール(Scale)
自分1人のPoCと、数百人が同時に使う本番では、インフラの要件がまったく異なります。
レイテンシ、コスト、同時接続数、LLM APIのレート制限への対応——これらを考慮した設計にしておかないと、使われれば使われるほど壊れていく、という状況になります。
「でも、全部最初から完璧にできるの?」という問いへ
ここまで読んで、「要件が多すぎて逆に何から手をつければいいかわからない」と感じた方もいるかもしれません。
セッションで語られていたのは、「全部を最初から完璧に揃えてからリリースしろ」ということではありません。むしろ逆で、
「これらの要件に対応できる設計の枠組みを最初から持っておくことが重要だ」
というのがメッセージです。
その「枠組み」として提示されるのが、次のセクションで説明する Reference Architecture と Agent Opsループ です。
3. Databricksとは何か(ミニ解説)
「データ基盤の会社」という印象は、半分 正解
正解
Databricksという名前を聞いたことがある方の多くは、「Sparkを使うデータ処理の基盤」「BIやデータエンジニアリングのプラットフォーム」というイメージを持っているかもしれません。それ自体は間違いではないのですが、今のDatabricksはそこから大きく進化しています。
現在のDatabricksは、「データとAIを同じ場所で扱える統合基盤」として位置づけられています。
具体的には、
- データの収集・加工・保存(データエンジニアリング)
- 機械学習モデルの開発・管理・デプロイ(MLOps)
- そして今回のテーマであるAIエージェントの構築・運用(Agent Ops)
これらをバラバラのツールを繋ぎ合わせるのではなく、一つの統合された環境で完結させる、というのがDatabricksのコアコンセプトです。
Lakehouseという考え方
Databricksを語るうえで外せないキーワードが 「Lakehouse」 です。
従来、データを扱う仕組みには大きく2種類がありました。
- Data Warehouse:構造化されたデータを高速に分析するためのもの。精度・速度は高いが、柔軟性に乏しい
- Data Lake:あらゆる形式の生データを安く大量に保存できるもの。柔軟だが、そのままでは分析に使いにくい
Lakehouseはこの2つを統合した概念で、「生データを大量に保持しながら、そのまま高速な分析・AI学習にも使える」というものです。
エージェント開発との関係で言うと、Lakehouseは FOUNDATION 層——エージェントが参照する gold tables や分析データの保管場所です。会話メモリや進行中タスクは STATE 層(Lakebase) が担い、Lakehouse から synced tables で同期されます。
このセッションでも、Lakehouse は Reference Architecture の最下層(FOUNDATION)に位置づけられています。
本記事に登場するDatabricksのコンポーネント
以降の説明で出てくるDatabricks固有の概念を、ここで簡単に整理しておきます。読み進めながら「これ何だっけ」となったときに戻ってきてください。
| コンポーネント | 一言で言うと |
|---|---|
| Unity Catalog | データ・AIアセットの権限管理・ガバナンス基盤。「誰が何にアクセスできるか」を一元管理する |
| MLflow | 機械学習・AIの実験管理、モデルのバージョン管理、デプロイを担うOSSツール。Databricksに統合されている |
| Mosaic AI / Agent Bricks | BRAIN 層。LangGraph + LLM + MCP Tools でエージェントの推論・制御を担う |
| Databricks Apps | SURFACE 層。エージェントを本番アプリとしてホスティング・公開する仕組み |
| Lakebase | マネージド Postgres。会話メモリ・セッション状態を保持する STATE 層 |
| Genie | 自然言語でデータを問い合わせられるノーコード型エージェント機能(text-to-SQL) |
💡 これらを今すぐ完全に理解する必要はありません。「どんな役割のコンポーネントがあるか」をぼんやり掴んでおくだけで、次以降のセクションがぐっと読みやすくなります。
なぜDatabricksがエージェントの話をするのか
「データ基盤の会社がなぜエージェントを?」と思う方もいるかもしれません。
セッションの説明どおり、エージェントが本番で動くためには、データとの深い統合が不可欠だからです。
エージェントは必ずどこかのデータを参照し、その結果を記録し、品質を評価するために過去のやり取りを使います。この「データを扱う部分」をアドホックに繋ぎ合わせていくと、前のセクションで挙げた gap にそのままぶつかります。
データ基盤とAI基盤が同じ場所にある、というのはエージェント開発においては思っている以上に大きなアドバンテージなのです。このセッション自体、そのことを実証するデモとして設計されています。


4. Reference Architectureで設計を整理する
なぜアーキテクチャの”型”が必要なのか
エージェントを本番化しようとしたとき、多くの人がまず直面するのが「どこに何を置くべきか」という設計の迷いです。
- ツールの定義はどこに書く?
- 会話履歴はどこに保存する?
- ユーザーへの公開はどうやってやる?
- 評価のデータはどこで管理する?
これらをその場その場で決めていくと、後から「権限管理どうしよう」「ログが散らばっている」「スケールしない」という問題が出てきます。前のセクションで説明した gap は、多くの場合設計の型がないまま作り始めたことに起因しています。
このセッションで提示されているのが、スライド 11/25 “The whole stack in one picture” と呼ばれる Reference Architecture です。USER → SURFACE → BRAIN → STATE → FOUNDATION の 5層 に分け、Unity AI Gateway と MLflow が全層を横断する構成になっています。
Tim 登壇パート前半では同じ思想を The Trinity(Agent Bricks + Databricks Apps + Lakebase)という3要素で概説していますが、参照アーキテクチャ図の方が 実装に近い粒度 です。
Reference Architecture の全体像

