本記事は OpenAI活用法 Advent Calendar 2023 by ナレコム の10日目の記事です。
OpenAI活用法 Advent Calendar 2023 by ナレコム ではGPTsを含めた最新のOpenAIの活用法について紹介します。
はじめに
クラウド上での検索エンジンの最適化は、データの扱いや検索の効率性を大きく向上させることができます。Azure AI Searchは、その中でも特に強力な検索機能とカスタマイズ性を提供しており、さまざまな言語と文化的背景を持つデータに対応することができます。特に、日本語のように独特な文法構造を持つ言語では、適切な検索エンジンの選択と設定が重要です。
この記事では、Azure AI Searchの検索分析エンジン「標準 – Lucene」、「日本語 – Lucene」、「日本語 – Microsoft」の違いと、それらのエンジンを使用して日本語データの検索最適化を行う方法について解説します。標準のLuceneエンジンでは多言語に基本的な検索機能を提供しますが、日本語専用のLuceneやMicrosoftのエンジンでは、より高度な日本語解析と検索精度の向上が期待できます。
取り込んだままだとメインとなる文章を取り込んだデータが「標準 – Lucene」になっています。これを日本語にする方法を解説します。
検索分析エンジンについて
今回の記事で利用する「標準 – Lucene」、「日本語 – Lucene」、「日本語 – Microsoft」の違いについて説明します。
-
標準 – Lucene: これは、Azure Searchにおけるデフォルトの検索分析エンジンです。Apache Luceneは、広く使用されているオープンソースの全文検索ライブラリで、多くの言語で基本的な検索機能を提供します。しかし、この標準設定では、特定の言語に特化した最適化や特別なトークン化処理は含まれていません。これは、多言語の環境で基本的な検索ニーズに対応するために使われます。
-
日本語 – Lucene: このオプションは、Luceneベースのエンジンを使用していますが、日本語の検索に特化しています。日本語は複雑な文法と曖昧性を持ち、単語の区切りが明確でないことが多いため、特別なトークン化アルゴリズムが必要です。このオプションは、日本語のテキストをより効果的に解析し、検索結果の精度を高めるための最適化が施されています。
-
日本語 – Microsoft: この設定も日本語に特化していますが、こちらはMicrosoftが開発した独自の分析エンジンを使用しています。Microsoftのエンジンは、Luceneベースのものとは異なり、Microsoftが長年にわたって蓄積してきた言語処理技術と知見を活用しています。これにより、より洗練されたトークン化、文脈理解、意味解析が可能になり、日本語の検索における精度と関連性をさらに高めることができます。
簡単に言うと、標準 – Luceneは多言語に基本的な検索機能を提供し、日本語 – Luceneは日本語に特化したLuceneベースの検索を、日本語 – MicrosoftはMicrosoft独自の技術による高度な日本語検索を提供します。選択は、利用するデータの言語と検索の必要性によって決まります。
検索分析エンジンの変更方法
インデックスの追加
- Azureポータルからインデックスの変更をしたいAzure AI Searchを選択します。
- 左メニューから「インデックス」を選択し、変更をしたいインデックスをクリックします。
- 「{} JSONの編集」をクリックします。