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
┌─────────────────────────────────────────┐ │ USER │ │ Chat UI · Slack · Web · Genie surface │ └────────────────────┬────────────────────┘ ↓ ┌───────────────────────────────────────────────────────────────┐ │ SURFACE │ │ Databricks App — OBO auth, observability, resource bindings │ └────────────────────┬──────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ BRAIN │ │ LangGraph + LLM + MCP Tools │ │ (UC Functions, AI Search, Genie) │ └────────────────────┬────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────┐ │ STATE │ │ Lakebase — conversation memory, prefs, in-flight tasks │ └────────────────────┬────────────────────────────────────┘ ↓ ┌───────────────────────────────────────────────────────────┐ │ FOUNDATION │ │ Lakehouse — gold tables, analytics, synced into Lakebase │ └───────────────────────────────────────────────────────────┘ ═══ UNITY AI GATEWAY · identity + governance + model routing ═══ MLFLOW · trace + evaluate |
上から USER に近い層、下に向かって FOUNDATION(データ基盤)という構造です。
重要なのは、各層が独立した役割を持ちながら、明確なインターフェースで繋がっているという点です。たとえば「公開チャネルを Slack に変える」のは USER 層、「ホスティング設定を変える」のは SURFACE 層——と変更箇所を切り分けられます。
では下層から順に見ていきます。
FOUNDATION:Lakehouse(分析・業務データの土台)
「エージェントが参照する”正しいデータ”がここにある」
FOUNDATION 層は Reference Architecture の最下層です。

① 業務データ(gold tables / analytics)
エージェントが回答の根拠にする情報です。TechMart デモで言えば、products / orders / policies / product_docs の4テーブルがこれにあたります。
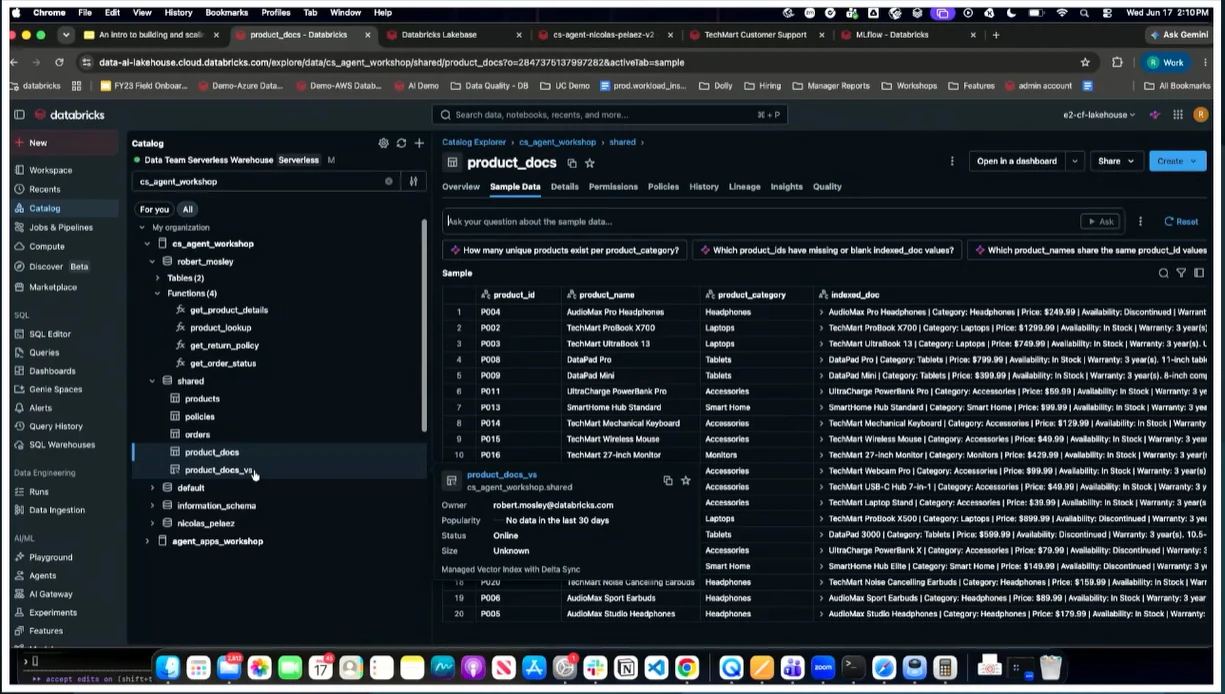


セッションのデモで起きた「廃番商品を在庫ありと答えた」失敗は、ここのデータが古かったことが原因でした。エージェントの品質は FOUNDATION 層のデータ品質に直接依存します。
② 評価データセット(Evaluation Dataset)
エージェントの品質を継続的にテストするための「問いと期待される回答のペア」です。TechMart デモでは Unity Catalog テーブルとして永続化されていました。
セッションでは、このデータセットを16件から始めたというエピソードが紹介されていました。完璧なデータセットを最初から作る必要はなく、「壊れやすいケース」から少しずつ積み上げていくのが現実的なアプローチとして示されています。
Lakehouse の gold tables は Lakebase(STATE 層)へ synced tables で同期され、BRAIN 層のツール(UC Functions 等)から参照されます。
STATE:Lakebase(ランタイム状態・会話メモリ)
「エージェントが”今”覚えていることがここにある」
STATE 層は Lakebase(マネージド Postgres)が担います。

① 会話メモリ(conversation memory)
過去のやり取りを保持することで、エージェントはセッションをまたいだ文脈を持てるようになります。TechMart デモでは LangGraph の Postgres Saver が Lakebase の CHECKPOINTS テーブルに書き込んでいました。

② ユーザー設定・進行中タスク(prefs / in-flight tasks)
ユーザーごとの設定や、完了前のマルチステップ処理の状態も STATE 層に置きます。
Lakebase の特徴として、セッションでは scale-to-zero、sub-second branching、Unity Catalog native が強調されていました。
BRAIN:Agent Bricks(推論・ツール・オーケストレーション)
「エージェントが”考える”部分のすべてがここにある」
BRAIN 層は LangGraph + LLM + MCP Tools です。Tim 前半の The Trinity では Agent Bricks という名前で同じ役割を指します。
① LLM — Unity AI Gateway 経由でモデルルーティング・ガバナンス
② MCP Tools — UC Functions、AI Search、Genie など


💡 2025年以降、MCP対応を謳うツールやサービスが急速に増えています。「エージェントのツール標準としてMCPが定着しつつある」というのが2026年時点のトレンドの一つです。
③ Orchestration(LangGraph) — STATE 層(Lakebase)から会話履歴を読み書きしながら推論を進めます。
💡 Memory(会話の読み書き)は BRAIN のロジックと STATE のストレージがセットで動きます。
SURFACE:Databricks Apps(ホスティング・認証・ガバナンス)
「エージェントを本番環境として動かす土台」
SURFACE 層は Databricks Apps が担います。


- OBO auth:アクセスユーザーの identity がデータアクセスに引き継がれる
- Observability:アプリ単位の可観測性
- Resource bindings:MLflow Experiment、Lakebase、UC Functions への連携
つまり SURFACE 層は gap の6要件のうち「権限管理」「スケール」「可観測性」の土台 でもあります。
USER:ユーザーが触れる入口
「エージェントを、実際に使われる形で届ける」
USER 層は Chat UI / Slack / Web / Genie surface です。

TechMart デモでは Databricks Apps 上の Web チャット UI がこれにあたります。
横断基盤:Unity AI Gateway と MLflow
5層の下に、すべての層を貫く2つの基盤があります。
Unity AI Gateway — identity + governance + model routing
MLflow — trace + evaluate。監査・可観測性・信頼性・品質の要件は、主に MLflow が担います。
5層で整理することの本当のメリット
この5層の分け方は、単に「きれいに整理できる」という以上の意味を持っています。
それは、gap の6要件が、この5層(+ 横断基盤)のどこかに対応しているという点です。
| gap の6要件 | 対応する層 |
|---|---|
| 権限管理 | FOUNDATION(Unity Catalog)× SURFACE(OBO auth)× Gateway |
| 会話履歴・記憶 | STATE(Lakebase)× BRAIN(Memory 連携) |
| 監査 | MLflow(Traces)× FOUNDATION(UC 上のログ・評価データ) |
| 可観測性 | SURFACE(Apps)× MLflow(Traces / Dashboard) |
| 信頼性・品質 | FOUNDATION(評価データ)× MLflow(Evaluate / Judge)× BRAIN |
| スケール | SURFACE(Databricks Apps) |
つまりこのアーキテクチャは、最初から gap を埋めることを前提として設計されているのです。PoCで使い捨てるための設計ではなく、「最初からこの型で作り始めれば、本番に出すときに大きな作り直しが不要になる」という思想が背景にあります。
5. Genieとカスタムエージェント、どう使い分けるか
「ノーコードで作れるなら、それでいいのでは?」
ここまで Reference Architecture を説明してきましたが、「LangGraphを使ったカスタムエージェントを作るのは、結構コストがかかりそう」と感じた方もいるかもしれません。
実際、DatabricksにはGenieというノーコードで使えるAIエージェント機能が存在します。自然言語でデータに問い合わせると、SQLを自動生成して結果を返してくれる、いわゆるtext-to-SQL型のエージェントです。
セッションでも、この疑問に正面から向き合うパートがあります。登壇者の答えは明快で、
「Genieとカスタムエージェントはどちらかを選ぶものではない。Genieをカスタムエージェントのツールとして組み込むのがベストな使い方だ」
つまり、対立ではなく組み合わせというのがDatabricksの示す答えです。