- 今回は「”name”: “chunk”」の「”analyzer”: null」を**「”analyzer”: “ja.lucene”」または「”analyzer”: “ja.microsoft”」**に変更したいものの作成済みインデックスは項目の変更が出来ないため、jsonをメモ帳にコピーします。
- 「インデックス」ページで「+ インデックスの追加」をクリックし、「インデックスの追加(JSON)」を選択します。
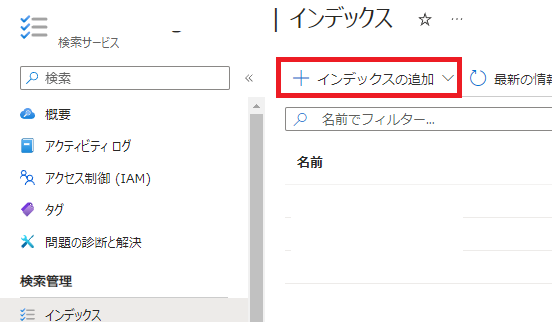
- 先程コピーしたJSONを貼り付け、以下の項目を編集します。
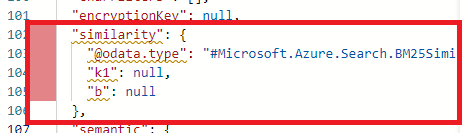
行番号が赤い列⇒削除(※similarityの部分は次の行まで削除が必要)
name⇒同一名だと保存できないので、任意の名前(例:〇〇-jalucene)
“analyzer”: null⇒”analyzer”: “ja.lucene” または “analyzer”: “ja.microsoft”
インデクサーの追加
- Azureポータルからインデックスの変更をしたいAzure AI Searchを選択します。
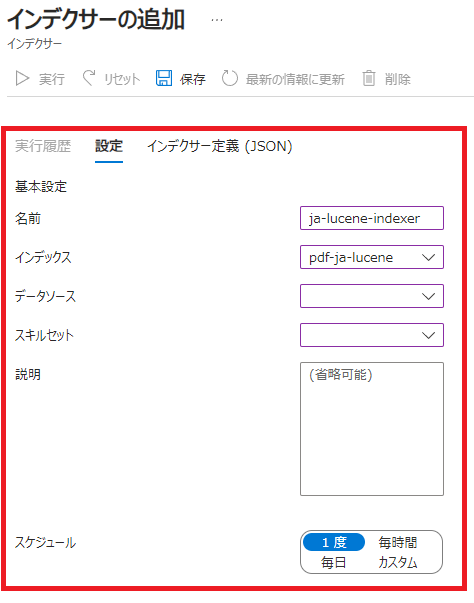
- 左メニューから「インデクサー」を選択し、「+ インデクサーの追加」をクリックします。
- 以下のように設定します。
名前⇒任意の名称
インデックス⇒上記で作成したインデックス
データソース⇒元のインデックスを作成したデータソース
スキルセット⇒なし
スケジュール⇒一度
- ページ上部の「保存」をクリックしてから「実行」をクリックします。
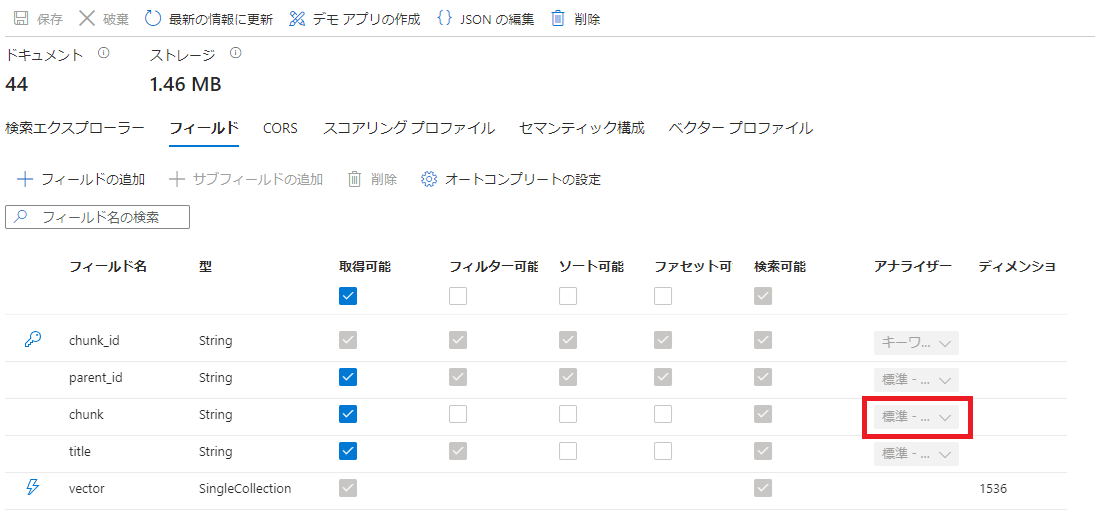
成功すると以下のようにアナライザーが変更され、左上のドキュメントやストレージにも数字が表示されます。
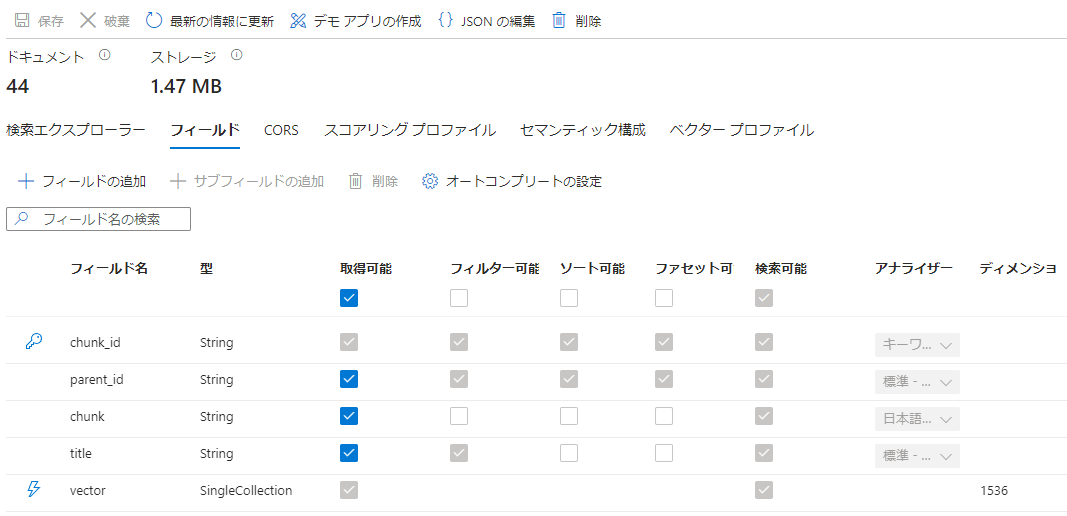
検証データでは、それほど複雑な文章もなく標準のluceneでも十分検索が出来、検索結果(スコアや順位)もほぼ変わらなかったです。
まとめ
この記事では、Azure AI Searchの検索分析エンジンの種類とそれぞれの特徴、および日本語データの検索最適化のための設定変更方法について解説しました。Azure AI Searchは、様々な言語データに対応する強力な検索機能を提供し、特に日本語のような複雑な言語においては、適切な検索分析エンジンの選択が重要です。
インデックスの追加とインデクサーの設定変更を通じて、既存の「標準 – Lucene」ベースのデータを日本語に特化したエンジンに変更する方法を紹介しました。このプロセスにより、日本語データの検索効率と精度が向上することが期待できます。
最後に、検証データにおいては、標準のLuceneでも十分な検索性能が得られることが確認されましたが、より複雑な日本語データに対しては、日本語に特化したエンジンがより適切な選択となります。Azure AI Searchの機能を最大限に活用し、日本語データの検索性能を高めることで、ユーザーにとってより価値のある検索経験を提供することができます。
また、ナレッジコミュニケーションでは 「Musubite」 というエンジニア同士のカジュアルトークサービスを利用しています!この記事にあるような生成AI 技術を使ったプロジェクトに携わるメンバーと直接話せるサービスですので興味がある方は是非利用を検討してください!