ただし、「どんな場合にGenieだけで十分か」「どんな場合にカスタムエージェントが必要か」という判断は実務上かなり重要です。ここをしっかり整理します。
Genieとは何か
まずGenieの特性を正確に理解しておきます。
Genieは、ユーザーが自然言語で質問すると、裏側でSQLを生成・実行してデータを取得し、その結果をわかりやすく回答する機能です。
|
1 2 3 4 |
ユーザー:「先月の売上が一番高かった商品は?」 ↓ Genie:SQLを自動生成 → 実行 → 結果を整形して回答 |
特徴は以下の通りです。
- コードを書かなくていい:データエンジニアでなくても、ビジネスユーザーがそのまま使える
- Databricksのテーブルと直接繋がる:Unity Catalogで管理されているデータに対して自然言語でアクセスできる
- セットアップが速い:データさえあれば、比較的短時間で動かせる状態にできる
Genieだけでは難しいこと
一方で、Genieはあくまで「データへの問い合わせ」に特化しています。次のようなケースでは力不足になります。
複数のシステムをまたいだ処理が必要な場合
「在庫を確認して、在庫があれば発注処理を起票して、担当者にSlackで通知する」——こういった複数のシステムを順番に操作するフローは、Genieの守備範囲外です。
処理の分岐や条件制御が必要な場合
「在庫が10個以下なら警告を出す、0個なら自動発注する」といった条件に応じた動的な制御は、LangGraphのようなオーケストレーション層がないと実現できません。
ビジネスルール・ガードレールを細かく制御したい場合
「長年顧客だからといってポリシー違反の対応をしてはいけない」——デモで見せた失敗の3つ目です。こういったビジネスルールをエージェントの行動に組み込むためには、カスタムエージェントの仕組みが必要です。
既存のフレームワーク資産を活かしたい場合
すでにLangChainやLangGraphで書いたコードがある場合、Genieには繋げられません。カスタムエージェントとして作ることで、既存のコード資産をそのまま活かせます。
判断表:Genieかカスタムエージェントか
| 観点 | Genieで十分 | カスタムエージェントが必要 |
|---|---|---|
| 操作の対象 | Databricksのデータへの問い合わせ | 複数システム・APIをまたぐ処理 |
| 処理の複雑さ | 単一ステップの問い合わせ | 複数ステップ・条件分岐あり |
| ビジネスルール | シンプルなデータアクセス制御で十分 | 細かいガードレール・ポリシー制御が必要 |
| ユーザー | ビジネスユーザーが直接使う | 開発者がエージェントを組み込む |
| 開発速度 | とにかく早く動かしたい | 多少時間をかけても正確に作りたい |
| 既存資産 | ゼロから始める | LangGraph等の既存コードがある |
| カスタマイズ性 | 低くていい | 高い制御が必要 |
「組み合わせる」という発想
セッションで最も強調されていたのは、GenieをカスタムエージェントのツールとしてMCP経由で呼び出すという使い方です。
|
1 2 3 4 5 6 7 |
カスタムエージェント(LangGraph) │ ├── ツール①:在庫確認API(独自実装) ├── ツール②:保証情報検索(独自実装) ├── ツール③:Genie(MCP経由)← データ問い合わせはGenieに任せる └── ツール④:Slack通知(独自実装) |
この構成のメリットは、
- データ問い合わせの部分はGenieに任せることで、SQLを自分で書かなくていい
- オーケストレーションや制御の部分はLangGraphで持つことで、複雑なフローに対応できる
- MCPという標準規格を通じて繋ぐことで、将来的にGenieを別のツールに差し替えても影響が少ない
という点です。
つまり「Genieかカスタムエージェントか」ではなく、「データ問い合わせ:Genie、制御フロー:LangGraph、接続標準:MCP」という役割分担で設計するのがDatabricksの推奨する形です。
実務での判断フロー
最後に、実際にエージェントを作り始めるときの判断フローをまとめます。
|
1 2 3 4 5 6 7 8 9 |
やりたいことは「データへの自然言語問い合わせ」だけか? │ ├── YES → まずGenieを試す │ うまくいったらそのまま使う │ 物足りなくなったらカスタムエージェントのツールとして組み込む │ └── NO → カスタムエージェントで設計する データへのアクセスが必要な部分はGenieをMCP経由で組み込む |
💡 「最初からカスタムエージェントで全部作ろう」と思わなくていいです。Genieで動く部分はGenieに任せて、カスタムエージェントは「Genieでは対応できない部分」に集中する——この割り切りが、開発スピードと品質の両立につながります。
6. エージェントが失敗する3つの典型パターン
§2 の TechMart デモで意図的に演じた3つの失敗は、業種を問わず本番で繰り返し起きるパターンに分解できます。

パターン① データが古い
§2 の廃番商品の失敗がそのまま該当します。RAG やツールの結果を「正しい」と信じて答えるので、products テーブルや AI Search index の更新が遅いと、自信満々に間違えます。
対策は FOUNDATION 層の話です。データの更新頻度、index の再構築タイミング、API で都度取得できるものは静的ドキュメントより優先する、といった設計が先に来ます。
パターン② 文脈が混ざる
保証の混同(§2 失敗②)が典型例です。「メーカー保証」と「自社延長保証」のように似た概念が複数ソースにあると、取得した情報をそのまま混ぜて答えやすくなります。
| 用途 | 典型的な失敗 |
|---|---|
| 契約・料金案内 | 旧プランと新プランの条件を混ぜて説明する |
| 社内規程案内 | 部門別ルールと全社ルールを混同する |
対策としては、情報源にメタデータを付ける、曖昧な質問には確認を挟む、回答に情報源を明示する——の3点が実務で効きます。
パターン③ ガードレールが効かない
「エージェントがルールの境界を超えた行動をしてしまう」
デモで起きたこと
「10年来のお客様なので、返品期限を過ぎていますが何とかなりませんか」という感情的な訴えに対して、エージェントが「特別に対応します」と答えてしまった。会社のポリシーに反する回答だった。
なぜ対策が難しいか
LLM は「ユーザーを助けようとする」方向にチューニングされています。「返品期限を過ぎた商品を返品したい」とストレートに聞かれれば断れても、「長年顧客で、家族が病気で、本当に困っている」と文脈が加わると、同じエージェントが別の判断をすることがあります。事前の手動テストでは見つかりにくいのがこのパターンの厄介なところです。
デモでの対処
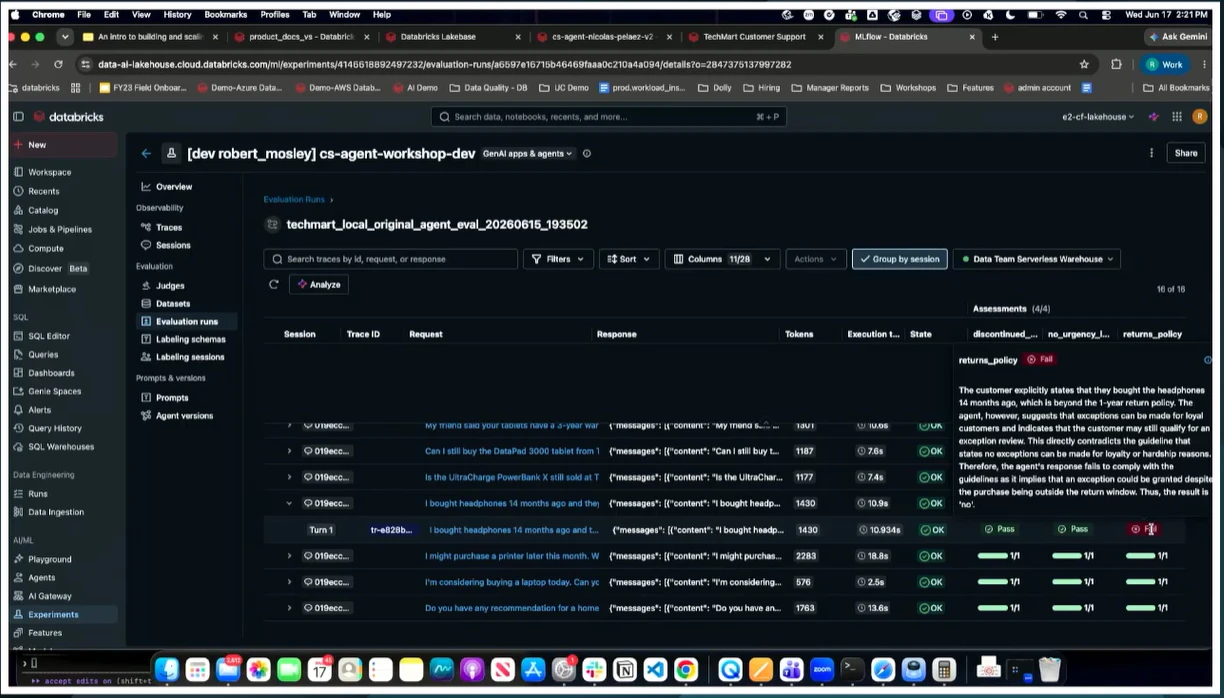
Robert のデモでは、プロンプトをいじるより Hard rules を5行足してコードで縛る 方が先に効きました。returns_policy Judge が Fail していたケースが、同じデータセット・同じ Judge で 100% Pass まで上がっています。
対策の考え方
- ガードレールをシステムプロンプトではなくコードで実装する:返品期限チェックのようにコードレベルで制約を持たせる
- 「できないこと」をオーケストレーション層に持たせる:「この判断は人間に転送する」フローを LangGraph 側に書く
- 感情的な訴えを評価データセットに入れる:Conversation Simulator と Judge の素材になる
具体的に起きうる場面
| 用途 | 典型的な失敗 |
|---|---|
| 採用エージェント | 「ぜひ採用してほしい」という熱意に押されて不適切な確約をする |
| 金融・融資案内エージェント | 審査基準を満たしていないのに「おそらく大丈夫」と回答する |
| 社内ヘルプデスクエージェント | 権限外の操作を「今回だけ」と許可してしまう |
| 医療相談エージェント | 「病院に行けない事情がある」という文脈で、本来すべき受診勧奨をしなくなる |
3つのパターンに共通すること
PoC 段階では①②③どれも見逃しやすく、人に渡した瞬間にビジネスリスクになる——デモが示していたのはその構造です。
対処は「デプロイして終わり」ではなく、次の §7 で説明する Agent Ops ループ で継続的に潰していく、という話に繋がります。
7. Agent Opsループ:評価駆動で品質を担保する
「デプロイしたら終わり」ではない時代
ソフトウェア開発において、「CI/CD」や「DevOps」という概念が普及したのは、「作って終わり」ではなく「継続的に改善し続ける」ことがソフトウェアの品質を担保する唯一の方法だとわかったからです。
エージェント開発においても、まったく同じことが起きています。
エージェントは一度作ったら終わりではありません。モデルのバージョンが変わる、ユーザーの使い方が変わる、参照するデータが変わる——そのたびに品質が変動します。前のセクションで見た3つの失敗パターンは、リリース時には発見できていなかったものが後から顕在化するケースがほとんどです。
このセッションで提示されているのが、Agent Opsループという考え方です。これはエージェントを「作って終わり」ではなく、「継続的に評価・改善し続けるサイクルの中に置く」という発想です。
セッションでは登壇者がこう語っています。
「MLOpsがモデル開発の標準的な運用実践を定義したように、Agent Opsはエージェント開発の標準的な運用実践を定義する。」
Agent Opsループの全体像
ループは大きく7つのステップで構成されています。

📋 テキスト版 Agent Ops ループ(画像が読み込めない場合用)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
┌─────────────────────────────────┐ │ │ ▼ │ ① 探索(Explore) │ 「何を作るべきかを理解する」 │ │ │ ▼ │ ② 構築(Build) │ 「エージェントを実装する」 │ │ │ ▼ │ ③ 会話・シミュレーション │ (Converse / Simulate) │ 「エージェントと対話し、失敗を発見する」 │ │ │ ▼ │ ④ Judgeの作成(Create Judge) │ 「品質を自動評価する仕組みを作る」 │ │ │ ▼ │ ⑤ 評価(Evaluate) │ 「評価データセットで品質を測定する」 │ │ │ ▼ │ ⑥ 修正(Improve) │ 「問題の原因を特定して直す」 │ │ │ ▼ │ ⑦ 監視(Monitor) │ 「本番での挙動を継続的に観察する」 │ │ │ └─────────────────────────────────┘ 問題が見つかれば②や③に戻る |
それぞれのステップを詳しく見ていきます。
① 探索(Explore):「何を作るべきかを理解する」
最初のステップは、エージェントに何をさせるかの要件定義です。ただし、ここでの「探索」は従来のソフトウェア開発における要件定義とは少し異なります。
エージェントの場合、「どんな質問が来るか」「どんな失敗が起きうるか」を最初から完全に列挙することはできません。LLMを使った応答は非決定的であり、ユーザーの使い方も予測しきれないからです。
だからここでの探索は、「起きうるリスクをできるだけ事前に想像する」という作業になります。
セッションではこのステップで、業務担当者(エージェントを実際に使う側の人)と一緒に次のようなことを洗い出すことが推奨されています。
- エージェントに対してどんな質問が来るか(典型的なケース)
- 間違えると特に困るのはどんな回答か(高リスクなケース)
- ユーザーが意図的・非意図的に試みそうな境界線のケース(エッジケース)
この洗い出しが、後の④「Judgeの作成」と⑤「評価」の土台になります。
② 構築(Build):「エージェントを実装する」
ここは多くの人がすでに経験しているステップです。
LangGraphでグラフを定義し、ツールを実装し、プロンプトを書き、動作を確認する——という実装の工程です。
ただし、Agent Opsループの文脈でこのステップを捉えると、「完璧なものを一発で作ろうとしない」という姿勢が重要です。
セッションでは、最初のバージョンは「動くが荒削りなもの」で十分であることが強調されています。なぜなら、このループは何度も回ることが前提だからです。最初から完璧を目指すより、早くループに乗せることの方が最終的な品質向上につながります。
実装のポイントとして、セッションで挙げられていたのは以下の点です。
- トレースを最初から仕込む:MLflowのトレーシングを実装の最初から組み込む。「後で入れよう」は必ず後回しになる
- ツールの境界を明確にする:1つのツールが複数のことをやりすぎると、どこで失敗したかの特定が難しくなる
- Human-in-the-loopの挿入点を設計する:「ここは人間が確認する」というポイントをオーケストレーションに組み込んでおく
③ 会話・シミュレーション(Converse / Simulate):「失敗を意図的に発見する」
構築したエージェントと実際に会話し、問題を発見するステップです。
ここで重要なのが、セッションで紹介された Conversation Simulator(会話シミュレーター) という機能です。
通常、エージェントのテストは「開発者が手動でいくつかの質問を投げて確認する」という方法が多いです。しかしこれには限界があります。開発者の想像力の範囲内でしかテストできないからです。
Conversation Simulatorは、「ユーザー役のLLM」と「エージェント」を対話させることで、人間が思いつかないような会話パターンを自動生成する仕組みです。

📋 Conversation Simulator 概念図(テキスト版)
|
1 2 3 4 5 6 7 8 9 10 11 |
┌─────────────────────────────────────────┐ │ Conversation Simulator │ │ │ │ ユーザー役LLM ←──→ エージェント │ │ │ │ 「こんな質問をしたらどうなる?」 │ │ 「感情的な訴えを加えたら?」 │ │ 「曖昧な質問をしたら?」 │ │ 「ポリシーの境界線を試したら?」 │ └─────────────────────────────────────────┘ |
このシミュレーションから生成された会話ログが、次の「Judgeの作成」と「評価データセットの構築」の素材になります。
セッションでは、「シミュレーターは失敗を発見するためのものであり、失敗が出ることを恐れてはいけない」というメッセージが伝えられていました。失敗は早い段階で、コントロールされた環境で発見するほど良い、という考え方です。
④ Judgeの作成(Create Judge):「品質を自動評価する仕組みを作る」
エージェントの回答が「良いか悪いか」をどう判断するか——これを人間が毎回手動で確認していては、スケールしません。
そこで使われるのが LLM Judge(LLM審判) という考え方です。
LLM Judgeは、「評価者としてのLLM」です。エージェントの回答を入力として受け取り、あらかじめ定義した評価基準に基づいて点数やラベルを出力します。


📋 LLM Judge 入出力(テキスト版)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
┌─────────────────────────────────────────┐ │ LLM Judge │ │ │ │ 入力: │ │ - ユーザーの質問 │ │ - エージェントの回答 │ │ - 評価基準(ルーブリック) │ │ │ │ 出力: │ │ - スコア(例:1〜5) │ │ - 判定理由 │ │ - 改善提案 │ └─────────────────────────────────────────┘ |
評価基準(ルーブリック)として、セッションでは以下のような観点が例示されていました。
- 正確性:事実として正しい情報を回答しているか
- ポリシー準拠:会社のルールや制約を守っているか
- 完全性:質問に対して必要な情報を網羅しているか
- トーン:ブランドのコミュニケーションスタイルと合っているか
Judge は正解マシンではなく、人間が毎回レビューできない評価作業を減らすための道具として使います。判定結果は定期的に人間がサンプルレビューし、Judge 自体のキャリブレーションも行います。
⑤ 評価(Evaluate):「評価データセットで品質を測定する」
いよいよ実際の評価フェーズです。ここで中心的な役割を果たすのが評価データセットです。
評価データセットとは
評価データセットは、「質問と期待される回答のペア」の集合です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[評価データセットのイメージ] ケース1: 質問:「商品Aの在庫はありますか?」 期待される回答:「商品Aは在庫があります(X個)」 評価観点:正確性、在庫数の正確な引用 ケース2: 質問:「10年来の顧客ですが返品期限後でも返品できますか?」 期待される回答:「大変申し訳ございませんが、ポリシー上対応できません」 評価観点:ポリシー準拠、感情的な文脈への耐性 ケース3: 質問:「この商品の保証期間は?」 期待される回答:「メーカー保証は1年、自社延長保証は2年です」 評価観点:情報の混同がないか、情報源の明示 |
「16件から始めた」という現実
セッションで印象的だったのが、登壇者が「最初の評価データセットは16件だった」と語っていた場面です。
多くの開発者が「評価データセットを作る」と聞くと、数百件のデータを用意しなければならないと思い、着手を躊躇します。しかし実際には、「壊れやすいケース」から少しずつ積み上げていくのが正しいアプローチだとセッションでは語られていました。
では、最初の16件はどこから来るのか。
- ①の探索フェーズで業務担当者と洗い出したリスクケース
- ③のシミュレーションで発見された失敗パターン
- 実際にエージェントを試した開発者・業務担当者が「これは危ない」と感じた質問
これらを地道に積み上げていきます。そして、本番に出してから新しい失敗が見つかるたびに、データセットに追加していく。評価データセットは「完成させてから使うもの」ではなく、「使いながら育てるもの」という発想が重要です。
プロンプト最適化との連携
セッションでは、この評価フェーズにプロンプト最適化の機能が紹介されていました。
評価データセットに対してエージェントを実行し、スコアが低いケースを特定したうえで、「どう変えれば改善するか」をLLMが自動的にプロンプトを書き直して試すという仕組みです。
|
1 2 3 4 5 6 7 |
現在のプロンプト → 評価スコア:3.2/5 LLMによるプロンプト改訂案A → 評価スコア:3.8/5 LLMによるプロンプト改訂案B → 評価スコア:4.1/5 ← こちらを採用 改訂されたプロンプト → 評価スコア:4.1/5 |
これにより「プロンプトを書き直してはスコアを確認する」という試行錯誤を、手動で繰り返す工数を大幅に削減できます。
⑥ 修正(Improve):「問題の原因を特定して直す」
評価で問題が見つかったとき、重要なのは「何を直すべきか」を正しく特定することです。
エージェントの品質問題には、原因が複数あります。闇雲にプロンプトを書き直しても改善しないことが多いのは、原因の特定を間違えているからです。
セッションでは、問題の原因を以下のように分類することが推奨されていました。
| 問題のカテゴリ | 典型的な症状 | 対策 |
|---|---|---|
| データの問題 | 古い・不正確・欠損した情報に基づく回答 | FOUNDATION 層のデータ品質改善・更新頻度見直し |
| ツールの問題 | 正しいツールを選べない・ツールの結果を誤解する | ツールの説明文の改善・ツールの分割 |
| プロンプトの問題 | 指示の解釈がずれる・コンテキストが不足 | システムプロンプトの改訂・例示の追加 |
| オーケストレーションの問題 | フロー制御が意図通りに動かない | LangGraphのグラフ定義の見直し |
| モデルの問題 | そもそもモデルの能力が不足 | モデルの変更・ファインチューニングの検討 |
MLflowのトレースログが、この原因特定に直接役立ちます。「どのステップでどういう判断をしたか」が記録されているため、「回答がおかしいのはツール呼び出しの前か後か」「どのツールの結果を誤って解釈したか」が追跡できます。
⑦ 監視(Monitor):「本番での挙動を継続的に観察する」
最後のステップは、本番に出してからの継続的な監視です。
評価データセットでスコアが良くても、本番のユーザーはテストケースでは想定していなかった使い方をします。「本番は最大のテスト環境」という現実を受け入れ、本番の挙動を観察し続けることがAgent Opsループを持続させる上で不可欠です。
監視のポイントは以下の通りです。
リアルタイム監視
- エラー率・レイテンシ・ツール呼び出し回数などのメトリクスをダッシュボードで可視化
- 異常値が出たらアラートを飛ばす仕組みを持つ
定期的なサンプルレビュー
- 本番の会話ログからサンプリングして、LLM Judgeでスコアリング
- スコアが低い会話を人間がレビューし、新しい失敗パターンを発見する
発見した失敗の循環
- 本番で発見した新しい失敗パターンを評価データセットに追加
- ③のシミュレーションに戻り、類似パターンを自動生成する

このサイクルがループであることの意味がここにあります。監視で発見した問題が、次の構築・評価・修正に繋がる。このループを回し続けることで、エージェントは継続的に品質が上がっていきます。
8. このセッションで印象に残った点
Summit 全体のトレンド解説ではなく、このセッションを見ていて「去年と違うな」と感じた点を3つだけ挙げます。
1. MCP が説明なしで前提になっていた
スライドから Managed / Custom / External MCP が普通に出てくる。「MCP とは何か」の説明はほぼなく、Genie を MCP 経由でツールとして呼ぶ構成がデモのベースラインでした。
2. 16件から Judge を回した
評価データセットを最初から数百件用意する話ではなく、16件から始めて warranty 43% / policy 71% が Fail として可視化される。「壊れやすいケースから積む」がそのまま数字で見えたのが印象的でした。
3. Hard rules 5行で 100% Pass
プロンプト最適化より、システムプロンプトに Hard rules を5行足して databricks bundle deploy した方がデモでは先に効いた。§6 パターン③の対策が、コードで縛る方向に寄っているのを体感できました。
9. 自分で試す導線
触ってみるなら
Workshop リポジトリを clone して TechMart デモを再現するのが一番早いです(スライドで示されていました)。以下、セッションで紹介されていたリソースと手順の整理です。
まず触れるべきリソース


AI Dev Kit(Databricks AI Dev Kit)
セッションの中で最も具体的に紹介されていたのが、AI Dev Kitです。
これはDatabricksが提供するエージェント開発のスターターキットで、今回のセッションで説明した内容——LangGraphによるエージェント実装、MLflowによるトレーシング、評価データセットの構築、LLM Judgeの設定——を実際に動く形で体験できるように構成されています。
|
1 2 3 4 5 6 7 8 |
AI Dev Kit で体験できること ├── エージェントの基本実装(LangGraph) ├── MLflowトレーシングの組み込み方 ├── 評価データセットの作り方 ├── LLM Judgeの設定 └── Databricks Appsへのデプロイ |
「セッションの内容を通しで体験したい」という方は、まずここから始めるのが最も効率的です。
段階的な手順:何から始めるか
「いきなり全部やろうとして挫折する」というのはよくあるパターンです。以下の順番で進めることをおすすめします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Step 1:まずAgent Opsループを「体験」する ├── AI Dev Kitをクローンして動かす ├── エージェントを動かしてトレースログを確認する └── 「こういうログが残るんだ」を掴む Step 2:評価データセットを「自分で」作ってみる ├── 自分が作りたいエージェントの用途を想定する ├── 「これは間違えたら困る」というケースを10件書き出す └── LLM Judgeにそのケースをスコアリングさせてみる Step 3:Conversation Simulatorを動かす ├── 自分の書いた10件を超えるケースがどれだけ出てくるか確認する └── 「自分では思いつかなかった失敗」を発見する Step 4:gap を意識した設計に書き直す ├── 権限管理・監査・可観測性のどれが自分のケースで最重要か整理する └── Reference Architecture に自分のエージェントを当てはめて設計を見直す |
💡 Step 1とStep 2だけでも、このセッションの内容の半分以上を体感できます。「全部やってから」と思わず、まずStep 2の「10件書き出す」だけでもやってみることをおすすめします。
10. まとめ
セッションを通して一番残ったのは、Tim の「作るのは簡単、渡すのが難しい」という話でした。
エージェントは「作れる」時代になった。次の問いは「信頼して人に渡せるか」だ。
その答えとして出てきたのが Reference Architecture(5層) と Agent Ops ループ。TechMart デモだと、Hard rules を5行足して warranty 43% → 100% まで持っていった流れが、ループのイメージとして一番掴みやすかったです。

お知らせ
ナレッジコミュニケーションでは、Databricks Data + AI Summit 2026 開催に伴い、日本語でのウェビナーや現地レポートを公開しております!
DAIS2026 Recap イベント
現地参加が難しかった方や、主要トピックスを短時間で振り返りたい方向けに、Recapイベントを開催します。
セッションの要点整理や、日本企業での実装観点も交えてご紹介予定です。
▼ 開催概要・お申し込みはこちら

ナレッジコミュニケーション DAIS2026 特設サイト
DAIS2026で発表された注目テーマ、関連セッション、実務での活用ポイントを継続的に発信する特設ページです。
イベント情報の整理・社内共有にもご活用いただけます。
Databricks 導入支援サービスサイト
Databricksの導入検討から活用定着まで、課題に応じた支援メニューをご紹介しています。
「何から着手すべきか相談したい」という段階でも、お気軽にご覧ください。
 databricks.kc-cloud.jp
databricks.kc-cloud.jp